Centro de monitoreo ambiental de IoT
1. Introducción a la modularización de proyectos
Cuando el sensor envía datos a la puerta de enlace, la puerta de enlace necesita analizar los datos y enviar los datos analizados al servidor para su almacenamiento, como se muestra en la figura:
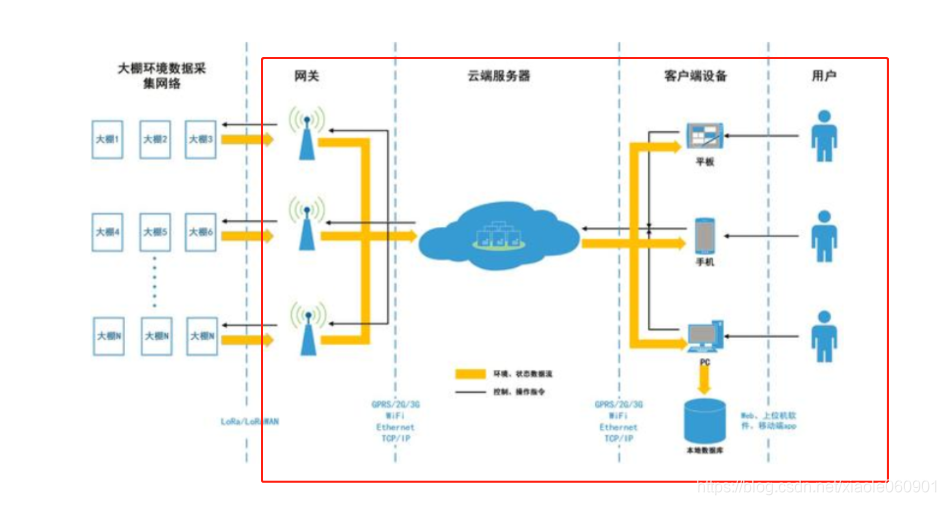
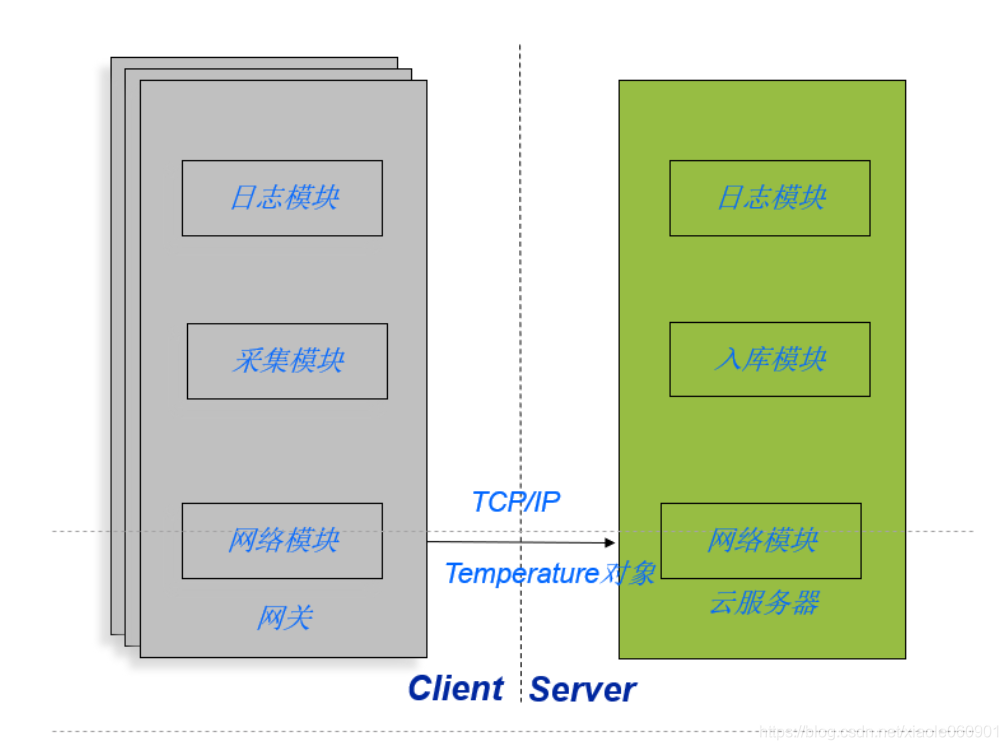
Luego nuestro proyecto se divide en cliente y servidor. La puerta de enlace en la figura es equivalente a nuestro cliente, y el servidor en la nube en la figura es equivalente a nuestro servidor. Necesitamos enviar los datos analizados al servidor, el servidor Almacenar los enviados datos. El diagrama del módulo específico es el siguiente:
2. Diagrama de estructura del proyecto
3. Puntos de conocimiento involucrados
Análisis de 3.1xml
Aprendí tres formas de analizar XML
Análisis de dom, análisis de saxofón, análisis de dom4j (forma convencional, simple y fácil de entender)
análisis de dom
//创建解析工厂并且获取到document对象
String filePath = "src/work/person.xml";
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder documentBuilder = factory.newDocumentBuilder();
Document document = documentBuilder.parse(new File(filePath));//filePath表示传入的xml文件的路径
// 获取根节点
Element root = document.getDocumentElement();
//获取到节点的属性集合
NamedNodeMap listMap = root.getAttributes();//这里举例获取到根节点的属性集合
// 获取根节点的所有子节点
NodeList list = root.getChildNodes();
// 得到标签所有的属性
NamedNodeMap attributes = element.getAttributes();//遍历得到的根节点
análisis de saxo
//通过不断的重写父类的方法得到xml的解析结果,基于事件的解析方式,只能解析一次,解析过得数据不能再解析
//不能过随机读取,只能够顺序读取
//获取到sax解析的父类
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
//重写他们的方法就可以得到解析到的xml对象
startDocument()
startElement()
characters()
endElement()
endDocument()
análisis dom4j
//想要使用dom4j解析,就必须要引入相应的jar包
//得到解析器
SAXReader saxReader = new SAXReader();
//解析一个xml文件
Document document = saxReader.read(filePath);//filePath表示传入的xml文件的路径
