antecedentes
Ha pasado mucho tiempo desde que se vieron, y se han desarrollado durante un tiempo (principalmente estoy luchando contra el Guerrero Dragón), y básicamente completaron una demostración de colección de rendimiento simple. Compartamos la experiencia relevante con ustedes.
APM (monitor de rendimiento de aplicaciones) es el control del rendimiento de aplicaciones. Hoy en día, cuando Internet móvil tiene cada vez más impacto en la vida de las personas, las funciones de las aplicaciones son cada vez más completas y, con ello, los requisitos para el rendimiento de las aplicaciones son cada vez más altos. No se puede esperar pasivamente a que se produzca de forma anormal usuarios y luego siga el registro en línea. Vaya a corregir el error y envíe la versión del parche nuevamente. La monitorización activa del rendimiento de la aplicación se ha vuelto cada vez más importante. Analizar el consumo de energía de la aplicación, los bloqueos de la interfaz de usuario y el rendimiento de la red se han convertido en una prioridad absoluta.
El desarrollo Apm del proyecto actual se refiere a Tencent Matrix , de 360 ArgusAPM , de Didi Dokit , y algunos proyectos pequeños. Personalice de acuerdo con el proyecto y luego complete su propio sistema de recolección de Apm.
Los artículos subsiguientes se actualizarán lentamente de acuerdo con mi progreso de desarrollo actual. Puedes seguirme cuando era un niño pequeño. La recopilación de estos tres indicadores de rendimiento está actualmente completa y la información de FD del hilo puede agregarse en el futuro, por lo que este artículo se centrará análisis Estos tres puntos.
Primero plantee la pregunta
-
Para un sistema de recopilación de datos de rendimiento, no puede convertirse en una carga para una aplicación y no puede retrasar la representación del hilo principal durante la recopilación. Después de conectarse a Apm, la aplicación se retrasará más.
-
Debido a que los Fps, la memoria, la CPU, etc., deben muestrearse con frecuencia, como Fps, actualizando 60 cuadros por segundo, si se informa la cantidad total de datos, entonces el jefe de back-end puede matarme.
-
Complete la recopilación de datos de página clave con una mínima intervención empresarial y vincule los datos de la página y los datos de rendimiento.
Adquisición de fps
En primer lugar, todavía tenemos que introducir qué es Fps.
La fluidez es la experiencia de la página en el proceso de deslizamiento, renderizado, etc. El sistema Android requiere que cada fotograma se dibuje en 16 ms. La finalización suave de un fotograma significa que cualquier fotograma especial debe ejecutar todos los códigos de representación (incluidos los comandos enviados por el marco a la GPU y la CPU para dibujar en el búfer) dentro de 16ms. Terminado en el interior, manteniendo una experiencia fluida. Si el renderizado no se completa en segundos, se producirán caídas de fotogramas. La caída de fotogramas es un problema fundamental en la experiencia del usuario. El fotograma actual se descarta y la frecuencia de fotogramas anterior no se puede continuar más tarde. Este intervalo discontinuo fácilmente llamará la atención del usuario, que es lo que a menudo llamamos tartamudeo y entrecortado.
Entonces, ¿es suave siempre que se dibujen 60 cuadros en 1s? No necesariamente, si se produce jitter, definitivamente habrá algunos fotogramas que son problemáticos. Entre ellos, debe haber un marco de dibujo máximo y un marco de dibujo mínimo, por lo que el valor promedio, el valor máximo y el valor mínimo son todo lo que necesitamos saber.
Antes de hablar de la colección, tenemos que hablar brevemente sobre las dos cosas Choreographery LooperPrinter.
Coreógrafo (coreógrafo)
Coreógrafo se traduce como "director de danza" en chino, que literalmente significa dirigir con gracia las tres operaciones de IU anteriores para bailar una danza juntos. Esta palabra puede resumir este tipo de trabajo. Si el sistema Android es un ballet, es la coreografía de este maravilloso espectáculo de danza que se muestra en la interfaz de usuario de Android. Los actores en el podio cooperan entre sí y realizan maravillosas actuaciones. ¡Parece que a los ingenieros de Google les gusta bailar!
Entre ellos, puede consultar este artículo para la introducción de Choreographer. Esta pregunta se hace a menudo durante entrevistas, como ViewRootImp y Vsync, etc., pero aún estamos más enfocados en la recopilación de datos y la presentación de informes, por lo que el foco de atención es todavía un poco diferente.
