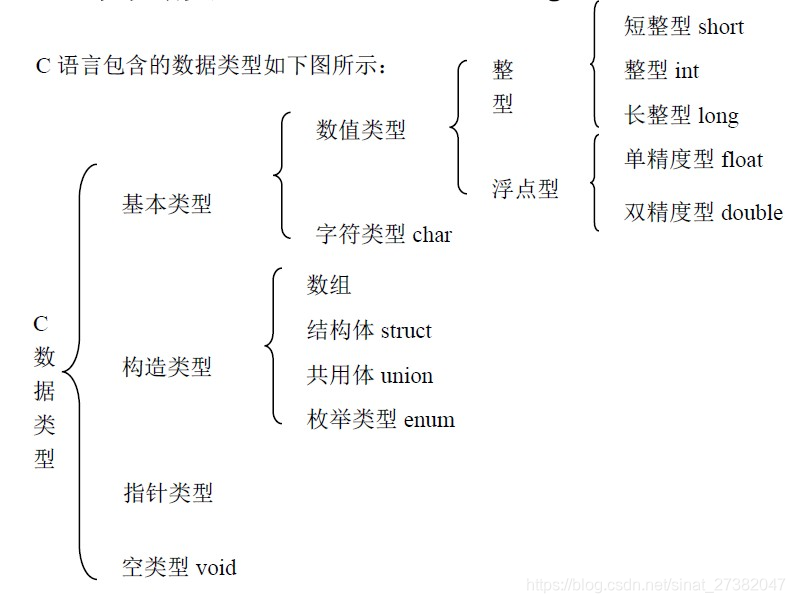
1. Relacionado con la máquina / sistema
1. Tabla de nombres
8 bits (bit, bit) = 2 bytes (Byte) = 1 palabra (WORD) [La "palabra" que dice el bus varía según el sistema]
1. Bit (bit)
Bit es la unidad más pequeña de almacenamiento de la computadora, abreviada como b, también conocida como bit (bit). La computadora usa 0 y 1 en binario para representar datos, y 0 o 1 representa un bit. Bit también es un bit en un número binario. Es la unidad de medida de la cantidad de información y la unidad más pequeña de la cantidad de información;
2. Byte
byte, English Byte, es una unidad de medida utilizada por las computadoras para medir el almacenamiento capacidad. byte es igual a ocho, pero también en un número de bytes en un lenguaje de programación de computadoras, y los datos que indican el tipo de caracteres del lenguaje, en las computadoras modernas, un byte es igual a ocho;
3, palabra
palabra es un término natural computadora unidad de datos en un En una computadora específica, una palabra es un grupo de bits de longitud fija que se utiliza para procesar transacciones al mismo tiempo. En las computadoras modernas, una palabra equivale a dos bytes.
Además, hay DWORD de palabra doble, QWORD de cuatro palabras
2. Direccionamiento y longitud de las palabras
1. La longitud de la palabra de máquina se refiere a la cantidad de bits que la CPU puede procesar datos a la vez, generalmente relacionada con la cantidad de registros de la CPU.
2. Longitud de la palabra de instrucción, el número de palabras de instrucción de computadora. La longitud de la palabra de instrucción depende de la longitud del código de operación esclavo, la longitud de la dirección del operando y el número de direcciones de operando. La longitud de palabra de diferentes instrucciones es diferente.
3. La longitud de la palabra de almacenamiento es una unidad de almacenamiento que almacena una cadena de códigos binarios (palabras de almacenamiento) El número de bits en esta cadena de códigos binarios se denomina longitud de la palabra de almacenamiento.
4. Longitud de la palabra de datos: la cantidad de bits ocupados por el almacenamiento de datos de la computadora.
Por lo general, las primeras computadoras: longitud de la palabra de almacenamiento = longitud de la palabra de instrucción = longitud de la palabra de datos. Por lo tanto, se puede obtener una instrucción o un dato a la vez.Con la expansión continua del rango de aplicaciones informáticas, los tres pueden ser diferentes, pero deben ser múltiplos enteros de bytes.
La CPU se puede dividir en microprocesador de 8 bits, microprocesador de 16 bits, microprocesador de 32 bits, microprocesador de 64 bits, etc. de acuerdo con la longitud de palabra de la información procesada.
