Recientemente, un fan entrevistó a una empresa de Internet y se le preguntó: ¿Sabe cómo se ejecutan la declaración de selección y la declaración de actualización? , Si quiero escribir un artículo sobre la diferencia entre las dos sentencias de ejecución SQL, esto no vendrá.
En general, la lógica ejecutada por seleccionar y actualizar es aproximadamente la misma, pero la implementación específica sigue siendo diferente.
Por supuesto, una comprensión profunda de la diferencia específica entre seleccionar y actualizar no es solo para entrevistas. Cuando desea que Mysql se ejecute de manera eficiente, la mejor manera es comprender claramente cómo Mysql ejecuta las consultas, solo para tener una comprensión más completa de cada ejecución de SQL. Para optimizar mejor SQl.
seleccionar declaración
Cuando se ejecuta el SQl de una consulta, probablemente ocurran los siguientes pasos:
- El cliente envía una declaración de consulta al servidor.
- El servidor primero verifica el nombre de usuario y la contraseña y verifica la autoridad.
- A continuación, comprueba si la consulta existe en la caché y, de ser así, devuelve el resultado que existe en la caché. Si no existe, continúe con el siguiente paso.
- Luego analiza el método gramatical y léxico, analiza el SQl, la detección gramatical y el preprocesamiento, y luego genera el plan de ejecución correspondiente por el optimizador.
- El ejecutor de Mysql se ejecuta de acuerdo con el plan de ejecución generado por el optimizador y llama a la interfaz del motor de almacenamiento para realizar consultas.
- El servidor devuelve el resultado de la consulta al cliente.
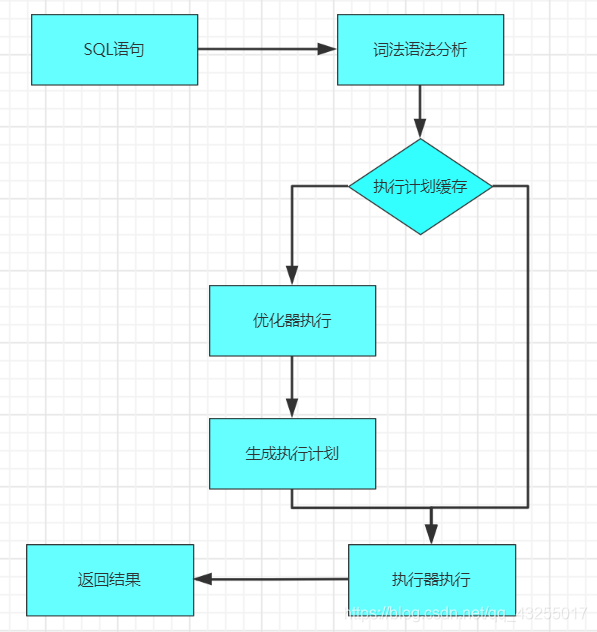
Proceso de ejecución de mysql
La ejecución de sentencias en Mysql es toda ejecución jerárquica, y las tareas realizadas por cada capa son diferentes. Hasta que se devuelve el resultado final, se divide principalmente en capa de servicio y capa de motor. La capa de servicio incluye: conector, analizador, Optimizador, ejecutor. La capa de motor es compatible con varios motores de almacenamiento en forma de complementos.
