
1. ¿Qué es la computación gráfica?
Graph data modela un conjunto de objetos (vértices) y sus relaciones (bordes), que pueden representar de forma intuitiva y natural varios objetos de entidad en el mundo real y sus relaciones. En el escenario de big data, las redes sociales, los datos de transacciones, los gráficos de conocimiento, las redes de transporte y comunicación, las cadenas de suministro y la planificación logística son todos ejemplos típicos de modelado de gráficos. La Figura 1 muestra los datos del gráfico de Alibaba en el escenario de comercio electrónico, que tiene varios tipos de vértices (consumidores, vendedores, artículos y dispositivos) y bordes (que representan la relación de compra, vista, comentario, etc.). Además, cada vértice también está asociado con una rica información de atributos.
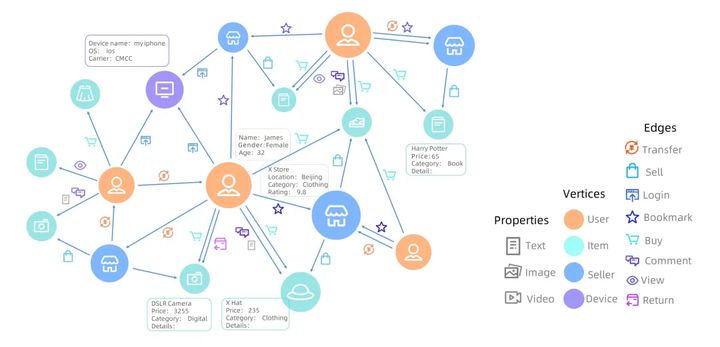
Figura 1: Ejemplo de datos de gráficos de escena de comercio electrónico de Alibaba
Estos datos de gráficos en escenas reales generalmente contienen miles de millones de vértices y billones de aristas. Además de la gran escala, la velocidad de actualización continua de este gráfico también es muy rápida y puede haber casi un millón de actualizaciones por segundo. Con el crecimiento continuo de la escala de aplicación de datos de gráficos en los últimos años, la exploración de las relaciones internas de los datos de gráficos y la computación en datos de gráficos ha recibido cada vez más atención. De acuerdo con los diferentes objetivos de la computación gráfica, se puede dividir aproximadamente en tres tipos de tareas: consulta interactiva, análisis gráfico y aprendizaje automático basado en gráficos.
1 Consulta interactiva de gráficos
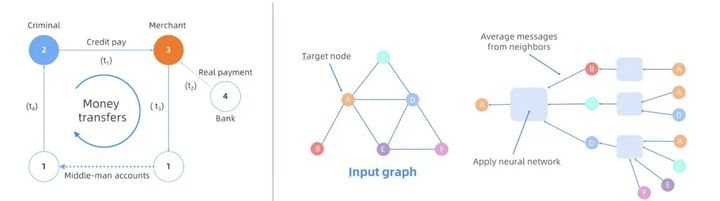
Figura 2: A la izquierda, un ejemplo de lucha contra el fraude financiero; a la derecha, un ejemplo de aprendizaje.
En la aplicación de la computación gráfica, la empresa generalmente necesita ver los datos gráficos de una manera exploratoria para localizar algunos problemas en el tiempo y analizar información en profundidad. El modelo gráfico (simplificado) de la Figura 2 (izquierda) se puede utilizar para fines financieros detección antifraude (efectivo ilegal de la tarjeta de crédito). Mediante el uso de identificadores falsos, los "delincuentes" pueden obtener crédito a corto plazo de los bancos (Vértice 4). Intenta retirar la moneda con la ayuda del comerciante (vértice 3) con una compra falsa (borde 2-> 3). Una vez que se recibe el pago (borde 4-> 3) del banco (vértice 4), el comerciante devuelve el dinero (a través de los bordes 3-> 1 y 1-> 2) al "criminal" a través de varias cuentas bajo su nombre. Este patrón eventualmente forma un bucle cerrado en el gráfico (2-> 3-> 1 ...-> 2). En un escenario real, la escala en línea de los datos del gráfico puede incluir miles de millones de vértices (por ejemplo, usuarios) y cientos de miles de millones a billones de bordes (por ejemplo, transacciones de pago), y todo el proceso de fraude puede involucrar a muchas entidades. La dinámica La cadena de transacciones de diversas restricciones requiere un análisis interactivo complejo en tiempo real para estar bien identificado.