El rango máximo de direcciones que puede encontrar la CPU se denomina capacidad de direccionamiento. La capacidad de direccionamiento de la CPU está en bytes. Por
ejemplo, una CPU de direccionamiento de 32 bits puede direccionar 2 a la 32.a potencia de la dirección, que es 4G, que es por qué 32 bits La razón por la cual la CPU puede coincidir con una memoria 4G, no se puede encontrar ninguna cantidad de CPU.
——En principio, la CPU de 32 bits no se puede instalar con un sistema de 64 bits (las computadoras tienen muy pocas CPU de 32 bits) . La memoria admitida por el
sistema operativo de acuerdo con el sistema operativo de
32 bits es 2 elevado a 32 , que son 4 GB de memoria.
El espacio de direccionamiento teórico de un sistema operativo de 64 bits es 2 elevado al 64 bit de potencia, y la unidad de conversión es 2147483648GB.
3. Método de codificación (el motivo de los caracteres confusos)
Código ASCII: una letra en inglés (no distingue entre mayúsculas y minúsculas) ocupa un byte de espacio. Una secuencia de números binarios, como una unidad digital en una computadora, es generalmente un número binario de 8 bits. Convertido a decimal, el mínimo es -128 y el máximo es 127. Por ejemplo, un código ASCII es un byte.
Codificación UTF-8: un carácter en inglés equivale a un byte y un carácter en chino (incluido el tradicional) equivale a tres bytes. La puntuación en chino ocupa tres bytes y la puntuación en inglés ocupa un byte.
Codificación Unicode: un inglés equivale a dos bytes y un chino (incluido el tradicional) equivale a dos bytes. La puntuación china ocupa dos bytes, la puntuación en inglés ocupa dos bytes
La clave para comprender la codificación es comprender el concepto de caracteres y el concepto de bytes con precisión. Estos dos conceptos son fáciles de confundir, así que hagamos una distinción:
un ejemplo de descripción de un concepto
, un símbolo usado por personas y un símbolo en un sentido abstracto. '1', 'medio', 'a', '$', '¥' ......
La unidad de almacenamiento de datos en una computadora de bytes, un número binario de 8 bits, es un espacio de almacenamiento muy específico. 0x01, 0x45, 0xFA ...
Palabra
En una computadora, una cadena de números procesados o calculados como un todo se llama palabra de computadora, o palabra abreviada. Una palabra generalmente se divide en varios bytes (cada byte es generalmente de 8 bits). En la memoria, normalmente cada celda almacena una palabra, por lo que cada palabra es direccionable. La longitud de la palabra se expresa en bits.
En la unidad aritmética y controlador de la computadora, generalmente se transmite en unidades de palabras. El significado de las palabras que aparecen en diferentes direcciones es diferente. Por ejemplo, la palabra enviada al controlador es una instrucción y la palabra enviada a la unidad aritmética es un número.
Cadena
en la memoria, si "carácter" existe en forma codificada ANSI, un carácter puede estar representado por un byte o más bytes, entonces llamamos a este tipo de cadena una cadena ANSI o una cadena multibyte. Por ejemplo, "123 chino" (ocupa 8 bytes, incluido un \ 0 oculto).
Juego de caracteres
Para la codificación ANSI, existen diferentes juegos de caracteres (Juego de caracteres). La misma secuencia de bytes representa diferentes caracteres en diferentes conjuntos de caracteres. Para analizar correctamente una cadena ANSI, debe seleccionar el conjunto de caracteres correcto; de lo contrario, puede causar el llamado fenómeno confuso. Las diferentes versiones de idiomas de los sistemas operativos tienen un juego de caracteres predeterminado. Si no se especifica el juego de caracteres, el sistema usará este juego de caracteres para analizar cadenas ANSI. En otras palabras, si abrimos un archivo de texto ANSI (archivo de texto que contiene solo cadenas ANSI) guardado por el sistema operativo japonés bajo la versión china simplificada de Windows, veremos caracteres confusos. Sin embargo, si abrimos este archivo con un editor de texto con selección de codificación como Visual Studio y seleccionamos el juego de caracteres correcto, podremos ver su apariencia original. Nota: Es posible que los caracteres tradicionales del conjunto de caracteres del chino simplificado y los caracteres tradicionales del conjunto de caracteres del chino tradicional no tengan la misma codificación.
