
¿Sincronizado, AtomicLong o LongAdder para contar?
La función de conteo se usa en muchos sistemas, entonces, ¿cuál de sincronizados, AtomicLong, LongAdder deberíamos usar para contar? Ejecutemos un ejemplo
public class CountTest {
private int count = 0;
@Test
public void startCompare() {
compareDetail(1, 100 * 10000);
compareDetail(20, 100 * 10000);
compareDetail(30, 100 * 10000);
compareDetail(40, 100 * 10000);
}
/**
* @param threadCount 线程数
* @param times 每个线程增加的次数
*/
public void compareDetail(int threadCount, int times) {
try {
System.out.println(String.format("threadCount: %s, times: %s", threadCount, times));
long start = System.currentTimeMillis();
testSynchronized(threadCount, times);
System.out.println("testSynchronized cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testAtomicLong(threadCount, times);
System.out.println("testAtomicLong cost: " + (System.currentTimeMillis() - start));
start = System.currentTimeMillis();
testLongAdder(threadCount, times);
System.out.println("testLongAdder cost: " + (System.currentTimeMillis() - start));
System.out.println();
} catch (Exception e) {
e.printStackTrace();
}
}
public void testSynchronized(int threadCount, int times) throws InterruptedException {
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
add();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public synchronized void add() {
count++;
}
public void testAtomicLong(int threadCount, int times) throws InterruptedException {
AtomicLong count = new AtomicLong();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.incrementAndGet();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
public void testLongAdder(int threadCount, int times) throws InterruptedException {
LongAdder count = new LongAdder();
List<Thread> threadList = new ArrayList<>();
for (int i = 0; i < threadCount; i++) {
threadList.add(new Thread(()-> {
for (int j = 0; j < times; j++) {
count.increment();
}
}));
}
for (Thread thread : threadList) {
thread.start();
}
for (Thread thread : threadList) {
thread.join();
}
}
}
threadCount: 1, times: 1000000
testSynchronized cost: 187
testAtomicLong cost: 13
testLongAdder cost: 15
threadCount: 20, times: 1000000
testSynchronized cost: 829
testAtomicLong cost: 242
testLongAdder cost: 187
threadCount: 30, times: 1000000
testSynchronized cost: 232
testAtomicLong cost: 413
testLongAdder cost: 111
threadCount: 40, times: 1000000
testSynchronized cost: 314
testAtomicLong cost: 629
testLongAdder cost: 162
Cuando la cantidad de simultaneidad es relativamente baja, la ventaja de AtomicLong es más obvia , porque la capa inferior de AtomicLong es un bloqueo optimista y no hay necesidad de bloquear el hilo, solo mantenga cas. Sin embargo , es ventajoso usar sincronizado cuando la concurrencia es relativamente alta , porque una gran cantidad de subprocesos continúan en cas, lo que hará que la CPU continúe aumentando, lo que reducirá la eficiencia.
LongAdder tiene ventajas obvias independientemente del nivel de simultaneidad. Y cuanto mayor sea la cantidad de simultaneidad, más obvia será la ventaja
El "Manual de desarrollo de Java" de Alibaba también tiene las siguientes sugerencias:

Entonces, ¿cómo logra LongAdder una alta concurrencia?
¿Cómo logra LongAdder una alta concurrencia?
La idea basica
El secreto de la alta concurrencia de LongAdder es usar espacio para el tiempo. La operación cas en un valor se convierte en la operación cas en múltiples valores. Cuando se obtiene la cantidad, los múltiples valores se pueden sumar.
