
Autores de artículos | Zaixiang Zheng, Hao Zhou, Shujian Huang, etc.
Compilador | Editado por Wu Shaojie | En el sistema de traducción automática de Cai Fangfang, el entrenamiento y decodificación de datos no paralelos siempre ha sido un desafío. No hace mucho, Toutiao y la Universidad de Nanjing propusieron conjuntamente el NMT basado en la duplicación. Es una arquitectura unificada que incluye un modelo de conversión de destino a fuente, un modelo de conversión de fuente a destino y dos modelos de idioma. El modelo de traducción y el modelo de idioma están en el mismo Un espacio semántico oculto, por lo tanto, ambas direcciones de traducción pueden aprender de manera efectiva a partir de datos no paralelos, lo cual es muy importante para mejorar la calidad de la traducción. Este documento ha sido aceptado por ICLR2020. Este artículo es una guía para el artículo 106 sobre IA Frontline. Interpretaremos este trabajo de investigación en detalle.
Visión de conjunto
El sistema de traducción automática neuronal (NMT) proporciona resultados de traducción bastante buenos cuando hay una gran cantidad de datos paralelos bilingües disponibles para la formación. Sin embargo, en la mayoría de los escenarios de traducción automática, no es fácil obtener una cantidad tan grande de datos paralelos. Por ejemplo, hay muchos pares de idiomas de bajos recursos (por ejemplo, inglés a tamil), que carecen de suficientes datos paralelos para la capacitación. Además, debido a la gran diferencia de dominio entre el dominio de prueba y los datos paralelos utilizados para el entrenamiento, si los datos paralelos en el dominio (como el dominio médico) son limitados, generalmente es difícil aplicar el modelo NMT a otros dominios. . En el caso de que los datos bilingües en paralelo sean insuficientes, es esencial hacer un uso completo de los datos bilingües no paralelos (por lo general, de bajo costo de adquisición) para obtener resultados de traducción satisfactorios.
Creemos que en las etapas de entrenamiento y decodificación, el método NMT actual que utiliza datos no paralelos no es necesariamente el mejor. Para el entrenamiento, la retrotraducción (Sennrich et al., 2016) es el método más utilizado para datos monolingües. Sin embargo, la traducción inversa actualiza las dos direcciones del modelo de traducción automática por separado, lo que no es el más eficaz.
Específicamente, dados los datos monolingües x del idioma de origen y los datos monolingües y del idioma de destino, la traducción inversa usa el modelo de traducción tgt2src (TMy → x) para obtener la traducción predicha xˆ usando y. Luego use el par de pseudotraducción ⟨xˆ, y⟩ para actualizar el modelo de traducción src2tgt (TMx → y). x se puede actualizar TMy → x de la misma manera. Tenga en cuenta aquí que TMy → x y TMx → y son independientes y están actualizados. En otras palabras, cada actualización de TMy → x no beneficiará directamente a TMx → y. Algunos trabajos, como la traducción inversa conjunta y el aprendizaje dual, introducen el entrenamiento iterativo, de modo que TMy → xy TMx → y se benefician mutuamente de forma implícita e iterativa. Pero el modo de traducción en estos métodos sigue siendo independiente. Idealmente, si hemos relacionado TMy → x y TMx → y, los beneficios de los datos no paralelos pueden magnificarse. En este caso, después de cada actualización de TMy → x, podemos obtener directamente un mejor TMx → y, y viceversa, haciendo así un uso más efectivo de los datos no paralelos.
En términos de decodificación, algún trabajo relacionado (Gulcehre et al., 2015) sugirió insertar un modelo de lenguaje externo LMy (entrenado por separado para los datos monolingües de destino) en el modelo de traducción TMx → y, que incluye el conocimiento de los datos monolingües de destino. para traducir mejor. Esto es particularmente útil para la adaptación de dominios, porque podemos obtener resultados de traducción más adecuados para el dominio (por ejemplo, redes sociales) a través de una mejor LMy. Sin embargo, insertar directamente un modelo de lenguaje independiente durante la decodificación puede no ser lo mejor. En primer lugar, el modelo de lenguaje utilizado aquí es externo y aún aprende independientemente del modelo de traducción, por lo que es posible que los dos modelos no puedan cooperar bien a través de simples mecanismos de interpolación (o incluso conflictos). Además, el modelo de lenguaje solo se incluye en la decodificación y no se considera en la formación. Esto conduce a la inconsistencia del entrenamiento y la decodificación, lo que afecta el rendimiento del sistema.