Cada juego de caracteres tiene un número determinado, llamado página de códigos (página de códigos). La página de códigos del chino simplificado (GB2312) es 936 y la página de códigos del juego de caracteres predeterminado del sistema es 0, lo que significa que se selecciona un juego de caracteres adecuado según la configuración de idioma del sistema.
Unicode
Las cadenas se almacenan en la memoria. Si los "caracteres" existen como números de serie en Unicode, entonces llamamos a esta cadena una cadena Unicode o una cadena de bytes anchos. En Unicode, cada carácter ocupa dos bytes. Por ejemplo, "123 chino" (ocupa 10 bytes). La diferencia entre Unicode y ANSI es equivalente a la diferencia entre "ancho completo" y "medio ancho" en el método de entrada.
Dado que los estándares estipulados por diferentes códigos ANSI son diferentes (los juegos de caracteres son diferentes), para una cadena de varios bytes dada, debemos saber qué juego de caracteres usa para saber que contiene Qué "caracteres" se usan. Para las cadenas Unicode, independientemente del entorno, el contenido de "caracteres" que representa es siempre el mismo. Unicode tiene un estándar unificado que define la codificación de la mayoría de los caracteres del mundo, de modo que el latín, los números, el chino simplificado, el chino tradicional y el japonés se pueden almacenar en la misma codificación.
2. Práctica: Programa de lenguaje C.
1. Tipo de almacenamiento
En una microcomputadora, cuántos bytes se usan generalmente para expresar la capacidad de almacenamiento de la memoria.
En diferentes sistemas, las longitudes de bytes ocupadas por estos tipos son diferentes:
short, int, long, char, float, double Estas seis palabras clave representan los seis tipos de datos básicos en el lenguaje C.
El tamaño de memoria ocupado por char en un sistema de 32 bits es de 1 byte.
El tamaño de memoria ocupado por short es 2 bytes;
el tamaño de memoria ocupado por int es 4 bytes;
el tamaño de memoria ocupado por float es 4 bytes;
el tamaño de memoria ocupado por double es 8 bytes;
el tamaño de memoria ocupado por long int es 4 bytes ;
* Puede usar la palabra clave del lenguaje C sizeof () para obtener el número de bytes ocupados actualmente.
Aunque el entero int, el flotante de punto flotante y el unsigned unsigned tienen la misma longitud en bytes, se almacenan de diferentes maneras y se leen de diferentes maneras.
Para obtener más detalles , consulte mi otro blog: El lenguaje C genera 0.000000 o caracteres confusos, y ahondar en ella.
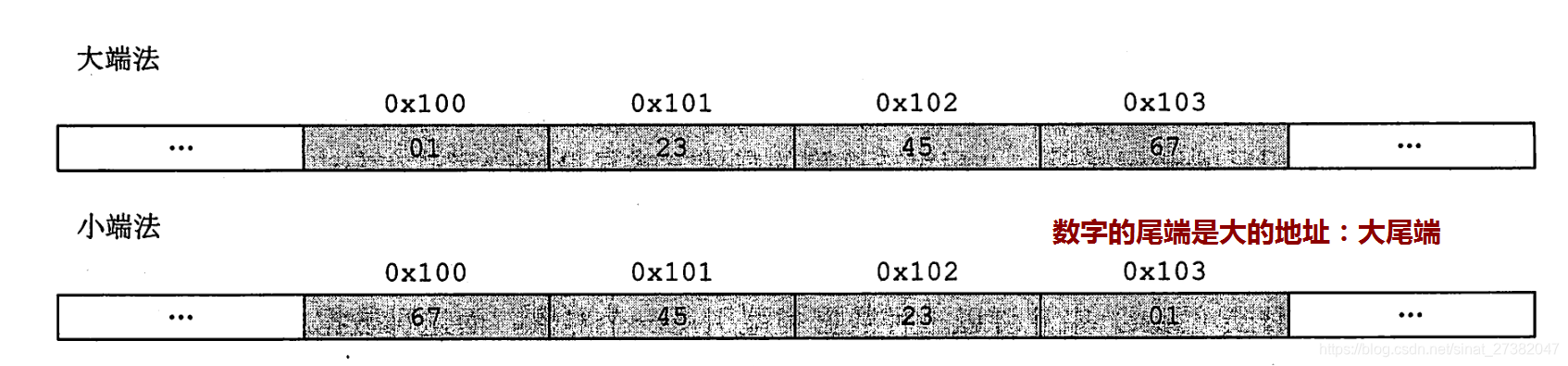
2. Big endian, little endian (orden de bytes)
El modo Big Endian significa que el byte alto de datos se almacena en la dirección baja de la memoria y el byte bajo de datos se almacena en la dirección alta de la memoria. Este modo de almacenamiento es un poco similar a tratar los datos como una cadena Procesamiento de secuencia: La dirección aumenta de pequeña a grande y los datos se colocan de mayor a menor, esto es consistente con nuestros hábitos de lectura.
