Sobre HashMap
Este artículo está escrito principalmente en torno a la realización de HashMap.
Se omitirán preguntas simples sobre qué es un HashMap, cómo usarlo y cómo hacer hash.
Al mismo tiempo, antes y después de jdk1.8, HashMap se implementa de diferentes formas y lógicas, por lo que la lógica del método correspondiente también es diferente. Este artículo se centra en el jdk1.8 posterior y, al mismo tiempo, para la comparación.
Al mismo tiempo, este artículo capta principalmente la lógica del código fuente, primero muestra la lógica del código fuente y coloca el espacio anterior como una pantalla lógica, y el código fuente + comentarios se colocan en la parte posterior, de modo que Es fácil de aprender, el contexto es claro, primero aclara la lógica y luego combina el gusto del código fuente.
La estructura básica de HashMap
En primer lugar, la capa inferior de HashMap es una matriz, sin importar la versión, es una matriz
transient Node<K,V>[] table;
Internal contiene un tipo de nodo de tabla de matriz . El nodo hereda de Entry (no más sobre esto)
Antes de jdk1.8,
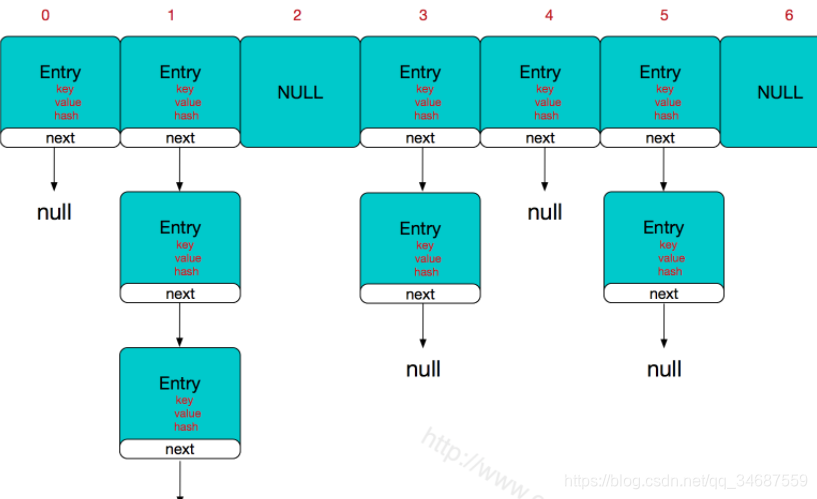
la implementación subyacente de HashMap era una matriz + lista vinculada.
- La matriz se usa como un cubo para almacenar elementos. Después de determinar el cubo a través del valor hash de la clave, colocamos los elementos en el cubo correspondiente (posición de la matriz).
- Entonces, naturalmente, parecerá que dos claves diferentes pueden tener el mismo código hash, y también puede haber dos códigos hash diferentes correspondientes al mismo depósito. Cuando cualquiera de ellos es posible, causará conflictos de hash. En este momento, el vínculo vinculado La lista saldrá para resolver el problema.
- En un depósito, si los nodos existen como una lista vinculada, no habrá conflictos
Como se muestra en la siguiente figura
(https://blog.csdn.net/samniwu/article/details/90550196)
Pero esto también tiene un problema: cuando se consulta una lista enlazada en un depósito, la complejidad del tiempo es O (M), que es demasiado alta y, obviamente, no se ajusta al concepto O (1) aproximado del HashMap.
Entonces fue modificado después de jdk1.8.
Reemplace la lista vinculada anterior con una lista vinculada / estructura de árbol rojo-negro.
Esto garantiza que cuando hay demasiados nodos en el depósito, se utiliza el árbol rojo-negro (árbol de búsqueda binaria equilibrada) para realizar consultas, lo que reduce la complejidad del tiempo de O (M) a O (logM), y el rendimiento mejora considerablemente. .
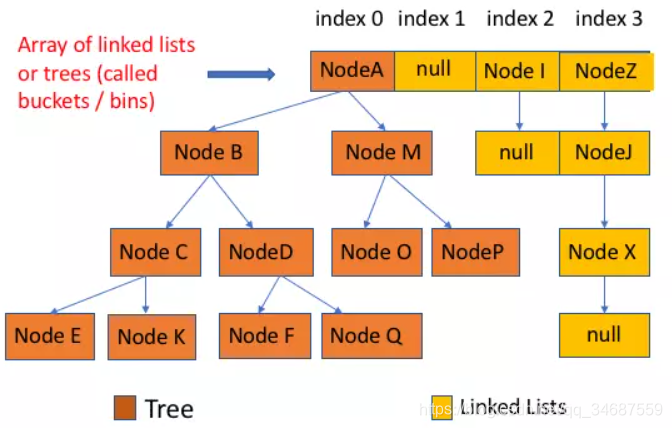
Así que ahora sabemos qué tipo de estructura es hashMap.
Campos y atributos importantes dentro de HashMap
- tabla: es nuestra matriz
capacidad: esto no es un campo, en realidad es la longitud de la matriz, pero es más importante, así que lo publiqué- loadFactor: factor de carga, un factor para calcular el umbral, que se puede utilizar para representar la escasez de datos en la matriz, cuanto más cerca de 1, más denso, más cerca de 0, más escaso
- umbral: umbral, el umbral para juzgar la expansión. umbral = capacidad * loadFactor
nodo:
- Nodo de tipo de lista vinculada
- Nodo de tipo de árbol: heredado de la lista vinculada
Cómo determinar el depósito en función del código hash
Primero obtenga su código hash de acuerdo con el método hash del objeto clave,
y luego perturbelo una vez (h = key.hashCode()) ^ (h >>> 16)(los 16 bits altos permanecen sin cambios, los 16 bits bajos ^ = 16 bits altos).
