Klicken Sie auf die Karte unten, um dem öffentlichen Konto „ CVer “ zu folgen
AI/CV schwere Trockenware, schnellstmöglich geliefert
In diesem Artikel schlagen Forscher der University of Hong Kong und ByteDance ein neues Transformer-basiertes Framework für die Segmentierung von Referenzvideoobjekten vor, ReferFormer. Es betrachtet die Sprachbeschreibung als Abfragebedingung und findet das Zielobjekt direkt im Video, außerdem wird die Verfolgung des Zielobjekts natürlich durch die Gesamtausgabe der Instanzsequenz ohne jegliche Nachbearbeitung abgeschlossen. ReferFormer erreicht bei allen vier Datensätzen zur Segmentierung von Referenz-Videoobjekten eine hochmoderne Leistung.

Papier: https://arxiv.org/abs/2201.00487
Code: https://github.com/wjn922/ReferFormer
Einleitung
Die Segmentierung von referenzierenden Videoobjekten (RVOS) ist eine aufkommende und herausfordernde multimodale Aufgabe, die eine Instanzsegmentierung von Referenzobjekten erfordert, auf die durch Text in Videos verwiesen wird.
Bei der derzeit umfassend untersuchten Aufgabe zur Referenzbildsegmentierung (RIS) basiert die Textbeschreibung normalerweise auf den Erscheinungsmerkmalen oder der räumlichen Beziehung des Ziels, während die RVOS-Aufgabe die vom Ziel durchgeführte Aktion beschreiben kann, was erfordert, dass das Modell über a verfügt stärker Verglichen mit der herkömmlichen Aufgabe zur Videoobjektsegmentierung(VOS) hat die RVOS-Aufgabe nicht den wahren Wert des gegebenen Segmentierungszielsin der Vorhersagestufe.Dies erhöht die Schwierigkeit, das Ziel richtig und fein zu segmentieren.
Bestehende RVOS-Methoden verlassen sich oft auf komplexe mehrstufige Frameworks, um die Konsistenz der Segmentierungsziele sicherzustellen. Um die oben genannten Probleme zu lösen, haben Forscher der University of Hong Kong und ByteDance ein End-to-End-RVOS-Framework basierend auf Transformer - ReferFormer vorgeschlagen, das die Sprachbeschreibung als Abfragebedingung verwendet und sich nur auf das Referenzziel in konzentriert Die Zielverfolgung kann erreicht werden, indem entsprechende Abfragen auf verschiedenen Frames ohne Nachbearbeitung verbunden werden. Das Modell erreicht auf vier RVOS-Datensätzen (Ref-Youtube-VOS, Ref-DAVIS17, A2D-Sentences, JHMDB-Sentences) eine State-of-the-Art-Performance.
Methoden-Highlights:
- Vorschlag eines einfachen und einheitlichen Transformer-basierten End-to-End-RVOS-Frameworks ohne Nachbearbeitung;
- Verwenden Sie Sprachbeschreibungen als Einschränkungen für Abfragen, damit Aufgaben mit einer kleinen Anzahl von Abfragen abgeschlossen werden können.
- Leistung auf dem neuesten Stand der Technik bei allen vier RVOS-Aufgabendatensätzen erreicht.
