Métodos de aprendizaje automático en la previsión de series de tiempo (6): Red de memoria a largo-corto plazo (LSTM)
Este artículo es el sexto artículo de la serie de "Métodos de aprendizaje automático en el pronóstico de series de tiempo". Si está interesado, puede leer los artículos anteriores primero:
[Análisis de datos] Uso de algoritmos de aprendizaje automático para el análisis predictivo (1): Promedio móvil (Promedio móvil) Promedio)
[Análisis de datos] Análisis predictivo con algoritmos de aprendizaje automático (2): Regresión lineal
[Análisis de datos] Análisis predictivo con algoritmos de aprendizaje automático (3): K-Vecinos más cercanos
[Análisis de datos] Análisis predictivo con algoritmos de aprendizaje automático (4): Modelo de promedio móvil diferencial autorregresivo (AutoARIMA)
[Análisis de datos] Análisis predictivo mediante algoritmos de aprendizaje automático (5): Prophet
1. Introducción a LSTM
Long Short-Term Memory (LSTM) es una arquitectura de red neuronal recurrente artificial (RNN) utilizada en el campo del aprendizaje profundo. A diferencia de las redes neuronales de retroalimentación estándar, LSTM tiene conexiones de retroalimentación. Puede procesar no solo un único punto de datos (como una imagen), sino también una secuencia de datos completa (como voz o video).
La red LSTM es muy adecuada para la clasificación, el procesamiento y la predicción basados en datos de series de tiempo, porque puede haber un desfase de duración desconocida entre eventos importantes en la serie de tiempo. LSTM fue desarrollado para hacer frente a los problemas de explosión y desaparición de gradientes que pueden surgir al entrenar a los RNN tradicionales. La relativa insensibilidad a la longitud del espacio es la ventaja de LSTM sobre RNN, el modelo de Markov oculto y otros métodos de aprendizaje de secuencias en muchas aplicaciones.
2. Ejemplo de "previsión del precio de las acciones"
El conjunto de datos es el mismo que el del artículo anterior y el propósito es comparar los efectos de predicción de diferentes algoritmos en el mismo conjunto de datos. El conjunto de datos y el código están en mi GitHub , y los amigos que lo necesiten pueden descargarlos por sí mismos.
Importe el paquete y lea los datos. Asegúrese de que los paquetes sklearn y keras estén instalados correctamente.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
df = pd.read_csv('NSE-TATAGLOBAL11.csv')
Establezca el índice. Para no destruir los datos originales, reconstruya un archivo new_data.
# setting the index as date
df['Date'] = pd.to_datetime(df.Date,format='%Y-%m-%d')
df.index = df['Date']
#creating dataframe
data = df.sort_index(ascending=True, axis=0)
new_data = pd.DataFrame(index=range(0,len(df)),columns=['Date', 'Close'])
for i in range(0,len(data)):
new_data['Date'][i] = data['Date'][i]
new_data['Close'][i] = data['Close'][i]
new_data.index = new_data.Date
new_data.drop('Date', axis=1, inplace=True)
Eche un vistazo al formato de new_data.
new_data
#creating train and test sets
dataset = new_data.values
dataset

Divida los datos en conjunto de entrenamiento y conjunto de prueba.
train = dataset[0:987,:]
valid = dataset[987:,:]
Normaliza el conjunto de datos.
#converting dataset into x_train and y_train
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(dataset)
scaled_data
La forma en que entrenamos el modelo es usar los 60 valores delante de cada número para entrenar.
x_train, y_train = [], []
for i in range(60,len(train)):
x_train.append(scaled_data[i-60:i,0])
y_train.append(scaled_data[i,0])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train.shape

y_train.shape

x_train = np.reshape(x_train, (x_train.shape[0],x_train.shape[1],1))
Construye una red LSTM. Sequential representa un modelo secuencial. La operación principal es agregarle capas. Además de LSTM, también puede agregar una capa convolucional Conv2D, una capa de agrupación máxima MaxPooling y una capa de aplanamiento Flatten.
# create and fit the LSTM network
model = Sequential() # 顺序模型,核心操作是添加layer(图层)
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1],1)))
model.add(LSTM(units=50))
model.add(Dense(1)) #全连接层
model.compile(loss='mean_squared_error', optimizer='adam') #选择优化器,并指定损失函数
model.fit(x_train, y_train, epochs=1, batch_size=1, verbose=2)

