Frente a nosotros, la lectura y creación del contenedor de origen XML Spring analiza la configuración , crea el contenedor Spring IOC se crea DefaultListableBeanFactory , carga el archivo de configuración y finalmente se resuelve en la instancia del documento, en este artículo, presentamos la pestaña de configuración de Bean y análisis En el artículo anterior, finalmente vimos que la resolución de la etiqueta y el registro de Bean se completaron en el método registerBeanDefinitions ( doc , resource ) de XmlBeanDefinitionReader . A continuación vemos el código fuente del método:
public int registerBeanDefinitions(Document doc, Resource resource) throws BeanDefinitionStoreException {
//标签的解析最终是通过BeanDefinitionDocumentReader 解析的,本行代码创建了一个 BeanDefinitionDocumentReader 实例
BeanDefinitionDocumentReader documentReader = createBeanDefinitionDocumentReader();
int countBefore = getRegistry().getBeanDefinitionCount();
//调用registerBeanDefinitions方法解析
documentReader.registerBeanDefinitions(doc, createReaderContext(resource));
return getRegistry().getBeanDefinitionCount() - countBefore;
}En el código anterior, puede ver que la resolución de la etiqueta finalmente se completa con la instancia BeanDefinitionDocumentReader . Aquí nos enfocamos en createReaderContext ( recurso ) , que devuelve una instancia XmlReaderContext. Porque este método pasará nuestra instancia DefaultListableBeanFactory . el código se muestra a continuación:
public XmlReaderContext createReaderContext(Resource resource) {
return new XmlReaderContext(resource, this.problemReporter, this.eventListener,this.sourceExtractor, this, getNamespaceHandlerResolver());
}Como se muestra en el método anterior, createReaderContext (recurso de recurso ) pasa un this objeto, que es una instancia de XmlBeanDefinitionReader . Está claro que se pasa en XmlBeanDefinitionReader. ¿Por qué dice que se pasa una instancia de DefaultListableBeanFactory ? En la explicación anterior de la configuración de carga, usamos el método de construcción XmlBeanDefinitionReader para pasar una instancia DefaultListableBeanFactory . Por lo tanto, usaremos la instancia XmlReaderContext creada por createReaderContext ( recurso Resource ) para obtener nuestro contenedor IOC, que es la instancia DefaultListableBeanFactory . A continuación, cortamos cómo BeanDefinitionDocumentReader analiza la configuración.
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
logger.debug("Loading bean definitions");
Element root = doc.getDocumentElement();
doRegisterBeanDefinitions(root);
}El código anterior es relativamente simple, obtenga el elemento raíz de la configuración y luego analice el elemento raíz, continuamos mirando el método doRegisterBeanDefinitions (Elemento raíz), el análisis del elemento finalmente se delega a la instancia BeanDefinitionParserDelegate para completar.
protected void doRegisterBeanDefinitions(Element root){
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
.....//这部分代码省略,判断是否是profile指定的配置,如果不是则返回
preProcessXml(root);
//解析配置
parseBeanDefinitions(root, this.delegate);
postProcessXml(root);
this.delegate = parent;
}El siguiente código es la lógica de createDelegate (getReaderContext (), root , parent ) para crear una instancia de BeanDefinitionParserDelegate :
protected BeanDefinitionParserDelegate createDelegate(XmlReaderContext readerContext, Element root, BeanDefinitionParserDelegate parentDelegate) {
//创建BeanDefinitionParserDelegate 实例
BeanDefinitionParserDelegate delegate = new BeanDefinitionParserDelegate(readerContext);
//做一些初始化工作
delegate.initDefaults(root, parentDelegate);
return delegate;
}Análisis de código fuente Camino aquí, el seguimiento es usar BeanDefinitionParserDelegate etiqueta de resolución registrada Bean, y continuamos mirando los métodos parseBeanDefinitions ( root , the this . Delegate ); esta parte del código es relativamente simple, para determinar si la etiqueta es la etiqueta predeterminada o una etiqueta personalizada, de acuerdo con getNamespaceURI Node ( ) Es http://www.springframework.org/schema/beans o nulo para determinar si es el espacio predeterminado.
