Obtenga una comprensión profunda del sistema de archivos de Linux (explicación detallada del inodo y el bloque, 5 minutos para comprender el enlace duro y el enlace suave)
Cuando se trata de varias fallas en el sistema Linux, los síntomas de la falla son los más fáciles de encontrar, y la causa de esta falla es la clave para la solución final del problema.
Familiarizarse con los archivos de registro comunes en el sistema Linux, comprender el análisis y las soluciones de fallas generales, ayudará al administrador a localizar rápidamente el punto de falla, "recetar el medicamento correcto" y resolver varios problemas del sistema a tiempo.
Debido a la incertidumbre del fenómeno de falla, es mejor hacer una copia de seguridad antes de realizar algunas operaciones de falla simuladas.
Uno, inodo y bloque
En el nuevo sistema operativo, además del contenido real, los archivos generalmente contienen muchos atributos, como los permisos de archivo del sistema operativo Linux (rwx, r significa legible y accesible; w significa modificable y modificable; x significa ejecutable ) Y atributos de archivo (propietario, grupo, parámetros de tiempo, etc.)
El sistema de archivos generalmente almacena estas dos partes en inodo y bloque respectivamente
1. Información general
Los archivos se almacenan en el disco duro, la unidad de almacenamiento más pequeña del disco duro es "sector", cada sector almacena 512 bytes
1.1 bloque
Generalmente, ocho sectores consecutivos forman un "bloque". Un bloque tiene un tamaño de 4K y es la unidad más pequeña de acceso a archivos
Cuando el sistema operativo lee el disco duro, no lee un sector un sector a la vez, sino que lee varios sectores a la vez, es decir, un bloque a la vez.
1.2 Meta información
Los datos del archivo incluyen datos reales y metainformación (similar a los atributos del archivo)
La metainformación es información sobre información, que se utiliza para describir la estructura, la semántica, el propósito y el uso de la información, como el creador, la fecha de creación, el tamaño del archivo y los permisos del archivo.
1.3 inodo
Los datos del archivo se almacenan en "bloques", también necesita encontrar un lugar para almacenar la metainformación del archivo
Esta área se llama inodo, la traducción al chino es "nodo índice". Yo-nodo
En resumen, un archivo debe ocupar un inodo y al menos un bloque
Contenido de la tienda
ubicación de almacenamiento
Meta informacion
inodo
datos
bloquear
2. Contenido de inodo
Inode contiene mucha metainformación del archivo, pero no incluye el nombre del archivo
Hay dos formas de ver la información del inodo correspondiente al nombre del archivo
ls -i nombre de archivo (solo se muestran el nombre y el tamaño del archivo)
Los archivos del sistema Linux tienen tres atributos de tiempo principales (vea la imagen de arriba)
Accedido recientemente (Acceso): la última vez que se accedió al archivo o directorio
Recientemente cambiado (Modificar): la última vez que se modificó un archivo o directorio (contenido)
Cambios recientes (cambio): la última vez que se cambió un archivo o directorio (atributo)
3. La estructura del archivo de directorio
Como se mencionó anteriormente, indo no contiene el nombre del archivo; el nombre del archivo se almacena en el directorio, y en el sistema Linx, todo es un archivo, por lo que el directorio también es una especie de archivo.
La estructura del archivo del directorio es como se muestra a continuación
Nombre de archivo 1
inodo número 1
Nombre de archivo 2
inodo número 2
...
...
