Dieser Artikel wird von der Huawei Cloud Community „ Warum hält HDFS im Bereich Big Data Bestand? , von JavaEdge.
1. Übersicht
1.1 Einleitung
- Ein von Hadoop (Hadoop Distributed File System) implementiertes verteiltes Dateisystem, das als HDFS bezeichnet wird
- Aus dem 2003 veröffentlichten GFS-Papier von Google geht hervor, dass HDFS ein Klon von GFS ist
Das wertvollste und am schwierigsten zu ersetzende Big Data sind Daten, und alles dreht sich um Daten.
HDFS ist das früheste Big-Data-Speichersystem, das wertvolle Datenbestände speichert.Wenn verschiedene neue Algorithmen und Frameworks weit verbreitet sein sollen, muss HDFS unterstützt werden, um die darin gespeicherten Daten zu erhalten. Je mehr Big-Data-Technologie sich entwickelt und je mehr neue Technologien, desto mehr Unterstützung erhält HDFS und desto mehr ist es untrennbar mit HDFS verbunden. HDFS ist vielleicht nicht die beste Big-Data-Speichertechnologie, aber es ist immer noch die wichtigste Big-Data-Speichertechnologie .
Wie erreicht HDFS eine schnelle und zuverlässige Speicherung und den Zugriff auf Big Data?
Das Designziel des verteilten Hadoop-Dateisystems HDFS besteht darin, Tausende von Servern und Zehntausende von Festplatten zu verwalten, große Server-Computing-Ressourcen als ein einziges Speichersystem zu verwalten und Dutzende von Petabyte an Daten für Anwendungen bereitzustellen Anwendungen zum Speichern umfangreicher Dateidaten, als würden sie ein normales Dateisystem verwenden.
1.2 Designziele
Dateien werden in mehreren Kopien gespeichert:
filel:node1 node2 node3
file2: node2 node3 node4
file3: node3 node4 node5
file4: node5 node6 node7
Mangel:
- Unabhängig davon, wie groß die Datei ist, wird sie in einem Knoten gespeichert. Bei der Verarbeitung von Daten ist es schwierig, eine parallele Verarbeitung durchzuführen. Der Knoten kann zu einem Engpass im Netzwerk werden, was die Verarbeitung von Big Data erschwert.
- Die Speicherlast ist schwer auszugleichen und die Auslastung jedes Knotens ist sehr gering
Vorteil:
-
Riesiges verteiltes Dateisystem
-
läuft auf gewöhnlicher billiger Hardware
-
Einfach zu erweitern und Benutzern einen Dateispeicherdienst mit guter Leistung bereitzustellen
2 So entwerfen Sie ein verteiltes Dateisystem
Implementierung von HDFS für Massenspeicher und Hochgeschwindigkeitszugriff.
Nachdem RAID-Daten-Shards erstellt wurden, erfolgt der Lese- und Schreibzugriff gleichzeitig auf mehreren Datenträgern, was die Speicherkapazität erhöht, den Zugriff beschleunigt und die Datenzuverlässigkeit durch Datenredundanzprüfung verbessert.Selbst wenn ein bestimmter Datenträger beschädigt wird, gehen keine Daten verloren. Durch die Erweiterung des Designkonzepts von RAID auf den gesamten verteilten Servercluster entsteht ein verteiltes Dateisystem, das das Kernprinzip des verteilten Dateisystems von Hadoop ist.
Ähnlich wie RAIDs Idee der Dateispeicherung und des parallelen Lesens und Schreibens auf mehreren Festplatten ist HDFS ein groß angelegter verteilter Servercluster, der nach dem Sharding paralleles Lesen und Schreiben und redundantes Speichern von Daten durchführt. Da HDFS in einem großen Servercluster bereitgestellt werden kann, können die Festplatten aller Server im Cluster von HDFS verwendet werden, sodass der Speicherplatz des gesamten HDFS das PB-Niveau erreichen kann.
