Si cree que el artículo está bien escrito y desea obtener los datos del artículo del blog, preste atención a la cuenta oficial: [Nota del Sr. Z], se han preparado más de 50 libros electrónicos de Python y más de 200G de materiales de video de alta calidad. Usted. Las palabras clave de respuesta entre bastidores: 1024 se pueden obtener; agregue el autor [WeChat personal], puede comunicarse directamente con el autor,
La tecnología de reconocimiento de texto OCR ahora está bastante madura, no importa que su precisión o velocidad de reconocimiento pueda satisfacer nuestras necesidades diarias; hoy les presentaré un paquete de Python, la función principal del paquete es para el reconocimiento de OCR, el nombre del paquete es Pyteeseract, con con la ayuda de algunas líneas de código en este paquete, puede identificar rápidamente una imagen de texto

El paquete Pytesseract se obtiene mediante la herramienta de código abierto Tesseract, desarrollada por Hewlett Packard Lab, e implementada como código abierto en 2005; desde 2006, ha sido desarrollado y mantenido conjuntamente por Google y algunos colaboradores destacados de código abierto.
Tesseract ha madurado gradualmente después de la versión 3.x, admitiendo múltiples formatos de imagen y agregando gradualmente reconocimiento de texto multilingüe; pero la versión Tesseract 3.x todavía se basa en algoritmos tradicionales de visión por computadora y se ha beneficiado de la rápida iteración de Deep Learning en el pasado. Tanto la precisión como la velocidad son mejores que los algoritmos tradicionales, después de la versión 4.0, Tesseract ha agregado el módulo Deep Learning, que se basa en Recognition LSTM, y LSTM puede clasificarse como RNN (red neuronal convolucional cíclica);
El experimento de este artículo se basa en la versión Tesseract3.05. Por último, la precisión del reconocimiento del idioma chino es ligeramente menor. Puede deberse a que no se utiliza 4.0+. Más tarde supe que existen 4.0+ o incluso 5.0+ ( pero no demasiado estable) y se basan en el módulo de aprendizaje profundo, pero no quiero cambiarlo porque soy demasiado vago ,,,
Primero explique el entorno experimental:
-
sistema operativo: Win10;
-
Python 3.8;
-
pyteeseract 0.3.8;
-
Tesseract 3.05 ;
instalación de pyteeseract
1. Instale la herramienta tesseract
