Haga clic en la tarjeta a continuación para seguir la cuenta pública " CVer "
Productos secos pesados AI/CV, entregados lo antes posible
Autor: Feilong Chen et al.
Reimpreso de: Heart of the Machine | Editor: Chen Ping
Conoce los últimos avances y nuevas áreas en el preentrenamiento visión-lenguaje en este artículo.
Lograr que las máquinas respondan de manera similar a los humanos siempre ha sido el objetivo de la investigación en IA. Con el fin de dotar a las máquinas de la capacidad de percibir y pensar, los investigadores han realizado una serie de estudios relacionados, como el reconocimiento facial, la comprensión lectora y el diálogo hombre-máquina, a través de estas tareas para entrenar y evaluar la inteligencia de las máquinas en aspectos específicos. Por lo general, los expertos en el dominio crean conjuntos de datos estándar a mano y luego entrenan y evalúan modelos relevantes en esos conjuntos de datos. Sin embargo, debido a las limitaciones de las tecnologías relacionadas, los modelos de entrenamiento a menudo requieren una gran cantidad de datos etiquetados para obtener modelos mejores y más potentes.
Los modelos preentrenados basados en la arquitectura Transformer solucionan este problema. Primero se entrenan previamente a través del aprendizaje autosupervisado para entrenar modelos a partir de datos no etiquetados a gran escala, y así aprenden una representación general. Pueden lograr resultados sorprendentes cuando se ajustan en tareas posteriores utilizando solo una pequeña cantidad de datos etiquetados manualmente. Desde que se aplicó BERT a las tareas de PNL, varios modelos preentrenados se han desarrollado rápidamente en el dominio unimodal, como Vision Transformer (ViT) y Wave2Vec. Un extenso trabajo ha demostrado que son beneficiosos para tareas unimodales posteriores y evitan entrenar nuevos modelos desde cero.
Similar al dominio unimodal, el dominio multimodal también sufre el problema de datos anotados de menor calidad. No podemos evitar preguntar, ¿se pueden aplicar los métodos de pre-entrenamiento anteriores a tareas multimodales? Los investigadores han explorado esta pregunta y han logrado avances significativos.
En este artículo, investigadores del Instituto de Automatización, la Academia de Ciencias de China y la Universidad de la Academia de Ciencias de China investigan avances recientes y nuevas áreas en el preentrenamiento de visión y lenguaje (VLP), incluido el preentrenamiento de imagen y texto y video- preentrenamiento de texto . VLP aprende la correspondencia semántica entre diferentes modalidades a través del entrenamiento previo en datos a gran escala. Por ejemplo, en el preentrenamiento de imagen y texto, los investigadores esperan que el modelo asocie los perros en el texto con las apariencias de los perros en las imágenes. En el preentrenamiento de video-texto, los investigadores esperan que el modelo asigne objetos/acciones en texto a objetos/acciones en video.

Dirección en papel: https://arxiv.org/abs/2202.09061
Para lograr este objetivo, los investigadores deben diseñar inteligentemente objetos VLP y arquitecturas modelo para permitir que el modelo extraiga asociaciones entre diferentes modalidades.
Para brindar a los lectores una mejor comprensión general de VLP, este estudio primero revisa su progreso reciente desde cinco aspectos: extracción de características, arquitectura del modelo, objetivos de capacitación previa, conjuntos de datos de capacitación previa y tareas posteriores . Luego, el artículo resume el modelo VLP específico en detalle. Finalmente, el artículo analiza la nueva frontera de VLP. Se entiende que esta es la primera encuesta en el campo de VLP. Los investigadores esperan que esta encuesta pueda arrojar luz sobre futuras investigaciones en el campo de VLP.
Descripción general de los VLP
Una revisión de cinco aspectos de VLP y su progreso reciente
En términos de procesamiento de funciones : el documento presenta principalmente cómo el modelo VLP preprocesa y representa imágenes, videos y textos para obtener las funciones correspondientes.
Para aprovechar al máximo los modelos preentrenados unimodales, VLP inicializa aleatoriamente los codificadores de transformador estándar para generar representaciones visuales o textuales. Hablando visualmente, VLP codifica ViT-PF con transformadores visuales preentrenados como ViT y DeiT. En términos de texto, VLP utiliza un transformador de texto previamente entrenado (como BERT) para codificar características de texto. Para simplificar, el estudio nombró a estos transformadores Xformer.
