Escribir al frente
Ya he escrito publicaciones de blog relacionadas con AQS antes, por lo que este artículo escribirá sobre los componentes de sincronización relacionados con AQS.
AQS es un marco básico proporcionado en Java para crear componentes de sincronización. Proporciona gestión básica del estado de sincronización, bloqueo de subprocesos, puesta en cola y mecanismos de activación. Esto facilita al usuario personalizar el componente de sincronización.
En el paquete concurrente de Java, muchos componentes también usan AQS.
Presentemos brevemente los componentes de sincronización más utilizados en AQS.
Aquí clasificamos de acuerdo con el método de intercambio de recursos de AQS:
- Exclusivo: ReentrantLock
- Compartido: Semaphore, CountDownLatch, CycliBarrier
- Exclusivo + compartido: bloqueo de lectura y escritura
ReentrantLock
Bloqueo reentrante Como su
nombre lo indica, este componente es un bloqueo (implementa la interfaz de bloqueo), que permite continuar adquiriendo el bloqueo cuando se ha adquirido el objeto de bloqueo.
(Synchronized puede volver a ingresar implícitamente al bloqueo)
Entonces, cuando ReentrantLock sostiene el objeto de bloqueo, vuelve a llamar al método lock () para adquirir el bloqueo sin ser bloqueado.
En cuanto a cómo implementarlo, veamos el código fuente. Aquí primero veremos la implementación de bloqueos injustos. En cuanto a la diferencia entre justicia e injusticia, la veremos más adelante.
La siguiente es la adquisición del candado injusto AQS integrado en el código fuente de ReentrantLock:
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
//如果状态为0,则意为无锁状态,可以获取
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
//如果有锁,判断持锁线程是不是自己
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
Aquí está ReentrantLock reescribiendo el método tryAcquire de AQS, en el que se llama al método nonFairlyAcquire de forma predeterminada.
- Si el estado de sincronización es 0, significa un estado sin bloqueo y puede obtener
- Si hay un bloqueo, determine si el hilo que sujeta el bloqueo es él mismo. Si es uno mismo, continúe aumentando la variable de estado de sincronización.
De esta forma, la lógica es muy clara.
Echemos un vistazo al método tryRelease:
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
emmmm corresponde a la adquisición. Es necesario determinar si el bloqueo lo mantiene usted mismo y luego reducir la variable de estado de sincronización.
En conclusión:
- Para los bloqueos reentrantes, el valor de su variable de estado de sincronización es infinito positivo 0, donde 0 es sin bloqueo y distinto de cero es el número de bloqueos que hay.
- Cuántas veces se agrega el candado, el candado debe liberarse cuántas veces para liberar el candado con éxito.
- Solo el hilo que actualmente sostiene el candado puede adquirir el candado nuevamente.
Echemos un vistazo al concepto de bloqueo justo e injusto y cómo se refleja en ReentrantLock.
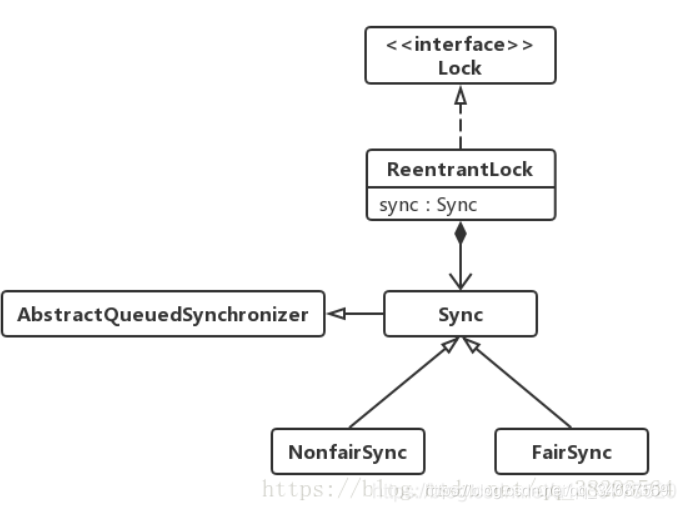
(Fuente de la imagen: https://www.cnblogs.com/a1439775520/p/12947010.html) Lo
anterior es el diagrama de estructura de clases de ReentrantLock.