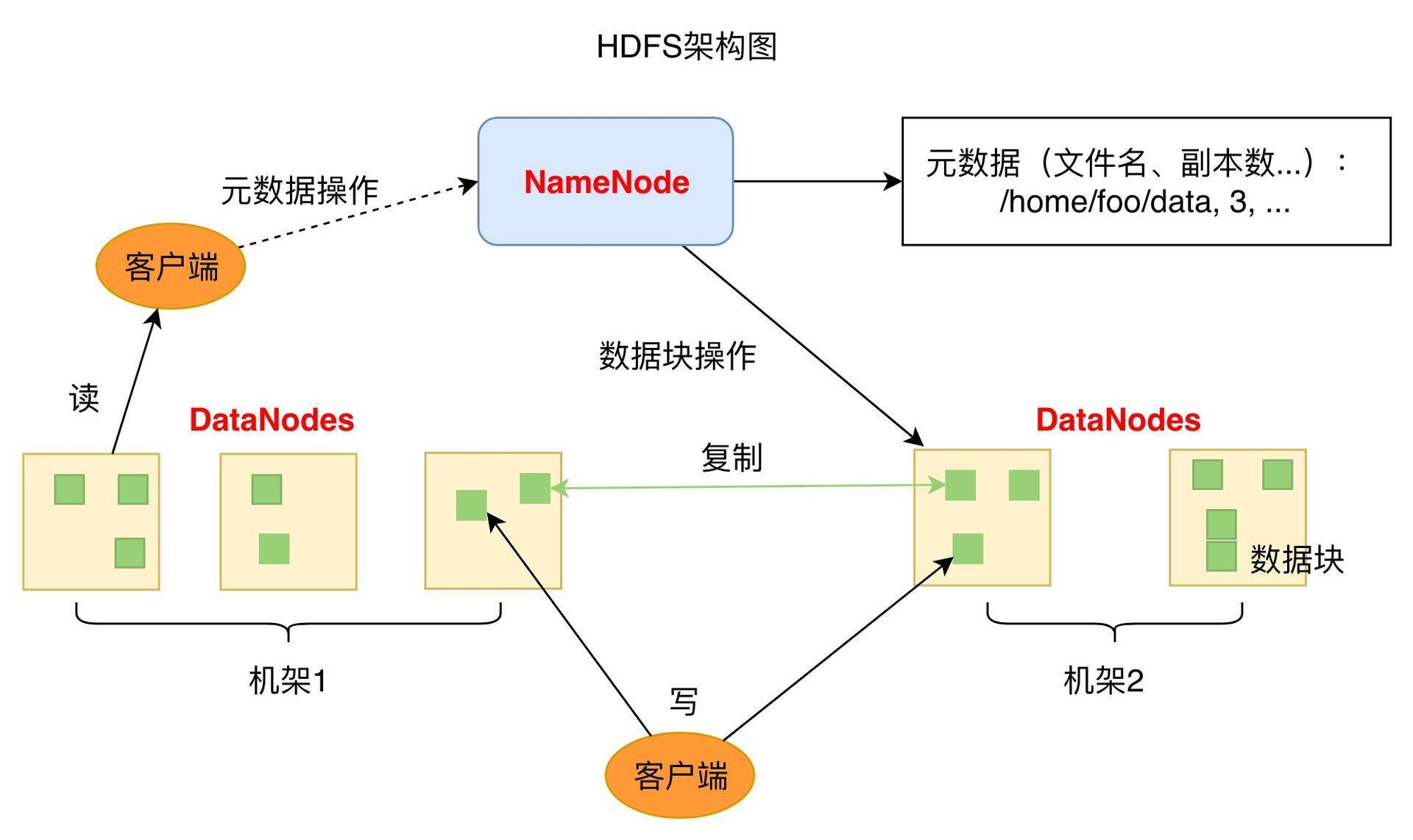
HDFS ist eine Master-Slave-Architektur. Ein HDFS-Cluster hat einen NameNode (Named Node, kurz NN) als Master-Server.