2 Análisis gráfico
La investigación sobre análisis y cálculo de gráficos se ha realizado durante décadas y se han producido muchos algoritmos de análisis de gráficos. Los algoritmos típicos de análisis de gráficos incluyen algoritmos de gráficos clásicos (p. Ej., PageRank, ruta más corta y flujo máximo), algoritmos de detección de comunidades (p. Ej., Camarilla máxima, cálculo de flujo conjunto, Lovaina y propagación de etiquetas), algoritmos de minería de gráficos (p. Ej., Patrón de conjunto frecuente coincidencia entre minería y gráficos). Debido a la diversidad de algoritmos de análisis de gráficos y la complejidad de la computación distribuida, los algoritmos de análisis de gráficos distribuidos a menudo necesitan seguir un determinado modelo de programación. El modelo de programación actual es una especie de modelo central "Think-like-vertex", modelo basado en matrices y modelo basado en subgrafos, etc. Bajo estos modelos, han surgido varios sistemas de análisis de gráficos, como Apache Giraph, Pregel, PowerGraph, Spark GraphX, GRAPE, etc.
3 Aprendizaje automático basado en gráficos
Las tecnologías clásicas de incrustación de gráficos, como Node2Vec y LINE, se han utilizado ampliamente en varios escenarios de aprendizaje automático. La red neuronal gráfica (GNN) propuesta en los últimos años combina la estructura y la información de atributos en la gráfica con las características del aprendizaje profundo. GNN puede aprender representaciones de baja dimensión para cualquier estructura de gráfico en el gráfico (por ejemplo, vértices, bordes o el gráfico completo), y las representaciones generadas se pueden clasificar, predicción de enlaces, agrupamiento, etc. por muchas máquinas relacionadas con gráficos descendentes. tareas de aprendizaje. Se ha demostrado que las técnicas de aprendizaje de gráficos tienen un rendimiento convincente en muchas tareas relacionadas con gráficos. A diferencia de las tareas tradicionales de aprendizaje automático, las tareas de aprendizaje de gráficos implican gráficos y operaciones relacionadas con la red neuronal (consulte la Figura 2 a la derecha). Cada vértice del gráfico utiliza operaciones relacionadas con el gráfico para seleccionar sus vecinos y combinar las características de sus vecinos Converge con neural operaciones de red.
Computación de dos imágenes: la piedra angular de la próxima generación de inteligencia artificial
No solo Alibaba, los datos gráficos y la tecnología informática han sido puntos de acceso en la academia y la industria en los últimos años. En particular, en los últimos diez años, el rendimiento de los sistemas de computación gráfica se ha incrementado de 10 a 100 veces, y el sistema sigue siendo cada vez más eficiente, lo que hace posible acelerar las tareas de inteligencia artificial y big data a través de la computación gráfica. De hecho, porque los gráficos pueden expresar varios tipos complejos de datos de forma muy natural y pueden proporcionar abstracciones para modelos comunes de aprendizaje automático. En comparación con los tensores densos, los gráficos pueden proporcionar una semántica más rica y funciones de optimización más completas. Además, los gráficos son una expresión natural de datos escasos de alta dimensión, y cada vez más estudios en redes convolucionales de gráficos (GCN) y redes neuronales de gráficos (GNN) han demostrado que la computación de gráficos es un complemento eficaz del aprendizaje automático, y los resultados El sexo, el razonamiento profundo, la causalidad, etc. jugarán un papel cada vez más importante.