En términos de arquitectura del modelo : el documento presenta la arquitectura del modelo VLP desde dos perspectivas diferentes: (1) desde la perspectiva de la fusión multimodal para observar las arquitecturas de flujo único y doble (2) desde el diseño de la arquitectura general para comparar la comparación de dispositivos codificadores y codificadores-decodificadores.
Una arquitectura de flujo único se refiere a combinar características textuales y visuales y alimentarlas en un solo bloque transformador, como se muestra en la Figura 1 (a) a continuación. La arquitectura de flujo único fusiona entradas multimodales al agrupar la atención. La arquitectura de flujo único es más eficiente en cuanto a parámetros porque ambos modos utilizan el mismo conjunto de parámetros.
La arquitectura de dos flujos significa que las características textuales y visuales no se combinan, sino que se introducen en dos bloques de transformadores diferentes de forma independiente, como se muestra en la Fig. 1(b). Los dos bloques de transformadores no comparten parámetros. Para un mayor rendimiento, se utiliza la atención cruzada (que se muestra con la línea discontinua en la figura 1 (b)) para lograr interacciones intermodales. Para una mayor eficiencia, también se puede omitir la atención cruzada entre los bloques de transformadores visuales y los bloques de transformadores de texto.
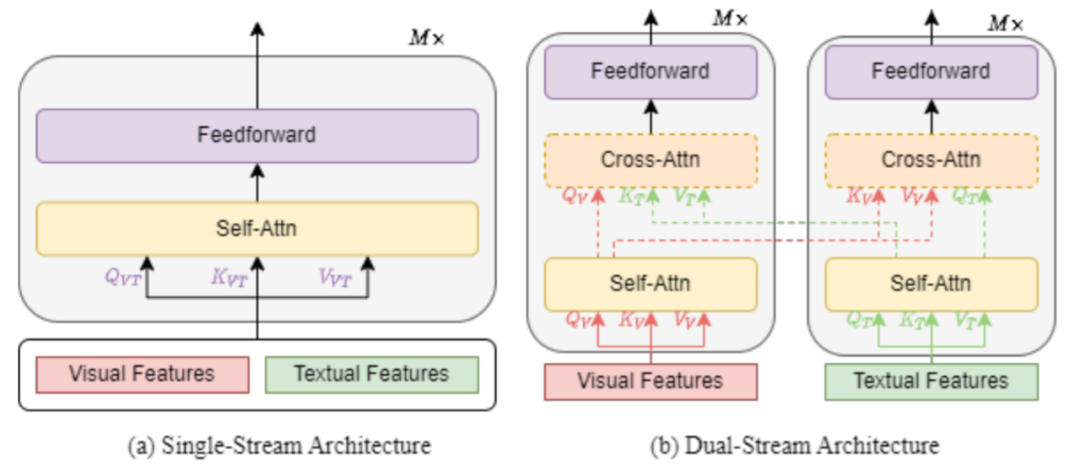
Muchos modelos VLP solo emplean una arquitectura de codificador , con diferentes representaciones modales alimentadas directamente a la capa de salida. Por el contrario, otros modelos de VLP abogan por el uso de una arquitectura de codificador-decodificador de transformador, donde las diferentes representaciones modales se introducen primero en el decodificador y luego en la capa de salida.
En términos de objetivos de precapacitación : el documento preentrena el modelo VLP utilizando diferentes objetivos de precapacitación y resume los objetivos de precapacitación en cuatro categorías: finalización, coincidencia, tiempo y tipo específico .
La finalización se refiere a la reconstrucción de elementos enmascarados a partir de partes no enmascaradas. Tome como ejemplo el modelado de lenguaje enmascarado (MLM), que fue propuesto por primera vez por taylor y es ampliamente conocido como BERT como una tarea previa al entrenamiento. El MLM en el modelo VLP es similar al MLM en el modelo de lenguaje preentrenado (PLM), que no solo puede predecir el token de texto enmascarado del resto de los tokens de texto, sino también predecir el token de texto enmascarado del token visual. Como regla general, un modelo VLP que sigue a BERT enmascara aleatoriamente cada token de entrada de texto con una tasa de enmascaramiento del 15 % y usa un token especial [MASK] el 80 % de las veces, un token de texto aleatorio el 10 % de las veces, y el 10% de tiempo restante usa el token original para reemplazar el texto enmascarado. Sin embargo, en el artículo "¿Debe enmascarar el 15 % en el modelado de lenguaje enmascarado?", de Chen Danqi y otros, de la Universidad de Princeton, los autores descubrieron que, con un esquema de precapacitación eficaz, podían enmascarar entre el 40 % y el 50 % del texto de entrada. y obtener mejores resultados que el predeterminado. 15% mejor rendimiento aguas abajo.
