论文 地址 :AID: Ampliando los límites del rendimiento de la estimación de la postura humana
con aumento de caída de información
Resumen del artículo
Este artículo no propone un método nuevo, principalmente para explorar los problemas en la aplicación de métodos de mejora de datos de pérdida de información y las mejoras que se pueden lograr.
El artículo anterior no utilizó el método de mejora de datos de pérdida de información o verificó la falla del método de pérdida de información en el problema de detección de pose. El trabajo realizado en este artículo es descubrir las razones de los fallos anteriores y proponer las soluciones correspondientes, aumentando el tiempo de formación. BlazePose también propuso el uso de métodos de mejora de datos para la pérdida de información, que deberían poder mostrar que la mejora de datos para la pérdida de información es efectiva.
Hablando de manera intuitiva, agregar métodos de mejora de datos para la pérdida de información puede simular la detección de varios puntos de auto oclusión corporal y clave ocluidos por objetos.
Finalmente, bajo la premisa de que la práctica de varios modelos y varias configuraciones correspondientes (resolución, red, etc.) ha mejorado el AP, el autor recomienda que la pérdida de información se utilice como un método convencional de mejora de datos para problemas de detección de pose, al igual que la escala aleatoria. escalado y rotación aleatoria., Lo mismo que giro aleatorio.
Cuando se usa AID, el autor proporciona dos esquemas de capacitación: (1) épocas de entrenamiento doble; (2) Entrenamiento en dos etapas: la primera etapa no usa AID y la segunda etapa agrega AID para refinamiento. El rendimiento de los dos métodos es similar.
Introducción
Tanto las señales de apariencia como las señales de restricción son pistas importantes para la detección de la postura humana. El autor cree que el método de entrenamiento actual permitirá que el modelo sobreajuste las señales de apariencia, y difícilmente se ajuste a las señales de restricción, lo que conduce a una mala predicción de los puntos clave invisibles. Las pistas de apariencia son intuitivamente la estructura corporal de una persona sin obstrucciones; las pistas de restricción son intuitivamente información variada sobre la estructura corporal. En el caso de estar ocluido, las pistas de apariencia se pierden y las pistas de restricción son muy importantes. Entonces, el autor introduce la pérdida de información para obligar a la red a aprender pistas sobre restricciones.
Aunque el propósito teórico de la AID es obtener más información sobre las restricciones, si usa el mismo programa de capacitación que antes, difícilmente tendrá ningún efecto o incluso tendrá un efecto negativo. Mediante la observación de la pérdida y el rendimiento del modelo, AID hará que la capacitación sea un desafío. El autor encontró que si la AID no se usa en la capacitación inicial, habrá un proceso de fácil a difícil, por lo que el autor produjo dos conjuntos de programas de capacitación que aplican AID.
La pérdida de la aplicación de la formación AID será definitivamente mayor que la del esquema sin AID. Si la AID se utiliza directamente para el entrenamiento, hará que el rendimiento del detector de postura disminuya en el proceso de entrenamiento inicial y se hará un seguimiento más tarde, por lo que la AID de entrenamiento tomará un período más largo. El autor proporciona dos esquemas de capacitación: (1) épocas de capacitación dobles; (2) capacitación en dos fases: la primera fase no usa AID y la segunda fase agrega AID para refinamiento. El rendimiento de los dos métodos es similar.
El experimento preliminar muestra: Para el modelo de arriba hacia abajo, CutOut aporta la mayor mejora; para el modelo de abajo hacia arriba, es HaS (áreas múltiples, pérdida de probabilidad).
Resultados experimentales
Utilice el yo en el conjunto de entrenamiento de coco como conjunto de entrenamiento, un total de 57.000 imágenes de entrenamiento y 150.000 ejemplos humanos. Usando HTC como un detector de arriba hacia abajo, su AP en la categoría 80 es 52.9, y para humanos, su AP es 65.1.
COCO
El efecto de val se muestra en la siguiente tabla: Se puede observar que los diferentes modelos de bottom-up y top-down usando AID han mejorado en diferentes resoluciones, que son alrededor de 0.6AP. Si val se divide en dos subconjuntos de puntos clave visibles y puntos clave invisibles, se puede ver en la siguiente tabla que AID no solo mejora la detección de puntos clave invisibles, sino que también mejora la detección de puntos clave visibles.
