3. La subcadena más larga sin caracteres repetidos
Dada una cadena, averigüe la longitud de la subcadena más larga que no contiene caracteres repetidos.
Ejemplo 1:
Entrada: s = "abcabcbb"
Salida: 3
Explicación: Debido a que la subcadena más larga sin caracteres repetidos es "abc", su longitud es 3.
Ejemplo 2:
Entrada: s = "bbbbb"
Salida: 1
Explicación: Debido a que la subcadena más larga sin caracteres repetidos es "b", su longitud es 1.
Ejemplo 3:
Entrada: s = "pwwkew"
Salida: 3
Explicación: Debido a que la subcadena más larga sin caracteres repetidos es "wke", su longitud es 3.
Tenga en cuenta que su respuesta debe tener la longitud de la subcadena, "pwke" es una subsecuencia, no una subcadena.
Ejemplo 4:
Entrada: s = ""
Salida: 0
提示:
0 <= s.length <= 5 * 10^4
s 由英文字母、数字、符号和空格组成
responder:
Método: ventana deslizante + tabla hash
La idea principal es utilizar la idea de la tabla hash para completar la operación de juzgar si habrá caracteres repetidos en la subcadena , lo que puede reducir en gran medida la cantidad de código. Es decir, primero formamos una subcadena a partir del encabezado de la matriz original, y luego, cada vez que se le agrega un carácter, primero debemos determinar si el carácter agregado ha aparecido en la subcadena original. Si no se ve demasiado es un plus y luego continuar, si lo ha habido en este momento es necesario por la idea de una ventana deslizante , un deslizamiento de nuestra subcadena comenzando en el índice y en este momento se agregará correspondiente al carácter repetir que El subíndice correspondiente al carácter más uno . Luego, calcule la longitud de la subcadena formada originalmente. Una vez que se actualiza el índice de inicio de la subcadena, la parte anterior al índice de inicio de la tabla hash que servimos como contador debe actualizarse nuevamente . Luego continúe con la operación anterior más tarde.
Icono:
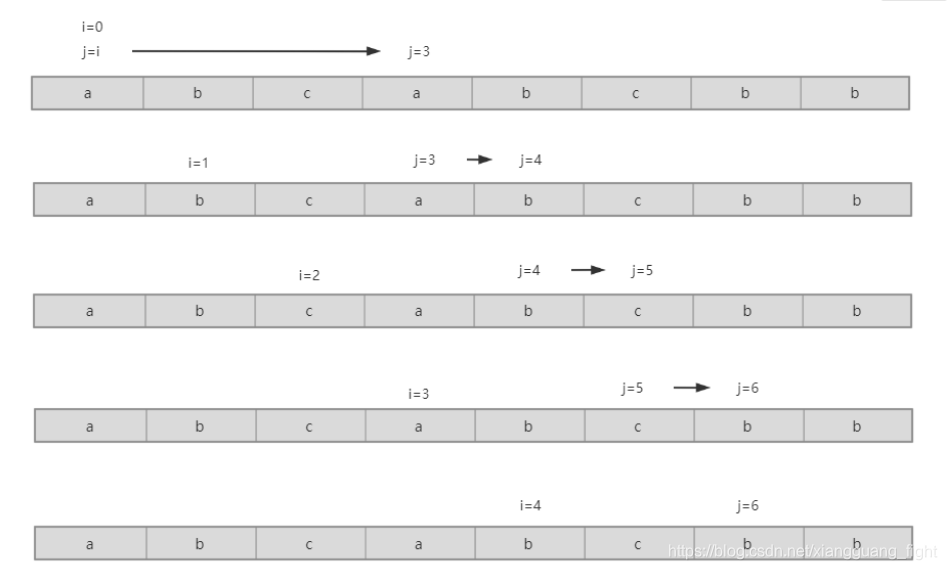
Tenga en cuenta que para facilitar la formación de un nuevo subíndice inicial cada vez, definimos el valor almacenado en la tabla hash como el subíndice correspondiente del carácter en la matriz original.
Código visible detallado:
Código:
#define max(a,b) ((a)>(b)?(a):(b))
int lengthOfLongestSubstring(char * s){
int hah[128];//哈希表
memset(hah,-1,128*sizeof(int));//先都初始化为-1
int num = 0;
int start = 0;//开始的起点
int num2 = 1;
int num3 = 0;
int x;
if(strlen(s)==0)
return 0;
if(strlen(s)==1)
return 1;
for(int i=0;i<strlen(s);i++)
{
if(hah[s[i]]==-1)//一旦还没有碰到该字符s[i]时
{
hah[s[i]]=i;//储存对应元素下标
num3++;
if(i==strlen(s)-1)//这是为了避免一直到末尾都不用更新开始下标的情况,即避免了“aab”类情况
//即可能会漏算最后形成的一个子串的长度,所以我们将这个长度与前面那些子串长度进行比较
{
x=i-start+1;
return max(x,num2);
}
}
else//一旦哈希表碰到了两次同样的字符时
{
num = i-1-start+1;//计算一下原先形成的子串长度
num2 = max(num2,num);//储存更大的子串长度
start = hah[s[i]]+1;//更新子串开始下标
for(int j=1;j<128;j++)
{
if(hah[j]<start)//将哈希表中每个字符储存的下标在新开始下标前面的部分的元素都初始化为原先的样子
{
hah[j]=-1;
}
}
hah[s[i]]=i;//原先这个没有计数,现在给他计数一下,因为他是包含在新形成的子串里的
}
}
if(num3==strlen(s))//若一直没有更新子串开始下标,即直接本身数组便是答案的情况
{
return num3;
}
else
{
return num2;
}
}