Directorio de artículos
- Introducción
- 1. Principio del clúster de equilibrio de carga
- 2.servidor virtual LVS
- 3. Cree un clúster de equilibrio de carga LVS
Introducción
El nombre cluster (o cluster) proviene de la palabra inglesa "Cluwster", que significa un grupo o un montón, y cuando se usa en el campo de servidor, significa una colección de una gran cantidad de servidores para distinguirlo de un solo servidor. Dependiendo del entorno real de la empresa, las funciones proporcionadas por el clúster también son diferentes y los detalles técnicos utilizados pueden tener sus propios méritos. Aquí, haremos una breve introducción a la estructura del clúster, el modo de trabajo, la aplicación virtual LVS y el almacenamiento compartido NFS.
1. Principio del clúster de equilibrio de carga
1.1 Descripción general de las aplicaciones de clúster empresarial
El significado de los racimos
- Clúster, clúster, clúster
- Consta de varios hosts, pero solo aparece externamente como un todo
problema
- En las aplicaciones de Internet, dado que los sitios tienen requisitos cada vez más altos de rendimiento del hardware, velocidad de respuesta, estabilidad del servicio, confiabilidad de los datos, etc., un solo servidor no puede hacerlo.
Solución
- Utilice miniordenadores y mainframes costosos
- Utilice servidores normales para crear clústeres de servicios
Introducción complementaria:
- El SLB en Alibaba Cloud es un programador de equilibrio de carga típico y ECS es un host en la nube (máquina virtual);
- SLB programa ECS y varios ECS forman un grupo de recursos, que forma la base de la computación en la nube.
1.2 Clasificación de agrupaciones empresariales
-
No importa qué tipo de clúster, incluye al menos dos servidores de nodo
-
Clasificación según la diferencia objetivo del
clúster Clúster de equilibrio de carga Clúster de
alta disponibilidad Clúster de
computación de alto rendimiento
1.2.1 Clúster de equilibrio de carga
- Mejore la capacidad de respuesta del sistema de aplicaciones, procese tantas solicitudes de acceso como sea posible, reduzca la latencia como objetivo y obtenga una alta concurrencia y un rendimiento general de alta carga (LB). Por ejemplo, el sondeo de DNS, la conmutación de la capa de aplicación, el proxy inverso, etc. se pueden utilizar como clústeres de equilibrio de carga.
- La distribución de carga de LB se basa en el algoritmo de descarga del nodo maestro para compartir las solicitudes de acceso del cliente a múltiples nodos de servidor, aliviando así la presión de carga de todo el sistema.
1.2.2 Clúster de alta disponibilidad
- El objetivo es mejorar la confiabilidad del sistema de aplicación, reducir el tiempo de interrupción tanto como sea posible, asegurar la continuidad del servicio y lograr el efecto de tolerancia a fallas de alta disponibilidad (HA). Por ejemplo, la conmutación por error, la copia de seguridad en caliente de sistema dual y la copia de seguridad en caliente de varios sistemas son tecnologías de clúster de alta disponibilidad;
- El modo de trabajo de HA incluye modos dúplex y maestro-esclavo. Dúplex significa trabajar al mismo tiempo; maestro-esclavo significa que solo el nodo maestro está en línea, pero cuando ocurre una falla, el nodo esclavo puede cambiar automáticamente al nodo maestro.
1.2.3 Clúster de computadoras de alto rendimiento
-
El objetivo es mejorar la velocidad de computación de la CPU del sistema de aplicación, expandir los recursos de hardware y las capacidades de análisis, y obtener las capacidades de computación de alto rendimiento (HPC) equivalentes a las supercomputadoras a gran escala. Por ejemplo, la computación en la nube y la computación en red también pueden considerarse un tipo de computación de alto rendimiento;
-
El alto rendimiento se basa en la "computación distribuida" y la "computación paralela". La CPU, la memoria y otros recursos de varios servidores se integran a través de hardware y software dedicados para lograr capacidades de computación que solo tienen las grandes computadoras y las supercomputadoras.
