
I. Introducción
Vmo es una biblioteca de herramientas que publiqué en 18 años para crear rápidamente modelos de datos. En ese momento, escribí un artículo "Diseño de modelos de datos front-end de Vmo" que recibió atención durante un período de tiempo. En ese momento, estaba comprometido en proyectos relacionados con la decoración 3D. Con la base de fondo de gráficos y los datos masivos y complejos, naturalmente, una solución técnica para el procesamiento, análisis y consumo de datos se derivará del front-end, que también plantó las semillas de mi concepto de modelos de datos.
Para dar un ejemplo simple: ¿Cuáles son los datos de una casa decorada en tres dimensiones que necesitan ser analizados?
- Casa (casa), piso (capa), habitación (habitación), pared (pared), pared (espacio de pared), esquina (esquina), techo (techo), rodapié (rodapié), piso (piso, con espesor), piso ( FloorSpace), puerta (puerta), ventana (ventana).
- Y ampliará muchas variantes, como ventanales, ventanales en ángulo recto, ventanas curvas, agujeros en las paredes, escaleras, etc.
Existen muchas correlaciones y cálculos al analizar estos datos. Por ejemplo, la habitación debe estar relacionada con la pared, la pared debe estar relacionada con la pared, la pared está relacionada con hasta 2 habitaciones, la esquina está relacionada con múltiples habitaciones, y la esquina está relacionada con múltiples paredes. Asociación de cuerpos, etc.
Frente a datos tan masivos y complejos, obviamente es una solución muy indeseable consumir solo el resultado de una solicitud de API. No digamos si los datos se pueden analizar correctamente, sino cómo mantener los datos y cómo recolectarlos al guardarlos. La serialización inversa de todos los datos en el back-end es un dolor de cabeza.
Por supuesto, estos problemas se resolvieron en los distintos modelos de datos que resumimos en ese momento. Si quieres conocer los detalles, puedes consultar mi artículo anterior.
De lo que quiero hablar hoy es que después de unirme a Ali, he estado pensando en dos cuestiones sobre los modelos de datos:
- ¿No hay escenario de uso o valor para cosas como modelos de datos para proyectos regulares? Regular, como una consulta de datos, o completar algunos datos para enviar. ¿Existe alguna clase abstracta y modelo de datos necesario para este requisito?
- ¿Por qué raras veces veo este aspecto en el círculo frontal? La mayoría de los círculos frontales ahora se están moviendo hacia la funcionalización, la composición, etc. ¿Hay algún problema con esta ruta?
Después de buscar durante 2 años, parecía haber encontrado algunas respuestas al liderar la refactorización de la página de lanzamiento de productos de los comerciantes de Lazada.
Segundo modelo de productos básicos
En primer lugar, en el proceso de agregar un producto, el usuario está creando un conjunto de datos del producto en forma de cliente. La perspectiva del front-end convencional es enviar un "JSON".
La edición consiste en extraer este "JSON" a través de la API y analizarlo en el formulario de formulario, lo que permite al usuario editar y luego enviar el "JSON".
Entonces, la abstracción aproximada de datos en un modelo será así:
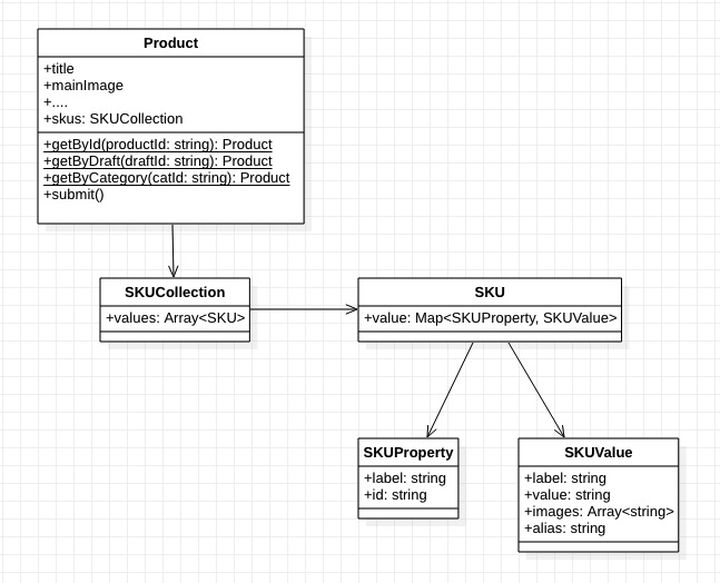
Bueno, todo lo que hemos hecho hasta ahora se siente como si nos estuviéramos quitando los pantalones y tirándonos pedos. Jajaja, todos los jueces, no rocíen por el momento, no se inquieten.