- NameNode wird verwendet, um den Namespace des Dateisystems zu verwalten und den Clientzugriff auf Dateien zu regulieren
- Es gibt auch mehrere DataNodes (kurz DN), Datenknoten, die als Slave-Knoten (Slave-Server) existieren.
- Normalerweise werden die DataNodes in jedem Cluster vom NameNode verwaltet, und die DataNodes werden zum Speichern von Daten verwendet
HDFS legt den Dateisystem-Namespace offen, sodass Benutzer Daten in Dateien speichern können, genau wie wir normalerweise das Dateisystem in Betriebssystemen verwenden, und Benutzer müssen sich nicht darum kümmern, wie die zugrunde liegenden Daten gespeichert werden.
Unter der Haube wird eine Datei in einen oder mehrere Datenblöcke unterteilt, und diese Datenbankblöcke werden in einer Reihe von Datenknoten gespeichert. Der standardmäßige 128M-Datenblock in CDH.
Bei NameNode können Dateisystem-Namespace-Operationen wie Öffnen, Schließen, Umbenennen von Dateien usw. durchgeführt werden. Dies bestimmt auch die Zuordnung von Datenblöcken zu Datenknoten.
HDFS ist so konzipiert, dass es auf gewöhnlichen billigen Computern läuft, auf denen normalerweise ein Linux-Betriebssystem ausgeführt wird. Eine typische HDFS-Cluster-Bereitstellung verfügt über einen dedizierten Computer, auf dem nur eine Instanz ausgeführt NameNodewird, während auf den Computern in den anderen Clustern jeweils eine DataNodeInstanz ausgeführt wird. Obwohl es möglich ist, mehrere Knoten auf einem einzelnen Computer auszuführen, wird dies nicht empfohlen.

Datenknoten
- Speichern Sie den Datenblock (Block), der der Datei des Benutzers entspricht
- Es sendet regelmäßig Heartbeat-Informationen an NN und meldet sich selbst und alle seine Blockinformationen und seinen Gesundheitszustand
HDFS ist für die Speicherung und Lese-/Schreiboperationen von Dateidaten verantwortlich und teilt die Dateidaten in mehrere Datenblöcke (Block) auf, und jeder DataNode speichert einen Teil des Blocks, sodass die Dateien im gesamten HDFS-Servercluster verteilt und gespeichert werden .
Anwendungsclients (Client) können parallel auf diese Blöcke zugreifen, sodass HDFS einen parallelen Datenzugriff in der Größenordnung von Serverclustern erreichen kann, wodurch die Zugriffsgeschwindigkeit erheblich verbessert wird.
In einem HDFS-Cluster gibt es viele DataNode-Server, die in der Regel zwischen Hunderten und Tausenden liegen.Jeder Server ist mit mehreren Festplatten ausgestattet, und die Speicherkapazität des gesamten Clusters beträgt etwa mehrere PB bis mehrere hundert PB.
NameNode
- Verantwortlich für die Beantwortung von Kundenanfragen
- Verantwortlich für die Verwaltung von Metadaten (Dateiname, Kopierkoeffizient, von Block gespeicherter DN)
Verantwortlich für die Verwaltung der Metadaten (MetaData) des gesamten verteilten Dateisystems, d. h. des Dateipfadnamens, der Datenblock-ID und des Speicherorts und anderer Informationen, ähnlich der Dateizuordnungstabelle (FAT) in os.
Um eine hohe Datenverfügbarkeit zu gewährleisten, kopiert HDFS einen Block in mehrere Kopien (standardmäßig 3 Kopien) und speichert mehrere Kopien desselben Blocks auf verschiedenen Servern oder sogar verschiedenen Racks. Wenn eine Festplatte beschädigt oder ein DataNode-Server oder sogar ein Switch ausgefallen ist, sodass auf die darin gespeicherten Datenblöcke nicht zugegriffen werden kann, sucht der Client nach seinem Backup-Block, auf den er zugreifen kann.
