Uno, crea un hilo a través de Callable
1.1 Diferencia
class Thread1 implements Runnable{
@Override
public void run() {
}
}
class Thread2 implements Callable<String>{
@Override
public String call() throws Exception {
return null;
}
}
- Es el método de ejecución que implementa la interfaz Runnable para crear un hilo y reescribe el método de llamada que implementa la interfaz Callable.
- Implementar la interfaz invocable para crear un proceso, que puede generar excepciones
- Implemente la interfaz invocable para crear un proceso, con un valor de retorno, y el valor de retorno debe ser coherente con el genérico.
1.2 Iniciar un hilo
Entonces, ¿cómo crear un hilo que implemente Callable? Al mirar el documento oficial, puede encontrar que el hilo creado usando Callable es similar a Runnable, por lo que puede iniciarlo en Therad

No hay ningún parámetro que se pueda pasar directamente a la interfaz invocable en Thread.
Para usar Callable in Thread, podemos imaginar este tipo de interfaz o clase que implementa Runnable y Callable? Y FutureTask es este tipo de clase. Primero, implementa la interfaz Runnable, y luego el método de construcción permite pasar la clase de implementación de la interfaz Callable.

FutureTask(Callable<V> callable)
Entonces es fácil iniciar el hilo invocable
class Thread2 implements Callable<String>{
@Override
public String call() throws Exception {
System.out.println("线程启动了");
return null;
}
}
public class CallableTest {
public static void main(String[] args) throws InterruptedException {
FutureTask<String> task = new FutureTask<>(new Thread2());
new Thread(task,"A").start();
}
}
1.3 Obtenga el valor de retorno
Llame al método get para obtener el valor de retorno
FutureTask<String> task = new FutureTask<>(new Thread2());
new Thread(task,"A").start();
task.get();
1.4 Principio
Llamar al subproceso del método get se bloqueará hasta el final de la ejecución del subproceso, devolverá el valor de retorno. Cuando necesite realizar operaciones que consuman más tiempo en el subproceso principal, pero no desee bloquear el subproceso principal, puede entregar estas tareas al objeto Future para que las complete en segundo plano. Cuando el subproceso principal lo necesite en el futuro, puede obtener los resultados del cálculo del trabajo en segundo plano a través del objeto Futuro o el estado de ejecución.
FutureTask<Integer> futureTask = new FutureTask(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 1024;
});
new Thread(futureTask,"A").start();
while(!futureTask.isDone()){
System.out.println("***wait");
}
System.out.println(futureTask.get());
System.out.println(Thread.currentThread().getName()+" come over");
Se inicia un hilo arriba para simular y calcular la tarea que consume más tiempo y luego se devuelve el resultado final. En el hilo principal, el método isDone juzga si la ejecución ha terminado y el final de la ejecución (completo / cancelar / anormal) regresa verdadero. El programa anterior puede demostrar que llama a get El método está bloqueado, solo el hilo A devolverá el resultado, continuará ejecutándose
 También tenga en cuenta que una tarea solo se calcula una vez, consulte el siguiente código
También tenga en cuenta que una tarea solo se calcula una vez, consulte el siguiente código
FutureTask<Integer> futureTask = new FutureTask(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 1024;
});
new Thread(futureTask,"A").start();
while(!futureTask.isDone()){
System.out.println("***wait");
}
System.out.println(futureTask.get());
System.out.println("--------");
System.out.println(futureTask.get());
System.out.println(Thread.currentThread().getName()+" come over");

En el segundo get, el hilo no se durmió durante 4 segundos. Se puede ver que se devuelve directamente, por lo que cada tarea solo se calculará una vez.
para resumir:
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法。一旦计算完成,就不能再重新开始或取消计算。get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。 一个task任务只计算一次,所以一般将get方法放到最后。
Dos, grupo de subprocesos
2.1 Beneficios del grupo de subprocesos
Hablando de grupos de subprocesos, es fácil pensar en el grupo de conexiones de bases de datos c3p0 y otras tecnologías de grupos de conexiones de bases de datos. Los beneficios del grupo de conexiones de bases de datos y el grupo de subprocesos son los mismos:
- Reducir el consumo de recursos: reducir el consumo causado por la creación y destrucción de subprocesos al reutilizar los subprocesos creados
- Mejorar la velocidad de respuesta: cuando llega una tarea, la tarea se puede ejecutar inmediatamente sin esperar a que se cree el hilo.
