
Recuerdo vagamente que cuando diseñé un sistema por primera vez, dibujé un montón de diagramas UML (Lenguaje de modelado unificado). Frente al diagrama de clases (de hecho, el modelo de dominio), luché durante mucho tiempo y no sabía cómo Impleméntalo. Porque si sigue este diagrama de clases para eliminar la base de datos, se verá muy extraño y un poco engorroso. Sin embargo, si no sigue este diagrama de clases, no sabe cuál es el uso de este diagrama de clases.
En retrospectiva, mi enredo en ese momento se debió a mi comprensión poco clara de los dos conceptos importantes del modelo de dominio y el modelo de datos. Recientemente, descubrí que la confusión entre estos dos conceptos no es un caso aislado, sino un fenómeno muy común. El resultado es que es lo suficientemente pequeño como para afectar la irracionalidad del diseño de algunos módulos, y lo suficientemente grande como para afectar decisiones técnicas importantes como las oficinas centrales de negocios, porque si la lógica, los conceptos y los fundamentos teóricos subyacentes no están claros, El sistema también tendrá problemas, problemas muy serios.
En vista del hecho de que pocas personas han realizado investigaciones y debates más profundos sobre este tema, creo que es necesario dedicar tiempo a aclarar cuidadosamente estos dos conceptos para ayudar a todos a tomar mejores decisiones de diseño en su trabajo.
Definición conceptual de un modelo de dominio y un modelo de datos
El modelo de dominio se centra en el conocimiento del dominio, que es la entidad central del dominio empresarial y encarna los conceptos clave en el dominio del problema y las conexiones entre conceptos. La clave para el modelado de modelos de dominio es ver si el modelo puede ser explícito y expresar claramente la semántica empresarial, y la escalabilidad es el segundo.
El modelo de datos se centra en el almacenamiento de datos. Todas las empresas no pueden prescindir de los datos y CRUD en los datos. Los factores de decisión del modelado de modelos de datos son principalmente atributos no funcionales como la escalabilidad y el rendimiento, y no es necesario considerar demasiado la semántica empresarial. Capacidad de caracterización.
Según el punto de vista de Robert en "Arquitectura limpia", el modelo de dominio es el núcleo y el modelo de datos es el detalle técnico. Sin embargo, la realidad es que ambos son importantes.
La razón por la que estos dos modelos son fáciles de confundir es que ambos enfatizan las entidades (Entidad) y ambos enfatizan las relaciones (Relación). Este no es el caso. Nuestro modelo de modelo de datos de base de datos tradicional es el diagrama ER.
Sí, los dos tienen algunas cosas en común. A veces, el modelo de dominio y el modelo de datos se parecerán, o incluso convergerán, lo cual es normal. Pero más a menudo, existe una diferencia entre los dos. El enfoque correcto debería ser distinguir conscientemente estos dos modelos y diseñar por separado, porque sus objetivos de modelado serán diferentes. Como se muestra en la figura siguiente, el modelo de datos es responsable del almacenamiento de datos y su esencia es la escalabilidad, la flexibilidad y el rendimiento. El modelo de dominio es responsable de la realización de la lógica empresarial.Su esencia es la expresión explícita de la semántica empresarial y el uso completo de las características OO para aumentar las capacidades de representación empresarial del código.