El diagrama de flujo de la ejecución de Mysql se muestra en la siguiente figura:

Aquí hay un ejemplo para ilustrar el proceso de ejecución de Mysql, cree una tabla de Usuario, como sigue:
// 新建一个表
DROP TABLE IF EXISTS User;
CREATE TABLE `User` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`age` int DEFAULT 0,
`address` varchar(255) DEFAULT NULL,
`phone` varchar(255) DEFAULT NULL,
`dept` int,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8;
// 并初始化数据,如下
INSERT INTO User(name,age,address,phone,dept)VALUES('张三',24,'北京','13265543552',2);
INSERT INTO User(name,age,address,phone,dept)VALUES('张三三',20,'北京','13265543557',2);
INSERT INTO User(name,age,address,phone,dept)VALUES('李四',23,'上海','13265543553',2);
INSERT INTO User(name,age,address,phone,dept)VALUES('李四四',21,'上海','13265543556',2);
INSERT INTO User(name,age,address,phone,dept)VALUES('王五',27,'广州','13265543558',3);
INSERT INTO User(name,age,address,phone,dept)VALUES('王五五',26,'广州','13265543559',3);
INSERT INTO User(name,age,address,phone,dept)VALUES('赵六',25,'深圳','13265543550',3);
INSERT INTO User(name,age,address,phone,dept)VALUES('赵六六',28,'广州','13265543561',3);
INSERT INTO User(name,age,address,phone,dept)VALUES('七七',29,'广州','13265543562',4);
INSERT INTO User(name,age,address,phone,dept)VALUES('八八',23,'广州','13265543563',4);
INSERT INTO User(name,age,address,phone,dept)VALUES('九九',24,'广州','13265543564',4);
Ahora emita una consulta SQl contra esta tabla:查询每个部门中25岁以下的员工个数大于3的员工个数和部门编号,并按照人工个数降序排序和部门编号升序排序的前两个部门。
SELECT dept,COUNT(phone) AS num FROM User WHERE age< 25 GROUP BY dept HAVING num >= 3 ORDER BY num DESC,dept ASC LIMIT 0,2;
Conector
Cuando comience este SQL, primero verificar el nombre de usuario y la contraseña son correctos , si los rendimientos incorrectas el mensaje de error: "Access denied for user";
Si se verifican el nombre de usuario y la contraseña, irá a la tabla de permisos para obtener los permisos del usuario actual y comprobará si la declaración tiene permiso. Si no hay permiso, devolverá directamente un mensaje de error. Si hay permiso, se procederá al siguiente paso. El primer paso se realiza en el conector que se muestra en la Figura 1, para verificar los permisos del usuario conectado.
Nota: Todas las operaciones posteriores dependen del alcance de esta autoridad.
Recuperar caché
Cuando se establece la conexión y se ejecuta la instrucción de consulta, primero verificará en el área de caché si se ha ejecutado el sql. Si se ha ejecutado antes, su resultado de ejecución se aplicará Key-Valuesin problemas a la memoria en forma de clave 执行的sqly valor 结果集.
Si se presiona la clave en la caché, el resultado se devolverá directamente al cliente. Si se pierde, se realizará la operación posterior. Una vez completado, el resultado se almacenará en caché para volver a consultar y obtener, y la próxima vez que se realice la consulta. Tal operación de bucle.
Nota : El caché en Mysql es más adecuado para aquellas tablas estáticas, tablas que no se actualizan con frecuencia, porque mientras la tabla actual tenga actualizaciones de datos, el caché sobre la tabla dejará de ser válido. Si la tabla se actualiza con frecuencia, el caché es efectivo con frecuencia, por lo que se mantiene el caché El rendimiento de consumo es mucho mayor que la optimización de rendimiento que trae el uso de la caché, por lo que la ganancia no valdrá la pena la pérdida, lo que afectará seriamente el rendimiento de Mysql, por lo que la caché se corta en la versión Mysql 8.
Desde un punto de vista personal, la opinión sobre el caché es que no hay necesidad de cortarlo. Puede configurarlo para que desactive el caché de forma predeterminada y luego activarlo cuando lo necesite, y puede especificar qué tablas usar el caché a través de parámetros de configuración, y esas tablas no usan el caché. Esto puede ser más efectivo para usar la caché.
Analizador
El analizador tiene dos pasos principales: (1) 词法分析(2)语法分析
El análisis léxico se realiza principalmente 提炼关键性字, tales como seleccionar, 提交检索的表,, 提交字段名, 提交检索条件determinó que la declaración es seleccionar o actualizar o instrucciones delete.
La principal realizar el análisis de sintaxis para identificar que 输出的sql与否准确, si 合乎mysql的语法, si no cumple con la sintaxis SQL tirará: You have an error in your SQL syntax.
Optimizador
El optimizador de consultas convertirá el árbol de análisis en un plan de ejecución. Una consulta puede tener varios métodos de ejecución y todos devuelven el mismo resultado al final. El papel del optimizador es encontrarlos 最好的执行计划.
Por ejemplo: cuando hay varios índices en la declaración de la consulta, el optimizador decide qué índice utilizar, o cuando hay varias asociaciones de tablas, el optimizador determina el orden de conexión de las tablas y otras operaciones .
El proceso de generar un plan de ejecución consume más tiempo, especialmente cuando existen muchos planes de ejecución alternativos. Si el plan de ejecución final correspondiente a la instrucción se almacena en caché durante la ejecución de una instrucción SQL.
Cuando 相似的语句se ingresa nuevamente al servidor, puede ser directamente 使用已缓存的执行计划, saltándose así todo el proceso de generación del plan de ejecución de la declaración SQL, mejorando así la velocidad de ejecución de la declaración.