Cada inodo tiene un número y el sistema operativo usa el número de inodo para identificar diferentes archivos
El sistema Linux no usa el nombre del archivo, pero usa el número de inodo para identificar el archivo
Para los usuarios, el nombre del archivo es solo un "alias" para una fácil identificación del número de inodo
El nombre de archivo y el número de inodo están en una relación correspondiente, cada número de inodo corresponde a un nombre de archivo
Número 4.inode
(Ejemplo) El usuario usa el nombre del archivo para abrir el archivo, pero habrá tres pasos en el sistema:
El sistema primero encontrará el número de inodo correspondiente al nombre del archivo
Luego obtenga la información de inodo a través del número de inodo para verificar si el usuario tiene permiso para acceder al archivo
Si es así, apuntará al bloque donde se encuentran los datos del archivo correspondiente según la información del inodo, leerá los datos y se los mostrará al usuario (si no, devolverá Permiso denegado, es decir, sin permiso)
Estructura después de la partición del disco duro
nombre del archivo
→
Elemento de directorio
/
Bloque de directorio
Meta informacion
→
inodo
/
bloque de tabla de inodo
datos
→
bloquear
/
bloque de área de datos
4. El tamaño del inodo
El inodo también consume espacio en el disco duro y el tamaño de cada inodo es generalmente de 128 bytes o 256 bytes.
Al formatear, el sistema dividirá automáticamente el disco duro en dos áreas
Uno es el área de datos, que almacena datos de archivos.
La otra es el área de inodo, que almacena la información contenida en el inodo
Normalmente, no es necesario prestar atención al tamaño de un solo inodo, sino al número total de inodos; el número total de inodos se da al formatear
Ejecute "df -i" para ver el número total de inodos correspondientes a cada partición del disco duro y el número de inodos utilizados
Dado que el número de inodo está separado del nombre del archivo, este mecanismo provoca los siguientes fenómenos únicos en el sistema Linux
Si el nombre del archivo contiene caracteres especiales, es posible que no se elimine normalmente. En este caso, debe eliminar el inodo directamente para eliminar el archivo.
Mover archivos o renombrar archivos solo cambiará el nombre del archivo y no afectará el número de inodo
Después de abrir un archivo, el sistema identificará el archivo por su número de inodo en lugar de considerar el nombre del archivo.
Después de que se modifiquen y guarden los datos del archivo, se generará un nuevo número de inodo
Bajo este mecanismo, el software se puede actualizar sin apagar y no necesita ser reiniciado, porque el sistema usa el número de inodo para identificar el archivo en ejecución en lugar del nombre del archivo . De esta manera, al actualizar (al igual que está ingresando El proceso de edición con vim editor), la nueva versión del archivo generará un nuevo inodo con el mismo nombre de archivo, sin afectar el archivo en ejecución.Cuando el software se ejecute nuevamente (wq), el nombre del archivo apuntará a La nueva versión del archivo y el número de inodo de la versión anterior del archivo se recuperan al mismo tiempo (actualice el número de inodo)
Dos, enlace duro y enlace suave
Hay dos tipos de archivos de enlace en Linux
Un archivo similar a la función de acceso directo de Windows, que se puede conectar rápidamente al archivo o directorio de destino. Esto se denomina enlace suave
La otra es generar el nombre del archivo a través del enlace de inodo del sistema de archivos en lugar de generar un nuevo archivo. Esto se denomina enlace duro
1. Enlace fijo
Generalmente, el nombre del archivo y el número de inodo están en una relación correspondiente, y cada número de inodo corresponde a un nombre de archivo
Sin embargo, el sistema Linux permite que varios nombres de archivo apunten al mismo número de inodo, lo que significa que se pueden usar diferentes nombres de archivo para acceder al mismo contenido.
El comando "ln" puede crear un vínculo físico, el formato del comando es:
ln 源文件 目标
Después de ejecutar este comando, el archivo de origen y el archivo de destino tienen el mismo número de inodo, y ambos apuntan a un inodo. El "número de enlaces" en la información del inodo aumentará en 1 en este momento.
Cuando un archivo tiene varios vínculos físicos y luego modifica el contenido del archivo, afectará a todos los nombres de archivo, pero eliminar un nombre de archivo no afectará a otros nombres de archivo, eliminar un nombre de archivo solo hará que el número de inodo "Número de enlaces" menos uno
Los enlaces físicos casi nunca se aplican en el entorno real y no se pueden crear enlaces físicos a directorios.