Entonces, ¿por qué necesitamos abstraer estos datos en una clase? Permítanme tomar algunos casos para ilustrar:
1 Solicitar datos y prueba unitaria
Muchas veces, el front-end escribe la solicitud y el procesamiento de los datos en el componente, y es mejor encapsularlo en un determinado clúster, o en un determinado Hook, para que el estado y los datos se puedan obtener fácilmente al llamar.
Hay muchas formas de solicitar datos, como los productos básicos: obtener de borradores, obtener de la edición y obtener de una determinada categoría (en diferentes categorías, los atributos de los productos básicos son diferentes).
La combinación de interfaz y parámetro solicitada por cada método de adquisición puede ser diferente, pero el producto final de consumo de front-end es el mismo. De acuerdo con el modelo de estrategia, se utilizan diferentes estrategias para obtener un modelo de producto, pero los productos son los mismos, independientemente del método que se llame del lado del consumidor, el resultado obtenido es una clase de modelo de Producto confiable.
Los front-end experimentados saben que, en muchos casos, después de una ronda de iteraciones de un proyecto, a menudo hay algunos datos en nuestra interfaz que necesitan ser procesados o convertidos por el front-end.
Ante tal procesamiento de datos, si se coloca en un componente o gancho, no es adecuado, puede traernos alguna resistencia a la hora de realizar pruebas unitarias o consumo de datos.
En mi opinión, la mejor manera de depurar un problema de datos es escribir una prueba unitaria para depurar los resultados esperados de la prueba unitaria. A menudo es más eficiente que burlarse de un dato en el navegador para depurar los datos, que es más eficaz para la estabilidad futura. También es más útil.
Una sensación de seguridad, el consumo de datos, una clase y un JSON dan a los desarrolladores una sensación de seguridad y comodidad que es completamente diferente. Para aquellos que han consumido modelos de datos o han consumido Interface la próxima vez, creo que estoy muy de acuerdo con este punto.
Jaja, cuando se trata de esto, algunos amigos pueden tener que preguntar, lo que dijiste podemos lograr el mismo efecto con Interface. Bien, continuemos ...
2 Datos de consumo computacional
¿Qué son los datos de consumo computacional? En pocas palabras, por ejemplo:
class Person1 {
fistName = "Wang";
lastName = "Yee";
get fullName() {
return `${this.lastName} ${this.fistName}`; // Yee Wang
}
get fullNameCN() {
return `${this.fistName} ${this.lastName}`; // Wang Yee
}
}El ejemplo anterior es muy clásico y claro. Los metadatos pueden ser solo datos básicos, pero en muchos casos el front-end necesita ensamblar metadatos de acuerdo con diferentes escenarios. En el pasado, estos datos a menudo se encapsulaban en varios métodos o se escribían en componentes como plantillas., Dispersas en todos los rincones, cada vez que se utilizan estos datos, se pueden ensamblar de nuevo según la escena. A menudo habrá una falta de demanda en este momento. Por ejemplo, en una determinada situación, todos los lugares donde antes se consumía fullName deben cambiarse a minúsculas.
En cuanto al lanzamiento del producto, ¿cuáles son los escenarios de aplicación para los datos de consumo computacional?