3 S Replika-Mechanismus
Bei HDFS wird eine Datei in einen oder mehrere Datenblöcke aufgeteilt. Standardmäßig gibt es drei Kopien jedes Datenblocks, jede Kopie wird auf einem anderen Computer gespeichert und jede Kopie hat ihre eigene eindeutige Nummer:
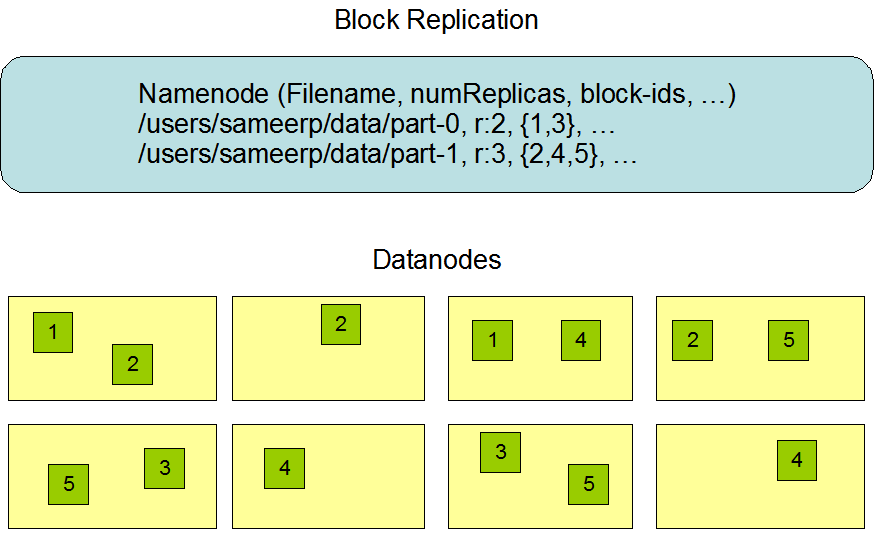
Blockdiagramm der Speicherung mehrerer Kopien
Die Anzahl der replizierten Backups der Datei /users/sameerp/data/part-0 wird auf 2 gesetzt, und die gespeicherten BlockIDs sind 1 bzw. 3:
- Die beiden Sicherungen von Block1 werden auf zwei Servern gespeichert, DataNode0 und DataNode2
- Zwei Backups von Block3 werden auf zwei Servern gespeichert, DataNode4 und DataNode6
Nachdem einer der oben genannten Server ausgefallen ist, existiert mindestens eine Sicherung jedes Datenblocks, was den Zugriff auf die Datei /users/sameerp/data/part-0 nicht beeinträchtigt.
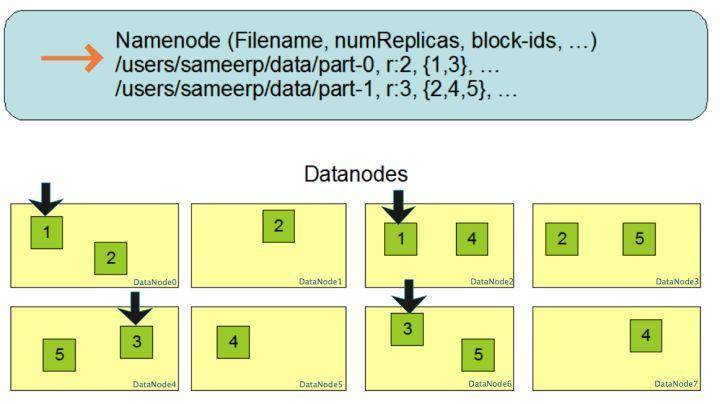
Wie bei RAID werden Daten in mehrere Blöcke unterteilt und auf verschiedenen Servern gespeichert, um eine große Datenspeicherkapazität zu erreichen, und Daten in verschiedenen Shards können parallel gelesen/geschrieben werden, um einen Hochgeschwindigkeitsdatenzugriff zu erreichen.
Speicherstrategie kopieren
Replikatspeicherung: Der NameNode-Knoten wählt einen DataNode-Knoten zum Speichern von Blockreplikaten aus.Die Strategie dieses Prozesses besteht darin, Zuverlässigkeit und Lese- und Schreibbandbreite auszugleichen.