Solo necesitamos mirar los métodos tryAcquire de NonFairSync y FairSync para comprender la diferencia entre equidad e injusticia.
El siguiente es el código fuente obtenido de manera justa:
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&//**看这里**
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
En comparación con el método nonfairTryAcquire anterior, encontramos que solo hay una diferencia, es decir, cuando c == 0, se juzga un método hasQueuePredecessors más.
public final boolean hasQueuedPredecessors() {
// The correctness of this depends on head being initialized
// before tail and on head.next being accurate if the current
// thread is first in queue.
Node t = tail; // Read fields in reverse initialization order
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
Mire la declaración de devolución en la última línea:
h!=t, Si es igual, significa que la cola está vacía, si no es igual, significa que hay al menos dos nodos diferentesh.next==nullSi no está vacío, hay nodos sucesores.s.thread != Thread.currentThread(), Si son iguales, significa que su nodo predecesor es el nodo principal, y es su turno de competir, por lo que, por supuesto, pueden competir.
En general, el método es juzgar si la cola está vacía, o cuando la cola no está vacía, si su predecesor es el nodo principal, para que los bordes puedan competir. En otros casos, devuelve verdadero y no puede competir.
En resumen, determine si hay otros subprocesos esperando en la cola, si está esperando, hágalo obedientemente, de lo contrario compita directamente.
Permítanme citar un ejemplo de este tipo para ilustrar las cerraduras justas y las cerraduras injustas.
- Fair lock: La cantina sirve comidas, y al principio, todos y cada uno de los que vienen a servir las comidas irán directamente a servir las comidas. Cuando hay demasiada gente empieza a hacer fila. El recién llegado descubrió que había una línea y, honestamente, fue directamente a la línea.
- Cerradura injusta: La cantina está sirviendo comida, nadie al principio, y todo el que viene a comer directamente va al restaurante. Cuando hay demasiada gente empieza a hacer fila. En ese momento, el recién llegado descubrió que había una fila, que no era buena, y saltó a la ventana para agarrar comida. Si el agarre tiene éxito, se le servirá la cena, si falla, los demás lo culparán (ficción) y llegará al final de la línea obedientemente.
Por supuesto, ambos tienen sus pros y sus contras. Fair lock puede garantizar equidad y garantizar FIFO.
El rendimiento de bloqueos injustos es grande, porque no es necesario activar los nodos posteriores, lo que ahorra muchos gastos generales.
Sin embargo, las cerraduras injustas pueden causar hambre. Cuando usted es un usuario común que va al banco para hacer negocios, hace cola y siempre hay VIP en frente de la cola, ¿dice que tiene hambre? Lo he encontrado y tmd es realmente molesto.
Semáforo
Generalmente conocido como semáforo , se implementa principalmente, permitiendo el acceso a un recurso y permitiendo que N subprocesos accedan a él al mismo tiempo.
Mire directamente el código fuente, el código fuente de Semaphore es todavía relativamente pequeño.
También hay conceptos de equidad e injusticia en Semaphore Parece que no es fácil hablar de bloqueo.
Mira su acceso justo:
protected int tryAcquireShared(int acquires) {
for (;;) {
if (hasQueuedPredecessors())
return -1;
int available = getState();
int remaining = available - acquires;
if (remaining < 0 ||
compareAndSetState(available, remaining))
return remaining;
}
}
Al igual que ReentrantLock, hay poca diferencia entre justicia e injusticia.
La lógica aquí también es muy simple, si hasQueuedPrecessors, falla.
Si el parámetro negativo del estado de sincronización actual (normalmente 1) es menor que 0, significa que la adquisición ha fallado, abandona la adquisición y vuelve directamente al resto (número negativo). (La variable de estado de sincronización mayor que 0 significa que el hilo también puede obtener recursos)
Semaphore llama al método de plantilla en AQS. Cuando la adquisición falla, se agrega a la cola de sincronización y luego se bloquea.
