I. Resumen

De hecho, Excel fusionando esta demanda debería ser una demanda extremadamente común. Hoy usaremos Python para completar la operación de "fusión (división) de Excel", de la siguiente manera:
- ① Combine varias tablas de Excel en un solo Excel (solo una hoja en cada Excel);
- ② Combine varias tablas de Excel en un solo Excel (más de una hoja en cada Excel);
- ③ Combine varias hojas en una tabla de Excel y guárdelas en el mismo Excel;
- ④ Divida una tabla de Excel en varias tablas de acuerdo con una determinada columna;
2. Explicación de los puntos de conocimiento

De hecho, completar estas operaciones implica demasiados puntos de conocimiento, por lo que antes de hablar sobre los puntos de conocimiento anteriores, lo llevaremos a revisar algunos puntos de conocimiento comúnmente utilizados.
- ① Explicar los puntos de conocimiento común del módulo OS;
- ② Explicar los puntos de conocimiento común del módulo pandas;
- ③ Explicar los puntos de conocimiento común del módulo xlsxwriter;
- ④ Explicar los puntos de conocimiento común de xlrd;
1. Explicación de los puntos de conocimiento del módulo del sistema operativo
Para el módulo os, hablamos principalmente de puntos de conocimiento como os.walk () y os.path.join ().
1.1 os.walk ()
Para este punto de conocimiento, necesitamos explicar los siguientes puntos:
- El valor de retorno de os.walk () es un generador, y necesitamos recorrerlo para obtener el contenido;
- Para cada recorrido, se devuelve un triple (ruta, directorios, archivos);
- ruta: Devuelve la dirección de la ruta de la carpeta que se está recorriendo actualmente;
- dirs: devuelve los nombres de todos los directorios de la carpeta (sin incluir los subdirectorios), cuántos se devuelven como "lista";
- archivos: se devuelven todos los archivos de la carpeta (sin incluir los archivos de los subdirectorios) y cuántos se devuelven como una "lista";
Si dice, hay una carpeta como se muestra en la figura.
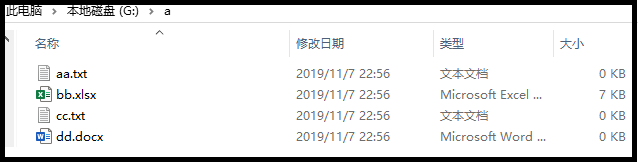
Usando el siguiente código, ¿qué resultados podemos obtener?
pwd = "G:\\a"
print(os.walk(pwd))
for i in os.walk(pwd):
print(i)
for path,dirs,files in os.walk(pwd):
print(files)```
Los resultados son los siguientes:
<generator object walk at 0x0000029BB5AEAB88>
('G:\\a', [], ['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx'])
['aa.txt', 'bb.xlsx', 'cc.txt', 'dd.docx']
1.2 os.path.join ()
Esta función se usa principalmente para combinar múltiples rutas y regresar, es súper simple y no se desarrollará.
path1 = 'G:\\a'
path2 = 'aa.txt'
print(os.path.join(path1,path2))
Los resultados son los siguientes:
G:\a\aa.txt
2. Explicación de los puntos de conocimiento del módulo pandas
Debido a que necesitamos usar Pandas para fusionar Excel, tenemos que aprender a usar Pandas para fusionar datos verticalmente.
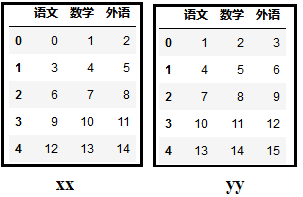
Primero creamos 2 marcos de datos (DataFrame):
import numpy as np
xx = np.arange(15).reshape(5,3)
yy = np.arange(1,16).reshape(5,3)
xx = pd.DataFrame(xx,columns=["语文","数学","外语"])
yy = pd.DataFrame(yy,columns=["语文","数学","外语"])
print(xx)
print(yy)
El efecto es el siguiente:
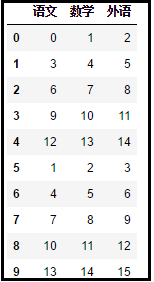
Luego, puede usar la función concat () en Pandas para completar la operación de empalme vertical.