En Modelado de visión enmascarada (MVM), como MLM, MVM toma muestras de una región o parche visual (imagen o video) y enmascara sus características visuales, generalmente con un 15% de probabilidad. El modelo VLP necesita reconstruir las características visuales de la máscara dadas las características visuales restantes y todas las características textuales.
La correspondencia visión-lenguaje (VLM) es el objetivo de preentrenamiento más utilizado para alinear la visión y el lenguaje. En el modelo VLP de flujo único, usamos una representación de token especial [CLS] como una representación fusionada de las dos modalidades. En el modelo VLP de dos flujos, concatenamos la representación visual del token de visión especial [CLSV] y la representación textual del token de texto especial [CLST] como una representación fusionada de las dos modalidades. El modelo VLP alimenta la representación fusionada de las dos modalidades a la capa FC y la función sigmoidea para predecir una puntuación entre 0 y 1, donde 0 representa una discrepancia visual y lingüística y 1 representa una coincidencia visual y lingüística. Durante el entrenamiento, el modelo VLP toma muestras de pares positivos o negativos del conjunto de datos en cada paso.
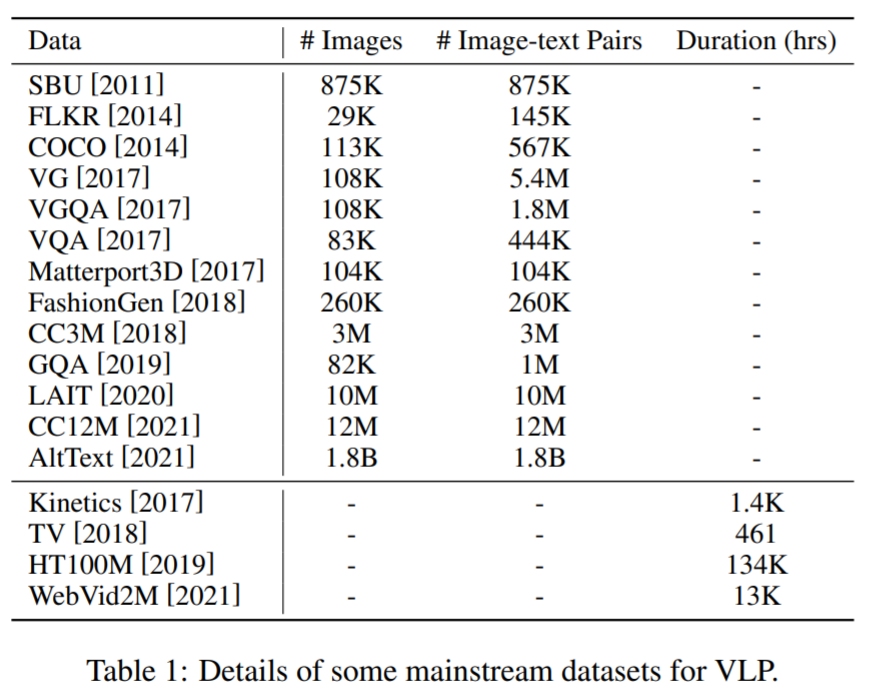
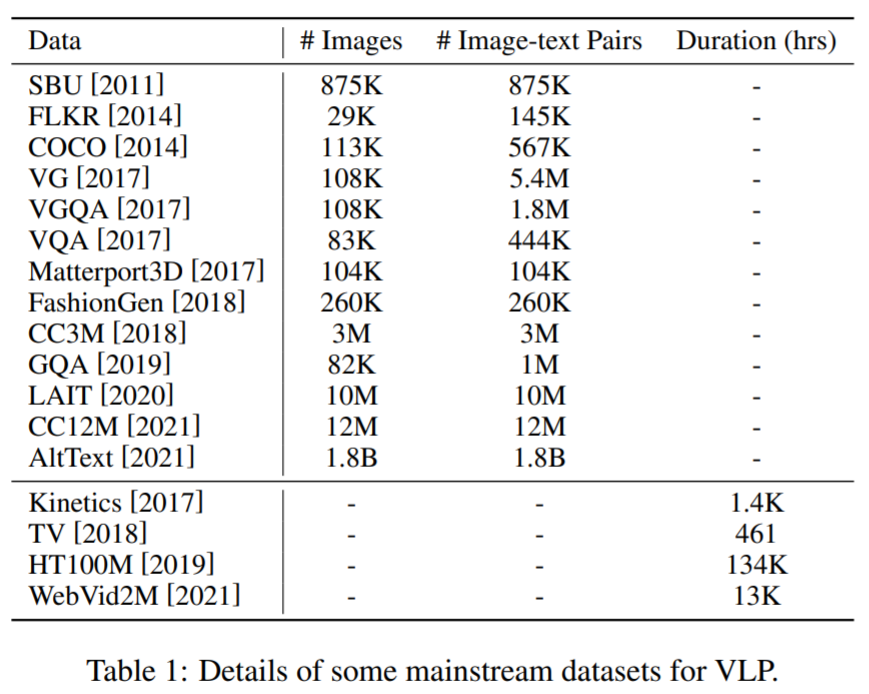
En términos de conjuntos de datos de preentrenamiento : la mayoría de los conjuntos de datos para VLP se construyen combinando conjuntos de datos públicos en tareas multimodales. Aquí, algunos corpus principales y sus detalles se muestran en la Tabla 1 a continuación.
En términos de tareas posteriores : una amplia variedad de tareas requieren la fusión de conocimientos visuales y lingüísticos. Esta subsección del documento presenta los detalles básicos y los objetivos de tales tareas y las divide en cinco categorías: clasificación, regresión, recuperación, generación y otras tareas , donde las tareas de clasificación, regresión y recuperación también se conocen como tareas de comprensión.
Entre las tareas de clasificación , incluye Respuesta Visual a Preguntas (VQA), Razonamiento Visual y Respuesta Sintética a Preguntas (GQA), Razonamiento Visual-Lingüístico (VLI), Razonamiento Visual en Lenguaje Natural (NLVR), Razonamiento Visual de Sentido Común (VCR), etc. En VQA, se proporciona una entrada visual de imagen o video, generalmente se considera como una tarea de clasificación, y el modelo predice la respuesta más adecuada de un grupo de opciones; en GQA, podemos considerar GQA como una versión mejorada de VQA, con el objetivo de Investigación avanzada sobre el razonamiento visual en escenas naturales; en VLI, dado un videoclip con subtítulos alineados como premisa, junto con una hipótesis de lenguaje natural basada en el contenido del video, el modelo necesita inferir si esa hipótesis contradice el videoclip dado.
