Este artículo es una reproducción de InfoQ, autora Anna Anisienia
Aunque Python es más lento que muchos lenguajes compilados, es fácil de usar y versátil. Para muchas personas, la utilidad del lenguaje supera a la velocidad.
Soy un ingeniero de Python, por lo que podría pensar que soy parcial. Pero quiero aclarar algunas críticas a Python y reflexionar sobre si es necesario preocuparse por la velocidad en el trabajo diario como la ingeniería de datos, ciencia de datos y análisis con Python.
¿Python es demasiado lento?
En mi opinión, este tipo de problema debería basarse en un contexto o caso de uso específico. En comparación con los lenguajes compilados como C, ¿Python es lento para procesar valores numéricos? Sí, es lento. Este hecho se conoce desde hace muchos años, por lo que existen bibliotecas de Python que juegan un papel vital en la velocidad, como numpy, que usa C debajo.
Pero para todos los casos de uso, ¿Python es mucho más lento que otros lenguajes (más difíciles de aprender y usar)? Si observa los puntos de referencia de rendimiento de las bibliotecas de Python optimizadas para resolver problemas específicos, encontrará que su rendimiento es bastante bueno en comparación con los lenguajes compilados. Por ejemplo, eche un vistazo a los puntos de referencia de rendimiento de FastAPI; obviamente, Go como lenguaje compilado es mucho más rápido que Python. Sin embargo, FastAPI aún supera a algunas bibliotecas de Go en la creación de API REST:
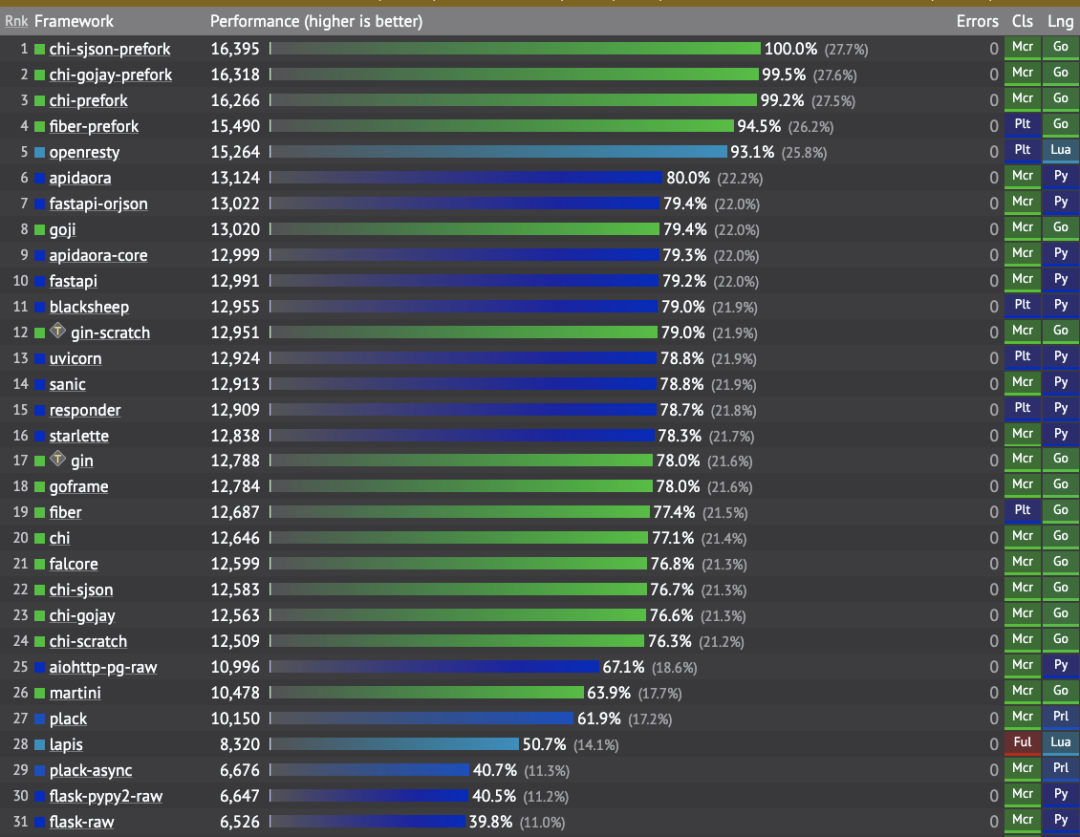
Evaluación comparativa del marco web
Nota al margen: Los marcos web C ++ y Java de mayor rendimiento no se incluyen en la lista anterior.