Antes de eso, me gustaría explicar el modelo de datos de SKU. Los metadatos principales son:

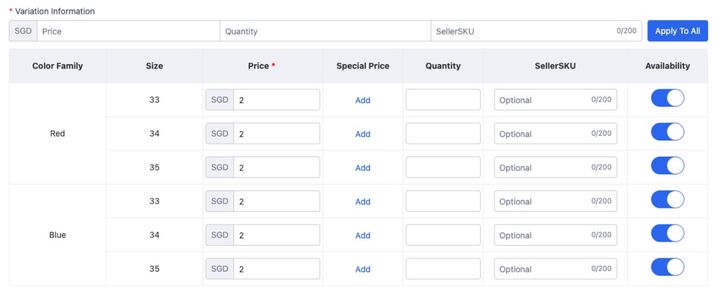
De acuerdo con la tabla que se muestra en la figura anterior, puede ver que el producto tiene 6 SKU en total, y los datos del modelo de SKU correspondientes al primer SKU deben ser:
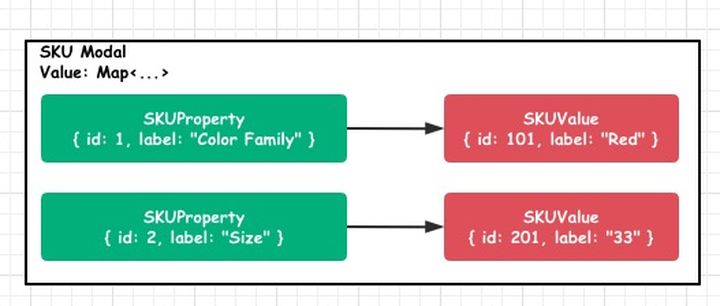
class SKU {
value = new Map([
[
new SKUProperty({ id: 1, label: "Color Family" }),
new SKUValue({ id: 101, label: "Red" }),
],
[
new SKUProperty({ id: 2, label: "Size" }),
new SKUValue({ id: 201, label: "33" }),
],
]);
price: string;
}Para un modelo de SKU como este, los metadatos que posee pueden describir claramente el SKU actual, y se pueden obtener muchos datos útiles a través de métodos de extensión de SKU, como:
- getProperties () Obtiene todas las propiedades del SKU, como: Familia de colores, Tamaño.
- getValues () Obtiene todos los valores del SKU, como: Red, 33.
- isEqual (anotherSKU: SKU): boolean compara si un SKU es exactamente el mismo que el SKU actual, lo cual es muy útil en la posterior fusión de datos.
- getValueByPropertyId (id: string) Obtiene un SKUValue a través de PropertyId.
En comparación con solo un objeto Objeto, el modelo de datos puede brindar una gran cantidad de capacidades de procesamiento y expansión de datos. Cuando los datos de consumo computacional generados por los datos deben consumirse en ciertas circunstancias, se pueden expandir y usar fácilmente. mejores expectativas y control sobre la estructura de datos.
En combinación con la prueba unitaria del modelo de datos, la capa de datos se puede desarrollar de forma clara y rápida. Cuando la capa de datos es confiable, el consumo en la capa de vista será suave y conveniente.
Dé un ejemplo de prueba unitaria:
it("alias sku equal", () => {
const data = [
{
text: "300MB",
value: 2988,
name: "p-1",
},
{
text: "Blue",
value: 2888,
alias: "Blue1",
name: "p-2",
},
];
const sku = SKU.fromData(data);
expect(
sku.isEqual(
SKU.fromData([
{
text: "300MB",
value: 2988,
name: "p-1",
},
{
text: "Blue",
value: 2888,
alias: "Blue2",
name: "p-2",
},
])
)
).toBeFalsy();
});Este tipo de SKU es un tipo especial de SKU, y habrá un campo de alias en él. Cuando hay este tipo de campo, al hacer una comparación de SKU, no solo se debe comparar el ID de SKUProperty y SKUValue, sino también el alias debe ser comparado.Comparación de campo.
Entonces, de acuerdo con la prueba única anterior, el resultado debería ser falso, porque los alias en los dos datos son diferentes. De ninguna manera, este es un requisito comercial.
Si usa datos puros para la comparación de datos en la capa de vista, es probable que se pierda esta parte de la lógica, lo que hará que el proyecto se estire y la pared se rompa.
De todos modos, cuando la capa del consumidor encuentra muchas necesidades de procesamiento o juicio de datos, se puede entregar al modelo de datos para su procesamiento, y el modelo de datos puede garantizar la estabilidad de los datos.
3 Relación de datos
El uso del modelo de datos también puede ayudarlo a administrar claramente la relación de datos, como la relación entre productos y SKU, SKU y SKUProperty y SKUValue.