1.3 Estructura en capas de equilibrio de carga
1.3.1 Resumen
- En un clúster de equilibrio de carga típico, hay tres niveles de componentes. Hay al menos un programador de carga en el front-end para responder a las solicitudes de acceso de carga y distribución de los clientes; el back-end está compuesto por una gran cantidad de servidores reales para formar un grupo de servidores para proporcionar servicios de aplicaciones reales. La escalabilidad de todo El clúster se logra agregando o eliminando nodos de servidor El proceso es transparente para el cliente, para mantener la consistencia del servicio, todos los nodos utilizan dispositivos de almacenamiento compartido.
1.3.2 Arquitectura de equilibrio de carga
- La primera capa, programador de carga (Load Balancer o Director)
- La segunda capa, el grupo de servidores (grupo de servidores)
- La tercera capa, almacenamiento compartido (almacenamiento compartido)
1.3.3 Introducción detallada de la arquitectura de equilibrio de carga
- Programador de carga: es la única entrada para acceder a todo el sistema del clúster. Utiliza la dirección VIP (IP virtual) común a todos los servidores, también conocida como dirección IP del clúster. Por lo general, se configuran dos programadores, los programadores principal y de respaldo para lograr una copia de seguridad en caliente. Cuando el programador principal falla, se reemplaza sin problemas al programador de respaldo para garantizar una alta disponibilidad;
- Grupo de servidores: el clúster proporciona servicios de aplicaciones y está a cargo del grupo de servidores. Cada nodo del clúster tiene una dirección RIP (IP real) independiente y solo procesa las solicitudes del cliente distribuidas por el programador; cuando falla un nodo, el programador de carga el mecanismo tolerante a fallas los aislará y esperará a que se elimine el error antes de volver a ingresar al grupo de servidores;
- Almacenamiento compartido: brinde servicios de acceso a archivos estables y consistentes para todos los nodos en el grupo de servidores para garantizar la unidad de todo el clúster.
1.4 Modo de trabajo de equilibrio de carga
- En cuanto a la tecnología de programación de carga del clúster, se puede distribuir en base a IP, puerto, contenido, etc., de los cuales la eficiencia de la programación de carga basada en IP es la más alta. En el modo de equilibrio de carga basado en IP, hay tres modos de trabajo comunes: traducción de direcciones, túnel IP y enrutamiento directo.
1.4.1 Traducción de direcciones de red
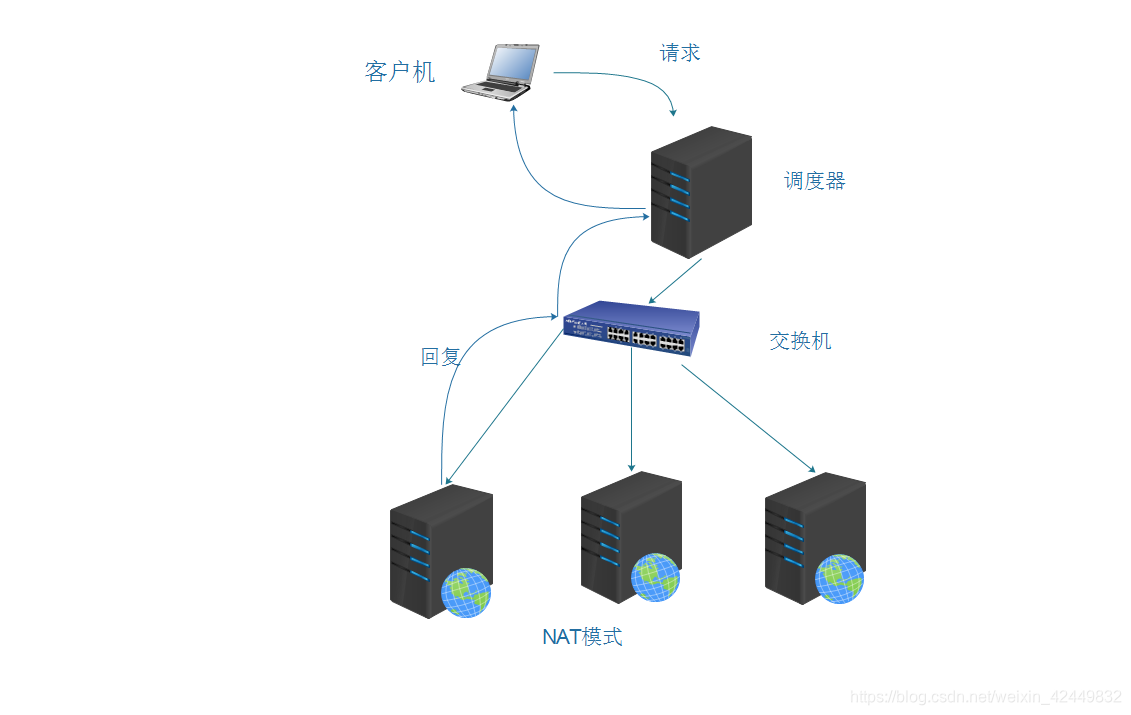
- Conocido como modo NAT, es similar a la estructura de red privada de un firewall. El programador de carga actúa como la puerta de enlace de todos los nodos del servidor, es decir, como la entrada de acceso del cliente, y también la salida de acceso de cada nodo en respuesta al cliente;
- El nodo del servidor usa una dirección IP privada y está ubicado en la misma red física que el programador de carga, y la seguridad es mejor que los otros dos métodos.