En comparación con otros paquetes, los pasos de instalación de pyteeseract serán un poco más engorrosos, porque la función de reconocimiento de pyteeseract se basa en la herramienta de código abierto tesseract, por lo que el primer paso es instalar tesseract, el enlace de descarga del paquete de instalación:
https://digi.bib.uni-mannheim.de/tesseract/
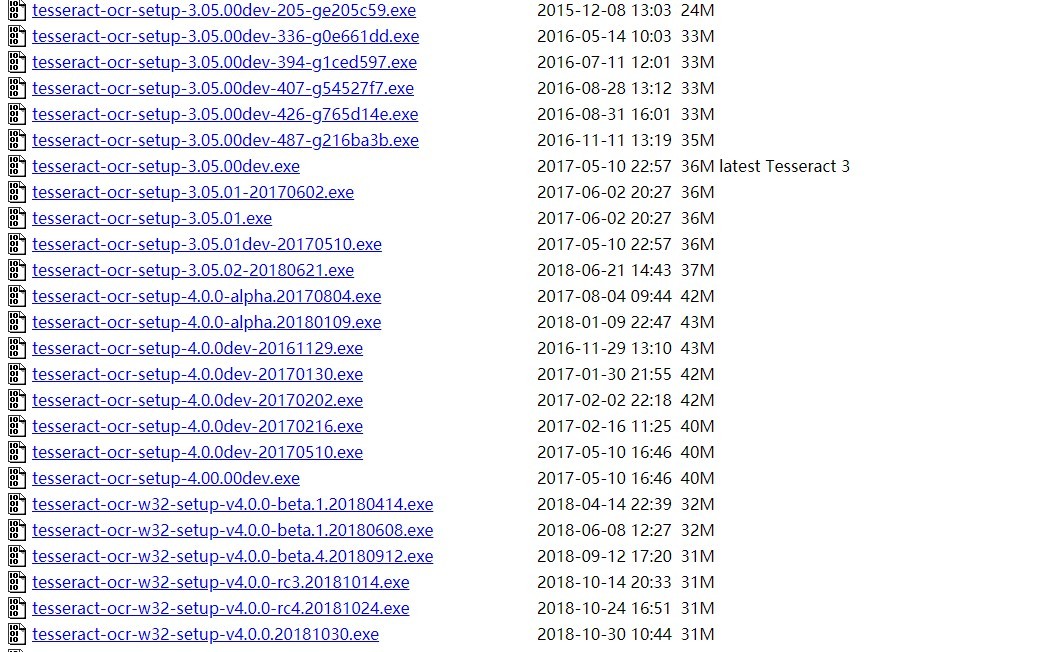
Disponible en versiones 3.0+, 4.0+ y 5.0+, instale después de descargar (el método de instalación es una instalación de tipo tonto)
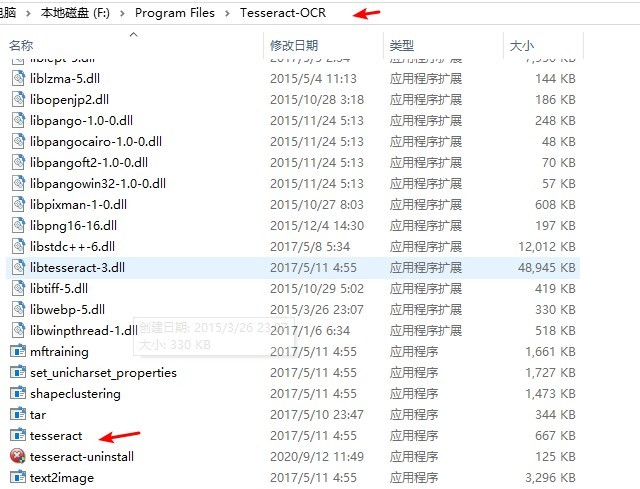
Una vez que tesseract se haya instalado correctamente, debe agregar la ruta del archivo donde se almacena tesseract.exe a la variable de entorno. Como se muestra en la figura siguiente, la carpeta donde se almacena mi tesseract.exe es F: / Program Files / Tesseract-OCR y agregue la variable de entorno;
2, pip instalar pytesseract
En la línea de comando, use la herramienta pip para descargar el paquete pytesseract
pip install pyteeseract
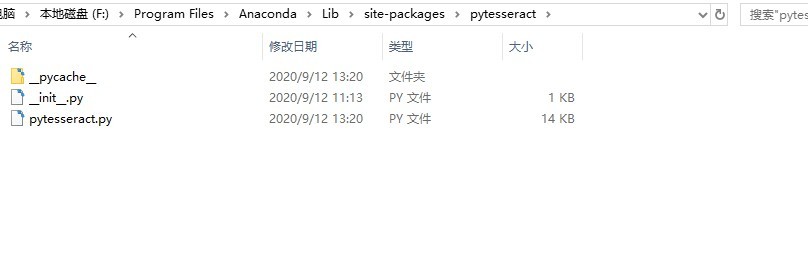
3. Modifique el script pytesseract.py
Sobre la base del paso 2, busque la ruta de instalación de pytesseract. Si Python se instala a través de Anaconda, la ruta de instalación generalmente se encuentra en la carpeta Anaconda / Lib / site-packages; después de encontrarla, busque pytesseract.py en la carpeta pytesseract Script archivo,
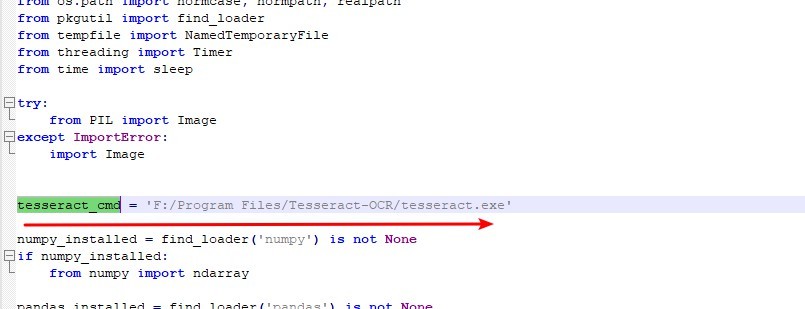
Después de encontrarlo, abra pyresseract.py con el Bloc de notas, ubique tesseract_cmd a través de la función de búsqueda rápida ctrl + f y modifique la siguiente información de ruta de archivo (reemplácela con la ruta de instalación de tesseract.exe mencionada anteriormente);
2. Uso de pytesseract
Usar el paquete es relativamente simple, puede obtener algunas líneas de código, el siguiente código es para identificar un carácter en la imagen e imprimirlo en una cadena, seleccione los idiomas de reconocimiento Inglés (Cambiar los parámetros lang = 'eng' pueden ser )
import pytesseract
import cv2
img_path = "G:/Coding/One_hundred_days/Data/orc_image2.jpg"
# 下面一行代码很重要
tessdata_dir_config = '--tessdata-dir "F://Program Files//Tesseract-OCR//tessdata"'
im = cv2.imread(img_path)
img = cv2.cvtColor(im,cv2.COLOR_BGR2RGB)
text = pytesseract.image_to_string(img,lang= 'eng',config= tessdata_dir_config,)
print(text)
Vista previa del efecto, antes del reconocimiento

Después del reconocimiento