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//如果是默认命名空间解析默认的标签
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//解析默认标签
parseDefaultElement(ele, delegate);
} else {
//解析自定义标签
delegate.parseCustomElement(ele);
}
}
}
} else {
//否则解析自定义标签
delegate.parseCustomElement(root);
}
}El método anterior usa diferentes métodos para analizar las etiquetas según si el espacio de nombres del nodo es el espacio de nombres predeterminado. En este artículo, presentamos principalmente el método parseDefaultElement ( ele , delegate ) . El código fuente es el siguiente:
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
//import标签
importBeanDefinitionResource(ele);
} else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
//alias标签
processAliasRegistration(ele);
} else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
//Bean标签
processBeanDefinition(ele, delegate);
} else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// beans标签
doRegisterBeanDefinitions(ele);
}
}La etiqueta de importación se utiliza para analizar el recurso importado y finalmente encapsulado como una instancia de recurso. El alias es para registrar el alias del Bean, que eventualmente se almacenará en la variable Map de SimpleAliasRegistry. DefaultListableBeanFactory hereda la clase SimpleAliasRegistry. En lo que queremos enfocarnos es en el análisis de etiquetas de bean. Es decir, el método processBeanDefinition : el código es el siguiente:
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//这里会解析bean标签并且将Bean标签包装为BeanDefinitionHolder 实例
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
//注册Bean
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
} ......//异常以及其他逻辑
}
}En el método anterior, hay dos partes. Una es la encapsulación final del elemento de análisis como un BeanDefinitionHolder , y el Bean se registra en el contenedor. Primero miramos cómo registrar el Bean en el contenedor y luego miramos el análisis de la etiqueta. Frijol registrada es la BeanDefinitionReaderUtils. RegisterBeanDefinition ( bdHolder , getReaderContext () getRegistry ().) Una línea de código, vemos el código fuente:
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)throws BeanDefinitionStoreException {
//获取Bean的名称
String beanName = definitionHolder.getBeanName();
//注册Bean
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
//为bean 注册别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
registry.registerAlias(beanName, alias);
}
}
}El código anterior al llamar a BeanDefinitionRegistry del Bean registrado de registerBeanDefinition, el método BeanDefinitionRegistry (...) es la interfaz DefaultListableBeanFactory , como sigue la implementación de BeanDefinitionRegistry :
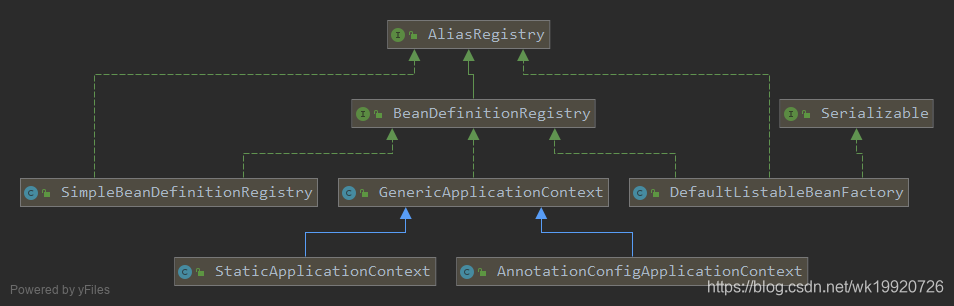
Lo anterior es solo una implementación parcial. Entre ellos, DefaultListableBeanFactory , GenericApplicationContext y SimpleBeanDefinitionRegistry implementan el método registerBeanDefinition (...). SimpleBeanDefinitionRegistry es solo un contenedor simple y no se hace nada. Hay un mapa para almacenar la relación entre el nombre del Bean y el Bean finalmente .ContextnericApplication El método de DefaultListableBeanFactory todavía se llama , por lo que solo debemos prestar atención a DefaultListableBeanFactory . El código es el siguiente:
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition) throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}......//catch代码
//声明一个BeanDefiinition实例
BeanDefinition oldBeanDefinition;
//从缓存中取出一个BeanDefinition实例
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
//缓存BeanDefinition
this.beanDefinitionMap.put(beanName, beanDefinition);
} else {
//如果BeanDefinition没有找到,但是已经有Bean创建//即容器已经启动
if (hasBeanCreationStarted()) {
synchronized (this.beanDefinitionMap) {
//缓存实例
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<String>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<String>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
} else {
//容器没有启动。缓存Bean
this.beanDefinitionMap.put(beanName, beanDefinition);
//添加BeanName
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}Creo que el código anterior es muy largo, pero la lógica principal es almacenar BeanDefinition en el campo Map de DefaultListableBeanFactory y declararlo de la siguiente manera:
private final Map<String, BeanDefinition> beanDefinitionMap = new ConcurrentHashMap<String, BeanDefinition>(256);Después del código anterior, sabemos que la forma final de registro de Bean es BeanDefinition, que se almacena en la instancia de Map de DefaultListableBeanFactory, lo que significa que la forma final de nuestro Bean configurado en XML o Bean anotado es BeanDefinition. Veamos primero la jerarquía BeanDefinition. Figura, y luego observe cómo se resuelven las etiquetas en BeanDefinition.