Methode
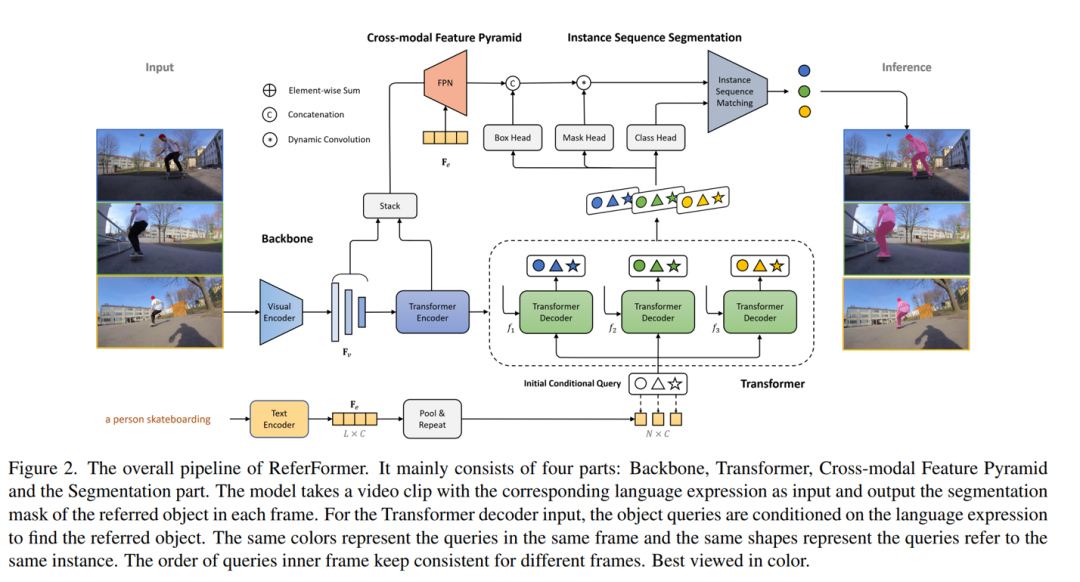
Abbildung 1 Gesamtstruktur des Netzwerks
Das Netzwerk besteht hauptsächlich aus vier Teilen: Backbone, Transformer, modalübergreifender FPN und Teil zur Generierung der Instanzsegmentierung.
Backbone.Das Netz verwendet zuerst den visuellen Codierer, um die Merkmale jedes Rahmensaus dem Video zu extrahieren, und verwendet den Textcodierer, um die durch den Textbeschriebenen Sprachmerkmale zu erhalten.Der Vektor, der erhalten wird, nachdem das Merkmal durchschnittlich zusammengelegtwurde, ist das Satzmerkmal.
Transformer : Der Transformer-Encoder wird verwendet, um die Multiskalenmerkmale von Videoframes weiter zu modellieren; im Decoderteil werden N lernbare Merkmale als Abfragen definiert und für alle Frames geteilt. Gleichzeitig werden die obigen Satzmerkmale N-mal repliziert, und die Abfrage- und Satzmerkmale werden gemeinsam als Eingabe des Decoders verwendet. Auf diese Weise konzentrieren sich alle Abfragen nur auf das Zielobjekt unter der Führung der Sprache, daher nennt dieses Papier diese Abfrage "bedingte Abfrage (bedingte Abfrage)". Dank dieses Designs kann das Modell mit einer kleinen Anzahl von Abfragen (standardmäßig 5) gute Ergebnisse erzielen. Schließlich werden durch das Zusammenwirken von Abfrage und visuellen Merkmalen im Decoder N Darstellungen erhalten, die Zielinformationen enthalten, und zwar für jedes Einzelbild, und für das gesamte Video gibt es insgesamt Nq Darstellungen.
Cross-modal FPN : In diesem Teil führen visuelle Merkmale und Textmerkmale mehrskalige und feinkörnige Interaktionen in Form gegenseitiger Aufmerksamkeit durch, wodurch bessere Segmentierungsergebnisse erzielt werden können. In diesem Prozess generiert FPN semantisch reichhaltige, hochauflösende Feature-Maps, die an nachfolgende Segmentierungsmodule gesendet werden.
Instanzsegmentierungs-Erzeugungsteil Für die N Darstellungen, die auf jedem obigen Rahmen erhalten werden, werden zuerst ihre entsprechenden binären Klassifikationswahrscheinlichkeits-, Bounding-Box- und dynamischen Faltungskernparameter durch Klassenkopf, Boxkopf bzw. Maskenkopf erzeugt. Der Begrenzungsrahmen wird dem Ausgabemerkmal von FPN als relatives Koordinatenmerkmal hinzugefügt, und die jeder Abfrage entsprechende Faltungsmerkmalskarte wird erhalten. Die Generierung der Zielmaske wird durch dynamische Faltung erhalten:
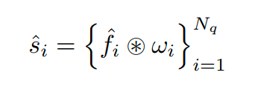
Training und Vorhersage : Die Abfrage an der entsprechenden Position in jedem Rahmen verfolgt dieselbe Instanz (dargestellt durch dieselbe Form in der Figur), und durch Verbinden der entsprechenden Abfragen können die zu derselben Instanz gehörenden Sequenzen erhalten werden, so dass jedes Ziel können ohne Nachbearbeitung natürlich verarbeitet werden. In der Trainings- und Prädiktionsphase wird die Instanzsequenz als Ganzes für die Überwachung und Ausgabe betrachtet.