Generalmente, el Choreographercoreógrafo dibujado por el hilo de la interfaz de usuario puede dibujar la colección de Fps convencional . El coreógrafo es un singleton de ThreadLocal, que recibe la señal vsync para representar la interfaz. Siempre que le agreguemos un CallBack, podemos calcular el marco ingeniosamente. El tiempo de dibujo.
Matrix Choreographeres el CallbackQueuegancho adecuado para el núcleo , addCallbackLockedagregando ganchos personalizados a las cabezas de diferentes tipos de colas de devolución de llamada a través de ganchos FrameCallback. Por lo tanto, el sistema CALLBACK_INPUT = tiempo de inicio personalizado CALLBACK_ANIMATION tiempo de inicio personalizado CALLBACK_INPUT tiempo de finalización CALLBACK_ANIMATION = tiempo de inicio personalizado CALLBACK_TRAVERSAL tiempo de inicio personalizado CALLBACK_ANIMATION sistema de tiempo de inicio CALLBACK_TRAVERSAL = msg dipatch tiempo de finalización personalizado CALLBACK_TRAVERSAL tiempo de inicio
LooperPrinter
En primer lugar, primero debemos tener un concepto, todo lo relacionado con la vista y el ciclo de vida se ejecutan en el hilo principal. Entonces, ¿hay alguna manera de monitorear el consumo de tiempo del hilo principal?
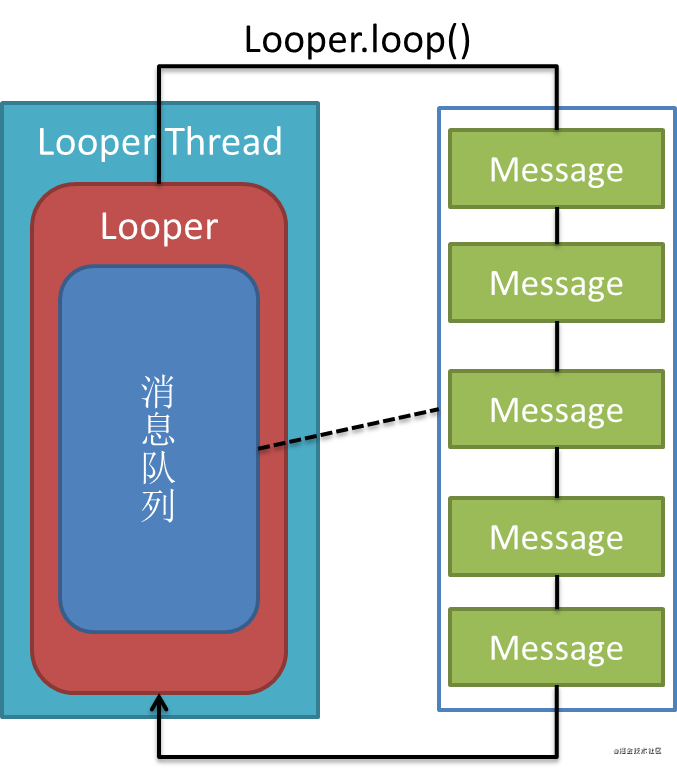
Conocemos cómo se realiza un disco Handler, en primer lugar Looperdesde el MessageQueueadquirido hasta Message, después de la determinación del Mensaje interno Handlero se Runnabledecide realizar una operación posterior.
A partir del ActivityThreadanálisis, todas las operaciones del hilo principal se ejecutan en el hilo principal Looper, por lo que siempre que ejecutemos Looperel loopmétodo Messageantes y después de la adquisición y escribamos el código en el hilo principal , ¿podemos monitorear el Messagetiempo de ejecución?
public static void loop() {
final Looper me = myLooper();
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
final MessageQueue queue = me.mQueue;
// Make sure the identity of this thread is that of the local process,
// and keep track of what that identity token actually is.
Binder.clearCallingIdentity();
final long ident = Binder.clearCallingIdentity();
// Allow overriding a threshold with a system prop. e.g.
// adb shell 'setprop log.looper.1000.main.slow 1 && stop && start'
final int thresholdOverride =
SystemProperties.getInt("log.looper."
+ Process.myUid() + "."
+ Thread.currentThread().getName()
+ ".slow", 0);
boolean slowDeliveryDetected = false;
for (;;) {
Message msg = queue.next(); // might block
if (msg == null) {
// No message indicates that the message queue is quitting.
return;
}
// This must be in a local variable, in case a UI event sets the logger
final Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
...