Luego sobre el lanzamiento, el código fuente aquí es:
public void release(int permits) {
if (permits < 0) throw new IllegalArgumentException();
sync.releaseShared(permits);
}
Cuando la variable de estado de sincronización> = 0, se llamará al método de plantilla releaseShared de AQS.
En general, Semaphore limita la cantidad de subprocesos que pueden acceder a los recursos sincronizados.
CountDownLatch
Su función es dejar que varios subprocesos esperen varios subprocesos.
Generalmente, tenemos que implementar un hilo para esperar otro hilo. A menudo usamos los métodos wait () y notificar () de la variable de bloqueo,
pero eso solo se puede lograr. Cuando el hilo en espera me notifica, habrá un wait () inmediatamente. El hilo se despierta. Al mismo tiempo, va acompañado de la liberación y adquisición de la cerradura, que no puede lograr nuestro efecto.
Lo que queremos es que un grupo de subprocesos espere a que termine todo el grupo de subprocesos antes de continuar.
Entonces, CountDownLatch nos ayudó a realizar esta idea.

CountDownLatch countDownLatch = new CountDownLatch(3);
Establecemos el contador de CountDownLatch en 3 en el hilo principal,
llamamos a otros hilos, y luego await () y entramos en el bloque. En este momento, cuando otros hilos ejecuten el método countDown, el contador de CountDownLatch disminuirá en 1, y cuando se reduce a 0, se despertará el hilo principal.
Aquí hay un ejemplo para demostrar:
public class CountdownLatchExample {
public static void main(String[] args) throws InterruptedException {
final int totalThread = 10;
CountDownLatch countDownLatch = new CountDownLatch(totalThread);
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < totalThread; i++) {
executorService.execute(() -> {
System.out.print("run..");
countDownLatch.countDown();
});
}
countDownLatch.await();
System.out.println("end");
executorService.shutdown();
}
}
run..run..run..run..run..run..run..run..run..run..end
Aquí para explicar, countdownLatch es una sola vez, y el contador es 0 si es 0, y no se puede restablecer.
En segundo lugar, varios subprocesos en espera continúan ejecutándose después de satisfacer las condiciones. Como condición, los subprocesos en espera pueden continuar ejecutándose o esperando independientemente de si no importa.
Dos usos clásicos de CountDownLatch:
- Un subproceso espera a que n subprocesos terminen de ejecutarse antes de comenzar a ejecutarse. El contador de CountDownLatch se inicializa an: new CountDownLatch (n), cada vez que se ejecuta un subproceso de tarea, el contador disminuye en 1 countdownlatch.countDown (), cuando el valor del contador se convierte en 0, el subproceso de await () en CountDownLatch se despertará. Un escenario de aplicación típico es que al iniciar un servicio, el subproceso principal debe esperar a que se carguen varios componentes antes de continuar.
- Obtenga el máximo paralelismo para que varios subprocesos comiencen a ejecutar tareas. Tenga en cuenta que se trata de paralelismo, no de simultaneidad. Enfatiza que varios subprocesos comienzan a ejecutarse al mismo tiempo. Al igual que en una carrera, se colocan varios hilos en el punto de partida, esperando a que suene el pistoletazo de salida y luego se ejecutan al mismo tiempo. El método consiste en inicializar un objeto CountDownLatch compartido e inicializar su contador a 1: nuevo CountDownLatch (1), varios subprocesos primero countdownlatch.await () antes de comenzar a realizar tareas, y cuando el subproceso principal llama a countDown (), el contador se convierte en 0 Se despiertan varios subprocesos al mismo tiempo. ( Empiece a la misma hora )
(Sobre el código fuente de CountDownLatch, lo agregaré más adelante si es necesario)
CycliBarrier
Valla de bucle
La implementación de CountDownLatch se basa en AQS, mientras que CycliBarrier se basa en ReentrantLock (ReentrantLock también pertenece al sincronizador AQS) y Condition.
/** The lock for guarding barrier entry */
private final ReentrantLock lock = new ReentrantLock();
/** Condition to wait on until tripped */
private final Condition trip = lock.newCondition();
Es una barrera, y su función es asegurar que en una posición, después de que un número suficiente de hilos alcancen esta posición, todos puedan comenzar juntos (similar al inicio simultáneo anterior). Los que llegan temprano esperan, pero los que llegan tarde no tienen prisa.