1.4.2 Túnel IP
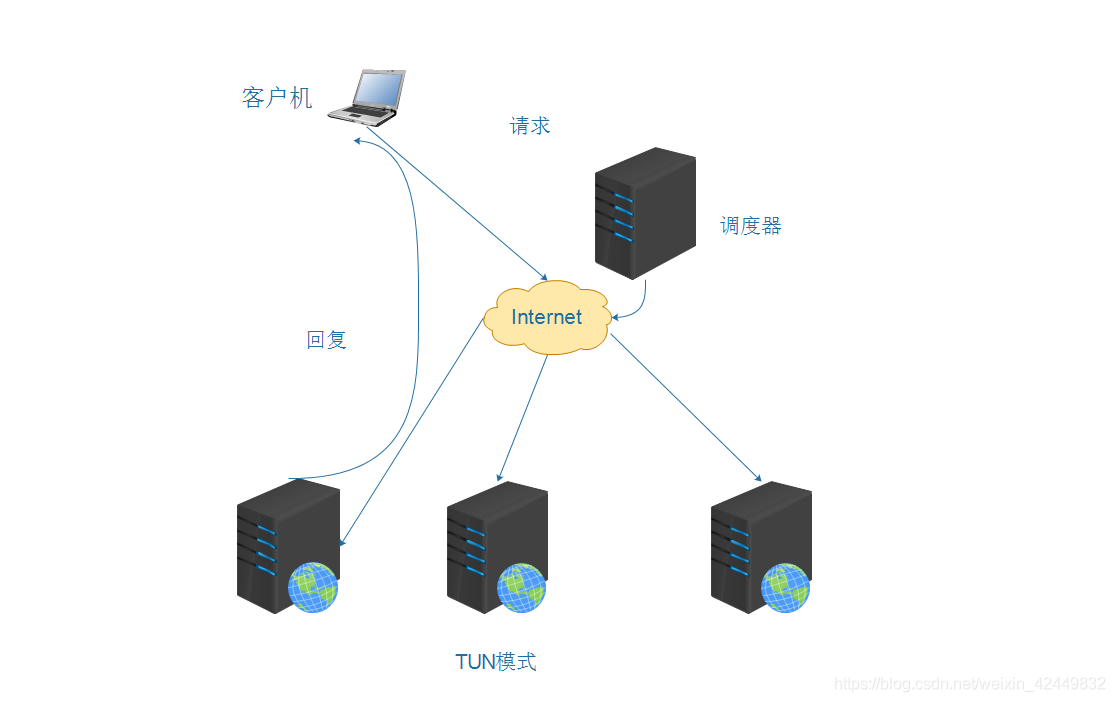
- Denominado modo TUN, adopta una estructura de red abierta. El programador de carga solo sirve como portal de acceso del cliente. Cada nodo responde directamente al cliente a través de su propia conexión a Internet sin pasar por el programador de carga;
- Los nodos de servidor están dispersos en diferentes ubicaciones en Internet, tienen direcciones IP públicas independientes y se comunican con el programador de carga a través de un túnel IP dedicado.