Da in der Trainingsphase nur ein Zielobjekt im Video vorhanden ist, wird der Mindestkostenabgleich verwendet, um positive Abtastwerte zuzuweisen.Die Verlustfunktionen umfassen binären Klassifikationsverlust, Begrenzungsrahmenverlustund Maskenverlust:
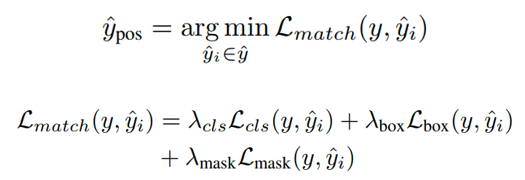
In der Vorhersagephase ist die Eingabe ein ganzes Video. Berechnen Sie zuerst die durchschnittliche Punktzahl jeder Instanzsequenz auf allen Frames, wählen Sie die Instanzsequenz mit der höchsten Punktzahl aus, ihr Index ist σ, und geben Sie ihre entsprechende Maskensequenz aus.
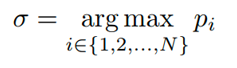
Demo
Das Folgende zeigt den Segmentierungseffekt des Modells in mehreren herausfordernden Szenen:
- Ref-DAVIS17
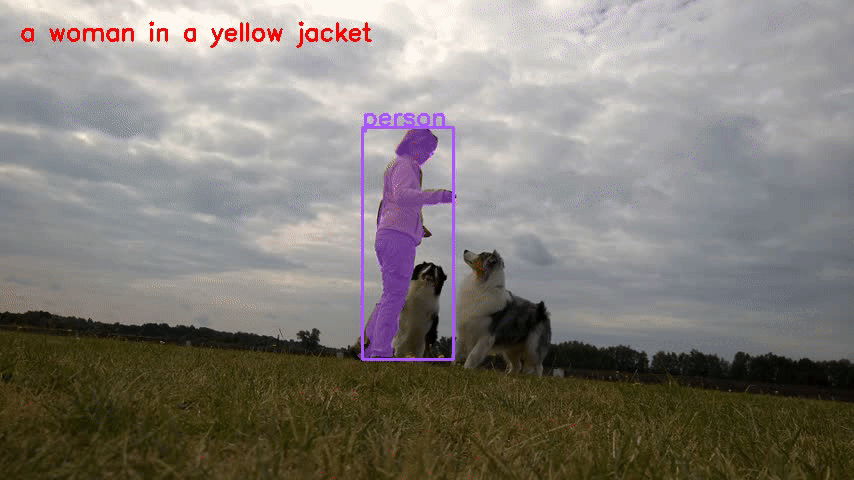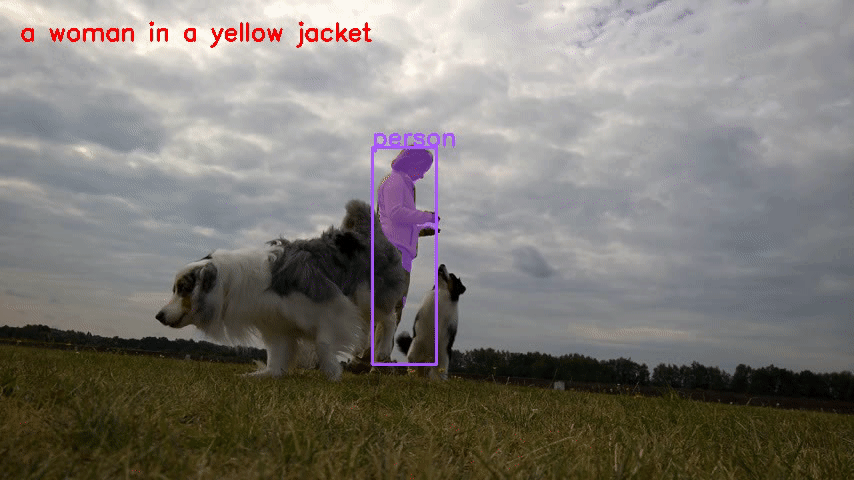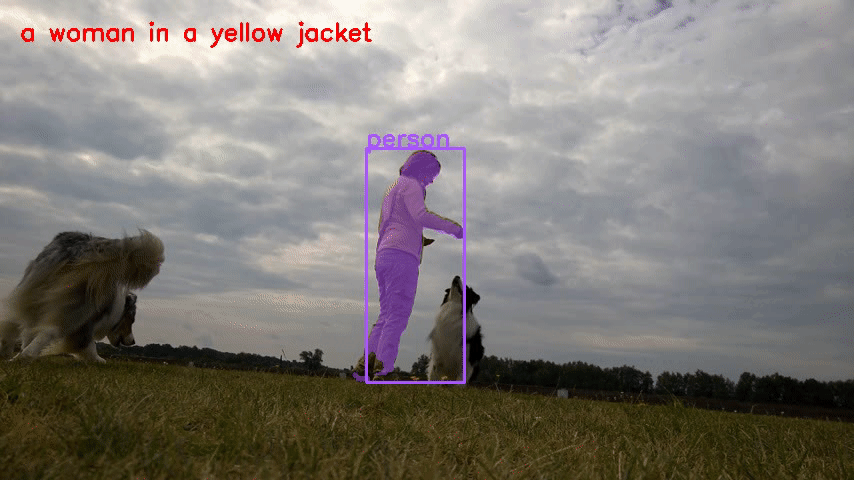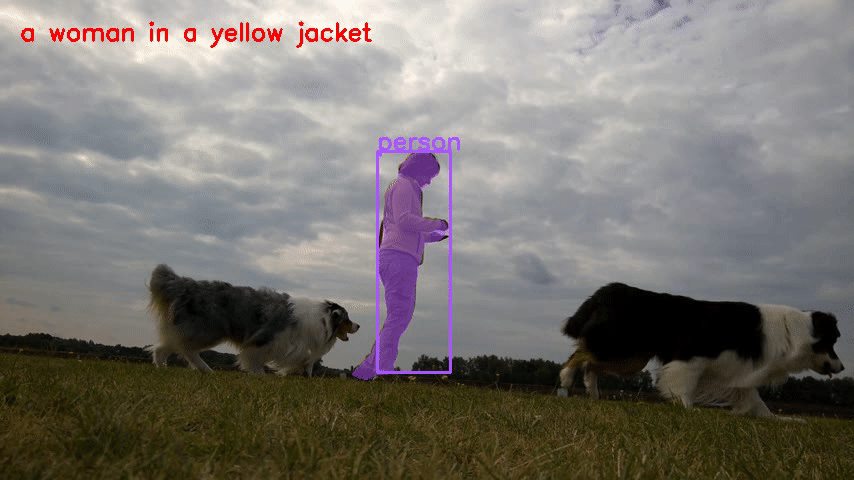
verschließen

Einstellung ändern
- Ref-Youtube-VOS

feine Segmentierung

schnelle Bewegung
Abbildung 2 Visualisierungsanzeige
Leistung
Dieses Papier führt umfangreiche Experimente mit verschiedenen visuellen Encodern durch und erreicht die aktuelle State-of-the-Art-Leistung auf allen vier aktuellen RVOSs. Unter anderem verwendet die Auswertung von Ref-DAVIS17 und JHMDB-Sentences Modelle, die auf Ref-Youtube-VOS bzw. A2D-Sentences trainiert wurden, was die Generalisierungsleistung der Methode belegt.
