Comprensión profunda de los principios de implementación de DML de Delta Lake (actualizar, eliminar, fusionar)
Big data de memoria anterior
Delta Lake admite comandos DML, incluidos DELETE, UPDATE y MERGE, lo que simplifica escenarios comerciales como CDC, auditoría, gobernanza y flujo de trabajo GDPR / CCPA. En este artículo, demostraremos cómo usar estos comandos DML, presentaremos la implementación de estos comandos y también presentaremos algunas técnicas de ajuste de rendimiento para los comandos correspondientes.
Delta Lake: principios básicos
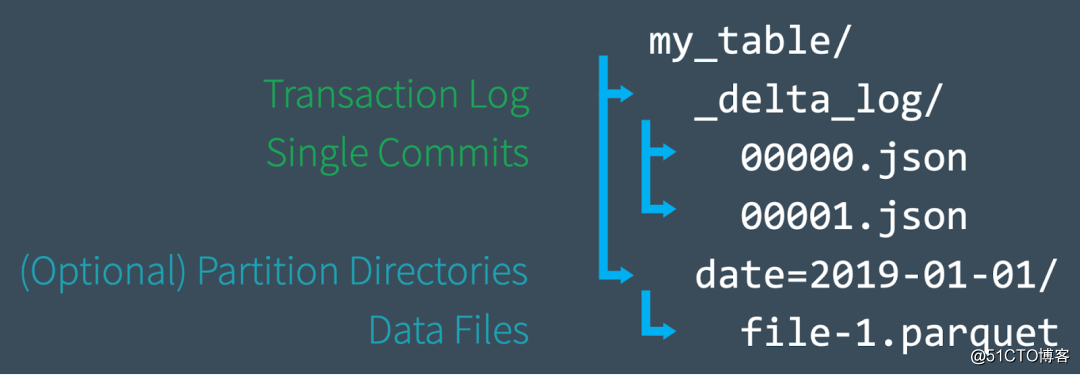
Si recién está aprendiendo sobre Delta Lake, puede leer este capítulo para comprender rápidamente los principios básicos de Delta Lake. Esta sección presenta principalmente la construcción de la tabla Delta Lake a nivel de archivo.
Al crear una nueva tabla, Delta guarda los datos en una serie de archivos Parquet y crea una carpeta _delta_log en el directorio raíz de la tabla, que contiene el registro de transacciones de Delta Lake, y el registro de transacciones ACID registra cada vez que la tabla correspondiente cambio. Cuando modifica la tabla (por ejemplo, agregando nuevos datos o realizando una actualización, fusión o eliminación), Delta Lake guarda el registro de cada nueva transacción como un archivo JSON numerado en la carpeta delta_log, de 00 ... 00000. El nombre json comienza, seguido de 00 ... 00001.json, 00 ... 00002.json, y así sucesivamente; por cada 10 transacciones, Delta también generará un archivo Parquet "checkpoint" en la carpeta delta_log. Este archivo permite nosotros para recrear rápidamente el estado de la mesa.
Finalmente, cuando consultamos la tabla de Delta Lake, primero podemos leer el registro de transacciones para determinar rápidamente qué archivos de datos constituyen la última versión de la tabla, sin tener que listar todos los archivos en el almacenamiento de objetos en la nube, lo que mejora en gran medida el rendimiento de las consultas. Cuando realizamos operaciones DML, Delta Lake creará nuevos archivos en lugar de modificarlos en los archivos originales y usará el registro de transacciones para registrar todas estas operaciones, como qué archivos son nuevos. Si desea saber más sobre esto, puede consultar el artículo "Comprensión detallada de los registros de transacciones de Apache Spark Delta Lake".
Bueno, con la introducción básica anterior, podemos presentar cómo usar el comando DML de Delta Lake y el principio de funcionamiento detrás de él. El siguiente ejemplo usa SQL para operar. Esto requiere que usemos Delta Lake 0.7.0 y Apache Spark 3.0. Para obtener detalles, consulte "Habilitar Spark SQL DDL y DML en Delta Lake".
ACTUALIZAR uso y principios internos
Puede utilizar la operación UPDATE para actualizar de forma selectiva cualquier fila que coincida con una condición de filtro (también conocida como predicado). El siguiente código muestra cómo usar cada tipo de predicado como parte de una instrucción UPDATE. Tenga en cuenta que la actualización de Delta Lake se puede usar en Python, Scala y SQL, pero para el propósito de este artículo, solo usamos SQL para introducir su uso aquí.
-- Update events
UPDATE events SET eventType = 'click' WHERE eventType = 'click'
UPDATE: Under the hoodLa implementación de UPDATE en Delta Lake se divide en dos pasos:
• Primero busque y seleccione aquellos archivos que contienen datos que coinciden con el predicado y necesitan ser actualizados. En este proceso, Delta Lake puede utilizar la tecnología de omisión de datos para acelerar este proceso. La tecnología de salto de datos parece estar disponible solo en el departamento de comercio de la cantidad de ladrillos, y la versión de código abierto parece no haber sido vista.