1.4.3 Enrutamiento directo
- Conocido como modo DR, adopta una estructura de red semiabierta, que es similar a la estructura del modo TUN, pero los nodos no están dispersos por todas partes, sino que están ubicados en la misma red física que el programador;
- El programador de carga está conectado a cada servidor de nodo a través de la red local y no es necesario establecer un túnel IP dedicado.
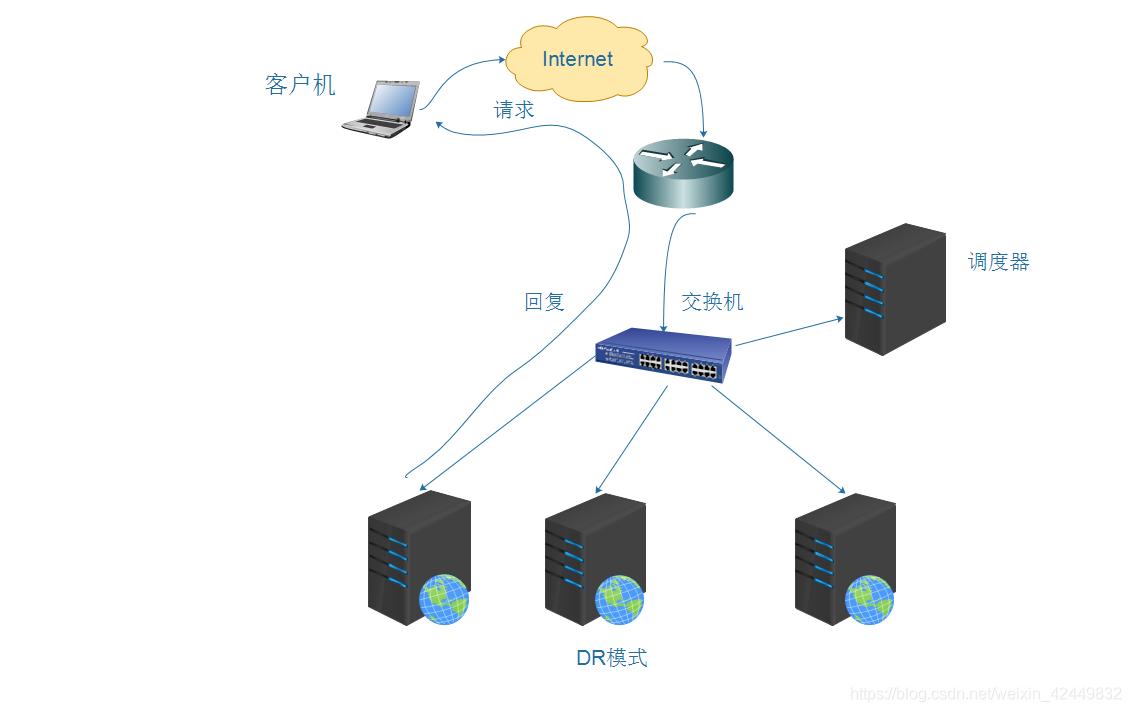
La diferencia entre el modo DR y TUN: - El mismo punto: todos los nodos web responden directamente al cliente;
- Diferente: el modo TUN tiene una prueba pública independiente, pero el DR no; los nodos web TUN se comunican con el túnel IP del planificador, mientras que los nodos web DR se comunican con la red de área local; los nodos web del modo TUN responden directamente y los nodos web del modo DR deben hacerlo. responder a través de un enrutador.
1.5 La diferencia entre los tres modos de trabajo
| Diferencia en el modo de trabajo. | Modo NAT | Modo TUN | Modo DR |
|---|---|---|---|
| Servidor real (servidor de nodo) | |||
| Número de servidor (número de nodos) | Bajo 10-20 | Alto 100 | Alto 100 |
| Puerta de enlace real | Programador de carga | Enrutador propio | Enrutador gratuito |
| dirección IP | Red pública + red privada | red pública | Red privada |
| ventaja | Alta seguridad | Datos cifrados del entorno Wan | Máximo rendimiento |
| Desventaja | Baja eficiencia y alta presión. | Necesita soporte de túnel | No se puede extender la LAN |
2.servidor virtual LVS
2.1 Resumen
- Linux Virtual Server es una solución de equilibrio de carga para el kernel de Linux, creada en mayo de 1998 por el Dr. Wensong Zhang de mi país. LVS es en realidad equivalente a las aplicaciones virtualizadas basadas en direcciones IP y propone una solución eficiente para el equilibrio de carga basada en direcciones IP y distribución de solicitudes de contenido.