//3.得到根节点
Element rootElement = document.getRootElement();
//得到标签的名字
System.out.println("<"+rootElement.getName()+">");
elements.forEach(t ->{
System.out.print("<"+t.getName());
List<Attribute> list =t.attributes();
list.forEach(p->{
System.out.print(" "+p.getName() + "=" + p.getValue());
//默认的命名空间uri
System.out.println(p.getNamespaceURI());
});
System.out.print(">");
System.out.println();
List<Element> list2 = t.elements();
list2.forEach(l->{
System.out.print("<"+l.getName()+">");
System.out.print(l.getTextTrim());
System.out.println("</"+l.getName()+">");
});
});
3.2 base de datos Oracle
1. La clasificación de las declaraciones SQL
DQL (Lenguaje de consulta de datos): principalmente declaraciones de selección.
DML (lenguaje de manipulación de datos): principalmente inserta declaraciones, actualiza declaraciones, elimina declaraciones, lo que generará transacciones
Debe confirmar o deshacer después de la declaración para finalizar la transacción; de lo contrario, la base de datos no actualizará los datos
DDL (lenguaje de definición de datos): crear, modificar, eliminar, truncar declaraciones
TCL (lenguaje de control de transacciones): confirmación, reversión, declaraciones de puntos de guardado para mantener la coherencia de los datos
DCL (lenguaje de control de datos): declaraciones de concesión, revocación, utilizadas para realizar operaciones de concesión y retirada de permisos
2. seleccionar declaración
La instrucción select nunca modifica el contenido de la tabla
3. Varias funciones de uso común
- ||: función de empalme, la cadena está entre comillas simples
- Nvl: el valor nulo se puede reemplazar
- distinto: realizar el procesamiento de deduplicación
- formato: para formato de salida
4. Ordenar
La clasificación al consultar datos es mostrar los registros en orden ascendente o descendente de acuerdo con el valor de un campo determinado
select col_name,...