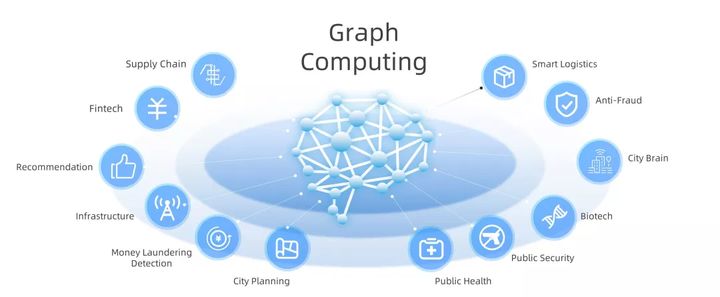
Figura 3: La computación gráfica tiene amplias perspectivas de aplicación en varios campos de la IA
Es previsible que la computación gráfica desempeñe un papel importante en diversas aplicaciones de la inteligencia artificial de próxima generación, incluida la lucha contra el fraude, la logística inteligente, el cerebro urbano, la bioinformática, la seguridad pública, la salud pública, la planificación urbana, la lucha contra el blanqueo de capitales, la infraestructura, Sistema de recomendación, tecnología financiera y cadena de suministro y otros campos.
Estado de cálculo de tres imágenes
Después de estos años de desarrollo, ha habido muchos sistemas y herramientas para diversas necesidades de cálculo de gráficos. Por ejemplo, en términos de consulta interactiva, existen bases de datos de gráficos como Neo4j, ArangoDB y OrientDB, así como sistemas y servicios distribuidos como JanusGraph, Amazon Neptune y Azure Cosmos DB; en términos de análisis de gráficos, hay sistemas como Pregel, Apache Giraph, Spark GraphX y PowerGraph; Hay DGL, pytorch geometric, etc. en el aprendizaje de mapas. Sin embargo, frente a los datos de gráficos ricos y los escenarios de gráficos diversificados, el uso efectivo de la computación de gráficos para mejorar los efectos comerciales aún enfrenta enormes desafíos:
- Los escenarios de cálculo de gráficos en la vida real son diversos y, por lo general, muy complejos, e involucran múltiples tipos de cálculos de gráficos. Los sistemas existentes están diseñados principalmente para tipos específicos de tareas de computación gráfica. Por lo tanto, los usuarios deben descomponer tareas complejas en múltiples trabajos que involucren muchos sistemas. Se pueden generar muchos gastos generales adicionales, como integración, E / S, conversión de formato, red y almacenamiento entre sistemas.
- Es difícil desarrollar aplicaciones para cálculos gráficos a gran escala. Para desarrollar aplicaciones de computación gráfica, los usuarios generalmente usan herramientas simples y fáciles de usar (como NetworkX y TinkerPop en Python) para comenzar con datos gráficos a pequeña escala en una sola máquina. Sin embargo, para los usuarios normales, es extremadamente difícil extender su solución independiente a un entorno paralelo para procesar gráficos a gran escala. Los sistemas distribuidos existentes para gráficos a gran escala generalmente siguen diferentes modelos de programación y carecen de la rica biblioteca de algoritmos / complementos listos para usar en bibliotecas independientes (como NetworkX). Esto hace que el umbral para la computación de gráficos distribuidos sea demasiado alto.
- La escala y la eficiencia del procesamiento de imágenes grandes aún son limitadas. Por ejemplo, debido a la alta complejidad del modo de viaje, el sistema de consulta de gráficos interactivos existente no puede ejecutar consultas de Gremlin en paralelo. Para los sistemas de análisis de gráficos, el modelo de programación tradicional centrado en puntos hace que las técnicas de optimización existentes a nivel de gráfico ya no estén disponibles. Además, muchos sistemas existentes básicamente no están optimizados a nivel de compilador.
Echemos un vistazo a las limitaciones del sistema existente a través de un ejemplo específico.