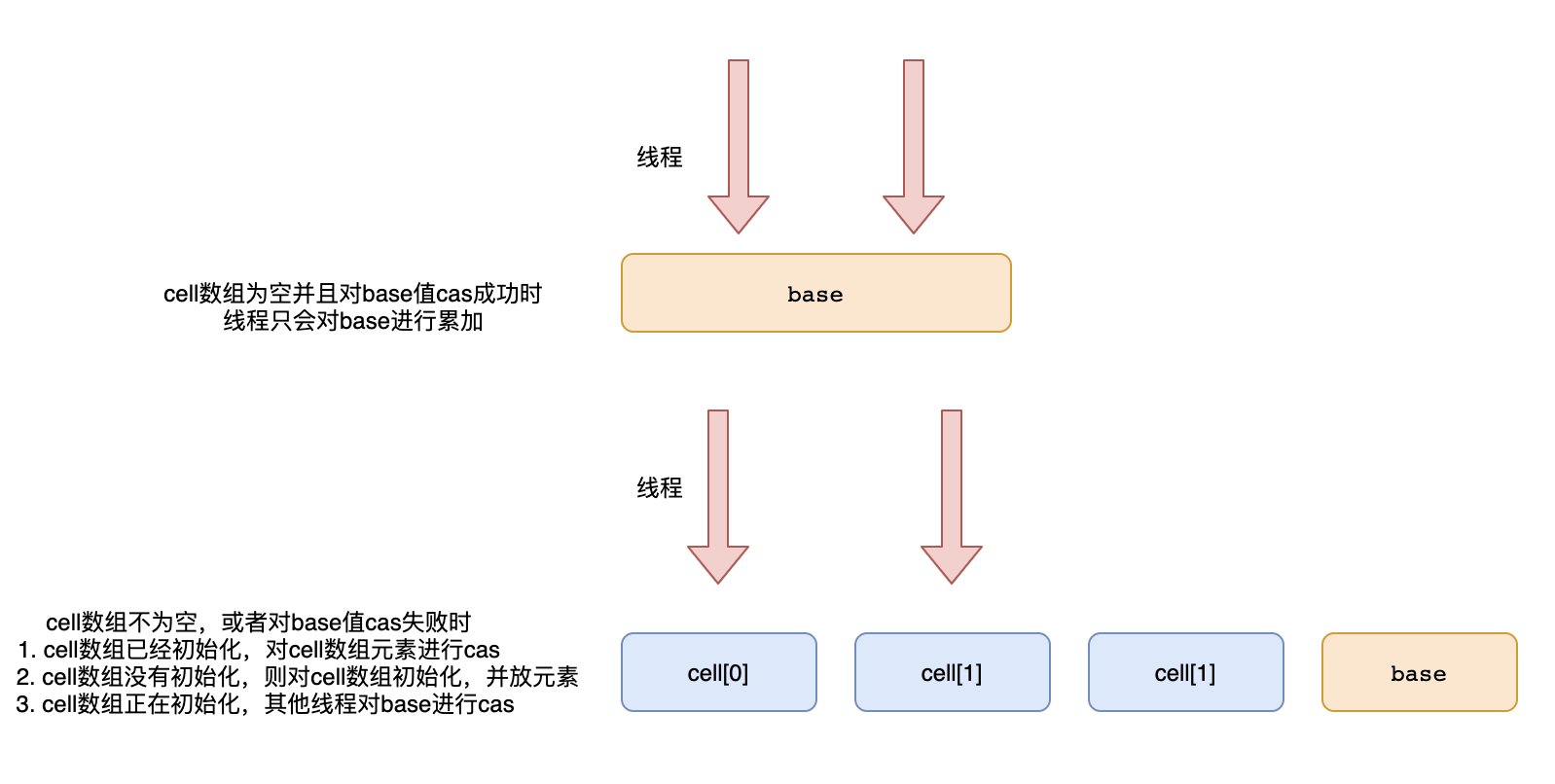
Específico para el código fuente es
- Realice la operación cas en la variable base primero y regrese después de que cas tenga éxito
- Obtenga un valor hash para el hilo (llame a getProbe), el valor hash modula la longitud de la matriz, localiza el elemento en la matriz de celdas y realiza cas en los elementos de la matriz
Aumentar el número de
public void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// 数组为空则先对base进行一波cas,成功则直接退出
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
Cuando la matriz no está vacía, y el elemento ubicado en un subíndice de la matriz no está vacío de acuerdo con el valor hash del hilo, cas regresará directamente a este elemento si tiene éxito, de lo contrario ingrese el método longAccumulate
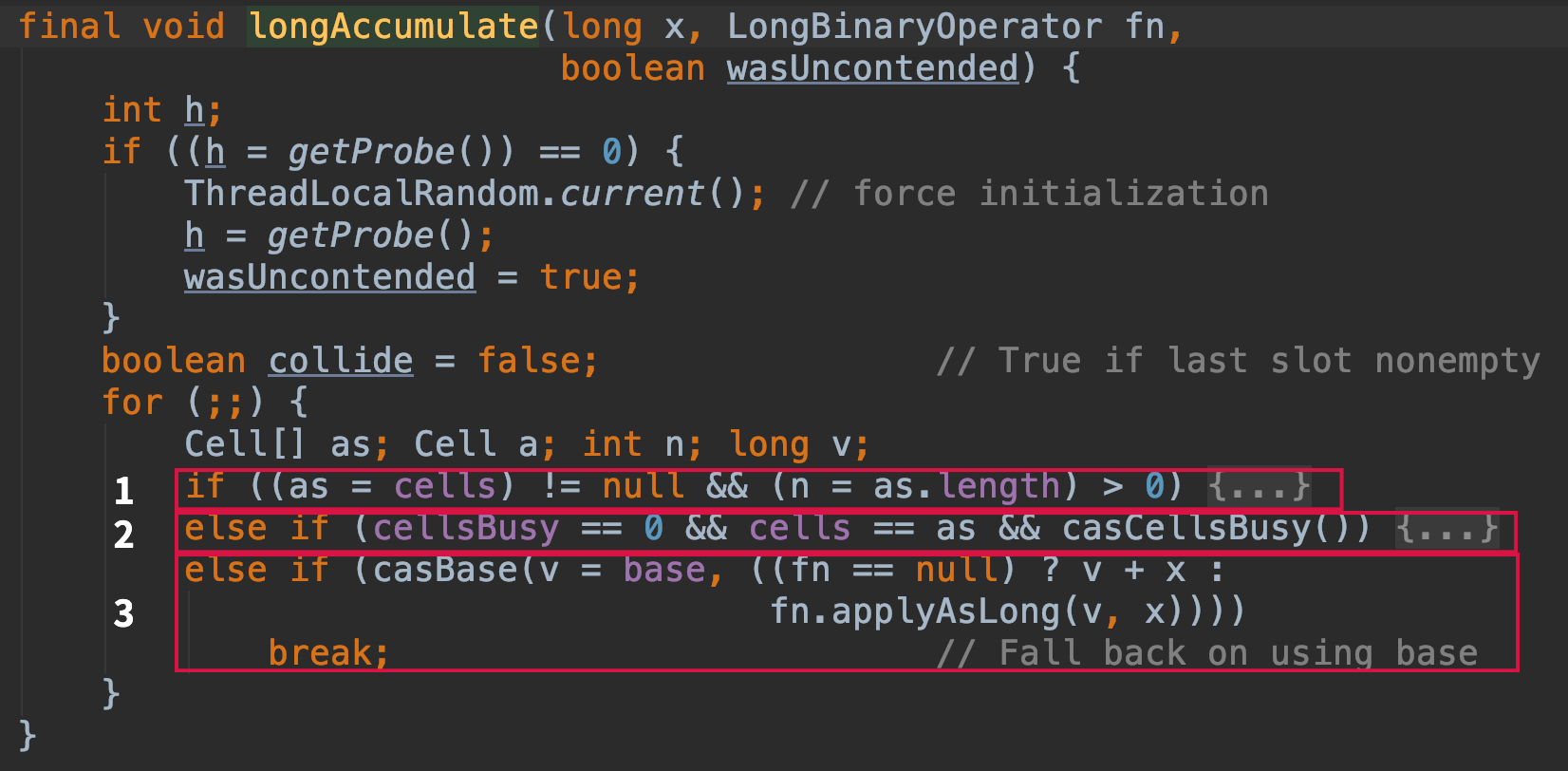
- La matriz de celdas se ha inicializado, principalmente para colocar elementos en la matriz de celdas y realizar operaciones como la expansión de la matriz de celdas.
- Si la matriz de celdas no está inicializada, inicialice la matriz
- La matriz de celdas se está inicializando y otros subprocesos usan cas para acumular baseCount
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended) {
int h;
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
// 往数组中放元素是否冲突
boolean collide = false; // True if last slot nonempty
for (;;) {
Cell[] as; Cell a; int n; long v;
if ((as = cells) != null && (n = as.length) > 0) {
if ((a = as[(n - 1) & h]) == null) {
// 有线程在操作数组cellsBusy=1
// 没有线程在操作数组cellsBusy=0
if (cellsBusy == 0) {
// Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try {
// Recheck under lock
Cell[] rs; int m, j;