- Mejorar la capacidad de administración de los subprocesos: los subprocesos son recursos escasos. Si se crean de forma ilimitada, no solo consumirán recursos del sistema, sino que también reducirán la estabilidad del sistema. La tecnología del grupo de subprocesos se puede utilizar para la asignación, el ajuste y la supervisión unificados.
2.2 Introducción al albacea
El marco del Ejecutor se compone principalmente de 3 partes:
- Tarea: Incluidas las interfaces que la tarea ejecutada necesita implementar: interfaz ejecutable e interfaz invocable
- Ejecución de la tarea: incluida la interfaz central Executor del mecanismo de ejecución de la tarea y la interfaz ExecutorService heredada de la interfaz Executor. Hay dos clases clave que implementan la interfaz ExecutorService: ThreadPoolExecutor, ScheduledThreadPoolExecutor
- El resultado del cálculo asincrónico: incluida la interfaz Future y la clase FutrueTask que implementa la interfaz Future
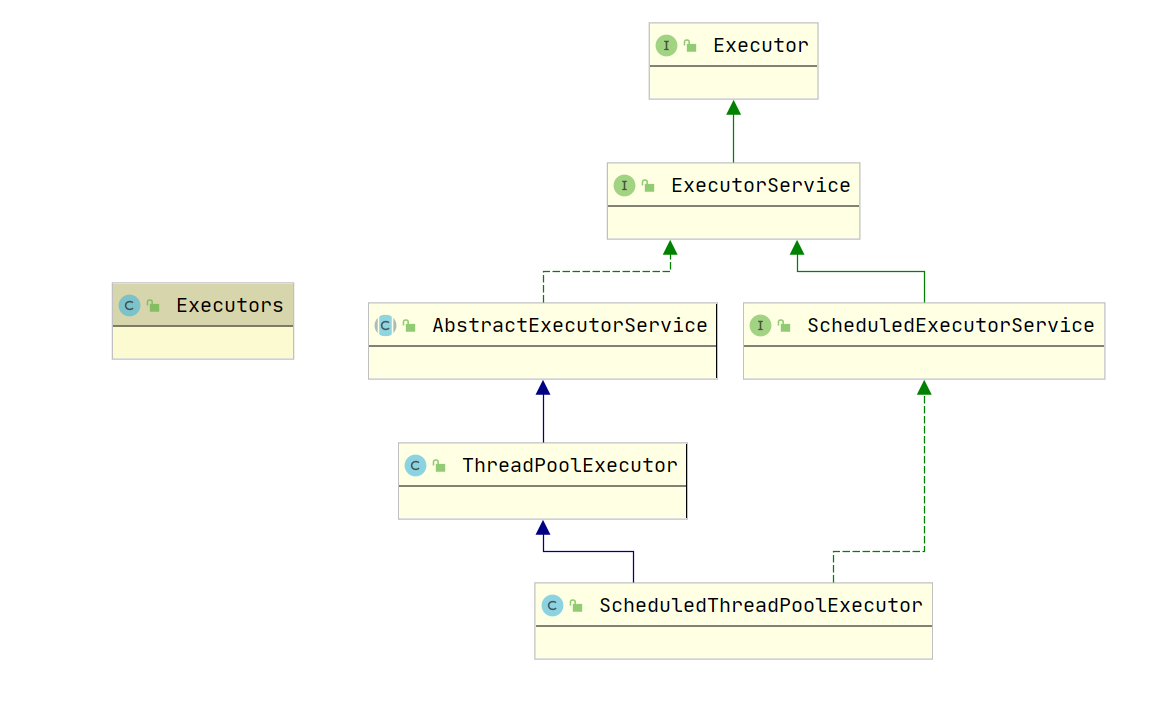
2.3 Usar grupo de subprocesos
A través de la clase de herramienta Ejecutores, puede crear 3 tipos de ThreadPoolExecutor:
- FixedThreadPool
- SingleThreadExecutor
- CachedThreadPool
2.3.1 FixedThreadPool
FixedThreadPool se denomina grupo de subprocesos reutilizables con un número fijo de subprocesos. Se pasa un parámetro para indicar el número máximo de subprocesos en el grupo de subprocesos.