MySQL utiliza un optimizador de consultas basado en costos. Intentará predecir el costo de una consulta utilizando un plan de ejecución determinado y elegirá el de menor costo.
Solenoide
El plan de ejecución generado por el optimizador se entrega al ejecutor para su ejecución. El ejecutor llama a la interfaz de lectura del motor de almacenamiento, y la interfaz de lectura del motor de almacenamiento se llama cíclicamente en el ejecutor a cambio de filas de datos que cumplen con las condiciones y la pone en un En el conjunto de resultados, se recorren y obtienen todas las filas de datos que cumplen las condiciones y, finalmente, se devuelve el conjunto de resultados para finalizar todo el proceso de consulta.
declaración de actualización
Hemos terminado la instrucción de selección anterior. El proceso de ejecución de la instrucción de selección pasará por el conector, analizador, optimizador, ejecutor y motor de almacenamiento. La misma instrucción de actualización también pasará por el proceso de ejecución de la instrucción de selección.
Pero la mayor diferencia con select es que la declaración de actualización involucra dos operaciones de registro redo log(rehacer registro) y binlog (registro de archivo) . Para la introducción detallada de estos dos registros, escribí un artículo para presentarlo antes, y aquellos que estén interesados pueden echar un vistazo a []:
Entonces, ¿cómo se usa redo logsum en Mysql binlog? ¿Por qué usar redo logsum binlog? ¿No es suficiente realizar la actualización directamente y guardarla? También colocado redo logy binlog, ¿esto no te molesta? Permítanme hablar despacio, hay muchos artículos en él.
rehacer registro
Todo el mundo sabe que Mysql es una base de datos relacional, que se utiliza para almacenar datos. Cuando la cantidad de acceso a la base de datos es grande, la eficiencia del acceso al disco de lectura y escritura de Mysql es muy baja, y las condiciones en sql filtran los datos, por lo que la eficiencia Es aún más bajo.
Esta es la razón por la introducción de la base de datos no relacionales como razones de caché de datos, tales como: Redis, MongoDBy así sucesivamente, es reducir la base de datos SQL io operaciones durante la ejecución .
De la misma manera, si se ejecuta cada declaración de actualización, se requieren operaciones de io de disco y filtrado de datos, y se puede admitir una pequeña cantidad de acceso y una base de datos de volumen de datos, entonces la cantidad de acceso y la cantidad de datos son grandes, por lo que la base de datos Ciertamente no puedo soportarlo .
Basado en los problemas anteriores, hay un redo logregistro. El registro de rehacer también se llama tecnología WAL ( Write- Ahead Logging). Es una tecnología que escribe el registro primero, actualiza la memoria y luego actualiza el disco. La actualización del disco suele ocurrir cuando Mysql está relativamente inactivo. Esto reduce en gran medida la presión sobre Mysql.
Las características del registro de rehacer son : el registro de rehacer es un tamaño fijo, un registro físico, que pertenece al motor InnoDB, y la escritura del registro de rehacer es una forma de escritura de registro circular :

Como se muestra en la figura anterior: si hay cuatro grupos de redo logarchivos, un grupo tiene un tamaño de 1G, entonces los cuatro grupos tienen un tamaño de 4G, entre los cuales se write posencuentra la posición actual del registro, y los datos se escriben en la posición actual, entonces la posición de escritura se escribirá mientras se escribe Retrocede .
Y check pointes la posición borrada , porque el registro de rehacer es de un tamaño fijo, por lo que cuando el registro de rehacer está lleno, es decir, escriba el punto de control de recuperación de la posición cuando sea necesario eliminar parte de los datos del registro de rehacer, los datos claros se conservarán en el disco , Y luego mueva el punto de control hacia adelante .
El registro de rehacer se da cuenta de que incluso cuando la base de datos está inactiva de manera anormal, los registros anteriores no se perderán después del reinicio, que es la capacidad a prueba de fallos.
binlog
Binlog se llama un registro de archivo, que es un registro lógico. Pertenece al registro de nivel de servidor de Mysql. Registra la lógica original de sql. Hay dos modos principales. Uno es el formato de declaración que registra el sql original, y el formato de fila es Registre el contenido de la línea .