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
Desde el código fuente, podemos ver que Looperuna Printerclase está reservada al principio, y el Printermétodo se ejecutará después de que comience la ejecución del Mensaje y después de que finalice la ejecución del Mensaje . Podemos looper.setMessageLogging(new LooperPrinter());método para configurar el monitoreo.
IdleHandler
Cuando Looperel MessageQueuecaso está vacío, se dispara IdleHandler, por lo que el hilo principal Caton, generalmente junto con el reinicio, consume mucho tiempo, por lo que podemos garantizar cuando el hilo principal está vacío, el método de cálculo que consume mucho tiempo no saldrá mal.
UIThreadMonitor (supervisión del hilo principal)
Después de una breve introducción a algunas cosas en la parte superior, esta parte del código de muestra real para nuestra colección de Fps que hice referencia en Matrixel UIThreadMonitor, y UIThreadMonitorse hace mediante una combinación de lo anterior.
private void dispatchEnd() {
long traceBegin = 0;
if (config.isDevEnv()) {
traceBegin = System.nanoTime();
}
long startNs = token;
long intendedFrameTimeNs = startNs;
if (isVsyncFrame) {
doFrameEnd(token);
intendedFrameTimeNs = getIntendedFrameTimeNs(startNs);
}
long endNs = System.nanoTime();
synchronized (observers) {
for (LooperObserver observer : observers) {
if (observer.isDispatchBegin()) {
observer.doFrame(AppMethodBeat.getVisibleScene(), startNs, endNs, isVsyncFrame, intendedFrameTimeNs, queueCost[CALLBACK_INPUT], queueCost[CALLBACK_ANIMATION], queueCost[CALLBACK_TRAVERSAL]);
}
}
}
dispatchTimeMs[3] = SystemClock.currentThreadTimeMillis();
dispatchTimeMs[1] = System.nanoTime();
AppMethodBeat.o(AppMethodBeat.METHOD_ID_DISPATCH);
synchronized (observers) {
for (LooperObserver observer : observers) {
if (observer.isDispatchBegin()) {
observer.dispatchEnd(dispatchTimeMs[0], dispatchTimeMs[2], dispatchTimeMs[1], dispatchTimeMs[3], token, isVsyncFrame);
}
}
}
this.isVsyncFrame = false;
if (config.isDevEnv()) {
MatrixLog.d(TAG, "[dispatchEnd#run] inner cost:%sns", System.nanoTime() - traceBegin);
}
}
UIThreadMonitorNo es lo mismo, y los dispatchEndmétodos tienen algunos de LooperMonitorlos aceptados.
Y estableció uno LooperMonitorpor Looperel setMessageLoggingmétodo del hilo principal LooperPrinter. dispatchEndUna vez finalizada la ejecución del método del hilo principal, el Choreographerdibujo actual Vsync y el tiempo de renderizado se obtienen a través de la reflexión . Finalmente, cuando se activa IdleHandler, el tiempo se restablece LooperPrinter, para evitar el cálculo lento del método cuando el hilo principal está inactivo.
Matrix LoopMonitor, el portal de esta parte de la generación de fuentes
¿Por qué dar la vuelta a un gran círculo para monitorear Fps? ¿Cuáles son los beneficios de escribir de esta manera? Específicamente fui a buscar el siguiente Wiki oficial de Matrix , el BlockCanarycódigo de referencia de Martix , a través de una combinación de menor Choreographery BlockCanary, cuando Caton marco para obtener la pila de subprocesos principal actual de Caton, y luego por LooperPrinterla pila actual de salida del Método de Caton, que puede ayudar mejor a la desarrollo para localizar el problema atascado, en lugar de decirle directamente al lado comercial que su página está atascada.
Análisis de muestreo
El artículo comenzó a plantear una pregunta: si se informa de todos los datos recopilados, en primer lugar, se generará una gran cantidad de presión de datos no válidos en el servidor y, en segundo lugar, se informará de muchos datos no válidos, entonces, ¿qué se debe hacer?
En este artículo, nos referimos al código de Matrix. Primero, los datos de Fps no se pueden reportar en tiempo real. En segundo lugar, es mejor filtrar los datos problemáticos de los datos dentro de un período de tiempo. Hay algunos pequeños detalles sobre la colección Fps de Matrix. Es muy buena.
- Retraso de 200 milisegundos. Primero recopile 200 cuadros de datos, luego analice el contenido de los datos, filtre y recorra el cuadro más grande, el cuadro más pequeño y el cuadro promedio, y luego guarde los datos en la memoria.