Este artículo propone NMT generativo espejo (MGNMT) para resolver los problemas anteriores y utilizar eficazmente datos no paralelos en NMT. MGNMT propone entrenar conjuntamente modelos de traducción (TMx → y y TMy → x) y modelos de lenguaje (LMx y LMy) bajo un marco unificado, lo cual es muy importante. Inspirándonos en el NMT generativo (Shah & Barber, 2018), proponemos introducir una variable semántica implícita z compartida entre xey. Nuestro método utiliza simetría o características de imagen especular para descomponer la probabilidad conjunta condicional p (x, y | z), a saber:
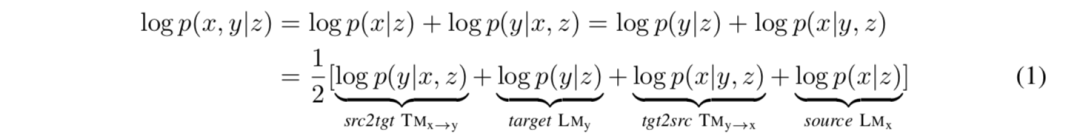
El modelo gráfico de MGNMT se muestra en la Figura 1. MGNMT alinea el modelo de traducción bidireccional y el modelo de lenguaje en los dos idiomas a través de un espacio semántico implícito compartido (Figura 2), de modo que todos estos modelos están relacionados y se vuelven condicionalmente independientes para una z dada. En este caso, MGNMT tiene las siguientes ventajas:
En el entrenamiento, dado que z es un puente, TMy → xy TMx → y no son independientes, por lo que cada actualización en una dirección beneficiará directamente a la otra dirección, al igual que el efecto de "1 + 1> 2". Esto mejora la eficiencia del uso de datos no paralelos. (Sección 3.1)
Para la decodificación, MGNMT puede utilizar naturalmente su modelo de lenguaje interno del lado de destino, que se aprende junto con el modelo de traducción. Juntos, han contribuido a un mejor proceso de generación. (Sección 3.2)
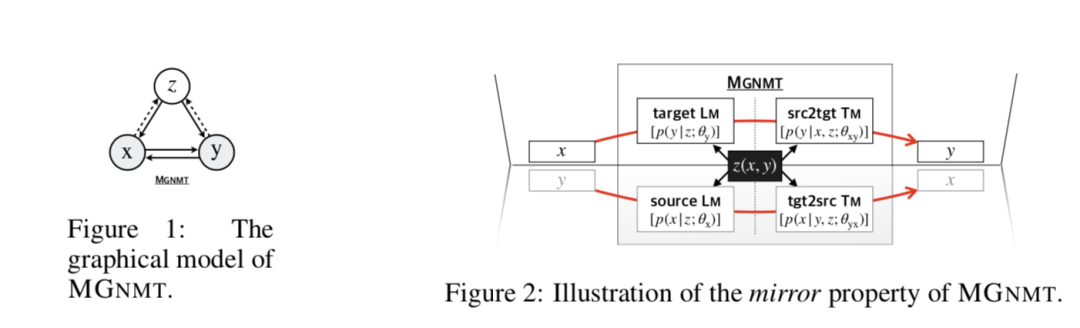
Tenga en cuenta que MGNMT es ortogonal al aprendizaje dual y la traducción inversa conjunta (Zhang et al., 2018). Los modos de traducción en MGNMT son interdependientes y los dos modos de traducción pueden promoverse directamente entre sí. La diferencia es que los métodos de aprendizaje dual y traducción conjunta son efectivos, y estos dos métodos también se pueden utilizar para mejorar aún más el MGNMT. El modelo de lenguaje utilizado en el aprendizaje dual se enfrenta al mismo problema que (Gulcehre et al., 2015). Dado el GNMT, el MGNMT propuesto también es significativo. GNMT tiene un solo modelo de lenguaje fuente, por lo que no puede mejorar la decodificación como MGNMT. Además, en (Shah & Barber, 2018), requieren que GNMT comparta todos los parámetros y vocabulario entre los modelos de traducción para poder utilizar datos monolingües, que no son los más adecuados para pares de idiomas de larga distancia. Haremos más comparaciones en trabajos relacionados.