// // 和单例模式的双重检测一个道理
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
// 成功在数组中放置元素
if (created)
break;
continue; // Slot is now non-empty
}
}
collide = false;
}
// cas baseCount失败
// 并且往CounterCell数组放的时候已经有值了
// 才会重新更改wasUncontended为true
// 让线程重新生成hash值,重新找下标
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// cas数组的值
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
// 其他线程把数组地址改了(有其他线程正在扣哦荣)
// 数组的数量>=CPU的核数
// 不会进行扩容
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// collide = true(collide = true会进行扩容)的时候,才会进入这个else if
// 上面2个else if 是用来控制collide的
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) {
// Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try {
// Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
Cantidad adquirida
valor base + el valor en la matriz de celdas
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
Cabe señalar que el número devuelto al llamar a sum () puede no ser el número actual, porque en el proceso de llamar al método sum (), puede haber otros arreglos que hayan cambiado la variable base o el arreglo de celdas.
// AtomicLong
public final long getAndIncrement() {
return unsafe.getAndAddLong(this, valueOffset, 1L);
}
El método AtomicLong # getAndIncrement devolverá el valor exacto después del incremento, porque cas es una operación atómica
Finalmente, te contaré un pequeño menú. En jdk1.8, la idea de ConcurrentHashMap de incrementar el número de elementos y operaciones estadísticas es exactamente la misma que la de LongAdder. El código es básicamente el mismo. Si estás interesado, puede echar un vistazo.
Blog de referencia
[1] https://www.cnblogs.com/thisiswhy/p/13176237.html