Sin embargo, la realidad es que muchos de nuestros diseños de sistemas comerciales no distinguen la relación entre los dos. A menudo se cometen dos errores, uno es tratar el modelo de dominio como un modelo de datos y el otro es tratar el modelo de datos como un modelo de dominio.
2 Uso incorrecto del modelo de dominio como modelo de datos
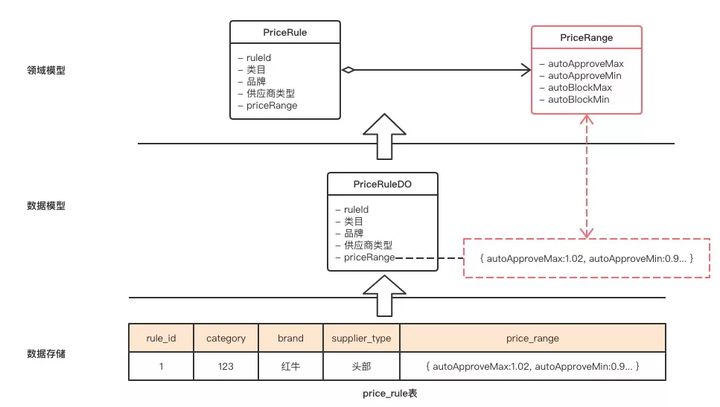
Estoy trabajando en un proyecto de optimización de cotizaciones en estos días, que involucra el tema de reglas de cotización. La lógica comercial de esta pieza es decir que para diferentes productos (diferenciados por categoría, marca, tipo de proveedor, etc.), daremos diferentes rangos de precios y luego determinar si la cotización del comerciante debe aprobarse automáticamente (autoApprove) o debe bloquearse automáticamente (autoBlock).
Para esta regla, el modelo de dominio es muy simple, es decir, proporciona los datos de configuración necesarios para el control de precios, como se muestra en la siguiente figura:

Si diseñamos nuestro almacenamiento de acuerdo con este modelo de dominio, naturalmente necesitamos dos tablas: price_rule y price_range, una para almacenar reglas de precios y la otra para almacenar rangos de precios.

Si diseñamos el modelo de datos de esta manera, cometeremos el error de tratar el modelo de dominio como un modelo de datos. Aquí, es más apropiado usar una tabla como campo, almacenar price_range como un campo en price_rule con un campo, como se muestra en la figura a continuación, y usar un campo JSON para acceder a la información de múltiples rangos de precios en él.

Los beneficios de esto son obvios:
- En primer lugar, el costo de mantener una tabla de base de datos es definitivamente menor que dos.
- En segundo lugar, la escalabilidad de sus datos es mejor. Por ejemplo, cuando surge una nueva demanda, se debe agregar un rango de precios sugerido. Si hay dos tablas, necesito agregar dos nuevos campos en price_range, y si está almacenado en JSON, el modelo de datos puede permanecer sin cambios.
Sin embargo, en código empresarial, hacer cosas basadas en JSON no es tan bueno. Necesitamos convertir los objetos de datos JSON en objetos de dominio con semántica empresarial, de modo que no solo podamos disfrutar de la conveniencia que brinda la escalabilidad del modelo de datos, sino también la legibilidad del código que brinda la explicidad del modelo de dominio para la empresa. semántica Sexo.
Tres errores al usar el modelo de datos como modelo de dominio
De hecho, es mejor que el modelo de datos sea lo más escalable posible. Después de todo, cambiar la base de datos es un gran proyecto. Ya sea agregar campos, restar campos o agregar o eliminar tablas, implica mucho trabajo.
Hablando del diseño de expansión clásico del modelo de datos, el centro de negocios que no es de Alibaba no es otro que el producto principal, el pedido, el pago y las tablas de logística 4. Gracias al buen diseño de escalabilidad, es compatible con docenas de negocios de Ali. Miles de escenarios empresariales.
Tome la estación intermedia de productos básicos como ejemplo, utiliza una tabla vertical Auction_extend para resolver todos los requisitos de escalabilidad de almacenamiento de datos comerciales de productos básicos. En teoría, este modelo de datos puede satisfacer una expansión comercial ilimitada.
Ya sean campos JSON o tablas verticales, aunque puede resolver el problema de las extensiones de almacenamiento de datos, es mejor no tratar estas extensiones (características) como objetos de dominio. De lo contrario, su código no estará orientado en absoluto. La programación de objetos es programación para campos extendidos (características), que comete el error de tratar el modelo de datos como un modelo de dominio. Un mejor enfoque debería ser convertir objetos de datos en objetos de dominio para su procesamiento.
Como se muestra a continuación, este tipo de código está lleno de métodos de escritura getFeature y addFeature, que es una demostración de error típica del uso del modelo de datos como modelo de dominio.

