Inscripción
Preguntas de la comunidad china de Elasticsearch:
No hay un campo incremental único ni un campo de tiempo incremental único para las tablas en MySQL. ¿Cómo usar logstash para realizar la importación de datos incrementales en tiempo real desde MySQL a es?
Tanto logstash como kafka_connector solo admiten la sincronización incremental de datos basada en una actualización de identificación o marca de tiempo autoincrementada.
Volviendo a la pregunta en sí: si no hay campos relacionados en la tabla de la biblioteca, ¿qué debo hacer?
Este artículo ofrece discusiones y soluciones relevantes.
1. Reconocimiento de Binlog
1.1 ¿Qué es binlog?
Binlog es un registro binario mantenido por la capa del servidor Mysql. Es un registro completamente diferente del registro de rehacer / deshacer en el motor InnoDB; se usa principalmente para registrar declaraciones SQL que actualizan o potencialmente actualizan datos mysql, y usan "transacciones" El formulario se guarda en el disco.
Las funciones principales son:
- 1) Replicación: Para lograr el objetivo de datos maestro-esclavo consistentes.
- 2) Recuperación de datos: recupere datos a través de la herramienta mysqlbinlog.
- 3) Copia de seguridad incremental.
1.2 Ali's Canal realiza una sincronización incremental de Mysql
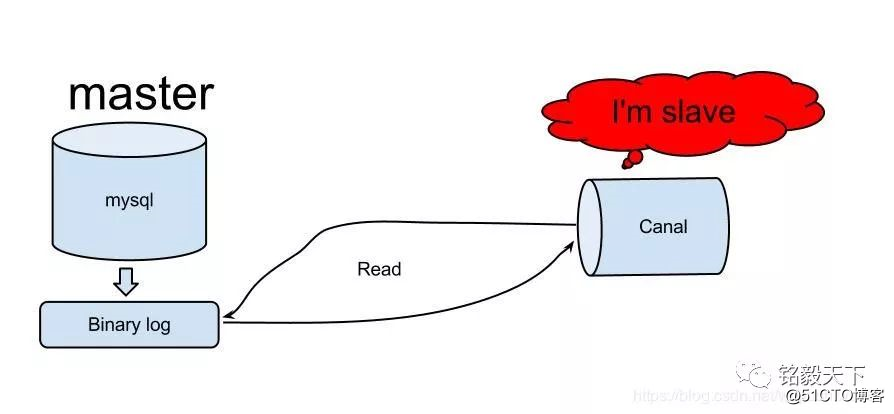
Una imagen vale más que mil palabras Canal es un middleware desarrollado en Java basado en el análisis de registro incremental de la base de datos, que proporciona suscripción y consumo de datos incrementales.
En la actualidad, canal admite principalmente el análisis de binlog de MySQL, y el cliente de canal se utiliza para procesar los datos relacionados después de que se completa el análisis. Propósito: suscripción y consumo de datos incrementales.
En resumen, el uso de binlog puede superar las limitaciones de logstash o kafka-connector sin una identificación autoincrementada o sin un campo de marca de tiempo, y lograr una sincronización incremental.
2. Método de sincronización basado en binlog
1) Proyecto de código abierto Debezium basado en kafka Connect, dirección: https://debezium.io/
2) Aplicaciones independientes que no dependen de terceros: proyecto de código abierto Maxwell, dirección: http://maxwells-daemon.io/
Dado que se implementó conluent (la versión empresarial de kafka, que viene con zookeeper, kafka, ksql, kafka-connector, etc.), este artículo es solo para Debezium.
3. Introducción a Debezium
Debezium es una plataforma de sincronización distribuida de código abierto que captura cambios dinámicos de datos en tiempo real. Captura en tiempo real de fuentes de datos (Mysql, Mongo, PostgreSql): operaciones de agregar (inserciones), actualizar (actualizaciones), eliminar (eliminar), sincronización en tiempo real con Kafka, gran estabilidad y muy rápido.
caracteristicas:
- 1) Simple. No es necesario modificar la aplicación. Puede proporcionar servicios externos.
- 2) Estable. Mantenga un registro de cada cambio en cada línea.
- 3) Rápido. Basado en Kafka, es escalable y puede manejar datos de gran capacidad después de la verificación oficial.