En tareas de regresión , el análisis de sentimiento multimodal (MSA) tiene como objetivo detectar emociones en videos utilizando señales multimodales como la visión, el lenguaje, etc. Se utiliza como una variable de intensidad continua para predecir la dirección emocional de los enunciados.
Entre las tareas de recuperación , Vision-Linguistic Retrieval (VLR) comprende la visión (imagen o video) y el lenguaje a través de una estrategia de coincidencia adecuada, que consta de dos subtareas, recuperación de visión a texto y recuperación de texto a visual, donde la visión- la recuperación de texto es Obtener las descripciones textuales más relevantes de un conjunto de descripciones más grande basado en la visión y viceversa.
En las tareas generativas , los subtítulos visuales (VC) tienen como objetivo generar descripciones textuales semántica y sintácticamente apropiadas para una entrada visual (imagen o video) determinada. Además, el documento presenta otras tareas posteriores, como la traducción automática multimodal (MMT), la navegación de lenguaje visual (VLN) y el reconocimiento óptico de caracteres (OCR).
Modelo SOTA VLP
Modelo VLP de imagen-texto . VisualBERT, conocido como el primer modelo preentrenado de imagen y texto, utiliza Faster R-CNN para extraer características visuales, concatena características visuales e incrustaciones de texto, y alimenta las características concatenadas en un solo transformador inicializado por BERT. Muchos modelos de VLP siguen una extracción de características y una arquitectura similares a las de VisualBERT cuando se ajustan los objetivos de preentrenamiento y los conjuntos de datos de preentrenamiento. Recientemente, VLMO aprovecha las incrustaciones de parches de imagen y las incrustaciones de palabras de texto para alimentar las incrustaciones combinadas junto con expertos modales en un solo transformador y lograr un rendimiento impresionante. METER explora cómo usar modelos preentrenados de modalidad única y propone un modelo arquitectónico de dos flujos para manejar la fusión multimodal, logrando un rendimiento de vanguardia en muchas tareas posteriores.