- LVS ahora se ha convertido en parte del kernel de Linux, compilado como un módulo ip_vs por defecto, y se puede llamar automáticamente cuando sea necesario.
[root@localhost~]# modprobe ip_vs '//加载ip_vs模块,确认内核对LVS的支持'
[root@localhost~]# cat /proc/net/ip_vs '//查看ip_vs版本信息'
2.2 Algoritmo de programación de carga LVS
2.2.1 Round Robin
- Las solicitudes de acceso recibidas se asignan a cada nodo (servidor real) en el clúster en orden, y cada servidor se trata por igual, independientemente del número real de conexiones del servidor y la carga del sistema.
2.2.2 Round Robin ponderado
- De acuerdo con la capacidad de procesamiento del servidor real, las solicitudes de acceso recibidas se asignan a su vez. El programador puede consultar automáticamente el estado de carga de cada nodo y ajustar dinámicamente su peso para garantizar que el servidor con una fuerte capacidad de procesamiento soporta más tráfico de acceso.
2.2.3 Conexiones mínimas
- La asignación se realiza según el número de conexiones establecidas por el servidor real, y la solicitud de acceso recibida se asigna preferentemente al nodo con el menor número de conexiones. Si todos los nodos del servidor tienen un rendimiento similar, este método puede equilibrar mejor la carga.
2.2.4 Conexiones menos ponderadas
- En el caso de grandes diferencias en el rendimiento de los nodos del servidor, los pesos se pueden ajustar automáticamente para los servidores reales, y los nodos con pesos más altos soportarán una mayor proporción de la carga de conexión activa.
2.3 Usar la herramienta de administración ipvsadm
Creación y gestión de clústeres LVS
- Crea un servidor virtual
- Agregar, eliminar nodos de servidor
- Ver el estado del clúster y del nodo
- Guardar estrategia de distribución de carga
3. Cree un clúster de equilibrio de carga LVS
3.1 Entorno del caso
- Como puerta de enlace del grupo de servidores web, el programador LVS tiene dos tarjetas de red LVS (VM1 y VM2), conectadas respectivamente a las redes internas y externas, utilizando el algoritmo de programación round-robin (rr)
Entorno de modo de traducción de direcciones de clúster de equilibrio de carga LVS (LVS-NAT)
(1) Un servidor de despacho
- Dirección IP: 192.168.70.10 (intranet VM1)
- Dirección IP: 192.168.80.10 (red externa VM2)
(2) Dos servidores web
- Dirección IP: 192.168.70.11 (SERVIDOR AA)
- Dirección IP: 192.168.70.12 (SERVIDOR AB)
Nota: La puerta de enlace del servidor web debe apuntar a la tarjeta de red interna del despachador
(3) servidor compartido NFS
- Dirección IP: 192.168.70.13
(4) Un cliente, tomando win7 como ejemplo, para pruebas y verificación
- Dirección IP: 192.168.70.14 (intranet)
- Dirección IP: 192.168.80.14 (red externa)
Nota: Es necesario asegurarse de que el mismo segmento de red pueda comunicarse entre sí.
3.2 Propósito experimental
- El cliente win10 accede al sitio web 192.168.70.10, a través de la traducción de direcciones nat, acceso de sondeo a los hosts Apache1 y Apache2;
- Construya el servicio de almacenamiento de archivos de red nfs.