- El subproceso secundario procesa los datos y las operaciones de filtrado y transversal se mueven al subproceso secundario, para evitar que APM cause problemas de bloqueo de la aplicación.
- Los datos de 200 milisegundos solo se utilizan como uno de los fragmentos de datos. El nodo de informes de Matrix se informa durante un período de tiempo más largo. Cuando el tiempo excede aproximadamente 1 minuto, se informa como un fragmento de problema.
- La recopilación de datos no es necesaria para la conmutación de front-end y back-end.
private void notifyListener(final String focusedActivity, final long startNs, final long endNs, final boolean isVsyncFrame,
final long intendedFrameTimeNs, final long inputCostNs, final long animationCostNs, final long traversalCostNs) {
long traceBegin = System.currentTimeMillis();
try {
final long jiter = endNs - intendedFrameTimeNs;
final int dropFrame = (int) (jiter / frameIntervalNs);
droppedSum += dropFrame;
durationSum += Math.max(jiter, frameIntervalNs);
synchronized (listeners) {
for (final IDoFrameListener listener : listeners) {
if (config.isDevEnv()) {
listener.time = SystemClock.uptimeMillis();
}
if (null != listener.getExecutor()) {
if (listener.getIntervalFrameReplay() > 0) {
listener.collect(focusedActivity, startNs, endNs, dropFrame, isVsyncFrame,
intendedFrameTimeNs, inputCostNs, animationCostNs, traversalCostNs);
} else {
listener.getExecutor().execute(new Runnable() {
@Override
public void run() {
listener.doFrameAsync(focusedActivity, startNs, endNs, dropFrame, isVsyncFrame,
intendedFrameTimeNs, inputCostNs, animationCostNs, traversalCostNs);
}
});
}
} else {
listener.doFrameSync(focusedActivity, startNs, endNs, dropFrame, isVsyncFrame,
intendedFrameTimeNs, inputCostNs, animationCostNs, traversalCostNs);
}
...
}
}
}
}
Lo anterior es el código fuente de Matirx, donde podemos ver que listener.getIntervalFrameReplay() > 0cuando se dispara esta condición, el oyente realizará primero una operación de recolección, y después de que se dispara una cierta cantidad de datos, se disparará la lógica posterior. En segundo lugar, podemos ver el juicio null != listener.getExecutor(), por lo que esta parte de la operación recopilada se ejecuta en el grupo de subprocesos.
private class FPSCollector extends IDoFrameListener {
private Handler frameHandler = new Handler(MatrixHandlerThread.getDefaultHandlerThread().getLooper());
Executor executor = new Executor() {
@Override
public void execute(Runnable command) {
frameHandler.post(command);
}
};
private HashMap<String, FrameCollectItem> map = new HashMap<>();
@Override
public Executor getExecutor() {
return executor;
}
@Override
public int getIntervalFrameReplay() {
return 200;
}
@Override
public void doReplay(List<FrameReplay> list) {
super.doReplay(list);
for (FrameReplay replay : list) {
doReplayInner(replay.focusedActivity, replay.startNs, replay.endNs, replay.dropFrame, replay.isVsyncFrame,
replay.intendedFrameTimeNs, replay.inputCostNs, replay.animationCostNs, replay.traversalCostNs);
}
}
public void doReplayInner(String visibleScene, long startNs, long endNs, int droppedFrames,
boolean isVsyncFrame, long intendedFrameTimeNs, long inputCostNs,
long animationCostNs, long traversalCostNs) {
if (Utils.isEmpty(visibleScene)) return;
if (!isVsyncFrame) return;
FrameCollectItem item = map.get(visibleScene);
if (null == item) {
item = new FrameCollectItem(visibleScene);
map.put(visibleScene, item);
}
item.collect(droppedFrames);
if (item.sumFrameCost >= timeSliceMs) { // report
map.remove(visibleScene);
item.report();
}
}
}
private class FrameCollectItem {
String visibleScene;
long sumFrameCost;
int sumFrame = 0;
int sumDroppedFrames;
// record the level of frames dropped each time
int[] dropLevel = new int[DropStatus.values().length];
int[] dropSum = new int[DropStatus.values().length];
FrameCollectItem(String visibleScene) {
this.visibleScene = visibleScene;
}
void collect(int droppedFrames) {
float frameIntervalCost = 1f * UIThreadMonitor.getMonitor().getFrameIntervalNanos() / Constants.TIME_MILLIS_TO_NANO;
sumFrameCost += (droppedFrames + 1) * frameIntervalCost;
sumDroppedFrames += droppedFrames;