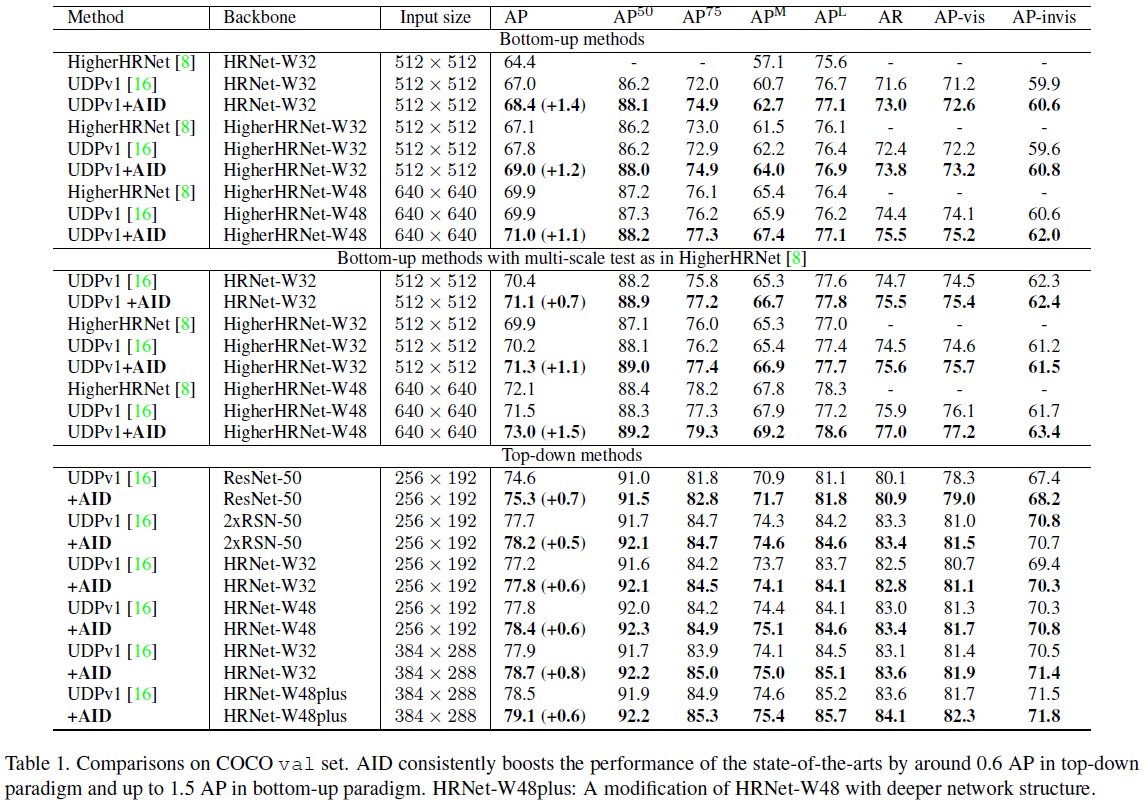
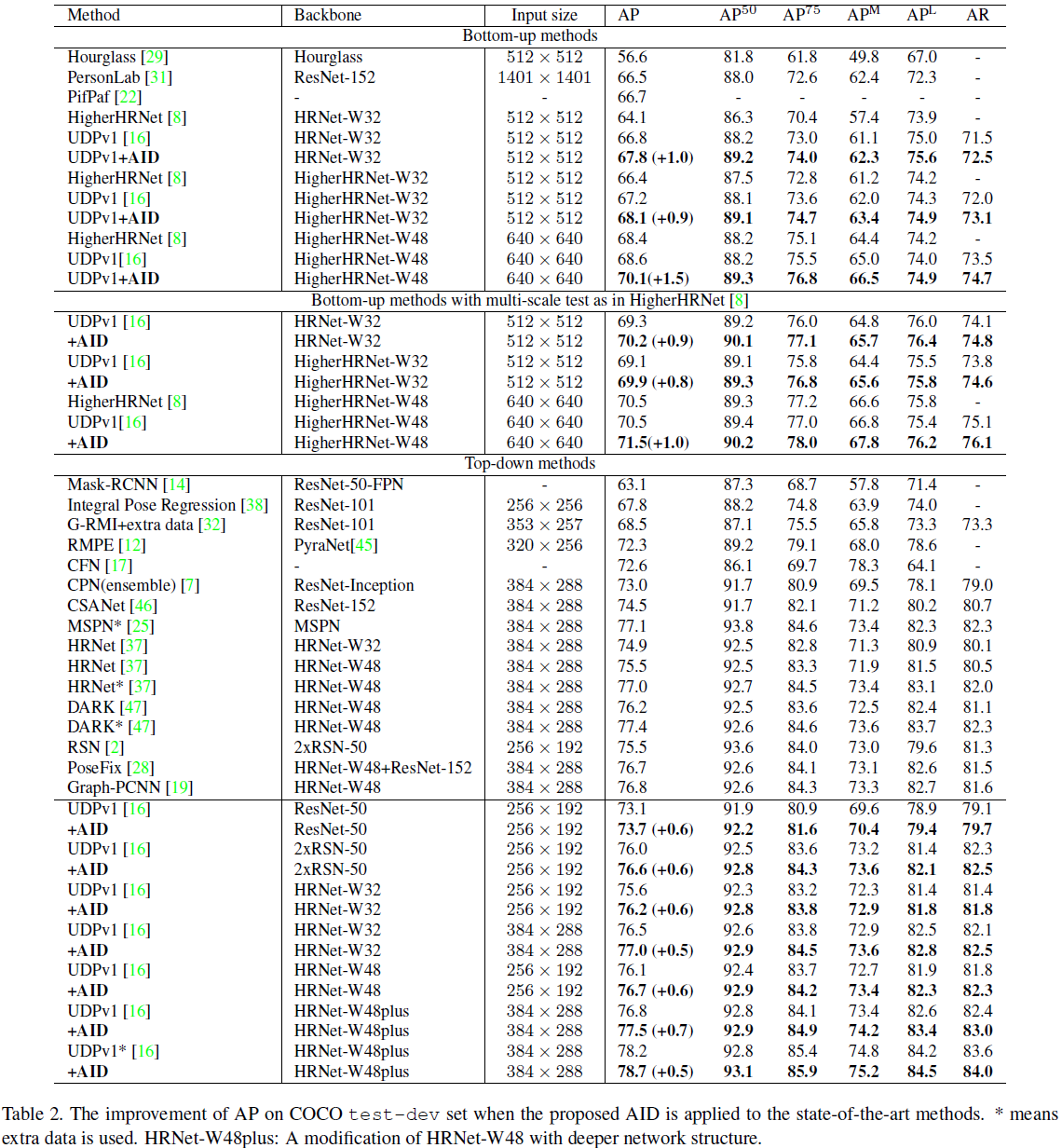
El efecto sobre test-dev se muestra en la siguiente tabla: donde ∗ *∗ indica que se utilizan datos adicionales AI Challenger. Usando datos adicionales, el modelo original 78.2AP ya es muy alto, pero cuando se usa AID, aún agrega 0.5AP a 78.7AP. Esto muestra que un modelo entrenado con más datos puede mejorar eficazmente el rendimiento del modelo, pero aún no puede resolver el problema del sobreajuste. La AID sigue siendo una solución eficaz.
CrowdPose
Los resultados de CrowdPose se muestran en la siguiente tabla: Tome HigherHRNet como referencia.

Aprendizaje de ablación
Explore los experimentos de Cutout, Has y GridMask. En la mejora de datos, la configuración de hiperparámetros es muy importante. Con el fin de hacer comparables varios métodos, el autor hizo que la pérdida inicial fuera lo más cercana posible para minimizar el impacto de los hiperparámetros. Finalmente se obtuvieron dos conclusiones: (a) El desempeño de los diferentes esquemas de pérdida de información en el sistema bottom-up es diferente, pero son similares en top-down; (b) HaS es el mejor para bottom-up y Cutout es para Top- abajo es el mejor. Los resultados experimentales se muestran en la siguiente figura:
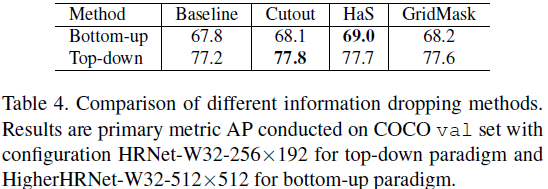
Experimento de aprendizaje de ablación del programa de entrenamiento.