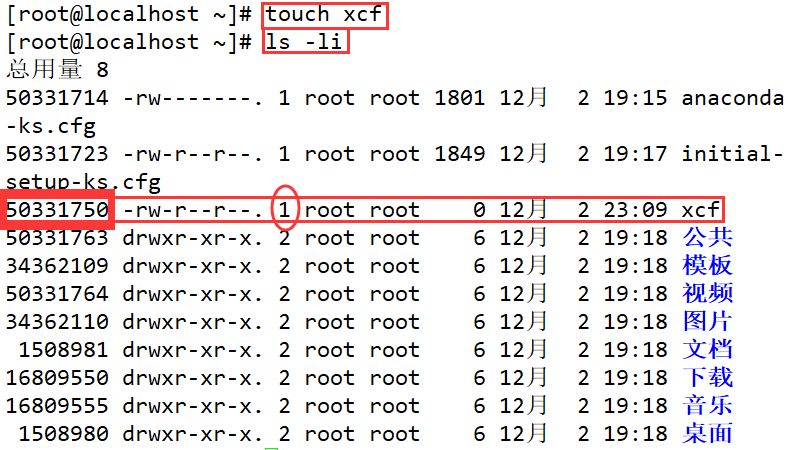
Ejemplo:
Cree un nuevo archivo, compruébelo, puede ver el número de inodo y el número de enlaces
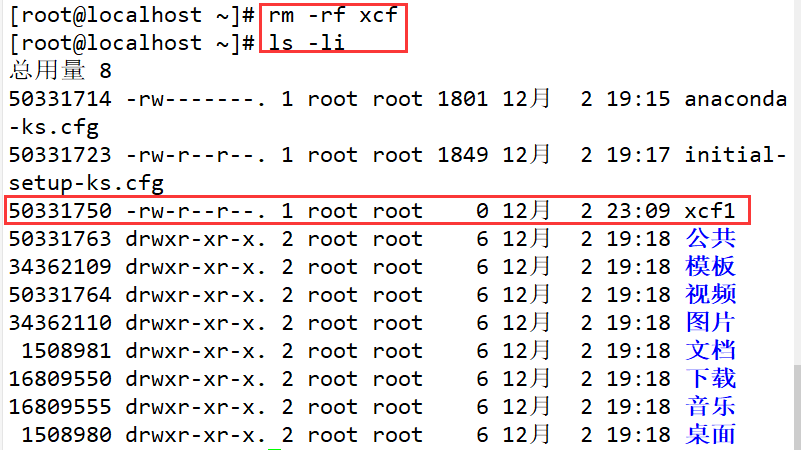
Ahora cree un enlace físico, puede ver que el número de inodo es el mismo y el número de enlaces aumenta en uno, se convierte en 2.
Eliminó el archivo de origen "xcf" y descubrió que los enlaces físicos no se vieron afectados, pero la cantidad de enlaces disminuyó en uno y volvió a cambiar a uno.
2. Enlace flexible
Un enlace suave es para crear un archivo separado, y este archivo permitirá que la lectura de datos apunte al nombre del archivo al que está conectado.