Debe utilizar el método de construcción predeterminado para especificar el número de subprocesos interceptados por la barrera.
public CyclicBarrier(int parties, Runnable barrierAction) {
if (parties <= 0) throw new IllegalArgumentException();
this.parties = parties;
this.count = parties;
this.barrierCommand = barrierAction;
}
Las partes aquí significan que cuando el número de hilos interceptados alcanza este valor, la valla se abre para dejar pasar todos los hilos.
Y Runnable se refiere a que este método se ejecuta automáticamente cuando se alcanza el valor.
Escenario de aplicación:
CyclicBarrier se puede utilizar para datos de cálculo de subprocesos múltiples y, finalmente, resultados de cálculo combinados. Por ejemplo, usamos Excel para guardar todos los registros bancarios del usuario, y cada hoja guarda los registros bancarios de una cuenta durante el año pasado. Ahora necesitamos contar los registros bancarios promedio diarios del usuario. Primero, use el multihilo para procesar Los registros bancarios en cada hoja. Una vez completadas todas las ejecuciones, se obtiene la rotación bancaria promedio diaria de cada hoja y, finalmente, la barreraAction se utiliza para calcular la rotación bancaria promedio diaria de todo el Excel utilizando los resultados de cálculo de estos hilos.
Cuando el hilo alcanza la barrera, ejecuta el método await (), entra en suspensión y espera otros hilos.
El método dowait se llama en el método await. El código fuente es el siguiente:
private int dowait(boolean timed, long nanos)
throws InterruptedException, BrokenBarrierException,
TimeoutException {
final ReentrantLock lock = this.lock;
lock.lock();
try {
final Generation g = generation;
if (g.broken)
throw new BrokenBarrierException();
if (Thread.interrupted()) {
breakBarrier();
throw new InterruptedException();
}
int index = --count;//将计数器值减1 count是CycliBarrier的一个变量,就是计数器
//当计数器值为0时,则可以放行
if (index == 0) {
// tripped
boolean ranAction = false;
try {
final Runnable command = barrierCommand;
if (command != null)
command.run();
ranAction = true;
//这里是关键
//将count重置
//唤醒之前等待的线程
//下一波执行开始
nextGeneration();
return 0;
} finally {
if (!ranAction)
breakBarrier();
}
}
// loop until tripped, broken, interrupted, or timed out
for (;;) {
try {
if (!timed)
trip.await();
else if (nanos > 0L)
nanos = trip.awaitNanos(nanos);
} catch (InterruptedException ie) {
if (g == generation && ! g.broken) {
breakBarrier();
throw ie;
} else {
// We're about to finish waiting even if we had not
// been interrupted, so this interrupt is deemed to
// "belong" to subsequent execution.
Thread.currentThread().interrupt();
}
}
if (g.broken)
throw new BrokenBarrierException();
if (g != generation)
return index;
if (timed && nanos <= 0L) {
breakBarrier();
throw new TimeoutException();
}
}
} finally {
lock.unlock();
}
}
Como puede ver en mis comentarios, lo más importante aquí es el método nextGeneration:
private void nextGeneration() {
// signal completion of last generation
trip.signalAll();
// set up next generation
count = parties;
generation = new Generation();
}
Como puede ver, este método consiste en restablecer el contador y reactivar todos los demás subprocesos en espera.
Por lo tanto, sabemos que la cerradura CLH utilizada aquí es diferente de AQS.
El hilo anterior está bloqueado.
Cada vez es el último hilo en despertar otros hilos.
Esto también se debe al uso de ReentrantLock y condition.
Comparado con CountDownLatch, CycliBarrier es más como una válvula, es para asegurar que todas las roscas lleguen a una ubicación específica.
Y CountDownLatch se centra más en el concepto de condiciones.
Bloqueo de lectura y escritura
En tiempos normales, hablamos del principio 28, leemos 8 y escribimos 2, y la lectura es segura y la escritura no es segura, de
modo que leer es compartido y escribir es exclusivo.
Estoy un poco cansado aquí, escribiré más tarde.