- En pd.concat (lista) [eje predeterminado = 0], el valor predeterminado es la fusión vertical de datos;
- pd.concat (lista) es una lista pasada entre paréntesis;
- ignore_list = True significa ignorar el índice original y regenerar un nuevo conjunto de índices;
- O puede escribirse directamente como z = pd.concat ([xx, yy], ignore_list = True);
concat_list = []
concat_list.append(xx)
concat_list.append(yy)
z = pd.concat(concat_list,ignore_list=True)
print(z)
El efecto es el siguiente:
3. Explicación de los puntos de conocimiento del módulo xlsxwriter
El módulo xlsxwriter generalmente se usa junto con el módulo xlrd,
xlsxwriter: responsable de escribir datos,
xlrd: responsable de leer datos.
A continuación, presentaremos el uso común de estas dos bibliotecas.
1) ¿Cómo crear un "libro de trabajo"?
import xlsxwriter
# 这一步相当于创建了一个新的"工作簿";
# "demo.xlsx"文件不存在,表示新建"工作簿";
# "demo.xlsx"文件存在,表示新建"工作簿"覆盖原有的"工作簿";
workbook = xlsxwriter.Workbook("demo.xlsx")
# close是将"工作簿"保存关闭,这一步必须有,否则创建的文件无法显示出来。
workbook.close()
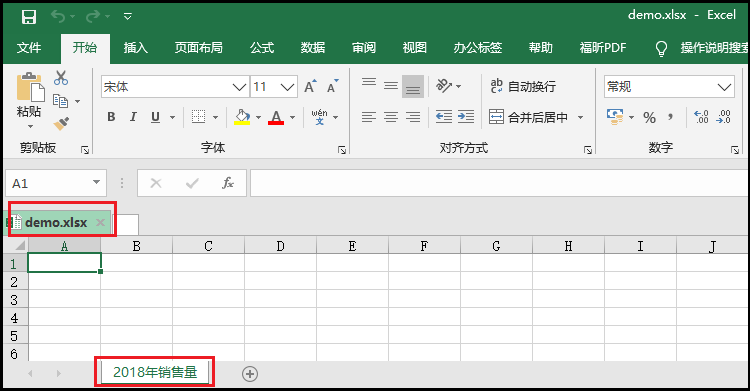
2) Cómo agregar una "hoja"
Sabemos que un archivo de Excel es un libro de trabajo de Excel, y en cada libro de trabajo hay muchas "hojas". A continuación, ¿cómo implementamos esta operación con código?
import xlsxwriter
workbook = xlsxwriter.Workbook("cc.xlsx")
worksheet = workbook.add_worksheet("2018年销售量")
workbook.close()
El efecto es el siguiente:
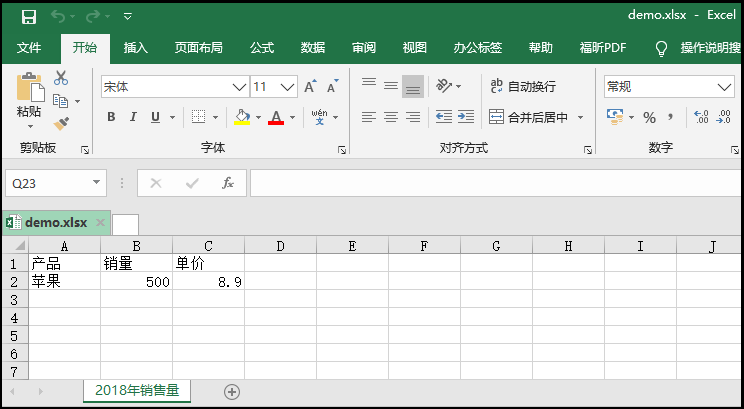
3) ¿Cómo insertar datos en la tabla?
import xlsxwriter
# 创建一个名为【demo.xlsx】工作簿;
workbook = xlsxwriter.Workbook("demo.xlsx")
# 创建一个名为【2018年销售量】工作表;
worksheet = workbook.add_worksheet("2018年销售量")
# 使用write_row方法,为【2018年销售量】工作表,添加一个表头;
headings = ['产品','销量',"单价"]
worksheet.write_row('A1',headings)
# 使用write方法,在【2018年销售量】工作表中插入一条数据;
# write语法格式:worksheet.write(行,列,数据)
data = ["苹果",500,8.9]
for i in range(len(headings)):
worksheet.write(1,i,data[i])
workbook.close()
El efecto es el siguiente:
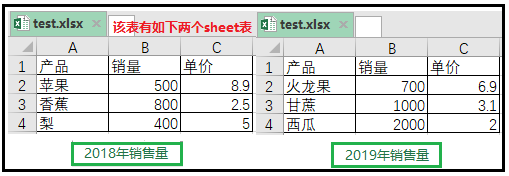
4. Explicación de los puntos de conocimiento del módulo xlrd
Aquí hay un libro de trabajo "test.xlsx". Hay dos "hojas" en el archivo, llamadas "Ventas en 2018" y "Ventas en 2019", como se muestra en la figura.