from tb_name
order by col_name [asc|desc]
--order by语句,只对查询记录显示调整,并不改变查询结果,所以执行权最低,最后执行
--排序的默认值是asc:表示升序,desc:表示降序
--如果有多个列排序,后面的列排序的前提是前面的列排好序以后有重复(相同)的值。
5. Consulta de condición
y tiene una prioridad más alta que o
--where子句的优先级别最高
--between and操作符,表示在俩个值之间
select id,last_name,salary
from s_emp
where salary between 700 and 1500;
--in(),表示值在一个指定的列表中
select id,last_name,salary
from s_emp
where id in (1,3,5,7,9);
--like,模糊查询,在值不精确的时候使用
-- %,通配0到多个字符
-- _,通配一个字符,并且是一定要有一个字符
-- \,转义字符,需要使用escape关键字指定,转义字符只能转义后面的一个字符
select id,last_name,salary
from s_emp
where last_name like'C%';
-- is null 和 is not null
select id,last_name,commission_pct
from s_emp
where commission_pct is null;
Pseudocolumna: la función principal de la pseudocolumna rownum en la base de datos de Oracle es completar consultas de paginación.
6. Consulta de grupo
select 字段1,字段2 ----5
from 表 ---1
where 条件 ---2
group by 分组条件 ---3
having 分组筛选条件 ---4
order by 排序条件 ---6
--聚合函数能够出现的位置
1. select后面
2. having后面
3. order by后面
7. Subconsulta
La idea de la subconsulta es utilizar el resultado de la consulta de la primera instrucción sql en la segunda instrucción sql. En este momento, el resultado de la primera instrucción sql puede servir como una de las condiciones where en la segunda instrucción sql. Valor o actuar como una mesa virtual.
select last_name,salary
from s_emp
where salary>
(select salary
from s_emp
where last_name='Smith');
8. Construye una mesa
-- 一般的建表语句
create table 表名(
字段名 数据类型 [列约束类型],
字段名 数据类型 [列约束类型],
字段名 数据类型 [列约束类型],
字段名 数据类型 [列约束类型],
字段名 数据类型 [列约束类型]);
Declaración 9.DML
insertar en el nombre de la tabla (columna 1, columna 2, ...) valores (valor 1, valor 2, ...);
actualizar el nombre de la tabla establece la columna 1 = valor 1, columna 2 = valor 2, ... donde condición;
eliminar del nombre de la tabla donde las condiciones eliminarán todos los datos de la tabla si no se agregan condiciones
Eliminar directamente eliminar la tabla y eliminar en cascada la información relacionada con la tabla
Solo las declaraciones DML producirán transacciones, otras declaraciones no producirán transacciones
Las declaraciones de confirmación, reversión y DDL pueden finalizar la transacción actual
10. Secuencia
Métodos comúnmente utilizados para crear secuencias:
crear secuencia nombre de secuencia
11. Índice
crear índice nombre de índice
en el nombre de la tabla (nombre de la columna);
3.3JDBC
1. Usando el procedimiento general (paso) operaciones de la base de datos JDBC de:
- Registrar conductor
- Obtener conexión a la base de datos
- Crear objeto de tipo o subtipo de declaración
- Ejecutar sql
- Procesamiento de resultados (si es necesario, se deben procesar declaraciones de consulta generales)
- Cerrar recurso
Forma general de cargar el controlador
private String driverClass="oracle.jdbc.driver.OracleDriver";
private String url="jdbc:oracle:thin:@127.0.0.1:1521:XE";
private String user="briup";
private String password="briup";
//1.加载注册驱动
Class.forName(driverClass);
//2.获取连接对象
conn=DriverManager.getConnection(url,user,password);
//3.获取Statement对象
stmt=conn.createStatement();
//4.执行SQL语句
Obtenga la conexión JDBC a través del grupo de conexiones de la base de datos
Properties properties = new Properties();
InputStream is = ConnectionTest.class.getClassLoader().getResourceAsStream("druid.properties");
properties.load(is);
//获取连接池对象
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
// 获取连接
conn=dataSource.getConnection();
Metadatos
Metadatos, puede obtener el objeto de metadatos a través del método de conexión getMetadata (), y luego puede obtener el nombre, la versión y la información de la versión de la base de datos
3.4SVN
Svn es similar a una herramienta de control de versiones. Puede enviar la información de cada versión conectándose a svn. Una vez que encuentre un problema, puede volver a una versión específica.