Modelo VLP de video-texto . VideoBERT es conocido como el primer modelo preentrenado de video-texto que amplía el modelo BERT para manejar tanto video como texto. VideoBERT utiliza ConvNet y S3D previamente capacitados para extraer funciones de video y concatenarlas con incrustaciones de palabras de texto, que se alimentan a un transformador inicializado con BERT. Cuando se entrena VideoBERT, ConvNet y S3D se congelan, lo que indica que el método no es de extremo a extremo. Recientemente, inspirados por ViT, Frozen y Region-Learner primero procesan clips de video en cuadros y obtienen incrustaciones de parches de acuerdo con la forma en que ViT procesa cada cuadro de imagen. Frozen y Region-Learner se optimizan y logran el rendimiento de SOTA de manera integral.
La Tabla 2 a continuación resume más modelos convencionales de VLP existentes:
En el futuro, basándose en el trabajo existente, los investigadores esperan que VLP pueda desarrollarse aún más a partir de los siguientes aspectos:
En combinación con la información acústica, la mayoría de los estudios de preentrenamiento multimodal anteriores enfatizaron el modelado conjunto del lenguaje y la visión, ignorando la información oculta en el audio;
El aprendizaje del conocimiento y la cognición, aunque los modelos VLP existentes han logrado un rendimiento notable, esencialmente se ajustan a conjuntos de datos multimodales a gran escala, lo que hace que los modelos VLP tengan más conocimiento es importante para los futuros VLP;
Optimización de sugerencias, mediante el diseño de sugerencias discretas o continuas y el uso de MLM para tareas posteriores específicas, estos modelos pueden reducir el costo computacional de ajustar una gran cantidad de parámetros, cerrando la brecha entre el entrenamiento previo y el ajuste fino.
上面综述PDF下载
后台回复:VLP综述,即可下载上面论文ICCV y CVPR 2021 Descarga de papel y código
Respuesta entre bastidores: CVPR2021, puede descargar los documentos de CVPR 2021 y la colección de documentos de código abierto
Respuesta de antecedentes: ICCV2021, puede descargar los documentos de ICCV 2021 y la colección de documentos de código abierto
Respuesta de fondo: revisión de Transformer, puede descargar las últimas 3 revisiones de Transformer en PDF
Se establece el grupo de intercambio CVer-Transformer
Escanee el código QR a continuación, o agregue WeChat: CVer6666, puede agregar el asistente de CVer WeChat, puede solicitar unirse al grupo de intercambio CVer- Transformer WeChat . Además, se han cubierto otras direcciones verticales: detección de objetos, segmentación de imágenes, seguimiento de objetos, detección y reconocimiento de rostros, OCR, estimación de pose, súper resolución, SLAM, imágenes médicas, Re-ID, GAN, NAS, estimación de profundidad, autónomo conducción, aprendizaje de refuerzo, detección de líneas de carril, poda y compresión de modelos, eliminación de ruido, eliminación de neblina, eliminación de lluvia, transferencia de estilo, imagen de detección remota, reconocimiento de comportamiento, comprensión de video, fusión de imágenes, recuperación de imágenes, comunicación y contribución en papel, PyTorch, TensorFlow y Transformer Wait .
Asegúrese de comentar: dirección de investigación + ubicación + escuela/empresa + apodo (como Transformador + Shanghái + traspaso + Kaká) , de acuerdo con los comentarios de formato, se puede pasar más rápido e invitar al grupo

▲ Escanee el código o agregue WeChat: CVer6666, ingrese al grupo de intercambio
¡Ya está aquí el Grupo de Intercambio Académico CVer (Knowledge Planet)! Si desea conocer los últimos, más rápidos y mejores proyectos de código abierto de alta calidad, tutoriales de aprendizaje, capacitación práctica y otros materiales de CV / DL / ML en papel express, escanee el código QR a continuación para unirse al grupo de intercambio académico CVer, que ha reunido a miles de personas!

▲Escanea el código para ingresar al grupo
▲Haga clic en la tarjeta de arriba para seguir la cuenta oficial de CVer
No es fácil de organizar, dale me gusta y mira![]()