4. Arquitectura síncrona
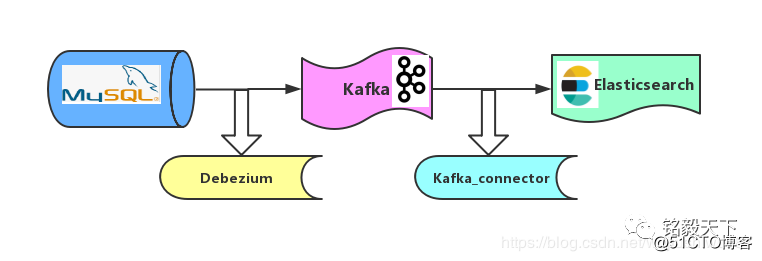
Como se muestra en la figura, la estrategia de sincronización de Mysql a ES adopta el mecanismo de "curva para salvar el país".
Paso 1: Basado en el mecanismo binlog de Debezium, sincronice los datos de Mysql con Kafka.
Paso 2: según el mecanismo Kafka_connector, sincronice los datos de Kafka con Elasticsearch.
5. Debezium realiza la sincronización en tiempo real de la adición, eliminación y modificación de Mysql a ES
Versión del software:
confluente : 5.1.2 ;
Debezium : 0.9.2_Final;
Mysql: 5.7.x.
Elasticsearch: 6.6.1
5.1 Instalación de Debezium
Para la instalación e implementación de confluent, consulte: http://t.cn/Ef5poZk, así que no entraré en detalles aquí .
La instalación de Debezium solo necesita descomprimir el paquete comprimido de debezium-connector-mysql y colocarlo en el directorio de complementos descomprimido (share / java) de Confluent.
Enlace de descarga del paquete comprimido del complemento MySQL Connector:
Preste atención a reiniciar confluent para que Debezium surta efecto.
5.2 Mysql binlog y otras configuraciones relacionadas.
Debezium utiliza el mecanismo binlog de MySQL para monitorear los cambios dinámicos de datos, por lo que MySQL necesita configurar binlog por adelantado.
La configuración principal es la siguiente, agregue la siguiente configuración en mysqld en /etc/my.cnf de la máquina Mysql.
1[mysqld]
2
3server-id = 223344
4log_bin = mysql-bin
5binlog_format = row
6binlog_row_image = full
7expire_logs_days = 10Luego, reinicie Mysql para que binlog surta efecto.
1systemctl start mysqld.service5.3 Configurar el conector conector.
Configurar el directorio de ruta confluente: / etc
Comando Crear carpeta:
1mkdir kafka-connect-debeziumAlmacene la información de configuración del conector en mysql2kafka_debezium.json:
1[root@localhost kafka-connect-debezium]# cat mysql2kafka_debezium.json
2{
3 "name" : "debezium-mysql-source-0223",
4 "config":
5 {
6 "connector.class" : "io.debezium.connector.mysql.MySqlConnector",
7 "database.hostname" : "192.168.1.22",
8 "database.port" : "3306",
9 "database.user" : "root",
10 "database.password" : "XXXXXX",
11 "database.whitelist" : "kafka_base_db",
12 "table.whitlelist" : "accounts",
13 "database.server.id" : "223344",
14 "database.server.name" : "full",
15 "database.history.kafka.bootstrap.servers" : "192.168.1.22:9092",
16 "database.history.kafka.topic" : "account_topic",
17 "include.schema.changes" : "true" ,
18 "incrementing.column.name" : "id",
19 "database.history.skip.unparseable.ddl" : "true",
20 "transforms": "unwrap,changetopic",
21 "transforms.unwrap.type": "io.debezium.transforms.UnwrapFromEnvelope",
22 "transforms.changetopic.type":"org.apache.kafka.connect.transforms.RegexRouter",
23 "transforms.changetopic.regex":"(.*)",
24 "transforms.changetopic.replacement":"$1-smt"
25 }
26}Tenga en cuenta la siguiente configuración:
- "database.server.id" corresponde a la configuración de server-id en Mysql.
- "database.whitelist": el nombre de la base de datos Mysql que se sincronizará.
- "table.whitlelist": el nombre de la tabla Mysq que se sincronizará.
- Importante: "database.history.kafka.topic": almacena la información del registro Shcema de la base de datos, no el tema,
- "database.server.name": el nombre lógico, cada conector es único, como el nombre de prefijo del tema de Kafka donde se escriben los datos.
Pit 1: La función de configuración de 5 líneas relacionada con las transformaciones es escribir la conversión de formato de datos.
De lo contrario, los datos de entrada incluirán: antes, después, antes y después de la modificación del registro, y la información de metadatos (fuente, op, ts_ms, etc.).