public class MyThreadPoolDemo1 {
public static void main(String[] args) {
//创建固定数量的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(4);
for (int i = 1; i <= 10; i++) {
//执行每个线程里的方法
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t进来了");
try {
//暂停1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池
threadPool.shutdown();
}
}

2.3.2 SingleThreadExecutor
SingleThreadExecutor es un Ejecutor que usa un solo hilo de trabajo, y el método de uso es el mismo que FixedThreadPool
ExecutorService threadPool = Executors.newSingleThreadExecutor();
for (int i = 1; i <= 10; i++) {
//执行每个线程里的方法
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t进来了");
try {
//暂停1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池
threadPool.shutdown();
2.3.3 CachedThreadPool
CachedThreadPool es un grupo de subprocesos que creará nuevos subprocesos según sea necesario, y el método de uso es el mismo que los dos anteriores
2.4 Siete parámetros de la agrupación de subprocesos
Aunque la clase de herramientas Ejecutores proporciona tres grupos de subprocesos disponibles, cada uno con un solo subproceso y un número específico de subprocesos, que se pueden ampliar según sea necesario, echemos un vistazo al código fuente.
//固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//单个work工作的线程
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
//可根据需要扩展的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
Viendo el código fuente anterior, podemos encontrar los puntos en común. Se llama al método ThreadPoolExecutor. Es decir, los 3 grupos de subprocesos proporcionados por los Ejecutores solo nos ayudan a pasar algunos parámetros a ThreadPoolExecutor. A continuación se muestra el código fuente de ThreadPoolExecutor.
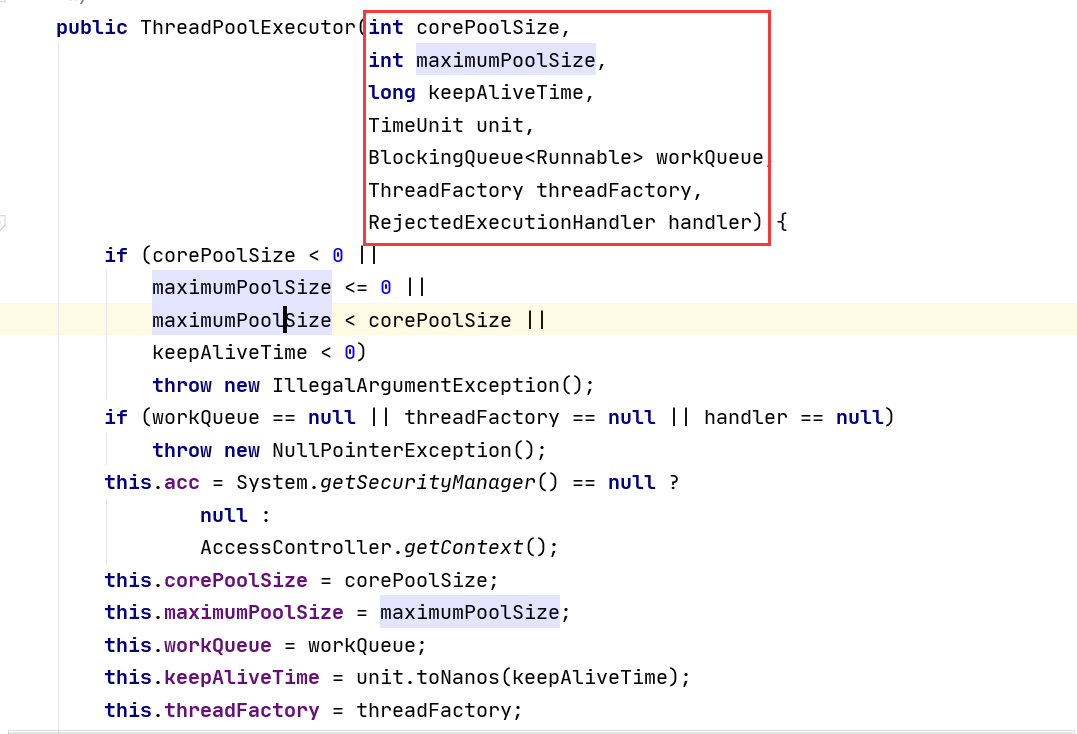
ThreadPoolExecutor tiene un total de siete parámetros, que se introducen uno por uno a continuación
2.4.1 corePoolSize
corePoolSize es el tamaño básico del grupo de subprocesos, el número de subprocesos centrales residentes en el grupo de subprocesos
Al enviar una tarea al grupo de subprocesos, el grupo de subprocesos creará un subproceso para ejecutar la tarea. Incluso si otros subprocesos básicos inactivos pueden realizar nuevas tareas, también crearán subprocesos. Cuando la cantidad de tareas que deben ejecutarse es mayor que el tamaño básico del grupo de subprocesos, no se crearán. Si se llama al método prestartAllCoreThreads () del grupo de subprocesos, el grupo de subprocesos creará e iniciará todos los subprocesos básicos por adelantado.