Los experimentos muestran que MGNMT tiene una fuerte competitividad en datos bilingües paralelos, mientras que MGNMT tiene sólidas capacidades de entrenamiento en datos no paralelos, en diferentes escenarios y pares de idiomas, incluidos escenarios ricos en recursos y escenarios de escasos recursos, MGNMT es superior a múltiples cruces de referencia sólidos -Traducciones de dominio en traducción de idiomas de bajos recursos Además, también descubrimos que cuando el modo de traducción de aprendizaje conjunto de MGNMT y el modo de idioma funcionan juntos, la calidad de la traducción realmente mejorará. También demostramos que MGNMT no está estructurado y se puede aplicar a cualquier modelo de secuencia neuronal, como Transformer y RNN. Esta evidencia demuestra que MGNMT cumple con nuestras expectativas de hacer un uso completo de datos no paralelos.
Traducción automática neuronal de generación espejo
Proponemos Mirror Generation NMT (MGNMT), un nuevo modelo generativo profundo que modela simultáneamente modelos de traducción src2tgt y tgt2src (variacional) y un par de modelos de lenguaje de origen y destino (variacional) de una manera altamente integrada. Por lo tanto, MGNMT puede aprender de datos bilingües no paralelos y utilizar el modelo de traducción para interpolar naturalmente su modelo de lenguaje aprendido durante el proceso de decodificación.