El modo Little Endian significa que el byte alto de datos se almacena en la dirección alta de la memoria, y el byte bajo de datos se almacena en la dirección baja de la memoria. Este modo de almacenamiento combina efectivamente el alto y bajo de la dirección con el Peso de bits de datos Arriba, la parte de dirección más alta tiene un peso más alto y la parte de dirección más baja tiene un peso más bajo.
* Nota
Debido a que un bloque de memoria en esta imagen es un byte con 8 bits, ponga 2 F (hexadecimal, 4 bits, 1111) ,
cuando mire esta imagen, debe poner "01", "23", "45" , "67" se considera "una palabra, estructura izquierda y derecha",
por lo que
1. "76 54 32 10" no aparecerá en little endian
2. El orden de bytes de red aparecerá para short, int, double, etc. más de uno byte, El problema de la endianidad.
Determina si es big endian
bool IsBig_Endian()
//如果字节序为big-endian,返回true;
//反之为little-endian,返回false
{
unsigned short test = 0x1122;
if (*((unsigned char*)&test) == 0x11)
return 1;
else
return 0;
}//IsBig_Endian()
3. Las palabras de diferentes sistemas / máquinas / compiladores ocupan diferentes bytes
El bus generalmente está diseñado para transmitir un dato de un tamaño fijo. Este dato se llama palabra. El número de bytes contenidos en una palabra (es decir, el tamaño de la palabra) es un parámetro básico en varias computadoras sistemas. Generalmente es diferente en diferentes sistemas. En la mayoría de los sistemas informáticos modernos, una palabra tiene 4 bytes u 8 bytes.
De aquí podemos ver que simplemente preguntar cuántos bytes ocupa una palabra no tiene sentido, porque el tamaño de la palabra depende de ello. El ancho del bus del sistema específico , si es un sistema de 32 bits (X86), una palabra tiene 4 bytes, si es un sistema de 64 bits (X64), tiene 8 bytes.
4. Extremo de bit (campo de bit), operación de bit, estructura
Al realizar operaciones con bits, también es necesario conocer algunas situaciones en las que se utiliza el bit máximo actual
#include<stdio.h>
#define WORDSIZE 32 //我现在是X86模式编译,占32位,4字节(32位=4字节)
int main()
{
unsigned a, b, c;
int n;
printf("请输入a和n \n");
scanf("%x,%d", &a, &n);
b = a << (WORDSIZE - n);//书中源码这里是16(字节),我运行发现总是不对,发现我现在是X86模式编译,占32位
c = a >> n;
c = c ^ b;
printf("a:%x \nc:%x", a, c);
printf("%d", IsBig_Endian());
return 0;
}
3. Unidades de escala (prefijo del Sistema Internacional de Unidades)
El Sistema Internacional de Unidades (SI) entre diferentes órdenes de magnitud:
1KB = 1024B; 1MB = 1024KB = 1024 × 1024B.
El estándar de la Comisión Electrotécnica Internacional para símbolos de letras para tecnología eléctrica es IEC 60027-2 e IEC 80000-13.
El almacenamiento de datos se expresa en sistema decimal y la transmisión de datos se expresa en sistema binario, por lo que 1KB no es igual a 1000B.