3.5 Maven
Cree proyectos java, gestión de dependencias y gestión de información de proyectos
Pasos de construcción del proyecto

- Limpiar: elimine el archivo de código de bytes de clase de archivo antiguo obtenido de la compilación anterior
- Compilar compilar: compila el programa fuente java en un archivo de código de bytes de clase
- Prueba de prueba: prueba automática, llame automáticamente al programa junit
- Informe informe: los resultados de la ejecución del programa de prueba
- Paquete de paquete: paquete War para proyecto web dinámico, paquete jar para proyecto java
- Instalar instalar: concepto específico de Maven, copiar los archivos empaquetados en la ubicación especificada en el almacén de Maven 7. Implementar implementación: colocar los resultados generados por el proyecto en el servidor o contenedor para que pueda ejecutarse
Formato dependiente del proyecto
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
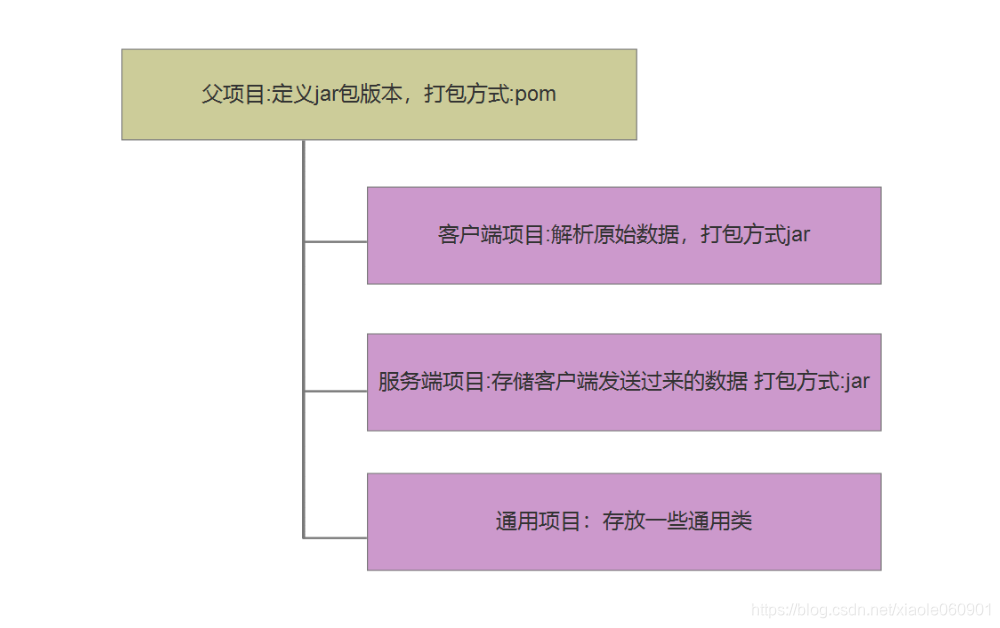
Por lo general, cuando creas un proyecto Maven, creas un proyecto agregado y luego le agregas submódulos. El método de empaquetado debe ser pom y las dependencias generales se escriben en el proyecto principal y luego
Otros módulos dependen automáticamente del proyecto principal y dependen automáticamente del paquete jar
4. Construcción del proyecto
1. El uso de un pequeño complemento
Lombok puede hacer que la clase no necesite escribir el método de construcción y el método getset, lo que mejorará en gran medida la flexibilidad de los datos (por ejemplo, modificará el método getset y el constructor al modificar atributos)
2. Nuevo proyecto Maven

Dividido en tres módulos
- medio ambiente común: se usa específicamente para escribir las clases de entidad y las clases de herramientas que todo el proyecto necesita usar, así como para depender de las dependencias comunes de otros proyectos, como base para otros módulos
- enviroment-gateway: la clase de puerta de enlace, es decir, el cliente, es responsable de leer los datos del archivo, almacenarlos en forma de objetos y luego enviarlos al servidor
- enviroment-server: el servidor, obtiene los datos enviados por el cliente a través de serversocked, y luego almacena los datos en la base de datos (este proyecto se almacena en 31 tablas)
4.1entorno-común

La imagen de arriba es el módulo común del proyecto.