Déjame darte un caso específico:
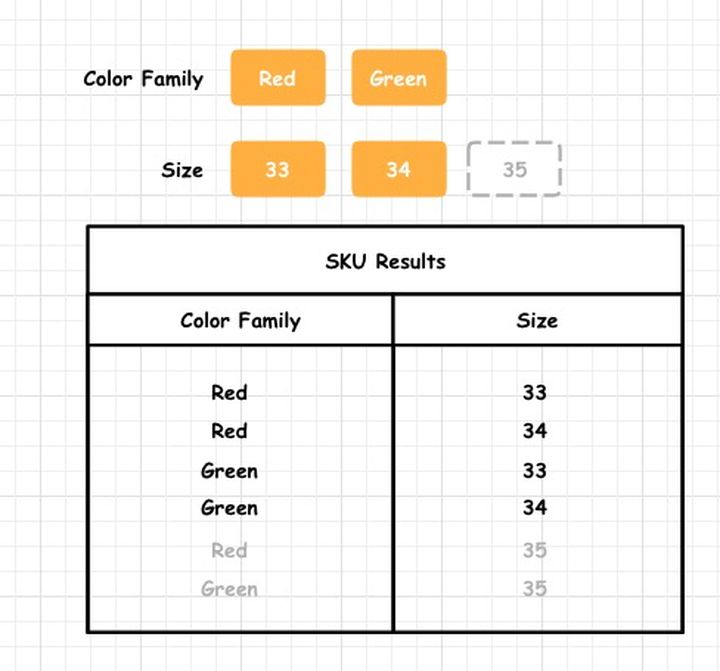
Este es un proceso de agrupación de productos cartesianos durante la edición del producto. Cuando el usuario agrega o modifica nuestros atributos de SKU, el producto cartesiano vuelve a calcular los resultados de combinación y permutación más recientes.
Por ejemplo, cuando el usuario agrega un tamaño de 35, el producto cartesiano tendrá dos resultados combinados más. De la misma manera, si la dimensión aumenta en una columna, como al agregar una dimensión de material, se generarán más resultados de SKU.
En el pasado, los desarrolladores de aplicaciones para el usuario siempre encapsulaban esta parte del proceso de cálculo en un método matemático, que se puede llamar en cualquier momento en utils, lo que parece no ser un problema.
Si considera este proceso como el proceso de construcción de un modelo de datos SKUCollection, todo se convertirá en una cuestión de rutina:
test('sku calculate whether valid', () => {
const skuCellection = SKUCollection.fromData({
'p-3xxxx': [
{
text: '300MB',
value: 2,
},
{
text: '128GB',
value: 3,
},
],
'p-4xxxx': [
{
text: 'Blue',
value: 3,
},
{
text: 'Red',
value: 15,
},
{
text: 'Green',
value: 1,
},
],
});
expect(
skuCellection.value
).toEqual(
// 6 SKU Model
);
});Con tal estructura de modelo de datos, los datos relacionados y los datos computacionales se pueden llamar claramente a través del modelo de datos.
Además, aunque los diferentes modelos de datos dependen unos de otros, el análisis de datos y los datos computacionales no son independientes entre sí, y se pueden utilizar de forma independiente y probarlos por unidades.
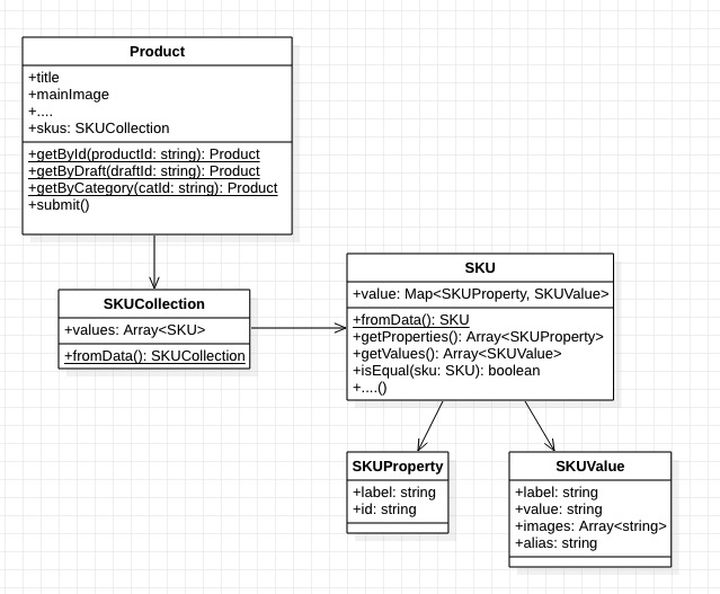
Modelo de tres anomalías
La liberación de productos básicos es esencialmente una página de envío de formularios más complicada. Debido a muchos campos e interacciones complejas, muchos campos se han dividido en diferentes módulos en el proceso de diseño del producto para reducir la carga psicológica de los usuarios.