1 Ejemplo: predicción de clasificación de papel
El conjunto de datos ogbn-mag es un conjunto de datos de Microsoft Academic. Hay cuatro tipos de puntos en los datos, que representan artículos, autores, instituciones y campos de investigación. Entre estos puntos, hay cuatro lados que representan relaciones: el autor "escribió" el artículo y el artículo "citó" otro. En el caso de los artículos, el autor "pertenece a" una institución y el artículo "pertenece" a un campo de investigación. Naturalmente, estos datos se pueden modelar con gráficos.
Un usuario espera realizar una tarea de clasificación en los "artículos" publicados en 2014-2020 en este gráfico, y espera poder basar el artículo en los atributos estructurales del gráfico de datos, sus propias características del tema y el grado de reunión, como kcore y triángulo-conteo.Los parámetros de medición de, categorizarlos y predecir la categoría temática del artículo. De hecho, esta es una tarea muy común y significativa. Esta predicción puede ayudar a los investigadores a descubrir mejor los puntos calientes potenciales de cooperación e investigación en el campo al considerar la relación de citas del artículo y el tema del artículo.
Analicemos esta tarea de cálculo: primero, debemos filtrar el papel y sus puntos y bordes relacionados según el año, y luego debemos calcular el kcore, el conteo de triángulos y otros cálculos de imagen completa en este gráfico, y finalmente combinar Estos dos parámetros y las características originales del mapa se combinan en un marco de aprendizaje automático para el entrenamiento y la predicción de clasificación. Descubrimos que los sistemas actuales existentes no pueden resolver bien este problema de un extremo a otro. Solo podemos operar organizando varios sistemas en una tubería:
Figura 4: Flujo de trabajo compuesto por múltiples sistemas para la clasificación y predicción del papel
Esta tarea parece estar resuelta, de hecho, hay muchos problemas ocultos detrás del esquema del oleoducto. Por ejemplo, varios sistemas son independientes y están separados entre sí, y los datos intermedios se colocan con frecuencia para transferir datos entre sistemas; el programa de análisis de gráficos no es un lenguaje declarativo y no hay un paradigma fijo; la escala del gráfico afecta la eficiencia del marco de aprendizaje automático, etc. Estos son los problemas que a menudo encontramos en escenarios de computación gráfica del mundo real. En resumen, se pueden resumir en los siguientes tres puntos:
- El problema del cálculo del gráfico es muy complicado, el modo de cálculo es diverso y la solución está fragmentada.
- El aprendizaje del cálculo de gráficos es difícil, costoso y tiene un umbral alto.
- La escala del gráfico y la cantidad de datos son grandes, el cálculo es complicado y la eficiencia es baja.
Para resolver los problemas anteriores, diseñamos y desarrollamos un sistema de computación gráfica de código abierto todo en uno: GraphScope.
¿Qué es GraphScope?
GraphScope es una plataforma de computación gráfica integral desarrollada y de código abierto por el Laboratorio de Computación Inteligente de Alibaba Dharma Academy. Basándose en los datos masivos y los ricos escenarios de Ali, y en la investigación de alto nivel de Dharma Academy, GraphScope se compromete a proporcionar soluciones integrales y eficientes a los desafíos mencionados anteriormente en la producción real de cálculos de mapas.
GraphScope proporciona un cliente Python, que puede conectar fácilmente los flujos de trabajo ascendentes y descendentes. Tiene las características de un desarrollo único, conveniente y un rendimiento extremo. Tiene una gestión eficiente de la memoria entre motores, admite la optimización de compilación distribuida de Gremlin por primera vez en la industria y admite la paralelización automática de algoritmos y el procesamiento incremental automático de actualizaciones de gráficos dinámicos, lo que proporciona el máximo rendimiento en escenarios de nivel empresarial. En las aplicaciones internas y externas de Alibaba, GraphScope ha demostrado lograr un nuevo valor comercial importante en múltiples áreas clave de Internet (como control de riesgos, recomendaciones de comercio electrónico, publicidad, seguridad de la red, gráficos de conocimiento, etc.).
