1.
Ejemplo de código del algoritmo del vecino más cercano (1) K
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 读取数据,预测签到地点
data = pd.read_csv(r"C:\Users\dell\Desktop\机器学习\机器学习代码和资料\数据\train.csv")
# 因为是测试,为了减少运算,只选取一部分数据
data = data.query("x > 2.0 & x < 2.25 & y > 3.5 & y < 3.75")
# 处理数据
# 1 处理时间数据,将把时间戳变成日期格式
time_value = pd.to_datetime(data['time'], unit='s')
# 2 利用上面日期格式转化为字典格式
time_value = pd.DatetimeIndex(time_value)
# 3 利用字典格式给data加上几个日期特征
data['day'] = time_value.day
data['hour'] = time_value.hour
data['weekday'] = time_value.weekday
# 4 删除时间戳
data = data.drop(['time'], axis=1)
# 5 将签到数量小于n的目标删除(place_id >= n)
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 6 删除无意义的特征值row_id
data = data.drop(['row_id'], axis=1)
# 取出数据中的特征值x和目标值y
y = data['place_id']
x = data.drop(['place_id'], axis=1)
# 分割数据,分为测试机和训练集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25)
# 特征工程 y是目标值,自然不用标准化
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
# 进入算法
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
# 得出结果
y_predict = knn.predict(x_test)
# 评价预测结果
score = knn.score(x_test, y_test)
print(score)
(2) Ventajas y desventajas del algoritmo de vecino más cercano K

(3) Ajuste de hiperparámetros y validación cruzada
# 首先要去掉上面knn后面跟的参数选择,然后自己调参
param = {
"n_neighbors": [3, 5, 10]}
# 进行网格搜索,设置超参数和交叉验证的n(cv=n)
gc = GridSearchCV(knn, param_grid=param, cv=4)
gc.fit(x_train, y_train)
# 预测准确率
print("在测试集上准确率:", gc.score(x_test, y_test))
print("在交叉验证当中最好的结果:", gc.best_score_)
print("选择最好的模型是:", gc.best_estimator_)
print("每个超参数每次交叉验证的结果:", gc.cv_results_)
En segundo lugar, el ingenuo algoritmo de Bayes
(1) Principio (fórmula bayesiana)
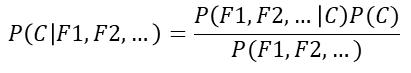
(2) Ejemplo de código
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets import fetch_20newsgroups
# 调用import来的数据
news = fetch_20newsgroups(subset='all')
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 因为是对文本分类,所以要对数据集进行特征抽取
tf = TfidfVectorizer()
# 以训练集当中的词的列表进行每篇文章重要性统计
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# 进行朴素贝叶斯算法的预测
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
# 得出准确率
print("准确率为:", mlt.score(x_test, y_test))
print("每个类别的精确率和召回率:", classification_report(y_test, y_predict, target_names=news.target_names))
3. Evaluación del modelo
(1) Matriz de confusión
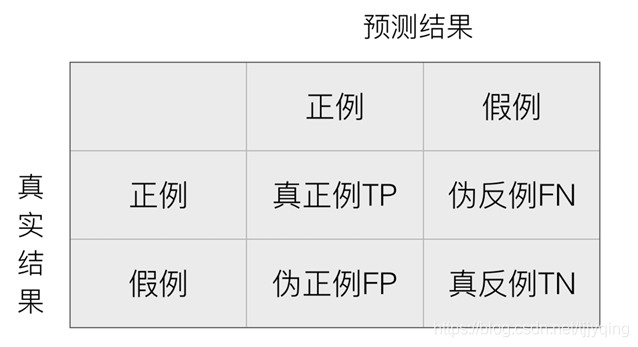
Tasa de precisión: la proporción de la muestra que se predice que será positiva
Tasa de recuerdo: la proporción de muestras cuyos ejemplos positivos reales se predice que serán positivos
F1score: índice de evaluación integral
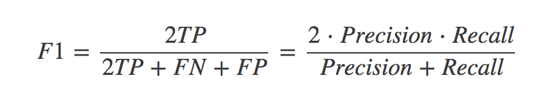
Código de cálculo:
sklearn.metrics.classification_report(y_true, y_pred, target_names=None)
y_true:真实目标值
y_pred:估计器预测目标值
target_names:目标类别名称
return:每个类别精确率与召回率
(2) Validación cruzada
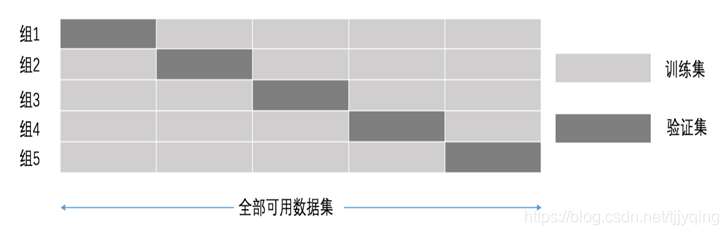
Validación cruzada: divida los datos obtenidos en conjuntos de entrenamiento y validación. Tome la siguiente figura como ejemplo: divida los datos en n partes, una de las cuales se utiliza como conjunto de verificación. Luego, después de n veces (grupos) de pruebas, cada vez se cambia un conjunto de verificación diferente. Es decir, se obtienen los resultados de n grupos de modelos y se toma como resultado final el valor medio. También conocido como validación cruzada de n veces.
Ejemplo: la siguiente imagen muestra una validación cruzada de cinco veces