sumFrame++;
if (droppedFrames >= frozenThreshold) {
dropLevel[DropStatus.DROPPED_FROZEN.index]++;
dropSum[DropStatus.DROPPED_FROZEN.index] += droppedFrames;
} else if (droppedFrames >= highThreshold) {
dropLevel[DropStatus.DROPPED_HIGH.index]++;
dropSum[DropStatus.DROPPED_HIGH.index] += droppedFrames;
} else if (droppedFrames >= middleThreshold) {
dropLevel[DropStatus.DROPPED_MIDDLE.index]++;
dropSum[DropStatus.DROPPED_MIDDLE.index] += droppedFrames;
} else if (droppedFrames >= normalThreshold) {
dropLevel[DropStatus.DROPPED_NORMAL.index]++;
dropSum[DropStatus.DROPPED_NORMAL.index] += droppedFrames;
} else {
dropLevel[DropStatus.DROPPED_BEST.index]++;
dropSum[DropStatus.DROPPED_BEST.index] += Math.max(droppedFrames, 0);
}
}
}
Esta parte del código es la lógica de que Matrix realiza el procesamiento de datos en un segmento de trama. Se puede ver que el collectmétodo ha filtrado los datos de múltiples latitudes, como la más grande y la más pequeña, lo que enriquece un segmento de datos. Cuantos más datos haya en este lugar, más puede ayudar a un problema de posicionamiento de desarrollo.
La lógica de adquisición también se refiere a esta parte del código de Matrix, pero se encontró un pequeño error en la fase de prueba real, porque el informe es un segmento de tiempo relativamente grande. Después de que el usuario cambia de página, los datos de fps de la página anterior aparecerán también se considerará como la página siguiente Informe de datos para cada página.
Así que hemos agregado uno ActivityLifeCycle, cuando la página cambie, se realizará una operación de informe de datos. En segundo lugar, ajustamos la lógica de cambiar entre la parte frontal y posterior de Matrix y la reemplazamos por una más confiable ProcessLifecycleOwner.
CPU y memoria
El uso de la memoria y la CPU puede ayudarnos a detectar mejor la situación real de los usuarios en línea, en lugar de esperar a que el usuario se bloquee, podemos revertir el problema y podemos filtrar diferentes datos de la página de acuerdo con la dimensión de la página para facilitar el desarrollo. y análisis del problema correspondiente.
Después de ganar experiencia en Fps, agregamos la recopilación de datos de CPU y memoria sobre esta base. En términos relativos, podemos aprender de mucha lógica de adquisición y luego solo necesitamos ajustar los datos clave.
- Los datos se recopilan en el subproceso para evitar que el subproceso principal se atasque en la recopilación de datos.
- Al mismo tiempo, los datos se recopilan una vez por segundo, el contenido de los datos se analiza localmente y se calcula el valor promedio de los valores pico y valle.
- El nodo de informe de datos se divide, la página se cambia dentro de un cierto período de tiempo y se generan datos.
- Combine los datos de la CPU y la memoria e infórmelos como la misma estructura de datos para optimizar los problemas de flujo de datos.
Recolección de datos de memoria
Para los datos de la memoria, nos referimos al código de Dokit. También hay diferencias entre la alta y la baja versiones. La versión de alta directamente puede Debug.MemoryInfo()obtener los datos de la memoria, y las necesidades versión de baja amsa ActivityManagerobtener los datos de ella.
La siguiente es la clase de herramienta de recopilación de rendimiento que recopila datos de la CPU al mismo tiempo, puede usarla directamente.
object PerformanceUtils {
private var CPU_CMD_INDEX = -1
@JvmStatic
fun getMemory(): Float {
val mActivityManager: ActivityManager? = Hasaki.getApplication().getSystemService(Context.ACTIVITY_SERVICE)
as ActivityManager?
var mem = 0.0f
try {
var memInfo: Debug.MemoryInfo? = null
if (Build.VERSION.SDK_INT > 28) {
// 统计进程的内存信息 totalPss
memInfo = Debug.MemoryInfo()
Debug.getMemoryInfo(memInfo)
} else {
//As of Android Q, for regular apps this method will only return information about the memory info for the processes running as the caller's uid;
// no other process memory info is available and will be zero. Also of Android Q the sample rate allowed by this API is significantly limited, if called faster the limit you will receive the same data as the previous call.