GraphScope reúne una serie de resultados de investigación académica de Dharma Academy. Su tecnología central ha ganado el premio al mejor trabajo de SIGMOD2017, el premio a la mejor presentación VLDB2017, el premio VLDB2020 a la mejor nominación de papel y el premio SAIL del concurso mundial de innovación en inteligencia artificial. El documento sobre el motor de consulta interactivo de GraphScope también ha sido aceptado por NSDI 2021 y se publicará pronto. Hay más de una docena de resultados de investigación en torno a GraphScope publicados en las principales conferencias académicas o revistas en el campo, como TODS, SIGMOD, VLDB, KDD, etc.
1 Introducción a la arquitectura
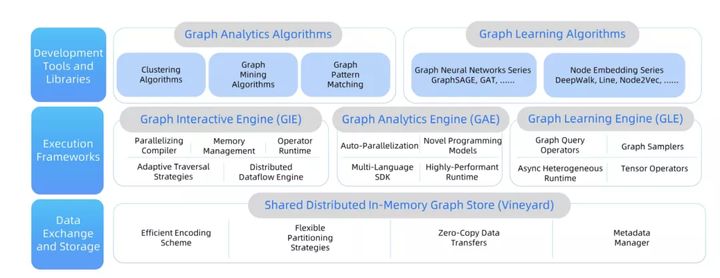
Figura 5: Diagrama de arquitectura del sistema GraphScope
La capa inferior de GraphScope es un viñedo de sistema de gestión de datos de memoria distribuida [1]. Vineyard también es un proyecto nuestro de código abierto. Proporciona una interfaz IO eficiente y rica responsable de interactuar con el sistema de archivos de nivel inferior. Proporciona una abstracción de datos eficiente y de alto nivel (incluidos, entre otros, gráficos, tensor, vector, etc.), admite la gestión de particiones de datos, metadatos, etc., y proporciona lectura de datos nativa de copia cero para aplicaciones de nivel superior. Es este punto el que respalda la capacidad integral de GraphScope: entre motores cruzados, los datos del gráfico existen en el viñedo en forma de particiones y el viñedo los gestiona de manera uniforme.
En el medio está la capa del motor, que está compuesta por el motor de consulta interactivo GIE, el motor de análisis de gráficos GAE y el motor de aprendizaje de gráficos GLE, que presentaremos en detalle en los capítulos siguientes.
La capa superior son las herramientas de desarrollo y las bibliotecas de algoritmos. GraphScope proporciona una variedad de algoritmos de análisis de uso común, incluidos cálculos de conectividad, descubrimiento de comunidades y PageRank, centralidad y otros cálculos numéricos. El paquete de algoritmos continuará expandiéndose en el futuro y brindará compatibilidad con la biblioteca de algoritmos NetworkX en super Gráficos a gran escala Habilidades de análisis. Además, también proporciona un rico paquete de algoritmos de aprendizaje de gráficos, soporte integrado para GraphSage, DeepWalk, LINE, Node2Vec y otros algoritmos.
2 Resuelva el problema: predicción de clasificación de papel
Con GraphScope, una plataforma informática integral, podemos resolver los problemas del ejemplo anterior de una manera más sencilla.
GraphScope proporciona un cliente Python, que permite a los científicos de datos completar todas las tareas relacionadas con el cálculo de gráficos en un entorno con el que están familiarizados. Después de abrir Python, primero debemos establecer una sesión de GraphScope.
import graphscope
from graphscope.dataset.ogbn_mag import load_ogbn_mag
sess = graphscope.sesson()
g = load_ogbn_mag(sess, "/testingdata/ogbn_mag/")En el código anterior, creamos una sesión de GraphScope y cargamos los datos del gráfico.