3.3 Pasos de implementación
- Cargue el módulo ip_vs, instale la herramienta ipvsadm
- Active el enrutamiento y el reenvío;
- Cree un nuevo servidor virtual LVS y agregue un servidor de nodo;
- Configure el servidor de nodo:
establezca un sitio web de prueba,
monte el almacenamiento compartido NFS,
establezca una página web de prueba - Guarde las reglas y pruebe
3.4 Pasos del proyecto
3.4.1 Apague el firewall
iptables -F
setenforce 0
systemctl stop firewalld
3.4.2 Configurar el servidor de almacenamiento NFS
[root@nfs ~]# rpm -qa | grep rpcbind //默认虚拟机已安装rpcbind模块
rpcbind-0.2.0-42.el7.x86_64
[root@nfs ~]# yum -y install nfs-utils //确认是否安装nfs-utils软件包
已加载插件:fastestmirror, langpacks
base | 3.6 kB 00:00
Loading mirror speeds from cached hostfile
* base:
软件包 1:nfs-utils-1.3.0-0.48.el7.x86_64 已安装并且是最新版本
无须任何处理
[root@nfs ~]# mkdir /opt/web1
[root@nfs ~]# mkdir /opt/web2
[root@nfs ~]# echo "<h1>this is web1.</h1>" > /opt/web1/index.html
[root@nfs ~]# echo "<h1>this is web2.</h1>" > /opt/web2/index.html
[root@nfs ~]# vi /etc/exports
/opt/web1 192.168.70.11/32 (ro)
/opt/web2 192.168.70.12/32 (ro)
[root@nfs ~]# systemctl restart nfs
[root@nfs ~]# systemctl restart rpcbind
[root@nfs ~]# showmount -e
Export list for nfs:
opt/web2 (everyone)
/opt/web1 (everyone)
3.4.3 Configurar el servidor del sitio web
yum -y install httpd
[root@web1 ~]# showmount -e 192.168.70.13
Export list for 192.168.70.13:
opt/web2 (everyone)
/opt/web1 (everyone)
[root@web1 ~]# mount 192.168.70.13:/opt/web1 /var/www/html
[root@web1 ~]# systemctl restart httpd
[root@web1 ~]# netstat -anpt | grep httpd
tcp6 0 0 :::80 :::* LISTEN 55954/httpd
[root@web2 ~]# mount 192.168.70.13:/opt/web2 /var/www/html
[root@web2 ~]# systemctl restart httpd
[root@web2 ~]# netstat -anpt | grep httpd
tcp6 0 0 :::80 :::* LISTEN 54695/httpd
3.4.4 Configurar en el servidor de despacho LVS
[root@lvs ~]# vi /etc/sysctl.conf
...
net.ipv4.ip_forward=1
[root@lvs ~]# sysctl -p '//开启路由地址转换'
net.ipv4.ip_forward=1
[root@lvs ~]# modprobe ip_vs '//加载ip_vs模块'
[root@lvs ~]# cat /proc/net/ip_vs
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
[root@lvs ~]# yum -y install ipvsadm
[root@lvs ~]# vi nat.sh
#!/bin/bash
ipvsadm -C
ipvsadm -A -t 192.168.80.10:80 -s rr
ipvsadm -a -t 192.168.80.10:80 -r 192.168.70.11:80 -m
ipvsadm -a -t 192.168.80.10:80 -r 192.168.70.12:80 -m
ipvsadm -Ln
//
-C:'表示清除缓存'
-A:'添加地址为192.168.80.10:80的虚拟地址,指定调度算法为轮询'
-a: '指定真实服务器,指定传输模式为NAT'
-t:'访问的入口地址,VIP'
rr:'表示轮询'
-m:'指的是NAT模式'
Ejecute el script para iniciar el servicio.