2.4.2 tamaño máximo de la piscina
maximumPoolSize es el número máximo de grupos de subprocesos, el número máximo de subprocesos que el grupo de subprocesos permite crear.Si la cola está llena y el número de subprocesos creados es menor que el número máximo de subprocesos, El grupo de subprocesos creará un nuevo subproceso para realizar tareas. Vale la pena señalar que si se utiliza el parámetro de cola de tareas ilimitada, no hay ningún efecto. Este valor debe ser mayor o igual a 1
2.4.3 unidad keepAliveTime 和
keepAliveTime es el tiempo de mantenimiento de la actividad de los subprocesos, el tiempo de supervivencia de los subprocesos inactivos redundantes. Cuando el número de subprocesos en el grupo actual excede corePoolSize, cuando el tiempo de inactividad llega a keepAliveTime, los subprocesos redundantes se destruirán hasta que solo queden subprocesos corePoolSize.
unit es la unidad de keepAliveTime
2.4.4 workQueue
workQueue: cola de tareas, tareas que se han enviado pero aún no se han ejecutado, puede elegir entre lo siguiente:
- ArrayBlockingQueue: Es una cola de bloqueo delimitada basada en la estructura del arreglo, esta cola
ordena los elementos según el principio FIFO (primero en entrar, primero en salir) . - LinkedBlockingQueue: Una cola de bloqueo basada en una estructura de lista enlazada. Esta cola clasifica los elementos según FIFO, y el rendimiento suele
ser mayor que el de ArrayBlockingQueue. El método de fábrica estático Executors.newFixedThreadPool () usa esta cola. - SynchronousQueue: una cola de bloqueo que no almacena elementos. Cada operación de inserción debe esperar hasta que otro subproceso llame a la
operación de eliminación; de lo contrario, la operación de inserción permanece en un estado de bloqueo y el rendimiento suele ser mayor que el Linked-BlockingQueue. El
método de fábrica estático Executors.newCachedThreadPool usa esta cola. - PriorityBlockingQueue: una cola de bloqueo infinita con prioridad.
Estas colas son en realidad las colas de bloqueo anteriores.
2.4.5 threadFactory
Representa la fábrica de subprocesos que genera subprocesos de trabajo en el grupo de subprocesos, utilizado para crear subprocesos, generalmente el valor predeterminado es suficiente
2.4.6 manipulador
La estrategia de saturación del controlador, cuando la cola y el grupo de subprocesos están llenos, lo que indica que el grupo de subprocesos está en un estado saturado, se debe adoptar una estrategia para manejar las nuevas tareas enviadas. Esta política es AbortPolicy de forma predeterminada, lo que significa que se lanza una excepción cuando no se puede procesar una nueva tarea. En JDK 1.5, el marco del grupo de subprocesos de Java proporciona las siguientes 4 estrategias.
- AbortPolicy: lanza una excepción directamente.
- CallerRunsPolicy: solo usa el hilo de la persona que llama para ejecutar tareas.
- DiscardOldestPolicy: descarta la tarea más reciente en la cola y ejecuta la tarea actual.