Por ejemplo, habrá: información básica, atributos del producto, descripción detallada, envío, etc.
Durante el proceso de llenado, habrá algunos escenarios de verificación de front-end + back-end.
En el proceso de envío de datos u otra escritura de datos, el backend también procesará la verificación del campo.Cuando el backend encuentra que un campo está llenado incorrectamente, el servidor devolverá información de error e información de campo de error.
Para tener una mejor experiencia interactiva, el front-end obtendrá la información del campo de acuerdo con la devolución, ubicará la posición del campo correspondiente, mostrará la información del error e informará en rojo, y también deberá juzgar el módulo al que pertenece en función del campo actual e informar del error.
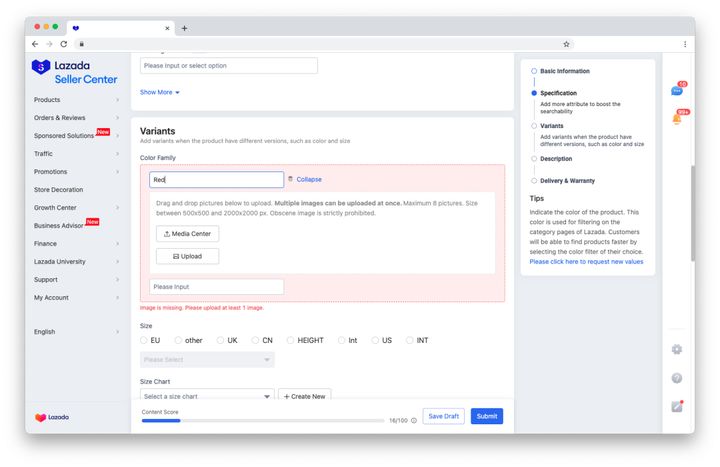
Hay otra situación: la verificación de primer nivel del servidor pasa y se lanza una excepción al llamar al enlace ascendente de otros productos básicos. En este momento, el enlace ascendente puede haber perdido la información de campo. Ante tales datos anormales , la interfaz debe mostrarse en la parte superior del formulario y proporcionar traceId para rastrear y localizar anomalías.
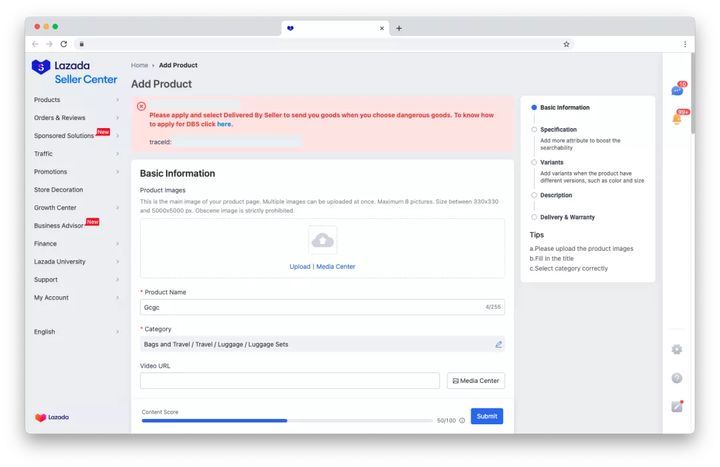
Por lo general, estos datos anormales deben confirmarse repetidamente con el back-end para confirmar el rendimiento de diferentes casos. Algunas anormalidades incluso son difíciles de ocurrir una vez. Durante el proceso de iteración, a menudo perdemos esta parte de la capacidad de consumo de datos debido a algún componente cambios o cambios lógicos.