1) ¿Cómo abrir un "libro de trabajo"? -> libro_abierto ()
# 这里所说的"打开"并不是实际意义上的打开,只是将该表加载到内存中打开。
# 我们并看不到"打开的这个效果"
import xlrd
file = r"G:\Jupyter\test.xlsx"
xlrd.open_workbook(file)
Los resultados son los siguientes:
<xlrd.book.Book at 0x29bb8e4eda0>
2) ¿Cómo obtener todos los nombres de "Hoja" en un libro de trabajo? -> sheet_names ()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheet_names()
Los resultados son los siguientes:
['2018年销售量', '2019年销售量']
3) ¿Cómo obtener la lista de objetos de todas las "Hojas de hoja"? -> hojas ()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
Los resultados son los siguientes:
[<xlrd.sheet.Sheet at 0x29bb8f07a90>, <xlrd.sheet.Sheet at 0x29bb8ef1390>]
Podemos usar el índice para obtener el objeto de cada hoja y luego podemos operar en cada objeto.
fh.sheets()[0]
<xlrd.sheet.Sheet at 0x29bb8f07a90>
fh.sheets()[1]
<xlrd.sheet.Sheet at 0x29bb8ef1390>
4) ¿Cómo obtener el número de filas y columnas de cada Hoja? -> Atributos nrows y ncols
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
fh.sheets()
fh.sheets()[0].nrows # 结果是:4
fh.sheets()[0].ncols # 结果是:3
fh.sheets()[1].nrows # 结果是:4
fh.sheets()[1].ncols # 结果是:3
5) Obtener por fila, los datos en cada Hoja—> row_values ()
import xlrd
file = r"G:\Jupyter\test.xlsx"
fh = xlrd.open_workbook(file)
sheet1 = fh.sheets()[0]
for row in range(fh.sheets()[0].nrows):
value = sheet1.row_values(row)
print(value)
El efecto es el siguiente:

Tres, narración del caso

1. Combine varias tablas de Excel en un solo Excel (solo una hoja en cada Excel)
Hay cuatro tablas, que están claras en el diagrama, así que no explicaré mucho.
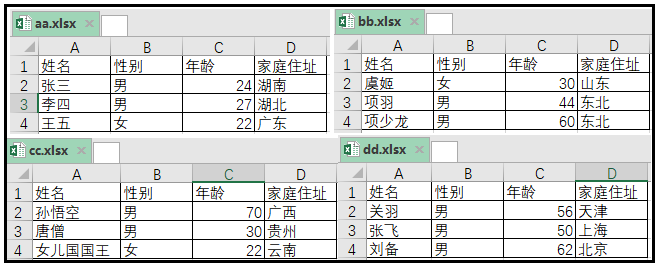
El código de implementación es el siguiente:
import pandas as pd
import os
pwd = "G:\\b"
df_list = []
for path,dirs,files in os.walk(pwd):
for file in files:
file_path = os.path.join(path,file)
df = pd.read_excel(file_path)
df_list.append(df)
result = pd.concat(df_list)
print(result)
result.to_excel('G:\\b\\result.xlsx',index=False)
Los resultados son los siguientes:
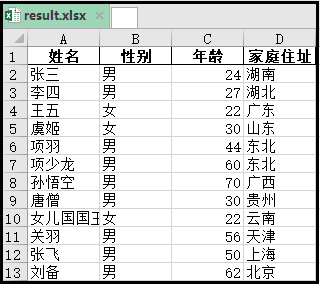
2. Combine varias tablas de Excel en un solo Excel (más de una hoja en cada Excel)
Hay dos libros de trabajo como se muestra en la figura. Un libro es pp.xlsx y un libro es qq.xlsx. En el libro de trabajo pp.xlsx, hay dos hojas de trabajo, sheet1 y sheet2. Bajo el libro de trabajo qq.xlsx, también hay dos hojas de trabajo, sheet1 y sheet2.