El propósito de la perturbación es hacer más hash el valor hash para evitar conflictos. (>>> es un cambio lógico a la derecha, el bit alto se llena con 0)
y luego se pasa al método putVal (el núcleo de put) y
luego (n-1) & hash se usa para determinar qué depósito es
(aquí, cuando n es 2 ^ n, el binario de n-1 es todo 1, lo que equivale al hash% n-1, por lo que se puede distribuir de manera más uniforme en cada depósito)
Cuándo expandir y convertir árboles rojo-negro
Expansión
- size> = capacidad * loadFactor: cuando el número de elementos en el HashMap actual es mayor que el umbral, la capacidad debe expandirse
- Cuando los nodos de la lista vinculada en un depósito llegan a 8 (valor predeterminado) y la longitud de la matriz no es suficiente para 64
Convertir árbol rojo-negro
- Cuando el nodo de la lista vinculada en un depósito llega a 8 (valor predeterminado) y la longitud de la matriz llega a 64: En este punto, la longitud de la matriz es lo suficientemente larga y hay demasiados nodos en el depósito actual, y es necesario convertirse en un árbol rojo-negro
Análisis lógico de métodos comunes de HashMap
A continuación, se analizará la lógica del código fuente de métodos comunes para mostrar cómo HashMap realiza operaciones de colocación, cómo expandir y cómo obtenerlas.
Implica principalmente los métodos put, get y resize.
El núcleo del método put put es el método putVal, por lo que aquí examinamos principalmente este método.
putVal:
iftable数组为空,或者长度为0:
resize()
根据传入key定位到哪一个桶((n - 1) & hash)
if 桶是空的:
直接插入
else 桶不为空:
e = null
if桶中第一个元素和当前元素相同(桶相同且hash相同且key相同):
用e来记录这个节点
else if 桶中第一个元素是树节点:
调用红黑树插入方法插入方法(涉及到平衡):
if 存在一个节点,和当前插入元素相同:
e = 该节点
跳出当前方法
红黑树插入
else 桶中第一个元素是链表节点:
if 存在一个节点,和当前插入元素相同:
e = 该节点
跳出当前else
链表插入当前插入元素:
判断是否需要转换红黑树or扩容
if e!=null(当前插入元素已经存在):
新值换旧值
if 当前大小超过了阈值:
resize()
return
La lógica específica se muestra arriba y se
resume aquí:
- Encuentra el balde primero
- El balde está vacío e insértelo directamente, regrese
- El balde no está vacío, verifique si ya existe, si lo está, reemplácelo
- Si no es así, agregue (agregue la lista vinculada o agregue el árbol rojo-negro)
- Determina si necesitas expandirte
get
principalmente llama al método getNode para obtener el nodo
getNode:
if table为空 || table没有元素 || 对应的桶里没有元素:
return null
if 桶里第一个元素就和当前查询元素相同:
return 该节点
if 桶里不只一个节点:
if 节点类型是树:
return 红黑树查询的结果
if 节点类型是链表:
遍历找到节点
return 目标节点
método de cambio de tamaño
resize:
if 旧容量已经大于等于最大容量了:
将threshold置为Integer.MAX_VALUE
return 旧table (不更新)
else 没有超过最大容量:
新容量设置为之前的两倍
更新阈值
创建新的table数组
循环遍历旧table:
重新计算hash,确定桶
将元素插入桶里
return 新table
- La capacidad se ha actualizado al doble de la anterior.
- Necesita crear una nueva matriz, recalcular el hash y luego copiar
- Cambiar el tamaño consume muchos recursos
Comentarios del código fuente
Los comentarios de código en esta parte son de javaGuide,
no hay marca, todos son jdk1.8
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// table未初始化或者长度为0,进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// (n - 1) & hash 确定元素存放在哪个桶中,桶为空,新生成结点放入桶中(此时,这个结点是放在数组中)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// 桶中已经存在元素
else {
Node<K,V> e; K k;
// 比较桶中第一个元素(数组中的结点)的hash值相等,key相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 将第一个元素赋值给e,用e来记录
e = p;
// hash值不相等,即key不相等;为红黑树结点
else if (p instanceof TreeNode)
// 放入树中
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 为链表结点
else {
// 在链表最末插入结点
for (int binCount = 0; ; ++binCount) {
// 到达链表的尾部
if ((e = p.next) == null) {
// 在尾部插入新结点
p.next = newNode(hash, key, value, null);
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
// 跳出循环
break;
}
// 判断链表中结点的key值与插入的元素的key值是否相等
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
// 相等,跳出循环
break;
// 用于遍历桶中的链表,与前面的e = p.next组合,可以遍历链表
p = e;
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) {
// 记录e的value
V oldValue = e.value;
// onlyIfAbsent为false或者旧值为null
if (!onlyIfAbsent || oldValue == null)
//用新值替换旧值
e.value = value;
// 访问后回调
afterNodeAccess(e);
// 返回旧值
return oldValue;
}
}
// 结构性修改
++modCount;
// 实际大小大于阈值则扩容
if (++size > threshold)
resize();
// 插入后回调
afterNodeInsertion(evict);
return null;
}
//jdk1.7
public V put(K key, V value)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
// 先遍历
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i); // 再插入
return null;
}
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 数组元素相等
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 桶中不止一个节点
if ((e = first.next) != null) {
// 在树中get
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 在链表中get
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({
"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}