Der Standardweg im Hadoop Definitive Guide:
- Das erste Replikat wird zufällig ausgewählt, aber es werden keine Knoten mit überfülltem Speicher ausgewählt
- Die zweite Kopie wird auf einem anderen und zufällig ausgewählten Gestell platziert als die erste Kopie
- 3. und 2. auf verschiedenen Knoten im selben Rack
- Die verbleibenden Replikate sind vollständig zufällige Knoten

Angemessene Analyse
- Zuverlässigkeit: Blöcke werden in zwei Regalen gelagert
- Schreibbandbreite: Schreibvorgänge durchlaufen nur einen Netzwerk-Switch
- Lesevorgang: Wählen Sie eines der zu lesenden Racks aus
- Blöcke werden über den Cluster verteilt
Das erste Laufwerk von Googles Big Data „Troika“ ist GFS (Google File System), und das erste Produkt von Hadoop ist HDFS, und die verteilte Dateispeicherung ist die Grundlage des verteilten Rechnens.
Im Laufe der Jahre wurden kontinuierlich verschiedene Computer-Frameworks, verschiedene Algorithmen und verschiedene Anwendungsszenarien eingeführt, aber der König der Big-Data-Speicherung ist immer noch HDFS.
5 Hochverfügbarkeitsdesign von HDFS
5.1 Fehlertoleranz bei der Datenspeicherung
Das Plattenmedium wird durch die Umgebung oder Alterung während des Speicherprozesses beeinträchtigt, und die gespeicherten Daten können chaotisch sein.
HDFS berechnet und speichert die Prüfsumme (CheckSum) der auf dem DataNode gespeicherten Datenblöcke. Berechnen Sie beim Lesen von Daten die Prüfsumme der gelesenen Daten neu. Wenn die Prüfsumme falsch ist, wird eine Ausnahme ausgelöst. Nachdem die Anwendung die Ausnahme abgefangen hat, liest sie die Sicherungsdaten auf anderen DataNodes.
5.2 Festplattenfehlertoleranz
Wenn der DataNode feststellt, dass eine bestimmte Platte der lokalen Maschine beschädigt ist, meldet er alle auf der Platte gespeicherten BlockIDs an den NameNode. Der NameNode prüft, welche DataNodes Backups für diese Datenblöcke haben, und informiert den entsprechenden DataNode-Server, die entsprechenden Daten zu kopieren Blöcke auf andere Server, um sicherzustellen, dass die Anzahl der Sicherungen von Datenblöcken den Anforderungen entspricht.
5.3 DataNode-Fehlertoleranz
Der DataNode wird die Kommunikation mit dem NameNode durch Heartbeats aufrechterhalten. Wenn der DataNode im Laufe der Zeit keinen Heartbeat sendet, betrachtet der NameNode den DataNode als ausgefallen und ausgefallen und findet sofort heraus, welche Datenblöcke auf dem DataNode gespeichert sind und welche Server diese Datenblöcke gespeichert. Benachrichtigen Sie dann diese Server, um einen weiteren Datenblock auf andere Server zu kopieren, um sicherzustellen, dass die Anzahl der in HDFS gespeicherten Datenblocksicherungen der vom Benutzer festgelegten Anzahl entspricht. Selbst wenn der Server erneut ausfällt, werden die Daten nicht gespeichert hat verloren.
5.4 NameNode-Fehlertoleranz
Der NameNode ist der Kern des gesamten HDFS. Er zeichnet die Informationen der HDFS-Dateizuordnungstabelle auf. Alle Dateipfade und Datenblockspeicherinformationen werden im NameNode gespeichert. Wenn der NameNode ausfällt, kann der gesamte HDFS-Systemcluster nicht verwendet werden; wenn die auf dem NameNode aufgezeichneten Daten gehen verloren, die gesamten Daten, die von allen DataNodes im Cluster gespeichert werden, sind unbrauchbar.