En lo que respecta al lanzamiento del producto, la acción obvia de "guardar" es una excepción que debe manejarse, por lo que escribiremos mucha lógica de procesamiento cuando el backend devuelva una excepción en el lugar de envío.
Cuando un día, otra iteración requiere una operación de escritura, también ocurrirán situaciones anormales.Cuando estas situaciones anormales se procesen nuevamente, habrá mucha conversión de datos y lógica de visualización de errores.
Si recibe estos datos de retorno de back-end, conviértalos en un modelo de datos anormales y luego entréguelos a la capa de vista para su consumo, de modo que toda la lógica que necesita procesarse bajo el modelo anormal se reutilice para evitar el pérdida de lógica de interacción.
Por supuesto, cómo la capa de vista puede consumir más inteligentemente este modelo de datos es otro diseño interesante. No lo mostraré aquí por el momento. Más adelante escribiré un artículo dedicado al diseño de administración del estado de la capa de vista del lanzamiento del producto.
Cuatro resumen
En el lanzamiento del producto, además de los varios modelos de datos mencionados anteriormente, se construyen algunos otros tipos de modelos de datos, como: modelo de carga, submodelo de calidad del producto, modelo de recomendación de categoría, etc. modelos Los modelos se combinan para formar un modelo básico.
Cuando se consume un modelo de datos de este tipo, a los desarrolladores no les importa demasiado qué API deben solicitarse, qué tipo de datos se devuelven y si sus devoluciones deben procesarse, convertirse o ser compatibles.
Al mismo tiempo, un modelo de datos de tan alta calidad no depende en realidad del marco de la capa de visualización. Puede extraerse como un paquete independiente para la gestión y el mantenimiento, y luego introducirse y utilizarse en otras páginas, como el producto básico. El dominio puede encontrar: gestión de productos básicos, selección de productos básicos, edición de fletes, vista previa de la calidad del producto, etc.
Volviendo al principio, las preguntas que mencioné:
- ¿No hay escenario de uso o valor para cosas como modelos de datos para proyectos regulares? Regular, como una consulta de datos, o completar algunos datos para enviar. ¿Existe alguna clase abstracta y modelo de datos necesario para este requisito?
- ¿Por qué raras veces veo este aspecto en el círculo frontal? La mayoría de los círculos frontales ahora se están moviendo hacia la funcionalización, la composición, etc. ¿Hay algún problema con esta ruta?
En primer lugar, en el proceso que utilicé, el modelo de datos fue muy claro, poderoso y resolvió firmemente los problemas comerciales que enfrenté, por lo que fue valioso.
En cuanto a los requisitos convencionales, ¿qué debo utilizar? Jaja, hay una respuesta deshonesta a esta pregunta. Los niños solo consideran lo que quieren o no, y los adultos lo quieren todo. Ninguna tecnología es ni negra ni blanca.
¿Se puede usar Vite solo en proyectos de Vue?
Lo que es adecuado y qué usar, la visualización simple de consultas de datos no requiere un procesamiento de datos tan sofisticado, por supuesto, puede usarlo directamente, ¡y la forma de resolver problemas comerciales es una buena manera!
En cuanto a la API de composición, de hecho, en el proceso de refactorización del lanzamiento del producto, la mayoría de ellos se realizan básicamente utilizando esta idea de diseño. Tal diseño realmente nos permite distinguir claramente lo que hace cada método y si afectará la interacción. , Y lo que está haciendo esta interacción. Cada interacción se mantiene y procesa en un solo lugar. Escribiré una introducción por separado más adelante.
En la práctica, descubrí que el modelo de datos y la API de composición no entran en conflicto. Uno se usa para procesar la capa de datos y el otro se usa para procesar la capa de vista. Se complementan y combinan el diseño de algunos modelos de suscripción, lo que Deje muy clara la división de todo el proyecto. Se recomienda encarecidamente que pueda utilizar este conjunto de ideas para resolver problemas comerciales cuando se encuentre con proyectos de un solo punto más complicados en el futuro.
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.