La arquitectura general de MGNMT se muestra en la Figura 3. MGNMT utiliza la propiedad de reflejo de la probabilidad conjunta para establecer un modelo de distribución conjunta en pares de oraciones bilingües: log p (x, y | z) = 1/2 [log p (y | x, z) + log p (y | z) + log p (x | y, z) + logp (x | z)], donde la variable latente z (usamos el estándar gaussiano previo z∼N (0, I)) representa la semántica compartida entre xey, Act como puente entre todos los modelos integrados de traducción y lenguaje.
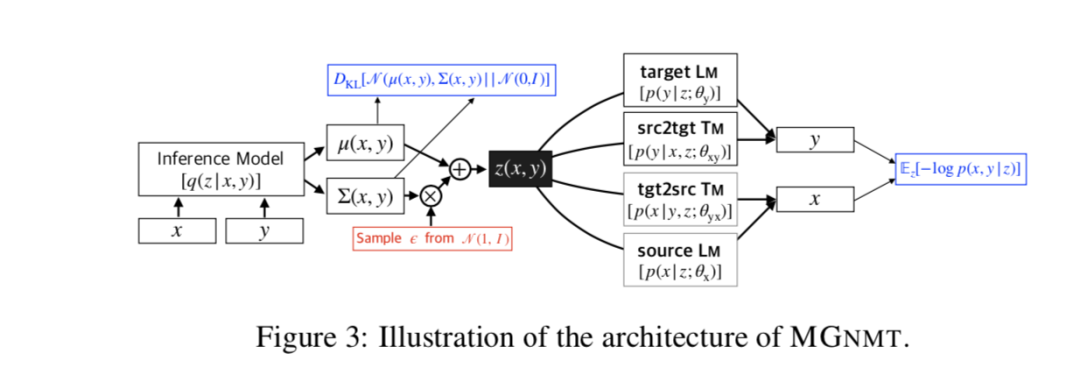
capacitación
Aprendizaje de datos en paralelo
Primero presentamos cómo entrenar MGNMT en datos paralelos bilingües regulares. Dado un par de oraciones bilingües paralelas ⟨x, y⟩, usamos Bayes variacional de gradiente estocástico (SGVB) (Kingma & Welling, 2014) para aproximar la estimación de máxima verosimilitud del logaritmo p (x, y). Parametrizamos el posterior aproximado q (z | x, y; φ) = N (μφ (x, y), ∑φ (x, y)). A partir de la ecuación (1), el límite inferior de la evidencia para la probabilidad logarítmica de verosimilitud conjunta (ELBO) L (x, y; θ; φ) se puede obtener como:
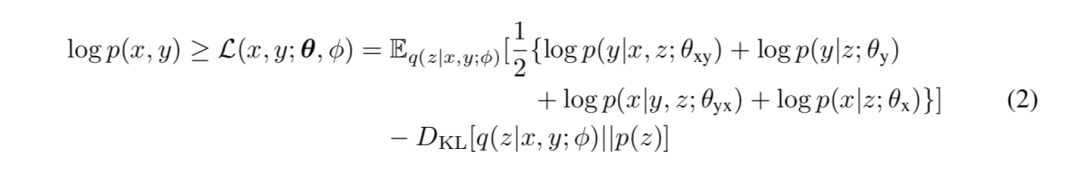
其中θ={θx,θyx,θy,θxy}是翻译和语言模型的参数集。第一项是句子对的(期望)对数似然。期望值是通过蒙特卡洛抽样得到的。第二项是 z 的近似后验分布和先验分布之间的 KL 散度。借助于重新参数化技巧(Kingma&Welling,2014),我们现在可以使用基于梯度的算法联合训练所有组件。
非平行数据学习
由于 MGNMT 本质上是一对镜像翻译模型,我们设计了一种迭代训练方法来开发非平行数据,在这种方法中,MGNMT 的两个方向都可以从单语数据中获益,并相互促进。算法 1 中给出了非平行双语数据的训练过程。

形式上,给定非平行双语句子,即来自源单语数据集 Dx={x(s)| s=1…s}的 x(s)和来自目标单语数据集 Dy={y(t)| t=1…t}的 y(t),我们的目标是最大化它们的边缘分布的可能性下限:
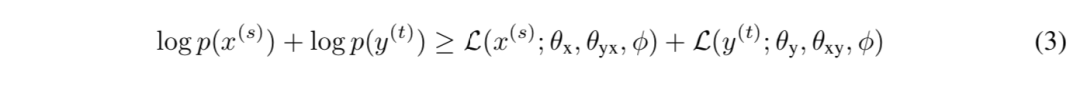
其中,L(x(s);θx,θyx,φ)和 L(y(t);θy,θxy,φ)分别是源和目标边缘对数像的下界。