- Ref-Youtube-VOS & Ref-DAVIS17
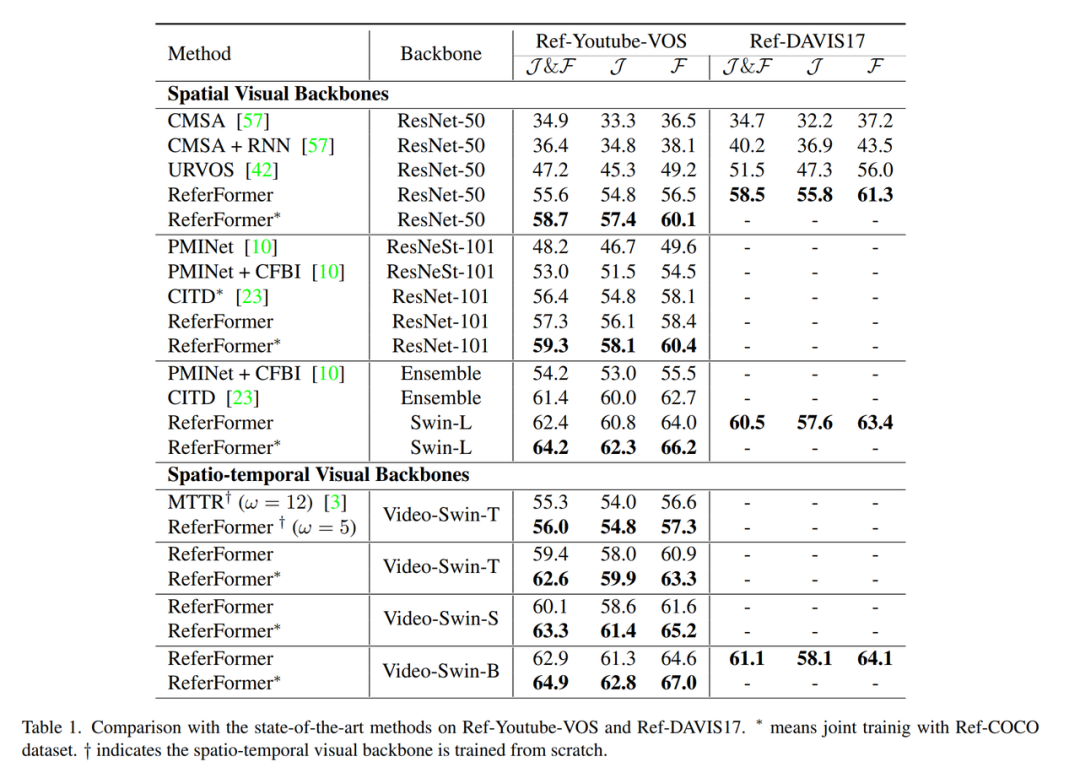
Abbildung 3 Leistungsvergleich der Datensätze Ref-Youtue-VOS und Ref-DAVIS17
- A2D-Sätze & JHMDB-Sätze

Abbildung 4 Leistungsvergleich des A2D-Sentences-Datensatzes
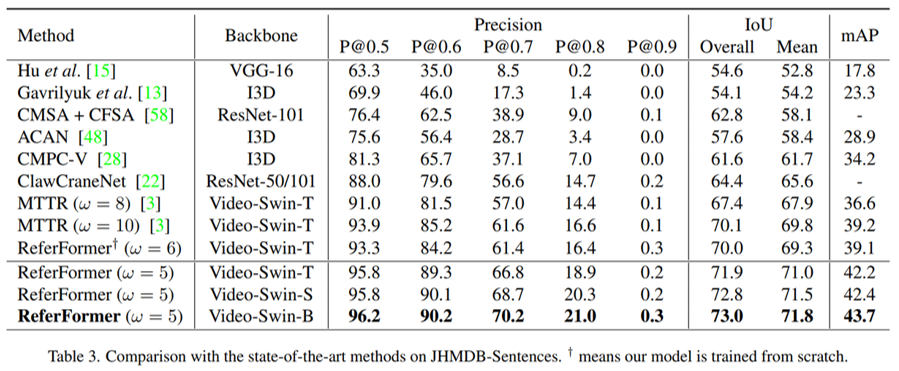
Abbildung 5. Leistungsvergleich des Datensatzes JHMDB-Sentences
abschließend
Dieses Papier schlägt ein einfaches und vereinheitlichtes Referenzvideo-Zielsegmentierungs-Framework vor. Anders als die vorherige komplexe und mehrstufige Pipeline schlägt dieses Papier das Konzept vor, die Sprachbeschreibung als Abfrage zu verwenden, damit sich das Modell genau auf das Zielobjekt konzentrieren kann Gleichzeitig passen sie die natürliche Sequenz durch die Instanzsequenz an.Es vervollständigt die Verfolgung des Ziels und realisiert die End-to-End-Ausgabe.
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看