GraphScope está diseñado para la nube nativa. Detrás de una sesión corresponde a un conjunto de recursos k8s. La sesión es responsable de la aplicación y gestión de todos los recursos en esta sesión. Específicamente, detrás de la línea de código del usuario, la sesión primero solicita un pod del coordinador de back-end. El coordinador es responsable de toda la comunicación con el cliente de Python. Después de completar su inicialización, desplegará un conjunto de módulos de motor. Cada pod de este grupo de pods tiene una instancia de viñedo, que en conjunto forman una capa de gestión de memoria distribuida; al mismo tiempo, cada pod tiene tres motores, GIE, GAE y GLE, y el coordinador determina sus estados de inicio y parada. en el seguimiento de la gestión bajo demanda. Cuando este grupo de pods se levanta y establece una conexión estable con el Coordinador y completa la verificación de estado, el Coordinador regresará al cliente para decirle al usuario que la sesión se ha retirado correctamente y que los recursos están listos para comenzar a cargar imágenes. o cálculos.
interactive = sess.gremlin(g)
# count the number of papers two authors (with id 2 and 4307) have co-authored
papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()Primero, configuramos un objeto de consulta interactivo interactivo en el gráfico g. Este objeto extrae un conjunto de motores de consultas interactivos GIE en el módulo del motor. Luego, la siguiente es una declaración de consulta estándar de Gremlin. El usuario desea ver los artículos de colaboración de dos autores específicos en estos datos. Esta declaración de Gremlin se enviará al motor GIE para su desmontaje y ejecución.
El motor GIE se compone de componentes centrales como el compilador paralelo, la gestión de la memoria y la programación, el tiempo de ejecución del operador, la estrategia de viaje adaptativa y el motor de flujo de datos distribuido. Después de recibir la declaración de consulta interactiva, el compilador primero dividirá la declaración y la compilará en varios operadores de operación. Luego, estos operadores se controlan y ejecutan en un modelo de flujo de datos distribuido. En este proceso, cada nodo de computación que contiene los datos de la partición ejecuta una copia del flujo de datos, procesa los datos en la partición en paralelo y, en el proceso, el intercambio de datos se realiza en -demanda en el sistema, para que las consultas de Gremlin se puedan ejecutar en paralelo.
Bajo la compleja gramática de Gremlin, la estrategia de viaje es muy importante y afecta el paralelismo de la consulta, su elección afecta directamente la ocupación de recursos y el rendimiento de la consulta. Depender simplemente de BFS o DFS no puede satisfacer la demanda en la realidad. La estrategia de viaje óptima a menudo debe ajustarse y seleccionarse dinámicamente en función de consultas y datos específicos. El motor GIE proporciona una configuración de estrategia de viaje adaptativa y selecciona la estrategia de viaje de acuerdo con los datos de la consulta, modelos de Operación y Costo desmontados, con el fin de lograr la eficiencia de la ejecución del operador.
# extract a subgraph of publication within a time range
sub_graph = interactive.subgraph("g.V().has('year', inside(2014, 2020)).outE('cites')")
# project the projected graph to simple graph.
simple_g = sub_graph.project_to_simple(v_label="paper", e_label="cites")
ret1 = graphscope.k_core(simple_g, k=5)
ret2 = graphscope.triangles(simple_g)
# add the results as new columns to the citation graph
sub_graph = sub_graph.add_column(ret1, {"kcore": "r"})
sub_graph = sub_graph.add_column(ret2, {"tc": "r"})Después de realizar una serie de consultas interactivas para la visualización de un solo punto, el usuario comienza a realizar tareas de análisis de gráficos a través de las declaraciones anteriores.
Primero, utiliza un operador de subgrafo para extraer un subgrafo de la imagen original de acuerdo con las condiciones del filtro. Detrás de este operador, el motor interactivo GIE ejecuta una consulta y luego escribe el gráfico de resultados en el viñedo.