Entonces, parece que aunque rehacer log y binlog registran diferentes formas y contenidos, ambos registros pueden recuperar datos a través de su propio contenido grabado, entonces, ¿por qué existen estos dos registros al mismo tiempo? Mientras uno de ellos no funcione, los dos existen al mismo tiempo. Escúchame despacio, también hay muchos artículos en él.
Porque MyISAM, el motor que viene con Mysql, no tiene una función a prueba de choques, y Mysql no tiene un motor InnoDB antes, y el registro binlog que viene con Mysql solo se usa para archivar registros, por lo que el motor InnoDB también rehace los registros por sí mismo. Para realizar la función de seguridad contra choques .
actualizar el proceso de ejecución
Las funciones y características de los dos registros se han mencionado durante tanto tiempo, entonces, ¿cuál es la relación entre estos dos registros y la declaración de ejecución de la actualización?
Veamos primero la imagen:

premisa: el motor actual usa InnoDB La diferencia entre la instrucción de actualización y la instrucción de selección es principalmente la diferencia entre el uso de estos dos registros cuando el ejecutor y el motor interactúan. Si se ejecuta la siguiente declaración de actualización simple:
update user set age=age+1 where id =2;
Como se mencionó anteriormente, la instrucción de actualización del proceso que ha pasado la instrucción de selección también se ejecutará nuevamente. Cuando se trata del ejecutor:
- El ejecutor llamará a la interfaz de lectura del motor y encontrará la fila de datos con id = 2. Debido a que id es el índice de clave principal, el índice encuentra esta fila de acuerdo con la búsqueda del árbol. Si la fila de datos ya existe en la página de datos de la memoria, el resultado se devolverá inmediatamente Si no está en la memoria, se cargará desde el disco a la memoria y luego se devolverá el resultado de la consulta .
- Luego, el ejecutor agrega +1 al campo de edad del resultado devuelto y llama a la interfaz de escritura del motor para escribir la fila de datos actualizada.
- Motor para obtener las filas de datos actualizadas en la memoria y actualizadas
redo logy los actuadores indicados pueden confirmar la transacción en cualquier momento, esta vezredo logen laprepareetapa. - Después de recibir la notificación del motor, el ejecutor genera un
binlogregistro y llama a la interfaz del motor para enviar la transacción, y el motor cambiaredo logel estado alcommitestado, para que se complete la operación de actualización.

En comparación con la instrucción select, debido a que la selección no actualiza los datos, solo devuelve los datos consultados por el motor al ejecutor incluso después de que finaliza. La actualización implica la actualización de los datos y vuelve a llamar a la interfaz del motor para escribir el proceso de interacción en el motor de almacenamiento.
Compromiso en dos fases
Lo anterior mencionó el proceso de ejecución de la declaración de actualización en detalle, y mencionó las dos fases de preparación y confirmación del registro de rehacer. Esta es una confirmación de dos fases. El propósito de la confirmación de dos fases es garantizar que el registro de rehacer y los registros de binlog mantengan la coherencia de los datos.
Si la escritura del registro de rehacer se realiza correctamente y la escritura del binlog falla, o si el registro de rehacer no se escribe y el binlog escribe correctamente, los datos de resultado obtenidos al usar los dos registros para la recuperación de datos son inconsistentes. Por lo tanto, para asegurarse de que los dos registros sean lógicamente consistentes, utilice dos Presentación de la etapa.
Resumen de rehacer log y binlog
Finalmente, comparemos estos dos registros: rehacer es físico, binlog es lógico, el tamaño de rehacer es fijo y los datos se escriben en forma circular. Cuando los datos están llenos, los datos del registro de rehacer deben borrarse y borrarse. Los datos eliminados se conservan en el disco .
El binlog se escribe en forma de registros adicionales, es decir, cuando el registro se escribe en un cierto tamaño, cambiará al siguiente y no sobrescribirá el registro escrito anteriormente.
Binlog se usa en la capa del servidor de Mysql. Debido a que binlog no tiene una función a prueba de fallas, el motor InnoDB implementa la función a prueba de fallas de rehacer el registro por sí mismo, para garantizar que los dos registros sean lógicamente consistentes usando la confirmación en dos fases .
Al utilizar los registros de rehacer y binlog, puede establecer la innodb_flush_log_at_trx_commitsuma del parámetro sync_binlogen 1, lo que significa que el registro se conservará en el disco cada vez que se confirme una transacción.
Bueno, aquí hay una introducción detallada a la diferencia entre las declaraciones de ejecución de selección y actualización, este problema está aquí, nuestro próximo período, bienvenido a reenviar y compartir.