• Lea cada archivo coincidente en la memoria, actualice la línea relevante y escriba el resultado en un nuevo archivo de datos.
Todo el proceso es el siguiente:
Una vez que Delta Lake ejecute con éxito la ACTUALIZACIÓN, agregará una confirmación al registro de transacciones, lo que indica que el nuevo archivo de datos se utilizará a partir de ahora para reemplazar el antiguo archivo de datos. Sin embargo, el archivo de datos antiguo no se elimina. En su lugar, simplemente se marca como desechado, lo que significa que este archivo solo pertenece a la versión anterior del archivo de datos de la tabla y no a la versión actual del archivo de datos. Delta Lake puede usarlo para proporcionar control de versiones de datos y viajes en el tiempo.
ACTUALIZACIÓN + Viaje en el tiempo de Delta Lake = Fácil depuración
Mantener archivos de datos antiguos es muy útil para la depuración, porque puede usar el viaje en el tiempo de Delta Lake en cualquier momento para volver al historial y consultar la versión anterior de la tabla. Si un día actualizamos accidentalmente la tabla por error y queremos saber qué sucedió, podemos comparar fácilmente las dos versiones de la tabla.
SELECT * FROM events VERSION AS OF 12ACTUALIZACIÓN: ajuste de rendimiento
La forma principal de mejorar el rendimiento del comando UPDATE de Delta Lake es agregar más predicados para reducir el espacio de búsqueda. Cuanto más específica sea la búsqueda, menos archivos Delta Lake necesita escanear y / o modificar.
La versión comercial de Databricks de Delta Lake tiene algunas mejoras empresariales, como la omisión de datos mejorada, el uso de filtros de floración y Optimización de orden Z. Optimización de orden Z reorganiza el diseño de cada archivo de datos para hacer similares Los valores de las columnas están estratégicamente cerca uno del otro para una máxima eficiencia.
BORRAR uso y principios internos
Podemos usar el comando DELETE y eliminar selectivamente cualquier fila según el predicado (condición de filtro).
DELETE FROM events WHERE date < '2017-01-01'Si desea recuperar una operación de eliminación accidental, puede usar el viaje en el tiempo para revertir la tabla a su estado original, como se muestra en el siguiente fragmento de código de Python.
# Read correct version of table into memory
dt = spark.read.format("delta") \
.option("versionAsOf", 4) \
.load("/tmp/loans_delta")
# Overwrite current table with DataFrame in memory
dt.write.format("delta") \
.mode("overwrite") \
.save(deltaPath)
BORRAR: Debajo del capó
ELIMINAR funciona igual que ACTUALIZAR. Delta Lake escanea los datos dos veces: el primer escaneo es para identificar cualquier archivo de datos que contenga filas que coincidan con las condiciones del predicado. El segundo escaneo lee el archivo de datos coincidentes en la memoria. En este momento, Delta Lake elimina las filas relevantes y luego escribe los datos recuperados en un nuevo archivo en el disco.
Después de que Delta Lake complete con éxito la operación de eliminación, los archivos de datos antiguos no se eliminarán; aún permanecen en el disco, pero estos archivos se registran como desechados en el registro de transacciones de Delta Lake (ya no forman parte de la tabla activa). Recuerde, esos archivos antiguos no se eliminarán de inmediato, porque es posible que necesitemos usar la función de viaje en el tiempo para saltar a una versión anterior de los datos. Si desea eliminar archivos que exceden un cierto período de tiempo, puede usar el comando VACÍO.
BORRAR + VACÍO: limpiar archivos antiguos
Ejecute el comando VACÍO para eliminar permanentemente todos los archivos de datos que cumplan las siguientes condiciones:
• ya no forma parte de la tabla activa y
• supera el umbral de retención (el valor predeterminado es siete días).
Delta Lake no elimina automáticamente los archivos antiguos; tenemos que ejecutar el comando VACUUM nosotros mismos, como se muestra a continuación. Si deseamos especificar un período de retención diferente del valor predeterminado, podemos proporcionarlo como parámetro.
from delta.tables import *
# vacuum files not required by versions older than the default
# retention period, which is 168 hours (7 days) by default
dt.vacuum()
deltaTable.vacuum(48) # vacuum files older than 48 hoursNota : Si el tiempo de retención especificado al ejecutar el comando VACUUM es 0 horas, se eliminarán todos los archivos no utilizados en la última versión de la tabla. Asegúrese de que no haya una operación de escritura en la tabla correspondiente cuando ejecute este comando; de lo contrario, podría producirse una pérdida de datos.
DELETE: El ajuste del rendimiento
es el mismo que el comando UPDATE. La forma principal de mejorar el rendimiento de las operaciones DELETE de Delta Lake es agregar más predicados para reducir el espacio de búsqueda. La versión comercial de Delta Lake de Databricks tiene algunas mejoras empresariales, como la omisión de datos mejorada, el uso de filtros de floración y Z-Order Optimize.