Luego, el usuario extrae los puntos cuya etiqueta es el papel y los bordes cuya relación se cita en este nuevo gráfico, y produce un gráfico isomorfo, y llama al algoritmo integrado de GAE k-core y triangulo contando con él. Triangles ha realizado cálculos analíticos en la imagen completa. Una vez producidos los resultados, estos dos resultados se vuelven a agregar a la imagen original como atributos en los puntos. Aquí, con la ayuda de la gestión de metadatos del viñedo y la abstracción de datos de alto nivel, el nuevo sub_gráfico se genera mediante la transformación de una nueva columna en la imagen original, y no hay necesidad de reconstruir todos los datos de la imagen completa.
El núcleo del motor GAE hereda el sistema GRAPE que ganó el premio SIGMOD2017 Best Paper Award [2]. Está compuesto por un tiempo de ejecución de alto rendimiento, componentes de paralelización automática, SDK de soporte multilingüe y otros componentes. El ejemplo anterior utiliza el propio algoritmo de GAE. Además, GAE también ayuda a los usuarios a escribir sus propios algoritmos de forma muy sencilla y enchufarlos y utilizarlos. Los usuarios escriben algoritmos basados en el modelo PIE de programación de subgrafos, o reutilizan algoritmos gráficos existentes sin considerar los detalles distribuidos. GAE hará la paralelización automática, lo que reduce en gran medida el umbral alto para los usuarios de computación gráfica distribuida. En la actualidad, GAE ayuda a los usuarios a escribir su propia lógica de algoritmo en C ++, Python (Java será compatible en el futuro) y otros lenguajes, plug and play en un entorno distribuido. El tiempo de ejecución de alto rendimiento de GAE se basa en MPI, con una optimización muy detallada de las características de comunicación, disposición de datos y hardware para lograr el máximo rendimiento.
# define the features for learning
paper_features = []
for i in range(128):
paper_features.append("feat_" + str(i))
paper_features.append("kcore")
paper_features.append("tc")
# launch a learning engine.
lg = sess.learning(sub_graph, nodes=[("paper", paper_features)],
edges=[("paper", "cites", "paper")],
gen_labels=[
("train", "paper", 100, (1, 75)),
("val", "paper", 100, (75, 85)),
("test", "paper", 100, (85, 100))
])A continuación, comenzamos a utilizar el motor de aprendizaje de gráficos para clasificar trabajos. Primero, configuramos la característica de 128 dimensiones del nodo de papel en los datos y los dos atributos de kcore y triángulos que calculamos en el paso anterior como característica de entrenamiento. Luego sacamos el motor de aprendizaje gráfico GIE de la sesión. Al abrir el gráfico lg en GIE, configuramos los datos del gráfico, los atributos de las características, especificamos el tipo de borde y dividimos el conjunto de puntos en un conjunto de entrenamiento, un conjunto de validación y un conjunto de prueba.
from graphscope.learning.examples import GCN
from graphscope.learning.graphlearn.python.model.tf.trainer import LocalTFTrainer
from graphscope.learning.graphlearn.python.model.tf.optimizer import get_tf_optimizer
# supervised GCN.
def train_and_test(config, graph):
def model_fn():
return GCN(graph, config["class_num"], ...)
trainer = LocalTFTrainer(model_fn,
epoch=config["epoch"]...)
trainer.train_and_evaluate()
config = {...}
train_and_test(config, lg)Luego usamos el código anterior para seleccionar el modelo y realizar alguna configuración de parámetros relacionados con el entrenamiento, y es muy conveniente usar GLE para iniciar la tarea de clasificación de imágenes.
El motor GLE consta de dos partes, Graph y Tensor, que se componen de varios operadores. La parte del gráfico implica la conexión de los datos del gráfico y el aprendizaje profundo, como la iteración por lotes, el muestreo y el muestreo negativo, y admite gráficos isomórficos y gráficos heterogéneos. La parte Tensor está compuesta por varios operadores de aprendizaje profundo. En el módulo de cálculo, la tarea de aprendizaje de gráficos se desarma en operadores y los operadores se ejecutan de manera distribuida durante el tiempo de ejecución. Para optimizar aún más el rendimiento de muestreo, GLE almacenará en caché vecinos remotos, puntos de acceso frecuente, índices de atributos, etc. para acelerar la búsqueda de vértices y sus atributos en cada partición. GLE utiliza un motor de ejecución asíncrono que admite hardware heterogéneo, lo que permite a GLE superponer de forma eficaz una gran cantidad de operaciones simultáneas, como E / S, muestreo y cálculos de tensores. GLE abstrae hardware informático heterogéneo en grupos de recursos (por ejemplo, grupo de subprocesos de CPU y grupo de flujo de GPU) y coopera en la programación de tareas simultáneas detalladas.