我们以 L(y(t);θy,θxy,φ)为例。受(Zhang 等人,2018)启发,我们将源语言中的 x 和 p(x | y(t)) 作为 y(t) 的翻译(即反向翻译)进行抽样,得到一个伪平行句子对<x,y(t)>。因此,我们给出了方程(4)中 L(y(t);θy,θxy,φ)的形式。同样,等式(5)适用于 L(y(t);θy,θxy,φ)。(其推导见附录)。
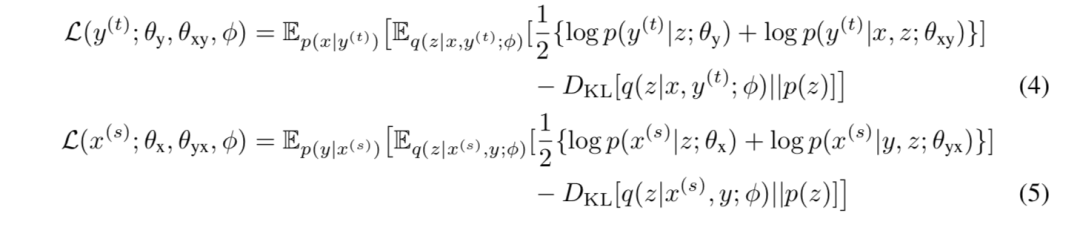
方程(3)中包含的参数可通过基于梯度的算法进行更新,其中偏差在镜像中计算为方程(6)和综合行为:
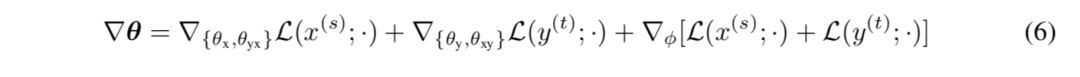
利用非平行数据的整个训练过程在某种程度上与联合反向翻译有相似的想法(Zhang 等人,2018)。但它们只利用非平行数据的一侧来更新每次迭代的一个方向的转换模型。共享的近似后验 q(z|x,y;φ)作为一个桥梁,因此 MGNMT 的两个方向都可以从单语数据中受益,达到“1+1>2”的效果。此外,MGNMT 的“反向翻译”伪翻译通过高级解码过程(见等式(7))得到了改进,从而获得了更好的学习效果。
解码
由于同时对翻译模型和语言模型进行建模,MGNMT 现在能够通过对翻译模型和语言模型的概率进行自然插值来解码。这使得 MGNMT 在译入语方面具有更高的流利性和质量。
由于 MGNMT 的镜像性质,解码过程也具有对称性:给定一个源语句 x(或目标语句 y),我们希望找到 y=argmax y p(y|x)=argmax y p(x,y)(x=argmaxx p(x| y ) = argmaxx p(x,y))的翻译,该翻译近似于 GNMT 中 EM 解码算法思想的镜像变体(Shah&Barber,2018)。算法 2 说明了我们的解码过程。

以 srg2tgt 翻译为例。给定一个源语句 x,1)我们首先从标准高斯先验中选取一个初始 z,然后得到一个初始草稿翻译为̃=argmaxy p(y | x,z);2)此翻译通过这次从近似后验 q(z | x,ỹφ)中重新采样 z 来迭代细化,并通过最大化 ELBO 来使用 beam 搜索重新解码:

现在,每一步的解码分数都由 TMx→y 和 LMy 给出,这有助于发现一个句子 y 不仅是 x 的翻译,而且在目标语言中更为可能。重建排序分数由 LMx 和 TMy→x 给出,在生成翻译候选后使用。MGNMT 可以利用这类分数对候选译文进行排序,并确定对源句最忠实的译文。它本质上与 (Tu 等人,2017) 和 (Cheng 等人,2017) 有相同的想法利用双语语义对等作为规范。
实 验数据集
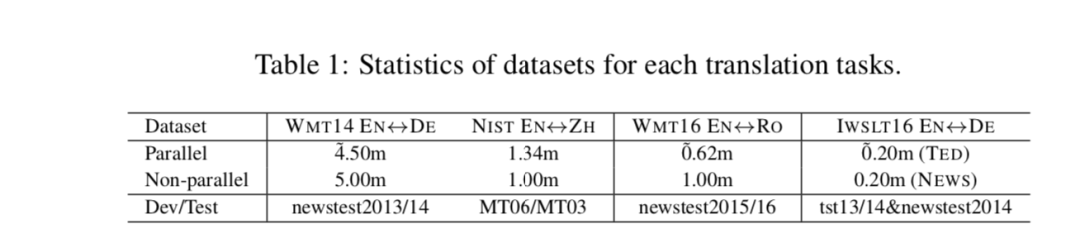
为了在资源匮乏的情况下评估我们的模型,我们进行实验在 WMT16 English-to/from-Romanian 翻译任务上作为低资源翻译和 IWSLT16 English-to/from-German (IWSLT16 EN↔DE) 的翻译任务作为跨域翻译的 TED 会话并行数据。对于资源丰富的场景,我们在 WMT14 English-to/from- German (WMT14 EN↔DE) 上进行了实验,NIST English-to/from-Chinese (NIST EN↔ZH) 翻译任务。对于所有语言,我们都使用来自 News Crawl 的非平行数据,除了 NIST EN↔ZH,从 LDC 语料库中提取汉语单语数据。表 1 列出了统计数据。
实验设置