Se compone principalmente de los siguientes módulos:
-
excepción (proporciona principalmente clases de excepción en este código de proyecto y varios tipos de excepción creados con enumeraciones)
- EnviromentException: dominar la escritura de clases de excepción
- ExceptionMessageEnum: Domina la escritura de enumeración
-
pojo (objeto java simple): al observar el formato de la información, se abstrae un objeto para cada pieza de información y el objeto se utiliza para manipular los datos
- Enviromet: Domina el pensamiento orientado a objetos, abstrae cada pieza de información como un objeto y abstrae el contenido específico como un atributo.
-
Utils (herramientas): escriba algunas herramientas comunes para proyectos
-
BackUpUtil (contiene todas las herramientas y métodos del proyecto)
-
almacenar (archivo de archivo, datos de objeto, adición booleana), pasando el archivo y los datos que se van a transferir al archivo, y si se debe sobrescribir el archivo de origen
Este método se puede utilizar para hacer una copia de seguridad de la información procesada para evitar que los datos de origen no se puedan encontrar después del procesamiento de la información.
En la etapa inicial de la construcción del proyecto, este método es posible y ocurrirán problemas durante la implementación, porque el paquete jar no se cargará cuando se genere el paquete jar generado.
La carpeta de origen hace que la ruta del archivo sea incorrecta. El archivo debe obtenerse a través del cargador de clases en la forma del flujo de recursos
el código se muestra a continuación:
Nombre de clase.class.getResourceAsStream ("El nombre del archivo que se va a operar, no se requiere ruta, solo el nombre del archivo + sufijo puede ser directamente")
2. read(File file,boolean append),接着上次的阅读过得地方继续读取 3. load(InputStream is) ,用于properties文件的读取 4. close(Connection connection,Statement statement,ResultSet resultSet) 用于关闭流的方法 -
-
IdWorker (algoritmo de copo de nieve)
- El algoritmo del copo de nieve solo necesita un nuevo objeto en una clase, de lo contrario, hará que el programa sea extremadamente lento, porque cargar una clase realizará muchos cálculos.
-
4.2enviroment-gateway
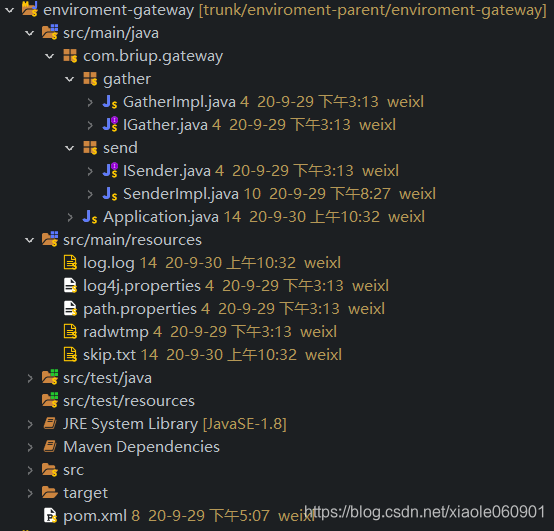
La imagen de arriba es el contenido del módulo de puerta de enlace
-
reunir
-
IGather es la interfaz para realizar la función de puerta de enlace
public Collection<Enviroment> gather() throws EnviromentException;El propósito de esta función es leer los datos y encapsular cada objeto y luego encapsularlo en la colección
-
GatherImpl es la clase de implementación de esta interfaz
- Primero, lea los archivos de datos enviados a la puerta de enlace y luego use métodos para analizarlos uno por uno
- Formato de datos: 100 | 101 | 2 | 16 | 1 | 3 | 5d606f7802 | 1 | 1516323596029
- Use split para dividirlos por separado, luego asigne valores a los objetos del entorno y agréguelos a la colección
- Se debe hacer una copia de seguridad de cada análisis. La próxima vez que se lea desde la posición donde finalizó la última vez, cuando se encuentre una excepción, se almacenará en el archivo de excepciones. La próxima vez se juzgará si el archivo de excepciones está vacío, si no está vacío, el archivo de excepción se analizará primero.