1B (byte, byte) = 8 bits (ver más abajo);
1KB (Kilobyte, kilobyte) = 1024B = 2 ^ 10 B;
1MB (Megabyte, megabyte, millón de bytes, denominado "mega") = 1024KB = 2 ^ 20 B;
1 GB (gigabyte, gigabyte, mil millones de bytes, también conocido como "gigabyte") = 1024 MB = 2 ^ 30 B;
1 TB (terabyte, billón de bytes, terabytes) = 1024 GB = 2 ^ 40 B; 1
PB (petabyte, petabytes, petabytes ) = 1024 TB = 2 ^ 50 B;
1EB (Exabyte, decenas de exabytes, exabytes) = 1024PB = 2 ^ 60 B;
1ZB (Zettabyte, diez billones de bytes, zettabytes) = 1024EB = 2 ^ 70 B;
1YB (Yottabyte, uno cien millones de billones de bytes, Yao bytes) = 1024ZB = 2 ^ 80 B;
1BB (Brontobyte, Cien mil millones de billones de bytes) = 1024YB = 2 ^ 90 B;
1NB (NonaByte, un billón de billones de bytes) = 1024BB = 2 ^ 100 B ;
1DB (DoggaByte, mil millones de billones de bytes) = 1024 NB = 2 ^ 110 B;
yotta Y 10008 10^24 1000000000000000000000000 Septillion Quadrillion 1991
zetta Z 10007 10^21 1000000000000000000000 Sextillion Trilliard 1991
exa E 10006 10^18 1000000000000000000 Quintillion Trillion 1975
peta P 10005 10^15 1000000000000000 Quadrillion Billiard 1975
tera T 10004 10^12 1000000000000 Trillion Billion 1960
giga G 10003 10^9 1000000000 Billion Milliard 1960
mega M 10002 10^6 1000000 Million 1960
kilo k 10001 10^3 1000 Thousand 1795
hecto h 10002⁄3 10^2 100 Hundred 1795
deca da 10001⁄3 10^1 10 Ten 1795
10000 10^0 1 One
deci d 1000−1⁄3 10^−1 0.1 Tenth 1795
centi c 1000−2⁄3 10^−2 0.01 Hundredth 1795
milli m 1000−1 10^−3 0.001 Thousandth 1795
micro µ 1000−2 10^−6 0.000001 Millionth 1960[2]
nano n 1000−3 10^−9 0.000000001 Billionth Milliardth 1960
pico p 1000−4 10^−12 0.000000000001 Trillionth Billionth 1960
femto f 1000−5 10^−15 0.000000000000001 Quadrillionth Billiardth 1964
atto a 1000−6 10^−18 0.000000000000000001 Quintillionth Trillionth 1964
zepto z 1000−7 10^−21 0.000000000000000000001 Sextillionth Trilliardth 1991
yocto y 1000−8 10^−24 0.000000000000000000000001 Septillionth Quadrillionth
En el Libro de Shushu de Xu Yue de la dinastía Han del Este, los números chinos que indican la cantidad están completamente registrados, de pequeños a grandes, son uno, diez, cien, mil, billones, mil millones (10 8), Zhao (10 · 12), Beijing (10 · 16), Gai (10 · 20), Zi (10 · 24), Rang (10 · 28), Gou (10 · 32), Jian (10 · 36), Zheng (10 · 40) y set (10 · 44). Desde entonces, con la introducción del budismo y los intercambios culturales, se agregaron polos (10 · 48), arena del Ganges (10 · 52) y monjes (10 · 56).), Nayuta (10 · 60), increíble (10 · 64), inconmensurable (10 · 68), números grandes (10 · 72), etc., entre los cuales diez mil y menos son decimales, y diez mil y más son diez mil.
Cita de referencia:
https://baike.baidu.com/item/byte
https://blog.csdn.net/weixin_34082177/article/details/86135393
http://bbs.gongkong.com/d/201504/613475_1. Shtml
https://blog.csdn.net/guosir_/article/details/78346472
https://blog.csdn.net/hammer_xie/article/details/52301243
https://www.crifan.com/big_endian_big_endian_and_small_end_little_endian_detailed/
https: / zhidao.baidu.com/question/1308113215598827339.html
https://www.cnblogs.com/ricksteves/p/9899893.html