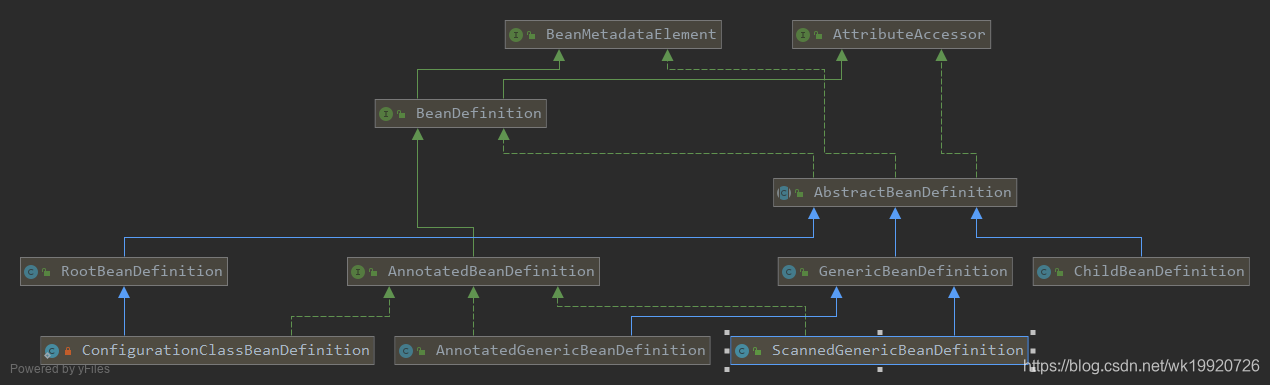
Lo anterior es toda la implementación de BeanDefinition, a continuación vemos cómo la etiqueta analiza el BeanDefinition, en el BeanDefinitionHolder anterior bdHolder = delegate .parseBeanDefinitionElement ( ele ) , a través del BeanDefinitionParserDelegate para analizar la etiqueta, vemos el código fuente de la parte final de análisis
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
//获取Bean标签的id或者name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
List<String> aliases = new ArrayList<String>();
//获取Bean的别名
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
//如果id属性为空,并且name属性不为空,从name属性的值中取出第一个当作Bean名称
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
}
//如果containingBean ==null,检测Name的唯一性
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
//将标签解析为BeanDefinition实例
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
//如果beanDefinition 不为空封装为BeanDefinitionHolder实例
if (beanDefinition != null) {
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}En el método anterior, parseBeanDefinitionElement ( ele , beanName , containingBean ) es finalmente llama ; el código para analizar las etiquetas Bean es como sigue:
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
//创建BeanDefinition
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//解析Bean标签的其他属性,比如scope,autowire等
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
......//解析Bean标签的其他内容meta properties,constructor等
return bd;
}......//catch代码
return null
}En el código anterior, una instancia de BeanDefinition es creada por createBeanDefinition ( className , parent ) , y finalmente se llama al siguiente método . Se crea una instancia usando la clase de implementación GenericBeanDefinition de BeanDefinition , y el nombre y el nombre de la clase se establecen para ello.
public static AbstractBeanDefinition createBeanDefinition(String parentName, String className, ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd = new GenericBeanDefinition();
bd.setParentName(parentName);
if (className != null) {
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
}else {
bd.setBeanClassName(className);
}
}
return bd;
}En este punto , el análisis del código fuente de nuestro registro de Bean está completo En resumen: Primero, el Bean finalmente se analiza en una instancia de BeanDefinition y se almacena en la instancia de Map de DefaultListableBeanFactory . El análisis se completa con el BeanDefinitionParserDelegate encargado . Durante el proceso de análisis de Bean, no se creó ninguna instancia para el Bean. La instancia de bean se crea cuando se adquiere.