- DiscardPolicy: No procesar, desechar.
Por supuesto, también puede implementar una estrategia personalizada para la interfaz RejectedExecutionHandler de acuerdo con las necesidades del escenario de la aplicación. Como el registro o el almacenamiento persistente no pueden manejar tareas.
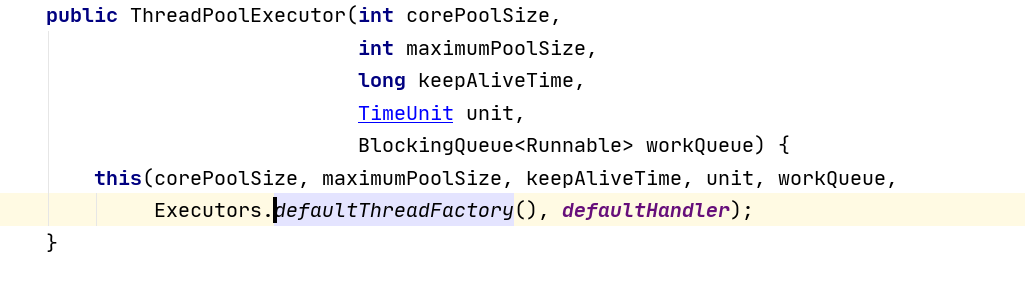

Se puede ver que la política de saturación usa AbortPolicy por defecto
2.5 El principio de funcionamiento subyacente del grupo de subprocesos
Cuando se usa el grupo de subprocesos arriba, se llama al método de ejecución. Este método es muy importante para comprender el principio de funcionamiento del grupo de subprocesos:
public void execute(Runnable command) {
//如果任务为null,则直接抛出异常
if (command == null)
throw new NullPointerException();
//The main pool control state, ctl, is an atomic integer packing
//ct1保存线程的运行状态
int c = ctl.get();
//首先判断当前线程池执行的任务数是否小于corePoolSize 如果小于新建一个线程,并将任务添加到该线程中 然后启动线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果当前线程数大于corePoolSize,那么就来到下面的逻辑
//通过isRunning判断线程的状态只有运行的线程,并且队列不满时才能加入到工作队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//再次获取线程的状态,如果不是Running就从队列里移除
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果addWorker失败 则直接启动拒绝策略
else if (!addWorker(command, false))
reject(command);
}
-
Después de crear el grupo de subprocesos, comience a esperar solicitudes.
-
Cuando se llama al método execute () para agregar una tarea de solicitud, el grupo de subprocesos hará los siguientes juicios:
- Si el número de subprocesos en ejecución es menor que corePoolSize, cree inmediatamente un subproceso para ejecutar esta tarea;
- Si el número de subprocesos en ejecución es mayor o igual que corePoolSize, coloque la tarea en la cola;
- Si la cola está llena en este momento y el número de subprocesos en ejecución sigue siendo menor que el maximumPoolSize, todavía tiene que crear un subproceso no central para ejecutar la tarea inmediatamente;
- Si la cola está llena y el número de subprocesos en ejecución es mayor o igual que maximumPoolSize, el grupo de subprocesos iniciará la ejecución de la estrategia de rechazo de saturación.
-
Cuando un subproceso completa su tarea, eliminará la siguiente tarea de la cola para su ejecución.
-
Cuando un hilo no tiene nada que hacer por más de un cierto tiempo (keepAliveTime), el hilo juzgará:
-
Si el número de subprocesos que se están ejecutando actualmente es mayor que corePoolSize, este subproceso se detiene.
-
Una vez completadas todas las tareas de todos los grupos de subprocesos, eventualmente se reducirá al tamaño de corePoolSize.
-
Profundicemos nuestra comprensión nuevamente a través de la figura a continuación.