-
-
enviar
-
ISender almacena los datos en la colección después de que la puerta de enlace recibe los datos y los envía al servidor
void send(Collection<Enviroment> data) throws EnviromentException; -
SenderImpl es la clase de implementación de esta interfaz
La colección obtenida en GatherImpl usa el socket como puente y usa el flujo de objetos para pasarlo al servidor,
Cuando la cantidad de datos es grande, puede envolverla con bufferedOutputStream, lo que aumentará la velocidad de envío
Esta es también la forma de leer el archivo de propiedades.
El parámetro en el método properties.load () es inputStream, que es conveniente para leer la transmisión. También puede leer archivos de esta manera en el futuro
-
-
Solicitud
El archivo siempre se lee a través de subprocesos múltiples y se envía al cliente
4.3 servidor-ambiente
El contenido del módulo de servidor en la imagen de arriba
-
revicer
-
Revicer es la interfaz para recibir datos, el propósito es devolver una colección de Environment
Collection<Enviroment> revicer() throws EnviromentException; -
RevicerImpl es la clase de implementación de la interfaz, y la colección devuelta por Socket se obtiene a través de ServerSocket
Primero obtenga el número de puerto a través del archivo de propiedades, reciba la información directamente y reciba directamente los datos enviados, y luego forzarlo a la colección de Environment.
-
-
base de datos
-
IStore es una interfaz para almacenar datos en la base de datos, y el propósito es clasificar y almacenar datos
-
IStoreImpl es la clase de implementación de la interfaz, responsable de almacenar el contenido de la colección en la base de datos
-
Obtenga el contenido de la unidad leyendo el archivo de propiedades
-
Dificultad: dividir los datos en 31 tablas según el día, cómo reducir el número de nuevos objetos prepareStatement al hacer los puntos
Al recorrer la colección obtenida actualmente, ingrese primero para determinar si el número del día es el mismo que el número del anterior, si es el mismo, no se necesita ningún objeto nuevo.
Al definir una variable externa, el valor del día se actualiza cada vez y luego la clase de fecha se convierte en una cadena usando SimpleDateFormat.
Asigne los otros valores por separado y luego realice un procesamiento por lotes.
-
-
-
Iniciar sesión
-
Introduzca directamente la dependencia de log4j y luego escriba un archivo de propiedades en formato de registro, cree un objeto de registro y logger.infor ()
Logger logger = Logger.getLogger(GatherImpl.class); logger.info(); logger.debug();
-
4.4 Construcción del proyecto
-
Prueba nativa
Modifique específicamente la ruta del archivo, el método en el kit de herramientas de modificación es usar el flujo de recursos para encontrar en todo el proyecto
-
Prueba de máquina virtual
Debido a que está utilizando una máquina virtual extranjera, debe modificar la zona horaria a la hora de Shanghai (porque el Kunshan local está demasiado cerca de Shanghai, por lo que la hora de Beijing no es sensible) modificar la hora de la máquina virtual a la hora de Shanghai y modificar la dirección IP . . . Dos máquinas virtuales se comunican
//修改虚拟机当前时区为上海 cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime echo 'Asia/Shanghai' >/etc/timezone -
La conexión no ha estado disponible debido a un problema con mi máquina virtual, GG. . .
4.5 Construye un almacén en Github y coloca el proyecto en él
Logger logger = Logger.getLogger (GatherImpl.class);
logger.info ();
logger.debug ();
''
4.4 Construcción del proyecto
-
Prueba nativa
Modifique específicamente la ruta del archivo, el método en el kit de herramientas de modificación es usar el flujo de recursos para encontrar en todo el proyecto
-
Prueba de máquina virtual
Debido a que está utilizando una máquina virtual extranjera, debe modificar la zona horaria a la hora de Shanghai (porque el Kunshan local está demasiado cerca de Shanghai, por lo que la hora de Beijing no es sensible) modificar la hora de la máquina virtual a la hora de Shanghai y modificar la dirección IP . . . Dos máquinas virtuales se comunican
//修改虚拟机当前时区为上海 cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime echo 'Asia/Shanghai' >/etc/timezone -
La conexión no ha estado disponible debido a un problema con mi máquina virtual, GG. . .
4.5 Construye un almacén en Github y coloca el proyecto en él
Hazlo cuando aprendas más tarde