El modelo utilizado es HRNet-W32-256x192, y las cajas humanas Ground-truth se utilizan para explorar el impacto del esquema de entrenamiento cuando se usa AID. Hay tres esquemas: (1) El mismo esquema de entrenamiento que HRNet, la tasa de aprendizaje inicial es 1e-3, luego cae a 1e-4 en 170 épocas y 1e-5 en 200 épocas, un total de 210 épocas; (2 ) Dos veces el período de entrenamiento de (1), reduciendo la tasa de aprendizaje en 380 y 410 épocas respectivamente; (3) Repita el experimento de (1), pero los dos primeros experimentos no usan AID y el segundo usa AID.
Hay diferentes períodos de tiempo, por lo que se realizan cinco experimentos:

Los valores de rendimiento y pérdida se muestran en la siguiente figura: E1 y E2 usan esquemas de entrenamiento que son ambos S1. La diferencia radica en si se usa AID y la pérdida cuando se usa AID es mayor. En el proceso de entrenamiento inicial, E2 se desempeñó peor que E1, lo que indica que en el proceso de entrenamiento inicial, la información sobre la apariencia es muy importante y la asistencia interferirá con el estudio de las características de la apariencia. Sin embargo, E1 y E2 tienen un rendimiento de modelo similar al final de la capacitación, lo que muestra que en el esquema de capacitación original, AID no tendrá un impacto positivo. Comparando E3 y E4, E4 comienza a superar a E3 en 250 épocas, y la ventaja es cada vez más grande en los entrenamientos posteriores.

Visualización del rendimiento del modelo en el papel.
En la siguiente figura, la izquierda es la verdad del terreno, el medio es el modelo con entrenamiento AID y la derecha es el modelo de referencia.