val memInfos = mActivityManager?.getProcessMemoryInfo(intArrayOf(Process.myPid()))
memInfos?.firstOrNull()?.apply {
memInfo = this
}
}
memInfo?.apply {
val totalPss = totalPss
if (totalPss >= 0) {
mem = totalPss / 1024.0f
}
}
} catch (e: Exception) {
e.printStackTrace()
}
return mem
}
/**
* 8.0以下获取cpu的方式
*
* @return
*/
private fun getCPUData(): String {
val commandResult = ShellUtils.execCmd("top -n 1 | grep ${Process.myPid()}", false)
val msg = commandResult.successMsg
return try {
msg.split("\\s+".toRegex())[CPU_CMD_INDEX]
} catch (e: Exception) {
"0.5%"
}
}
@WorkerThread
fun getCpu(): String {
if (CPU_CMD_INDEX == -1) {
getCpuIndex()
}
if (CPU_CMD_INDEX == -1) {
return ""
}
return if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.O) {
getCpuDataForO()
} else {
getCPUData()
}
}
/**
* 8.0以上获取cpu的方式
*
* @return
*/
private fun getCpuDataForO(): String {
return try {
val commandResult = ShellUtils.execCmd("top -n 1 | grep ${Process.myPid()}", false)
var cpu = 0F
commandResult.successMsg.split("\n").forEach {
val cpuTemp = it.split("\\s+".toRegex())
val cpuRate = cpuTemp[CPU_CMD_INDEX].toFloatOrNull()?.div(Runtime.getRuntime()
.availableProcessors())?.div(100) ?: 0F
cpu += cpuRate
}
NumberFormat.getPercentInstance().format(cpu)
} catch (e: Exception) {
""
}
}
private fun getCpuIndex() {
try {
val process = Runtime.getRuntime().exec("top -n 1")
val reader = BufferedReader(InputStreamReader(process.inputStream))
var line: String? = null
while (reader.readLine().also { line = it } != null) {
line?.let {
line = it.trim { it <= ' ' }
line?.apply {
val tempIndex = getCPUIndex(this)
if (tempIndex != -1) {
CPU_CMD_INDEX = tempIndex
}
}
}
}
} catch (e: Exception) {
e.printStackTrace()
}
}
private fun getCPUIndex(line: String): Int {
if (line.contains("CPU")) {
val titles = line.split("\\s+".toRegex()).toTypedArray()
for (i in titles.indices) {
if (titles[i].contains("CPU")) {
return i
}
}
}
return -1
}
}
Colección de CPU
El código de recopilación de datos de la CPU también está en él. Esta parte del código es relativamente simple. La complejidad radica en la línea de comandos y la adaptación de la versión. También es necesario distinguir la versión del sistema al obtenerla, tanto la versión alta como la baja se obtienen a través del comando cmd, el cual soluciona el problema de falla en la obtención del CpuId de la versión baja. Luego optimizó la lógica del código de DoKit. ShellUtilsPuede consultar Blankla colección de herramientas escritas.
para resumir
Los datos de Fps, cpu y memoria solo se pueden considerar como el enlace más simple en Apm. El propósito real de Apm es ayudar mejor a los desarrolladores a localizar problemas en línea y evitar problemas en línea a través de mecanismos de alerta temprana. Monitoreo del rendimiento. Sin embargo, es necesario recopilar más datos sobre el comportamiento del usuario en el seguimiento para ayudar al desarrollo a localizar con mayor precisión los problemas en línea.
Porque apoyarse en los hombros de gigantes, de hecho, la dificultad de esta parte del desarrollo es relativamente menor, pero todavía hay espacio para la optimización. Por ejemplo, actualmente solo monitoreamos los cambios en la Actividad. ¿Hay alguna manera de seguir? el fragmento ¿Hay alguna forma de extraer más información sobre el contenido de los datos?
El siguiente artículo le presentará el contenido relacionado con el monitoreo de lectura y escritura de IO en Apm. La cantidad de modificación mágica en esta parte del código aquí es un poco mayor. Básicamente, ya lo hice aquí, pero el contenido puede ser Todavía tengo que reorganizarlo.
Dirección original: https://juejin.cn/post/6890754507639095303
Además, este artículo se ha incluido en el proyecto de código abierto: https://github.com/xieyuliang/Note-Android , que contiene rutas de programación de autoaprendizaje en diferentes direcciones, una colección de preguntas de entrevista / sutras faciales y un serie de artículos técnicos, etc. Los recursos se actualizan continuamente en…
Compártelo aquí esta vez, nos vemos en el próximo artículo .