我们在 Transformer(Vaswani 等人,2017)和 RNMT(Bahdanau 等人,2015),GNMT(Shah&Barber,2018)以及 Pytorch 上实现了我们的模型。对于所有语言对,句子使用字节对编码(Sennrich 等人,2016)和 32k 合并操作进行编码,这些操作仅从平行训练数据集的连接中联合学习(NIST ZH-EN 除外,其 BPE 是单独学习的)。我们使用 Adam optimizer 与(Vaswani 等人,2017)的学习率优化策略相同,4k warmup steps。每个小批量分别由大约 4096 个源和目标令牌组成。我们在一个 GTX 1080ti GPU 上训练我们的模型。为了避免在 DKL(q(z)| | p(z)) 接近于零的趋势下学习忽略潜在表征的近似后验“collapses”,我们应用 KL-annealing 和单词 dropout 来对抗这一效应。在所有实验中,单词的 dropout 率都被设置为 0.3 的常数。老实说,退火 KL 权重有点棘手。表 2 列出了验证集上每个任务的最佳 KL 退火设置。翻译评估指标是 BLEU(Papineni 等人,2002)。

实验结果和讨论
如表 3 和表 4 所示,MGNMT 在资源贫乏和资源丰富的情况下均优于我们的竞争 Transformer 基线(Vaswani 等人,2017 年)、基于 Transformer 的 GNMT(Shah&Barber,2018 年)和相关工作。
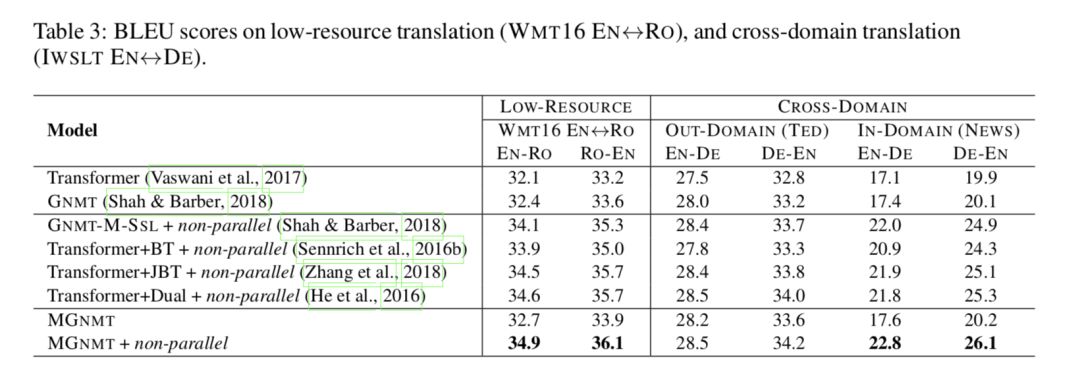
MGNMT 更好地利用了非平行数据 如表 3 所示,在两种资源匮乏的情况下,MGNMT 均优于我们的竞争 Transformer 基线(Vaswani 等人,2017 年)、基于 Transformer 的 GNMT(Shah&Barber,2018 年)和相关工作。
在低资源语言对上 该方法在缺乏双语数据的情况下,比传统方法和 GNMT 方法有了一定的改进。利用非平行数据可以获得很大的改进空间。
跨领域翻译 为了评估我们的模型在跨域集合中的能力,我们首先对来自 IWSLT 基准的 TED 数据进行域内训练,然后将模型暴露于域外新闻非平行双语数据中,从新闻爬网到域内知识访问。如表 3 所示,对于域内训练数据不可见会导致 Transformer 和 MGNMT 的域内测试集性能不佳。在这种情况下,域内非平行数据贡献显著,导致 5.7∼6.4 BLEU 增益。
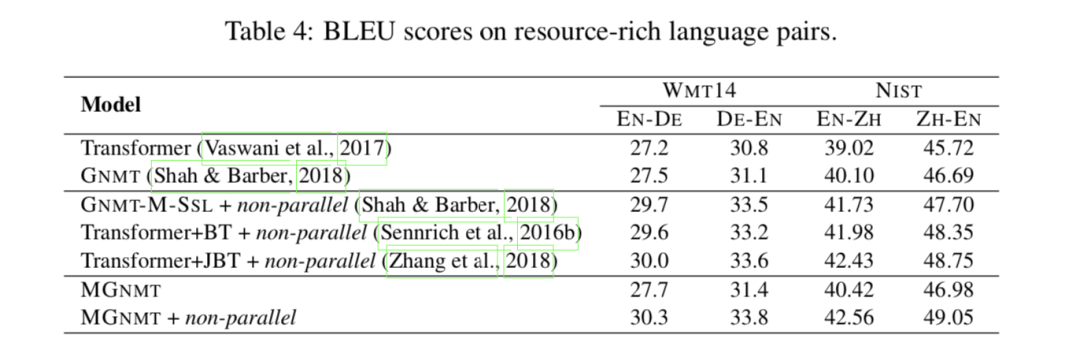
关于资源丰富的场景 我们还定期对两种资源丰富的语言对进行翻译实验,例如,EN↔DE 和 NIST EN↔ZH。如表 4 所示,在纯平行设置下,MGNMT 可以获得与判别基线 RNMT 和生成基线 GNMT 相比的可比结果。我们的模型在非平行双语数据的辅助下也能取得比以前的方法更好的性能,与资源贫乏情况下的实验结果一致。
与其他半监督工作的比较 我们将我们的方法与成熟的方法进行比较,这些方法也是为利用非平行数据而设计的,包括反向翻译(Sennrich et al.,2016b,Transformer+BT)、联合反向翻译训练(Zhang et al.,2018,Trans-Forder+JBT)、多语言和半监督的 GNMT 变体(Shah&Barber,2018,GNMT-M-SSL),以及对偶学习(He 等人,2016,Transformer+dual)。如表 3 所示,当将非平行数据引入低资源语言或跨域翻译时,所有列出的半监督方法都得到了实质性的改进。其中,我们的 MGNMT 成绩最好。同时,在资源丰富的语言对中,结果是一致的。我们认为,由于联合训练的语言模型和翻译模型能够协同解码,因此 MGNMT 优于联合反向翻译和对偶学习。有趣的是,我们可以看到 GNMT-M-SLL 在 NIST EN↔ZH 上的性能很差,这意味着参数共享不太适合远程语言对。研究结果表明,该方法在跨域场景下,具有很好的促进低资源翻译和从非并平行数据中挖掘领域相关知识的能力。