Daher ist die hohe Verfügbarkeit und Fehlertoleranz des NameNode sehr wichtig. NameNode bietet Hochverfügbarkeitsdienste in einem Master-Slave-Hot-Standby-Modus:
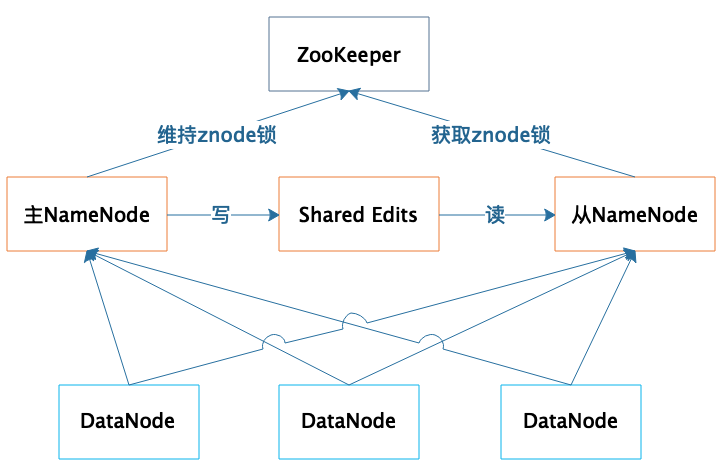
Der Cluster stellt zwei NameNode-Server bereit:
- Einer dient als Master-Server
- Einer als Slave-Server für Hot Backup
Die beiden Server werden von Zk ausgewählt, hauptsächlich durch den Wettbewerb um Znode-Lock-Ressourcen, um zu entscheiden, wer der Master-Server ist. Der DataNode sendet Heartbeat-Daten gleichzeitig an beide NameNodes, aber nur der primäre NameNode kann Steuerinformationen an den DataNode zurückgeben.
Während des normalen Betriebs werden die Metadateninformationen des Dateisystems zwischen den Master- und Slave-NameNodes durch gemeinsame Bearbeitungen eines gemeinsam genutzten Speichersystems synchronisiert. Wenn der primäre NameNode-Server ausfällt, wird der sekundäre NameNode durch ZooKeeper zum primären Server aktualisiert und sichergestellt, dass die Metadateninformationen des HDFS-Clusters, d. h. die Informationen der Dateizuordnungstabelle, vollständig und konsistent sind.
Das Softwaresystem mit schlechter Leistung kann für Benutzer akzeptabel sein; eine schlechte Benutzererfahrung kann auch toleriert werden. Ist die Verfügbarkeit jedoch schlecht, wird es ärgerlich, wenn es häufig ausfällt und nicht verfügbar ist, gehen wichtige Daten verloren, dann wird die Entwicklung zum Großereignis.
Verteilte Systeme können an vielen Stellen ausfallen: Arbeitsspeicher, CPU, Motherboard und Festplatten werden beschädigt, Server fallen aus, das Netzwerk wird unterbrochen und der Computerraum wird abgeschaltet. All dies kann dazu führen, dass das Softwaresystem lahmgelegt wird nicht verfügbare oder sogar permanente Daten verloren.
Daher müssen Softwareingenieure beim Entwerfen eines verteilten Systems die Usability-Strings straffen und darüber nachdenken, wie sichergestellt werden kann, dass das gesamte Softwaresystem unter verschiedenen möglichen Fehlerbedingungen immer noch verfügbar ist.
6 Strategien zur Sicherstellung der Systemverfügbarkeit
redundante Sicherung
Für jedes Programm und alle Daten muss mindestens eine Sicherung vorhanden sein, d. h. das Programm muss auf mindestens zwei Servern bereitgestellt werden, und die Daten müssen auf mindestens einem anderen Server gesichert werden. Darüber hinaus werden kleine Internetunternehmen mehrere Rechenzentren aufbauen, und die Rechenzentren werden sich gegenseitig sichern. Benutzeranfragen können an jedes Rechenzentrum verteilt werden, was das sogenannte Remote Multi-Active ist Naturkatastrophen ist die Hochverfügbarkeit der Anwendungen weiterhin gewährleistet.