pytesseract admite la imagen leída por OpenCV y PIL como entrada, pero el formato de imagen debe ser el modo RGB, por lo que después de que OpenCV lee, se agrega una línea de código para convertir el modo BGR de la imagen a RGB
Otra cosa a tener en cuenta es que la siguiente línea de código en el ejemplo anterior no se puede eliminar (se usa para configurar el parámetro de configuración en la función image_to_string () más adelante)
tessdata_dir_config = '--tessdata-dir "F://Program Files//Tesseract-OCR//tessdata"'
De lo contrario, será el siguiente error, ubicación de la ruta de archivos tessdata fracasó ,
Error al cargar el idioma 'eng' ¡Tesseract no pudo cargar ningún idioma! No se pudo inicializar tesseract. ')
La ruta del archivo tessdata almacena el archivo del paquete de idioma, que se usa para identificar diferentes idiomas en la imagen y se establece modificando el parámetro lang; pero lo que necesita saber es que el idioma predeterminado de la herramienta tesseract es eng (inglés ) al principio, si necesita usar tesseract para identificar diferentes idiomas, debe descargar los archivos del paquete de idioma correspondiente e instalarlos en la carpeta tessdata.
Por ejemplo, utilicé inglés en el caso anterior. Aquí quiero reconocer los caracteres chinos en la imagen. Necesito descargar el paquete de idioma chino para testdata. La dirección de descarga de cada paquete de idioma es https://github.com/ tesseract-ocr / tessdata
Luego configure el parámetro lang en image_to_string () en el código a chi_sim
Vista previa del efecto, antes del reconocimiento

Después del reconocimiento, el efecto de reconocimiento no es muy bueno para los chinos, pero adivina el motivo de la versión:

pyteeseract otro uso
1. Además de lo anterior, el reconocimiento de contenido en la imagen se puede convertir directamente en una cadena, y también se puede convertir directamente en un archivo pdf para exportar
# Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f:
f.write(pdf) # pdf type is bytes by default
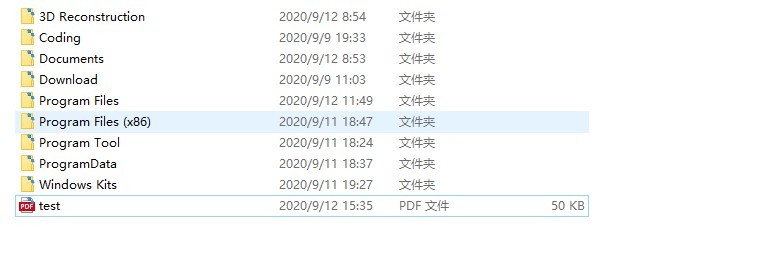
2. Se estima que se reconoce la información del cuadro de cada personaje y el rango de resolución de la posición en la imagen:
print(pytesseract.image_to_boxes(img_path,lang = 'chi_sim',config= tessdata_dir_config))
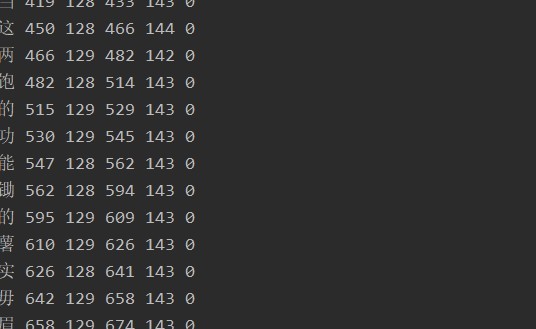
3. Aún quedan muchos usos del pyteeseract que aún no se han introducido. Quienes estén interesados pueden ir a la web oficial para presentarlos. El enlace es el siguiente:
https://pypi.org/project/pytesseract/