De manera similar, al comparar Dask (escrito en Python) y Spark (escrito en Scala) en una canalización de neuroimagen de uso intensivo de datos, el autor llegó a las siguientes conclusiones:
En general, nuestros resultados muestran que no hay una diferencia sustancial en el rendimiento entre los dos motores.
La pregunta que debemos hacernos es qué tipo de velocidad realmente necesitamos. Si solo necesita activar un trabajo ETL una vez al día, no necesita preocuparse si toma 20 segundos o 200 segundos. Entonces, puede preferir que el código sea fácil de entender, empaquetar y mantener, especialmente considerando que los recursos informáticos son cada vez más baratos que los motores costosos.
Velocidad de código vs practicidad
Desde un punto de vista práctico, al elegir un lenguaje de programación para el trabajo diario, debemos responder varias preguntas diferentes.
¿Puede resolver de manera confiable varios problemas comerciales en este idioma?
Si solo te importa la velocidad, no uses Python. Para varios casos de uso, existen alternativas más rápidas. La principal ventaja de Python radica en su legibilidad, facilidad de uso y la capacidad de usarlo para resolver varios problemas. Python se puede utilizar como un "pegamento" para conectar varios sistemas, servicios y casos de uso.
¿Puede encontrar suficientes empleados que comprendan este idioma?
Dado que Python es muy fácil de aprender y usar, la cantidad de usuarios de Python ha ido creciendo. Los usuarios comerciales que solían procesar valores numéricos en Excel ahora pueden aprender a codificar en Pandas muy rápidamente, aprendiendo así a ser autosuficientes sin depender de los recursos de TI. Al mismo tiempo, esto también descarga a los departamentos de análisis y TI. También acorta el tiempo para valorar la realización.
Hoy en día, es mucho más fácil encontrar un ingeniero de datos que entienda Python y pueda mantener las aplicaciones de procesamiento de datos Spark en este lenguaje que encontrar un ingeniero de Java o Scala que haga lo mismo. Muchas organizaciones han recurrido a Python para muchos casos de uso solo porque tienen una mayor probabilidad de encontrar empleados que puedan "hablar" el idioma.
Por el contrario, sé que algunas empresas necesitan desesperadamente desarrolladores de Java o C # para mantener las aplicaciones existentes, pero estos lenguajes son difíciles (lleva años dominarlos) y parecen poco atractivos para los programadores novatos, porque pueden usar lenguajes más simples (como como Go o Python) para obtener más ingresos.
Sinergia entre expertos en diferentes campos
Si su empresa utiliza Python, es probable que los usuarios comerciales, analistas de datos, científicos de datos, ingenieros de datos, desarrolladores web y de back-end, ingenieros de DevOps e incluso administradores de sistemas utilicen el mismo lenguaje. Esto puede crear sinergias en el proyecto, permitiendo que personas de diferentes campos trabajen juntas y utilicen las mismas herramientas.
¿Cuál es el verdadero cuello de botella en el procesamiento de datos?
Según mi propio trabajo, el cuello de botella que suelo encontrar no es el idioma en sí, sino los recursos externos. Más específicamente, veamos algunos ejemplos.
Escribir en una base de datos relacional
Cuando procesamos datos en ETL, eventualmente necesitamos cargar los datos en un lugar centralizado. Aunque podemos usar subprocesos múltiples en Python para escribir datos en algunas bases de datos relacionales más rápido (usando más subprocesos), el aumento en el número de escrituras paralelas puede maximizar la capacidad de CPU del valor de la base de datos.