Usaremos los 60 números delante de cada dato para predecir este número. Se predice un total de 248 números.
#predicting 248 values, using past 60 from the train data
inputs = new_data[len(new_data) - len(valid) - 60:].values # 1235 - 927 - 60 = 308
inputs = inputs.reshape(-1,1)
inputs = scaler.transform(inputs)
inputs.shape

X_test representa la entrada del conjunto de predicciones en el modelo.
X_test = []
for i in range(60,inputs.shape[0]):
X_test.append(inputs[i-60:i,0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0],X_test.shape[1],1))
X_test.shape

Comience a predecir con el modelo y convierta los datos estandarizados en datos brutos.
closing_price = model.predict(X_test)
closing_price = scaler.inverse_transform(closing_price)
Esta vez, observe el valor de RMSE, que es mucho menor que el valor obtenido por el método de predicción centralizado anterior, lo que indica que el error es relativamente pequeño.
rmse = np.sqrt(np.mean(np.power((valid - closing_price),2)))
rmse

Mira el pronóstico dibujando.
#for plotting
train = new_data[:987]
valid = new_data[987:]
valid['Predictions'] = closing_price
plt.figure(figsize=(16,8))
plt.plot(train['Close'])
plt.plot(valid[['Close','Predictions']])
plt.show
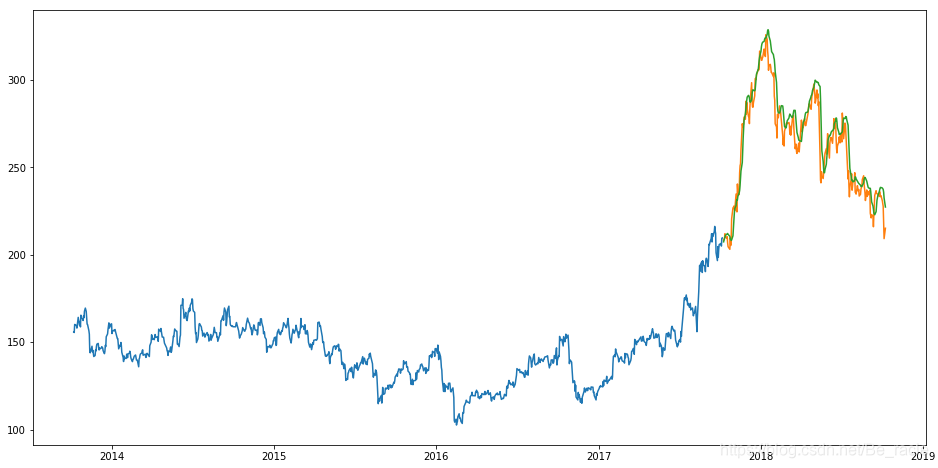
Puede verse que la predicción de LSTM en este conjunto de datos de precios de cierre del mercado de valores es relativamente precisa. Por supuesto, también podemos ajustar el modelo LSTM para varios parámetros, como cambiar el número de capas LSTM, agregar álgebra de entrenamiento, etc.
A través de los resultados de estos diversos experimentos, podemos ver que en la predicción de este stock, el algoritmo de media móvil, el algoritmo de regresión lineal, el algoritmo Arima, etc.no han mostrado buenos resultados de predicción, pero los resultados de predicción del algoritmo LSTM son más en línea con nosotros Valor esperado. Por supuesto, esto no significa que el algoritmo LSTM sea el mejor algoritmo de predicción de series de tiempo. Para diferentes temas, se necesita un análisis específico. Por ejemplo, si un supermercado quiere predecir las ventas futuras de diferentes productos básicos, definitivamente no encontrará un algoritmo definitivo para satisfacer todas las categorías. Una mejor solución es utilizar diferentes algoritmos para predecir cada categoría y encontrar la curva de predicción que mejor se ajuste a la categoría.
Incluso con el apoyo de algoritmos de aprendizaje automático, en la mayoría de los casos, es difícil para nosotros hacer predicciones precisas. Predecir el mercado de valores es muy difícil y hay demasiados factores inciertos. Y con el paso de las series de tiempo, para una determinada previsión de ventas de productos básicos, incluso si se encuentra el mejor algoritmo de previsión temporal, no significa que este algoritmo de previsión esté disponible en el futuro. ¿Dónde aparecerá el punto de inflexión en el tiempo? Esta es también una pregunta que debe considerarse.
Escrito en la parte posterior: "Predicción de precios de acciones mediante técnicas de aprendizaje automático y aprendizaje profundo", este artículo es muy útil para aprender a utilizar métodos de aprendizaje automático para el análisis predictivo basado en series de tiempo . Estos blogs son equivalentes a mis notas de estudio para escribir y promover el aprendizaje.