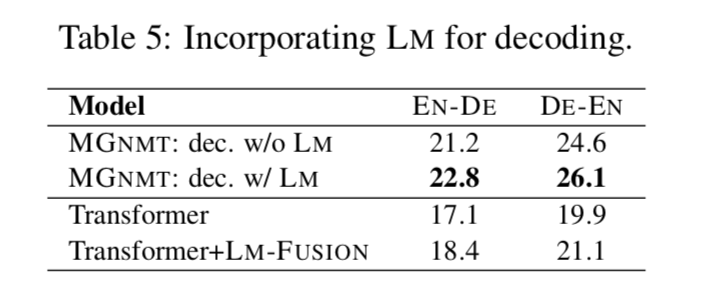
MGNMT 在解码时更善于结合语言模型 此外,我们从表 5 中发现,简单的 NMT 和外部 LM 插值(分别针对目标侧单语数据进行训练)(Gulcehre 等人,2015,Transformer-LM-FUSION)仅产生轻微的效果。这可以归因于不相关的概率建模,这意味着像 MGNMT 这样更自然的集成解决方案是必要的。除此之外,我们发现对于 MGNMT,解码收敛于 2∼3 次迭代,这消耗了∼2.7×的时间作为 Transformer 基线。减小速度的牺牲将是我们未来的方向之一。
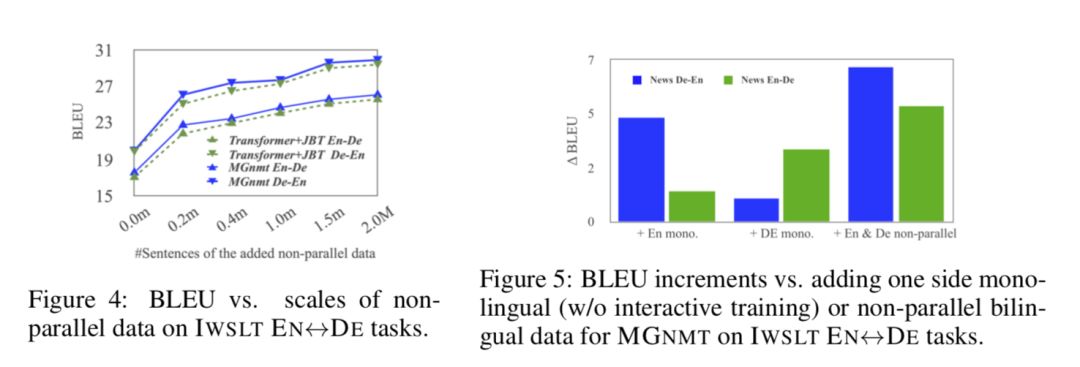
El impacto de los datos no paralelos Realizamos experimentos en la escala de datos no paralelos en IWSLT-EN↔DE para investigar la relación entre los ingresos y la escala de datos. Como se muestra en la Figura 4, a medida que aumenta la cantidad de datos no paralelos, todos los modelos se vuelven gradualmente más fuertes. MGNMT es consistentemente superior a Transformer + JBT en todas las escalas de datos. Sin embargo, la disminución de la tasa de crecimiento puede deberse al ruido de los datos no paralelos. También investigamos si el lado de los datos no paralelos es beneficioso para las dos direcciones de traducción de MGNMT. Como se muestra en la Figura 5, nos sorprende descubrir que usar solo datos monolingües, como el inglés, también puede mejorar ligeramente la traducción del inglés al alemán, lo cual está en línea con nuestra expectativa del efecto "1 + 1> 2".
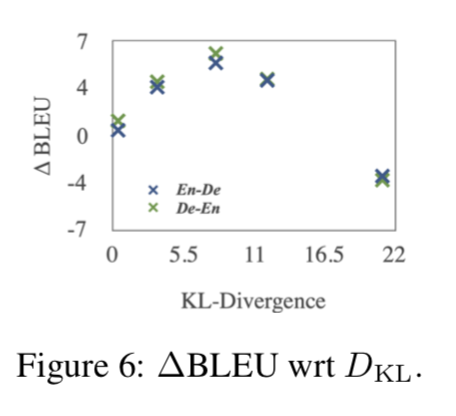