De hecho, esto sucedió una vez cuando utilicé subprocesos múltiples para acelerar la escritura en la base de datos RDS Aurora en AWS. Luego noté que la utilización de la CPU del nodo escritor aumentó tanto que tuve que ralentizar deliberadamente el código utilizando menos subprocesos para garantizar que la instancia de la base de datos no se dañara.
Esto significa que Python tiene mecanismos para paralelizar y acelerar muchas operaciones, pero las bases de datos relacionales (limitadas por el número de núcleos de CPU) tienen sus limitaciones, y es imposible resolver este problema solo usando lenguajes de programación más rápidos.
Llamar a API externa
Otro ejemplo en el que el lenguaje en sí no es un cuello de botella es utilizar una API REST externa (es posible que desee extraer datos de ella para satisfacer las necesidades de análisis de datos). Aunque podemos usar el paralelismo para acelerar la extracción de datos, puede ser inútil porque muchas API externas limitan la cantidad de solicitudes que podemos realizar en un cierto período de tiempo. Por lo tanto, a menudo puede encontrar que necesita reducir deliberadamente la velocidad de ejecución de su script para asegurarse de que no se exceda el límite de solicitud de API:
time.sleep(10)Procesando big data
Según mi experiencia con grandes conjuntos de datos, no importa qué idioma se utilice, es imposible cargar "grandes datos" reales en la memoria de una computadora portátil. Para tales casos de uso, es posible que deba utilizar marcos de procesamiento distribuidos como Dask, Spark, Ray, etc. Cuando se utiliza una sola instancia de servidor o una computadora portátil, la cantidad de datos que se pueden procesar es limitada.
Si desea transferir el trabajo de procesamiento de datos real a un conjunto de nodos informáticos, o incluso desea usar instancias de GPU para acelerar aún más el cálculo, entonces Python tiene un enorme ecosistema de marco que puede simplificar esta tarea:
-
¿Quiere utilizar GPU para acelerar los cálculos de ciencia de datos? Utilice Pytorch, Tensorflow, Ray o Rapids (o incluso SQL-BlazingSQL)
-
¿Quiere acelerar el código Python que procesa macrodatos? Utilice Spark (o Databricks), Dask o Prefect (Dask se resume en la parte inferior)
-
¿Quiere acelerar la velocidad de procesamiento del análisis de datos? Al utilizar una base de datos de columna rápida dedicada a la memoria, el procesamiento de alta velocidad solo se puede garantizar mediante consultas SQL.
Si necesita orquestar y monitorear el procesamiento de datos en un clúster de nodos informáticos, existen varias plataformas de administración de flujo de trabajo escritas en Python que se pueden usar, lo que puede acelerar el desarrollo y mantenimiento de las canalizaciones de datos, como Apache Airflow, Prefect o Dagster. . Si quieres saber más al respecto, consulta mi artículo anterior.
Por cierto, puedo imaginar que algunas personas que se quejan de Python no lo aprovechan al máximo, o tal vez no utilizan la estructura de datos adecuada para resolver el problema en cuestión.
Con todo, si necesita procesar grandes cantidades de datos rápidamente, es posible que necesite más recursos informáticos en lugar de lenguajes de programación más rápidos, y algunas bibliotecas de Python pueden distribuir fácilmente el trabajo a cientos de nodos.
En conclusión
En este artículo, discutimos si Python es el verdadero cuello de botella en el campo actual del procesamiento de datos. Aunque Python es más lento que muchos lenguajes compilados, es fácil de usar y versátil. Notamos que para muchas personas, la utilidad del lenguaje supera a la velocidad.
Finalmente, discutimos que, al menos en ingeniería de datos, el lenguaje en sí puede no ser el cuello de botella, sino la limitación del sistema externo y la gran cantidad de datos que no se pueden procesar en una sola máquina sin importar qué lenguaje de programación se seleccione. .