Directorio de artículos
Preámbulo
Como nueva juventud contemporánea, ¿debería ser capaz de hacer videos cortos más o menos?

Jaja, ese creador contemporáneo de auto-medios es bueno ~
¿Con qué frecuencia necesitas algunos sonidos divertidos al hacer un video? ¿O sonidos extraños? música espera~
Qué tan lenta es la descarga una por una, usaremos python para lograr la descarga por lotes hoy ~
entorno/módulo/objetivo
1. Metas

2. Entorno de desarrollo
Hermanos, si recién están aprendiendo Python, no instalen ningún otro software, solo instalen estos dos ~
Python 环境
Pycharm 编辑器
3. Módulo
Los módulos utilizados esta vez son principalmente estos dos
requests # 数据请求模块
re # 正则表达式模块
Explicación del proceso
Esta vez escribí el proceso en detalle, del tipo que Xiaobai puede entender. Después de leerlo, todos recuerdan a Sanlian, dame un poco de motivación para crear, jeje ~

Primero, abrimos el sitio web, hacemos clic con el botón derecho, seleccionamos verificar
 , seleccionamos red , actualice la página y desplácese hacia abajo. Aparecerá una página de la página 4 y la página 5.
, seleccionamos red , actualice la página y desplácese hacia abajo. Aparecerá una página de la página 4 y la página 5.
 Muchos datos en estas dos páginas están disponibles directamente aquí. Busquemos cualquiera y hagamos clic para reproducir, luego haga clic en multimedia. Habrá un archivo de audio en los encabezados, que es la dirección de descarga que marqué.
Muchos datos en estas dos páginas están disponibles directamente aquí. Busquemos cualquiera y hagamos clic para reproducir, luego haga clic en multimedia. Habrá un archivo de audio en los encabezados, que es la dirección de descarga que marqué.
 Puedes reproducirlo directamente o descargarlo
Puedes reproducirlo directamente o descargarlo
 directamente ¿Qué pasa si quieres obtener esta dirección?
directamente ¿Qué pasa si quieres obtener esta dirección?
Copiamos directamente esta cadena de números, como 32716, y luego hacemos clic en el cuadro de búsqueda en la esquina superior izquierda para buscar.
 Después de buscar, podemos ver que la página 5 tiene la dirección del enlace de audio aquí.
Después de buscar, podemos ver que la página 5 tiene la dirección del enlace de audio aquí.
 Los encabezados de audio también se pueden encontrar aquí.
Los encabezados de audio también se pueden encontrar aquí.

Luego hacemos clic en los encabezados y enviamos una solicitud directamente a esta dirección URL.

Primero importa el módulo de solicitudes
import requests
url es el enlace justo ahora
url = 'https://手动替换一下/search/word-/page-5'
Luego agregamos un encabezado para disfrazar
Simplemente copie el contenido del agente de usuario debajo de los encabezados aquí, solo
 recuerde agregar comillas
recuerde agregar comillas
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
Luego envía la solicitud, imprímela para ver el resultado
response = requests.get(url=url, headers=headers)
print(response.text)
Hay demasiado contenido impreso, buscamos MP3 directamente en él y lo localizamos con precisión, su título está en el enlace debajo del archivo mp3.
 Luego lo copiamos, usamos el regular para que coincida con el contenido del medio y reemplazamos la URL del medio con (.*?).
Luego lo copiamos, usamos el regular para que coincida con el contenido del medio y reemplazamos la URL del medio con (.*?).
Primero importa el módulo re
import re
¿Simplemente copió el contenido, .*? Rodéalo con paréntesis.
Para hacer coincidir desde response.text, el contenido coincidente es recibido por la variable play_url_list.
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
Luego imprímelo para ver si hay una coincidencia.
print(play_url_list)
Puede ver que el archivo mp3 coincide directamente y se incluye en una lista.
 Luego también necesitamos su nombre de título y copiarlo también.
Luego también necesitamos su nombre de título y copiarlo también.  ¿O la misma operación, reemplazar la url y el nombre con .*?
¿O la misma operación, reemplazar la url y el nombre con .*?
Para hacer coincidir desde respuesta.texto, el contenido coincidente es recibido por la variable name_list.
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
Imprímelo
print(name_list)
Se puede ver que se han obtenido los datos del nombre.
 Recorra, empaquete los datos obtenidos, extráigalos uno por uno, obtenga un contenido de datos binarios y use la variable mp3_content para recibirlo.
Recorra, empaquete los datos obtenidos, extráigalos uno por uno, obtenga un contenido de datos binarios y use la variable mp3_content para recibirlo.
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
Luego guárdelo directamente, con abrir, déle el nombre de una carpeta, agregue el nombre, agregue el sufijo de .mp3, modo de guardado = wb, use la variable f.write para recibir mp3_content
with open('音效\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
No hemos escrito para crear automáticamente una carpeta aquí, por lo que debe crear manualmente una carpeta y luego escribir el nombre que nombró en ella.
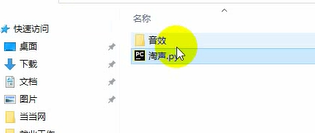
Luego lo imprimimos y vemos el resultado.
print(name)
 El contenido de datos relevante se guarda en la carpeta que creó
El contenido de datos relevante se guarda en la carpeta que creó

Nota: Puede reemplazar manualmente todas las URL usted mismo. Las eliminaré aquí, de lo contrario, se eliminarán por error.
todo el código
import requests
import re
url = 'https://这里大家自己替换一下/search/word-/page-5'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# print(response.text)
play_url_list = re.findall('<div class="ui360 ui360-vis"><a href="(.*?)"></a></div>', response.text)
name_list = re.findall('<a class="h6 text-white font-weight-bold" target="_blank" href=".*?" title="(.*?)">.*?</a>', response.text)
print(play_url_list)
print(name_list)
for play_url, name in zip(play_url_list, name_list):
mp3_content = requests.get(url=play_url, headers=headers).content
with open('音效\\' + name + '.mp3', mode='wb') as f:
f.write(mp3_content)
print(name)
Hermanos, el compartir de hoy está aquí, escápate ~
Recuerda dar me gusta y favoritos, dame motivación ~