La influencia de la variable latente x empíricamente, la Figura 6 muestra que cuando el término KL se acerca a 0 (z se vuelve menos detallado), el ingreso se vuelve más pequeño y un KL demasiado grande tendrá un impacto negativo; al mismo tiempo, la Tabla 2 muestra DKL [q (z) | | El valor de p (z)] es relativamente razonable, además, la decodificación desde cero z conduce a grandes pérdidas. Esto muestra que MGNMT ha aprendido una variable latente bilingüe significativa y se basa en gran medida en ella para simular tareas de traducción. Además, MGNMT mejora aún más la decodificación mediante el uso de un modelo de lenguaje basado en z semántica significativa (Tabla 5). Estas evidencias muestran la necesidad de z.
En conclusión
Con el fin de hacer un mejor uso de los datos no paralelos, este artículo propone un modelo NMT de generación espejo. MGNMT aprende conjuntamente el modelo de traducción bidireccional y los modelos de lengua de origen y lengua de destino en el espacio latente que comparte semántica bilingüe En este caso, las dos direcciones de traducción de MGNMT pueden beneficiarse de datos no paralelos al mismo tiempo. Además, MGNMT puede utilizar naturalmente su modelo de lenguaje del lado de destino aprendido para decodificar, a fin de obtener una mejor calidad de generación. Los resultados experimentales muestran que este método es superior a otros métodos en todos los escenarios de investigación y tiene ciertas ventajas en el entrenamiento y decodificación. En el trabajo futuro, investigaremos si MGNMT se puede utilizar en un entorno completamente sin supervisión.