Cuatro modelos de dominio y modelos de datos realizan cada uno sus funciones
Lo anterior muestra los problemas causados por la confusión entre el modelo de dominio y el modelo de datos. El enfoque correcto debería ser distinguir entre el modelo de dominio y el modelo de datos, y dejarles realizar sus funciones, para estructurar nuestro sistema de aplicación de manera más razonable.
Entre ellos, el modelo de dominio está orientado al dominio. Debe ser lo más específico posible y la semántica debe ser lo más clara posible. La expresión explícita de la semántica empresarial es su tarea principal y la escalabilidad es la segunda. El modelo de datos está orientado al almacenamiento de datos y debe ser lo más escalable posible.
En el rellano concreto, podemos adoptar la idea arquitectónica de COLA [1], utilizar la pasarela como pasarela de escape entre el objeto de datos (Objeto de datos) y el objeto de dominio (Entidad). Entre ellos, pasarela, además del rol de escapar, también juega un papel El efecto de anticorrosión y desacoplamiento elimina la dependencia directa del código comercial de los datos subyacentes (DO, DTO, etc.), mejorando así la capacidad de mantenimiento del sistema.

Además, los libros de texto nos enseñan que al diseñar bases de datos relacionales, debemos cumplir con 3NF (tres paradigmas). Sin embargo, en el trabajo real, a menudo rompemos deliberadamente este principio por razones de rendimiento y escalabilidad. Por ejemplo, usaremos la redundancia de datos. Para mejorar rendimiento de acceso, mejoraremos la escalabilidad de las tablas a través de metadatos, tablas verticales y campos de extensión.
Los escenarios comerciales son diferentes y los requisitos para la expansión de datos son diferentes. La expansión de datos de configuración simple como price_rule, JSON puede hacer el trabajo. Para ser más complicado, una tabla vertical como Auction_extend también es una buena opción.
Espera, algunos estudiantes dijeron que si haces esto, los datos se pueden expandir, pero ¿cómo resolver la consulta de datos? No se puede usar la tabla de unión ni usar me gusta. De hecho, para algunos datos de configuración, o datos con una pequeña cantidad de datos, puede gustarle por completo. Sin embargo, para datos masivos como los productos y transacciones de Ali, por supuesto, no puede gustarle, pero este problema se puede resolver fácilmente separando la lectura y la escritura y construyendo la búsqueda.

Cinco pensamientos más sobre la expansión
Finalmente, demos otra pregunta de reflexión.
Las expansiones de datos antes mencionadas son todas expansiones limitadas en el campo. Si ni siquiera sé cuál es el área comercial, ¿puedo expandir los datos? Sí, http://force.com de Salesforce hace esto. Su almacenamiento de datos subyacente está completamente basado en metadatos (basado en metadatos [2]). Utiliza una tabla con 500 campos anónimos para respaldarlo. Para todas las empresas de SaaS, el El significado de cada campo se describe mediante metadatos. Como se muestra en la figura siguiente, value0 a value500 son campos comerciales reservados. Lo que significan está definido por metadatos.

Para ser honesto, este método de implementación es realmente una idea, un diseño muy audaz, y es compatible con las miles de aplicaciones SaaS y el valor de mercado de Salesforce de cientos de miles de millones de dólares.
Es solo que no conozco el mapeo de metadatos a objetos de dominio ¿Cómo lo hace Salesforce específicamente, a través de su apex sintáctico de azúcar? Si no hay un objeto de dominio, ¿cómo escribir su código comercial? De todos modos, según los estudiantes que son proveedores en Salesforce, su llamado Low-Code todavía contiene muchos códigos escritos en Apex, y la capacidad de mantenimiento es promedio.
De todos modos, la mayoría de nuestras aplicaciones están orientadas a determinar los dominios problemáticos y no necesitan proporcionar capacidades de expansión "ilimitadas" como Salesforce. En este caso, creo que los objetos de dominio son el mejor puente entre el modelo de datos y la lógica empresarial.
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.