Failover
Wenn auf das Programm oder die Daten, auf die zugegriffen werden soll, nicht zugegriffen werden kann, muss die Zugriffsanforderung an den Server übertragen werden, auf dem sich das Backup-Programm oder die Daten befinden, was auch als Failover bezeichnet wird . Beim Failover sollten Sie auf die Erkennung des Ausfalls achten: In dem Szenario, in dem Master- und Slave-Server die gleichen Daten wie NameNode verwalten, wenn der Slave-Server irrtümlicherweise denkt, dass der Master-Server ausgefallen ist und das Cluster-Management übernimmt, übernimmt der Master und Slave-Server werden gemeinsam Anweisungen an den DataNode senden, was wiederum zu einer Cluster-Verwirrung führt, einem sogenannten "Split Brain". Das ist auch der Grund, warum in solchen Szenarien ZooKeeper bei der Wahl des Masterservers eingeführt wird. Wie ZooKeeper funktioniert, werde ich später analysieren.
herabstufen
Wenn eine große Anzahl von Benutzeranforderungen oder Datenverarbeitungsanforderungen eintrifft, ist es aufgrund begrenzter Rechenressourcen möglicherweise nicht möglich, eine so große Anzahl von Anforderungen zu verarbeiten, was zu einer Erschöpfung der Ressourcen und einem Systemabsturz führt. In diesem Fall können einige Anforderungen abgelehnt werden, dh Strombegrenzung , einige Funktionen können auch deaktiviert werden, um den Ressourcenverbrauch zu verringern, dh heruntergestuft werden . Stromdrosselung ist ein übliches Merkmal von Internetanwendungen, da Sie nicht vorhersagen können, wann plötzlich der Zugriffsverkehr eintrifft, der die Lastkapazität überschreitet, und sich daher im Voraus vorbereiten müssen.Wenn Sie auf plötzliche Spitzenlasten stoßen, können Sie sofort mit der Stromdrosselung beginnen. Das Downgrade wird in der Regel für vorhersehbare Szenarien, wie beispielsweise die „Double Eleven"-Werbung des E-Commerce vorbereitet. Um den normalen Betrieb der Kernfunktionen der Anwendung während der Aktion, wie beispielsweise der Bestellfunktion, sicherzustellen, kann das System sein heruntergestuft und geschlossen Unwichtige Funktionen, wie zB Produktbewertungsfunktionen.
Zusammenfassen
Wie HDFS eine hohe Kapazität, schnelle und zuverlässige Speicherung und Zugriff auf Daten durch große verteilte Servercluster erreicht.
1. Die Dateidaten werden in Datenblöcke unterteilt, und die Datenblöcke können auf jedem DataNode-Server im Cluster gespeichert werden, sodass die in HDFS gespeicherten Dateien sehr groß sein können und eine Datei theoretisch alle Festplatten des gesamten HDFS belegen kann Server-Cluster Massenspeicher.
2. Der allgemeine Zugriffsmodus von HDFS besteht darin, das MapReduce-Programm während des Rechnens durchzulesen, und MapReduce liest die Eingabedaten in Shards.Normalerweise ist ein Shard ein Datenblock, und jedem Datenblock wird ein Rechenprozess zugeordnet, damit er dies kann gleichzeitig gestartet werden Viele Prozesse greifen gleichzeitig auf mehrere Datenblöcke einer HDFS-Datei zu und realisieren so einen Hochgeschwindigkeits-Datenzugriff. Auf den konkreten Verarbeitungsprozess von MapReduce gehen wir später in der Kolumne näher ein.
3. Die vom DataNode gespeicherten Datenblöcke werden repliziert, sodass jeder Datenblock mehrere Backups im Cluster hat, was die Zuverlässigkeit der Daten gewährleistet und die Hochverfügbarkeit der Hauptkomponenten im HDFS-System durch eine Reihe von realisiert Fehlertoleranzmethoden, und stellen Sie dann eine hohe Verfügbarkeit der Daten und des gesamten Systems sicher.