Esta información no es necesaria para la escritura de datos posterior en Elasticsearch. (Preste atención a combinar sus propios escenarios comerciales).
Principios relacionados con la conversión de formato: http://t.cn/EftoaIi
5.4 Inicie el conector
1curl -X POST -H "Content-Type:application/json"
2--data @mysql2kafka_debezium.json.json
3http://192.168.1.22:18083/connectors | jq5.5 Verifique que la escritura sea exitosa.
5.5.1 Ver kafka-topic
1 kafka-topics --list --zookeeper localhost:2181Aquí verá la información escrita en el tema de datos.
Preste atención al formato del tema de datos recién escrito: database.schema.table-smt consta de tres partes.
Nombre del tema de este ejemplo:
full.kafka_base_db.account-smt
5.5.2 La escritura de verificación de datos de consumo es normal
1./kafka-avro-console-consumer --topic full.kafka_base_db.account-smt --bootstrap-server 192.168.1.22:9092 --from-beginningEn este punto, Debezium ha completado la sincronización de mysql kafka.
6, kafka-connector realiza la sincronización kafka Elasticsearch
6.1 Introducción al conector Kafka
Ver sitio web oficial: https://docs.confluent.io/current/connect.html
Kafka Connect es un marco para conectar Kafka con sistemas externos (como bases de datos, almacenes de valores clave, índices del sistema de recuperación y sistemas de archivos).
El conector se da cuenta de que los datos de origen de datos comunes (como Mysql, Mongo, Pgsql, etc.) se escriben en Kafka, o los datos de Kafka se escriben en la base de datos de destino, o puede desarrollar su propio conector.
6.2, configuración de sincronización del conector Kafka a ES
Ruta de configuración:
1/home/confluent-5.1.0/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.propertiesContenido de la configuración:
1"connector.class": "io.confluent.connect.elasticsearch.ElasticsearchSinkConnector",
2"tasks.max": "1",
3"topics": "full.kafka_base_db.account-smt",
4"key.ignore": "true",
5"connection.url": "http://192.168.1.22:9200",
6"type.name": "_doc",
7"name": "elasticsearch-sink-test"6.3 Conector de arranque Kafka a ES
Comando de inicio
1confluent load elasticsearch-sink-test
2-d /home/confluent-5.1.0/etc/kafka-connect-elasticsearch/quickstart-elasticsearch.properties6.4 Vista de la API RESTFul de Kafka-connctor
Los detalles del conector de Mysql2kafka y kafka2ES se pueden ver con la ayuda de cartero o un navegador o línea de comandos.
1curl -X GET http://localhost:8083/connectors7. Repetición en boxes.
Pit 2: Pueden ocurrir errores durante el proceso de sincronización, como: El tema de Kafka no puede consumir datos.
Las ideas para la resolución de problemas son las siguientes:
-
1) Confirme si el tema consumido es el tema de la escritura de datos;
- 2) Confirme que no haya ningún error durante la sincronización. Puede utilizar el conector para ver los siguientes comandos.
1curl -X GET http://localhost:8083/connectors-xxx/statusPit 3: Mysql2ES no reconoce el formato de fecha.
Es el problema del paquete jar de Mysql La solución: configurar la información de la zona horaria en my.cnf.
Pit 4: Kafka2ES, ES no escribe datos.
Solucionar problemas de ideas:
- 1) Sugerencia: primero cree un índice coherente con el nombre del tema Nota: El mapeo está personalizado estáticamente, no la identificación y generación dinámica.
- 2) Analizar la causa del error mediante connetor / status y analizarlo paso a paso.
8. Resumen
-
La realización de binlog rompe la limitación del campo, de hecho se ha implementado la búsqueda go-mysql-elasticsearch de la industria.
-
Comparación: logstash, kafka-conector, aunque Debezium "curva para salvar el país" dos pasos para lograr la sincronización en tiempo real, pero la estabilidad + rendimiento en tiempo real es relativamente bueno.
- Recomiende a todos que lo usen. Si tiene un buen método de sincronización, deje un mensaje para discutir e intercambiar.
Referencia:
[1] http://t.cn/EftX2p8
[2] http://t.cn/EftXJU6
[3] http://t.cn/EftXO8c
[4] http://t.cn/EftXn9M
[5] http://t.cn/EftXeOc
Lectura recomendada:
Blockbuster | Lista cognitiva de la metodología de Elasticsearch (Actualización del Festival de Primavera de 2019) 
Primera cuenta pública básica, avanzada y real de Elasticsearch