Por ejemplo: aunque los números de inodo del archivo A y del archivo B son diferentes, el contenido del archivo A es la ruta del archivo B. Al leer el archivo A, el sistema automáticamente dirigirá al visitante al archivo B. En este momento, el archivo A se llama archivo B "Enlace flexible" o "enlace simbólico"
Esto significa que el archivo A depende del archivo B y existe. Si se elimina el archivo B, el archivo A comenzará a informar errores. Esta es la mayor diferencia entre el enlace flexible y el enlace físico: el archivo A apunta al nombre del archivo B, no al inodo Número, el inodo "número de enlaces" del archivo B no cambiará en consecuencia
Formato para crear enlaces suaves:
ln -s 源文件或目录 目标文件或目录
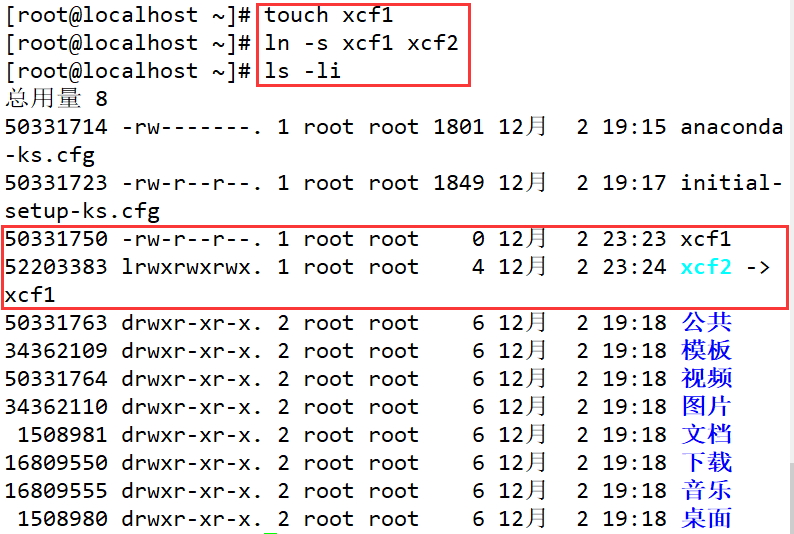
Ejemplo
Cree un nuevo archivo y cree un enlace suave para él. En este momento, se encuentra que el número de inodo ha cambiado y es obvio que el archivo de enlace suave es "xcf2-> xcf1" apuntando al archivo fuente
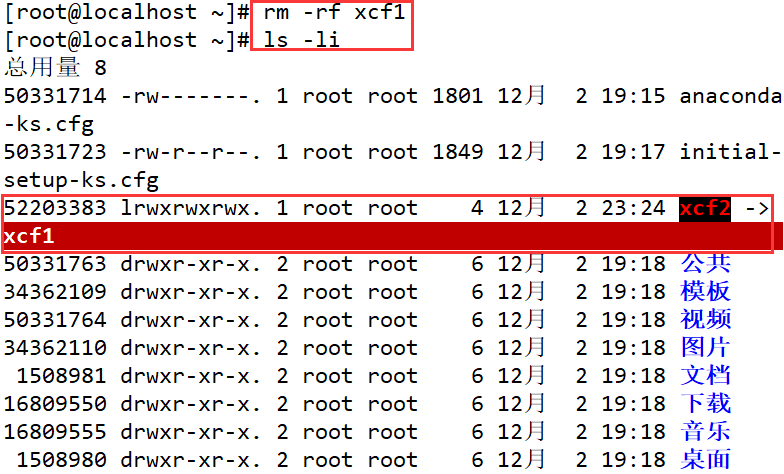
Elimine el archivo fuente xcf1 y descubra que xcf2 comienza a informar errores.
3. Resumen
/
Enlace suave
Enlace duro
inodo
Los archivos de origen de enlace suave y los archivos de enlace tienen diferentes números de inodo, que son dos archivos diferentes
El archivo de origen de enlace duro y el archivo de enlace comparten un número de inodo como un archivo con varios nombres de archivo, lo que indica que son el mismo archivo
Atributos de archivo
El enlace suave indica claramente que es un archivo vinculado
El enlace físico no está escrito y es esencialmente igual al archivo de origen
Establecimiento de sistemas de archivos cruzados
colocarse
no apoyo
Numero de enlaces
El número de enlaces suaves no aumentará y el tamaño del archivo será diferente (se puede entender como la relación entre el acceso directo y el archivo fuente correspondiente)
El enlace fijo muestra que el tamaño del archivo es el mismo que el del archivo de origen