Uso de MERGE y principios internos
El comando MERGE de Delta Lake nos permite realizar la semántica de upserts, que en realidad es una mezcla de UPDATE e INSERT. Para entender el significado de upserts, suponga que tenemos una tabla (tabla de destino) y una tabla de origen, que contiene nuevos registros y actualizaciones de los registros existentes. Upsert funciona así:
• Cuando un registro en la tabla de origen coincide con un registro existente en la tabla de destino, Delta Lake actualizará el registro.
• Cuando no hay coincidencia, Delta Lake insertará un nuevo registro.
MERGE INTO events
USING updates
ON events.eventId = updates.eventId
WHEN MATCHED THEN UPDATE
SET events.data = updates.data
WHEN NOT MATCHED THEN
INSERT (date, eventId, data) VALUES (date, eventId, data) El comando MERGE de Delta Lake simplifica enormemente el flujo de trabajo.
FUSIÓN: Debajo del capó
Delta Lake implementa MERGE a través de los siguientes dos pasos:
• Realice una unión interna entre la tabla de destino y la tabla de origen para seleccionar todos los archivos coincidentes.
• Realice una unión externa entre el archivo seleccionado en la tabla de destino y la tabla de origen, y escriba los datos actualizados / eliminados / insertados.
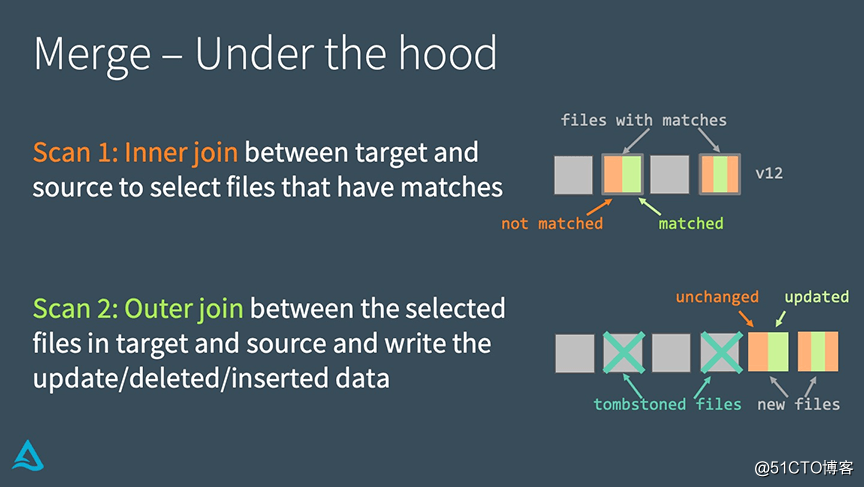
La principal diferencia entre la implementación de MERGE y UPDATE o DELETE es que utiliza join, lo que nos permite utilizar algunas estrategias únicas a la hora de buscar mejorar el rendimiento.
MERGE: ajuste de rendimiento
Para mejorar el rendimiento de ejecución de MERGE, necesitamos comprender cuál de las dos uniones anteriores afecta la ejecución del programa.
Si la unión interna es el cuello de botella de la ejecución de MERGE (por ejemplo, lleva demasiado tiempo encontrar los archivos que deben reescribirse en Delta Lake), entonces podemos usar las siguientes estrategias para resolverlo:
• Agregar más condiciones de filtro para reducir el espacio de búsqueda;
• Ajustar el número de particiones de reproducción aleatoria;
• Ajustar el umbral de unión de transmisión;
• Si hay muchos archivos pequeños en la tabla, podemos comprimirlos y fusionarlos primero; pero no comprímalos demasiado Archivos grandes, porque Delta Lake debe copiar todo el archivo para reescribirlo.
Si la unión externa es el cuello de botella de la ejecución de MERGE (por ejemplo, se tarda demasiado en reescribir el archivo), entonces podemos usar las siguientes estrategias para resolverlo:
• Ajuste el número de particiones aleatoriamente
• Esta tabla de particiones puede generar muchos archivos pequeños
• Active el reparticionamiento automático antes de escribir archivos para reducir los archivos generados por Reducir.
• Ajuste el umbral de transmisión. Si usamos una unión externa completa, Spark no puede realizar una unión de transmisión, pero si usamos una unión externa derecha, se puede usar Spark; podemos ajustar el umbral de transmisión de acuerdo con la situación real;
• tabla de origen de caché / DataFrame.
• tabla de origen de caché . Acelere el tiempo de la segunda exploración, pero recuerde no almacenar en caché la tabla de destino, ya que esto puede causar problemas de coherencia de la caché.
para resumir
Delta Lake admite comandos DML como UPDATE, DELETE y MERGE INTO, lo que simplifica enormemente el flujo de trabajo de muchas operaciones comunes de big data. En este artículo, demostramos cómo usar estos comandos en Delta Lake, presentamos los principios de implementación de estos comandos DML y proporcionamos algunas técnicas de ajuste del rendimiento.