Cinco actuaciones
GraphScope no solo resuelve el problema del cálculo de gráficos con una facilidad de uso integral, sino que también logra lo último en rendimiento, satisfaciendo las necesidades de nivel empresarial. Usamos LDBC Benchmark para evaluar y comparar el desempeño de GraphScope.
Como se muestra en la Figura 6, en la prueba de consulta interactiva LDBC SNB Benchmark, GraphScope implementado en un solo nodo es más de un orden de magnitud más rápido que el sistema de código abierto JanusGraph; en la implementación distribuida, la consulta interactiva de GraphScope básicamente puede lograr linealidad. Escalabilidad acelerada .
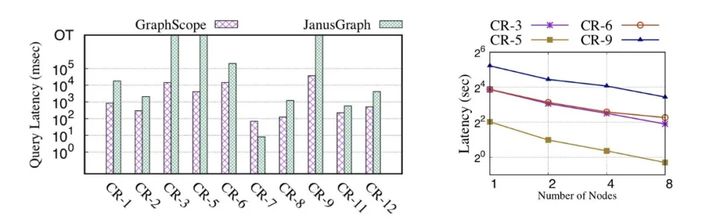
Figura 6: rendimiento de la consulta interactiva GraphScope
En la prueba de análisis de gráficos LDBC GraphAnalytics Benchmark, GraphScope se compara con PowerGraph y otros sistemas más recientes, y toma la delantera en casi todas las combinaciones de algoritmos y conjuntos de datos. En algunos algoritmos y conjuntos de datos, en comparación con otras plataformas, hay cinco veces la ventaja de rendimiento en el nivel más bajo. Los datos parciales se muestran en la figura siguiente.
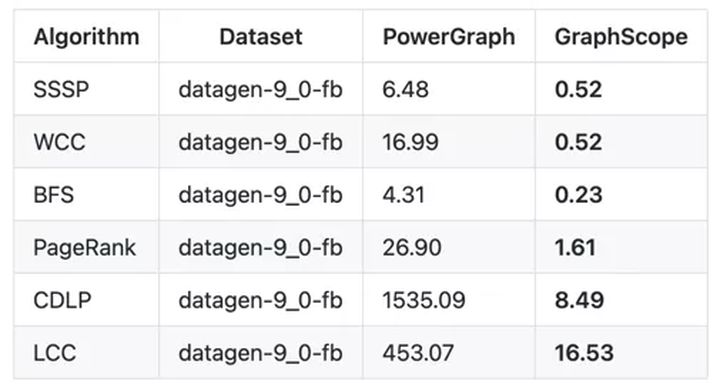
Figura 7: Rendimiento del análisis de gráficos GraphScope
Para conocer la configuración del experimento, la reproducción y la comparación completa del rendimiento, consulte el rendimiento de las consultas interactivas [3] y el rendimiento del análisis de gráficos [4].
Seis abrazan el código abierto
El documento técnico y el código de GraphScope se han publicado en http://github.com/alibaba/graphscope[5 ] y el proyecto cumple con la licencia Apache 2.0. Bienvenidos a todos a destacar, probar y participar en los cálculos de gráficos. También puede contribuir con código para crear el mejor sistema informático gráfico de la industria. Nuestro objetivo es actualizar continuamente el proyecto y mejorar continuamente la integridad de la función y la estabilidad del sistema. También puede seguir el sitio web http://graphscope.io para realizar un seguimiento del estado más reciente del proyecto.
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.