[root@lvs ~]# sh nat.sh
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.80.10:80 rr
-> 192.168.70.11:80 Masq 1 0 0
-> 192.168.70.12:80 Masq 1 0 0
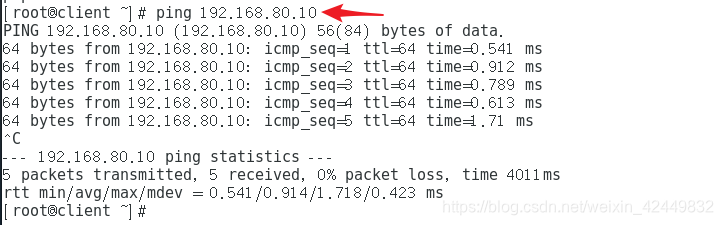
- Confirme si el programador puede acceder a dos páginas web

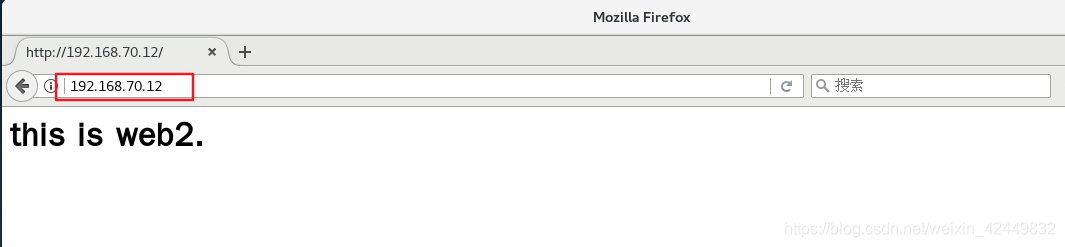
3.4.5 Resultado de la verificación
- Visita en navegador
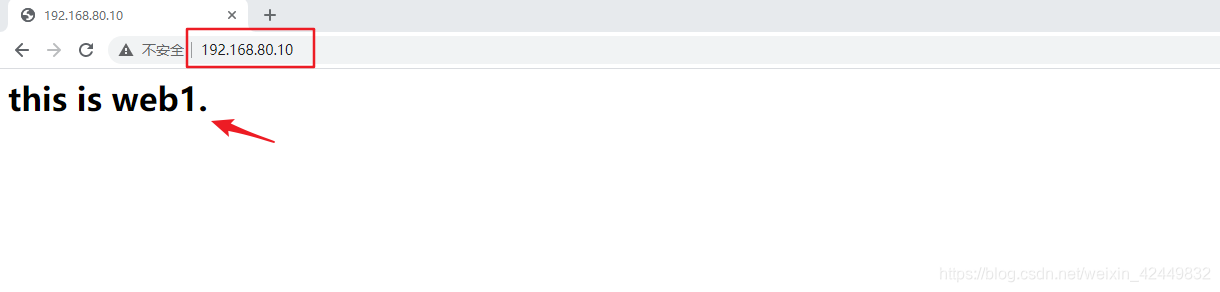
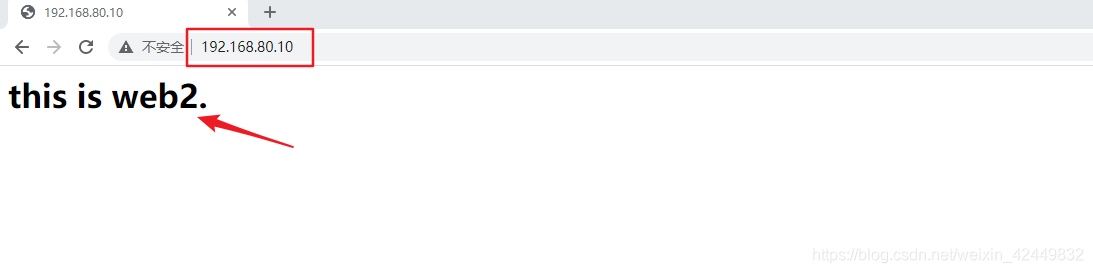
- Ver detalles de programación reales del clúster
[root@lvs ~]# ipvsadm -lnc '//查看真实调度明细'
IPVS connection entries
pro expire state source virtual destination
TCP 01:20 FIN_WAIT 192.168.80.1:51398 192.168.80.10:80 192.168.70.11:80
TCP 00:44 TIME_WAIT 192.168.80.1:51378 192.168.80.10:80 192.168.70.12:80
TCP 00:29 TIME_WAIT 192.168.80.1:51371 192.168.80.10:80 192.168.70.11:80
TCP 00:17 TIME_WAIT 192.168.80.1:51356 192.168.80.10:80 192.168.70.12:80
TCP 11:39 ESTABLISHED 192.168.80.1:51301 192.168.80.10:80 192.168.70.11:80