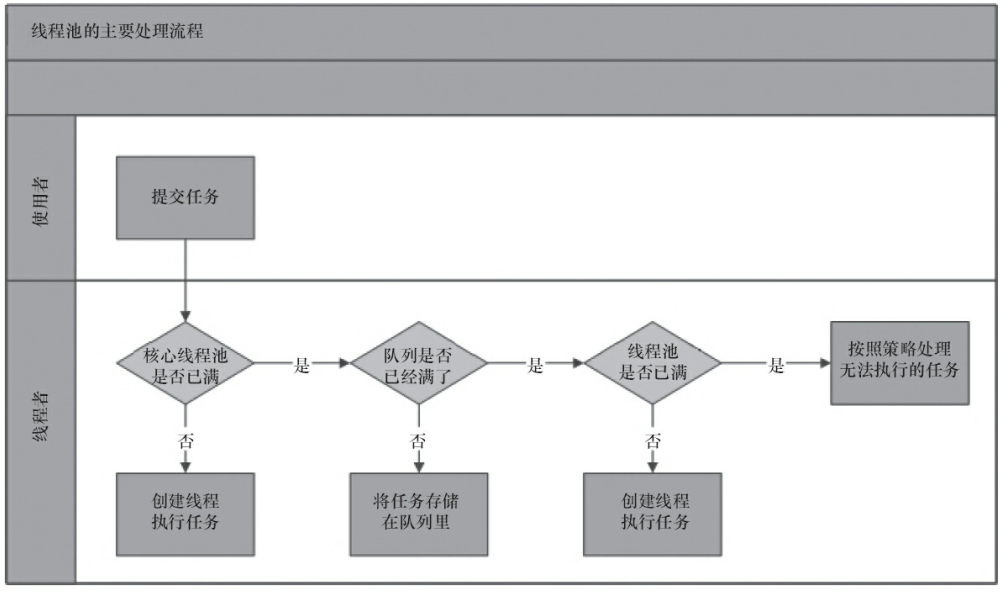
- El grupo de subprocesos determina si todos los subprocesos del grupo de subprocesos principales están realizando tareas. De lo contrario, cree un nuevo hilo de trabajo para realizar la tarea. Si todos los subprocesos del grupo de subprocesos principales están realizando tareas, ingrese al siguiente proceso.
- El grupo de subprocesos determina si la cola de trabajo está llena. Si la cola de trabajos no está llena, las tareas recién enviadas se almacenan en esta cola de trabajos. Si la cola de trabajos está llena, ingrese al siguiente proceso.
- El grupo de subprocesos juzga si todos los subprocesos del grupo de subprocesos están funcionando. De lo contrario, cree un nuevo hilo de trabajo para realizar la tarea. Si está lleno, entréguelo a la estrategia de saturación para que se encargue de esta tarea.
Es decir, el flujo de trabajo del grupo de subprocesos debe verificar 3 lugares. Cuando el número de subprocesos aumenta, verifique corePoolSize, si la cola de bloqueo de workQueue está llena y si se ha alcanzado el número máximo de subprocesos de maxmumPoolSize. Si aumenta el número de subprocesos, inicie la estrategia de saturación, que está relacionada con los siete parámetros del grupo de subprocesos
2.6 Configuración razonable del grupo de subprocesos
Aunque Executors nos proporciona 3 formas de crear subprocesos, y CachedThreadPool también puede crear subprocesos según sea necesario, pero en el trabajo real, aún necesita definir los parámetros del grupo de subprocesos usted mismo. Por razones específicas, puede consultar el código fuente de CachedThreadPool.
public static ExecutorService newCachedThreadPool () {
//可以看到最大容量为Integer.MAX_VALUE
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
¿Qué hay de los otros dos? FixedThreadPool y SingleThreadExecutor usan el LinkedBlockingQueue ilimitado (aunque se llama acotado, pero la capacidad máxima es Integer.MAX_VALUE, por lo que también se llama ilimitado aquí. Lo forzaré a explicar, porque "Java Concurrent Art Programming" dice que esto es ilimitado) , CachedThreadPool usa SynchronousQueue.
Por lo tanto, FixedThreadPool, SingleThreadExecutor y CachedThreadPool pueden romper la memoria y causar oom, por lo que generalmente se usan grupos de subprocesos con parámetros personalizados
Si desea configurar el grupo de subprocesos de manera razonable, primero debe analizar las características de la tarea, que se pueden analizar desde las siguientes perspectivas: la naturaleza de la tarea, la prioridad de la tarea, el tiempo de ejecución de la tarea y la dependencia de la tarea