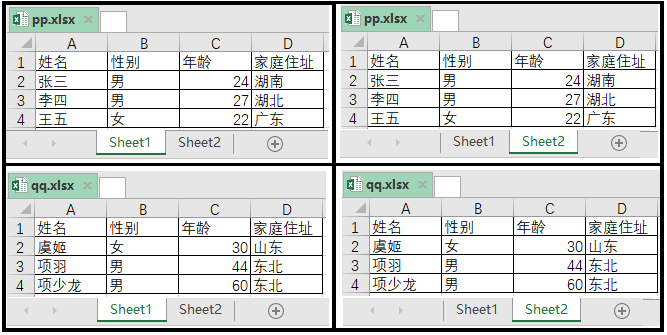
El código de implementación es el siguiente:
import xlrd
import xlsxwriter
import os
# 打开一个Excel文件,创建一个工作簿对象
def open_xlsx(file):
fh=xlrd.open_workbook(file)
return fh
# 获取sheet表的个数
def get_sheet_num(fh):
x = len(fh.sheets())
return x
# 读取文件内容并返回行内容
def get_file_content(file,shnum):
fh=open_xlsx(file)
table=fh.sheets()[shnum]
num=table.nrows
for row in range(num):
rdata=table.row_values(row)
datavalue.append(rdata)
return datavalue
def get_allxls(pwd):
allxls = []
for path,dirs,files in os.walk(pwd):
for file in files:
allxls.append(os.path.join(path,file))
return allxls
# 存储所有读取的结果
datavalue = []
pwd = "G:\\d"
for fl in get_allxls(pwd):
fh = open_xlsx(fl)
x = get_sheet_num(fh)
for shnum in range(x):
print("正在读取文件:"+str(fl)+"的第"+str(shnum)+"个sheet表的内容...")
rvalue = get_file_content(fl,shnum)
# 定义最终合并后生成的新文件
endfile = "G:\\d\\concat.xlsx"
wb1=xlsxwriter.Workbook(endfile)
# 创建一个sheet工作对象
ws=wb1.add_worksheet()
for a in range(len(rvalue)):
for b in range(len(rvalue[a])):
c=rvalue[a][b]
ws.write(a,b,c)
wb1.close()
print("文件合并完成")
El efecto es el siguiente:
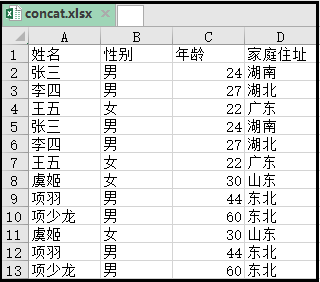
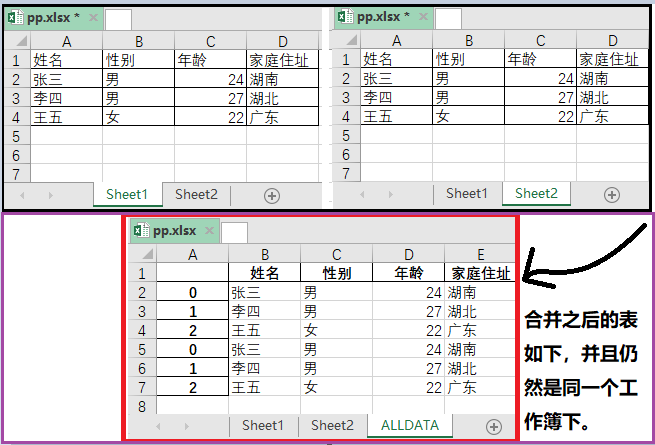
3. Combine varias hojas en una tabla de Excel y guárdelas en el mismo Excel
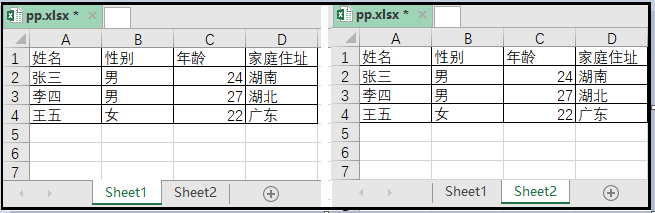
El código de implementación es el siguiente:
import xlrd
import pandas as pd
from pandas import DataFrame
from openpyxl import load_workbook
excel_name = r"D:\pp.xlsx"
wb = xlrd.open_workbook(excel_name)
sheets = wb.sheet_names()
alldata = DataFrame()
for i in range(len(sheets)):
df = pd.read_excel(excel_name, sheet_name=i, index=False, encoding='utf8')
alldata = alldata.append(df)
writer = pd.ExcelWriter(r"C:\Users\Administrator\Desktop\score.xlsx",engine='openpyxl')
book = load_workbook(writer.path)
writer.book = book
# 必须要有上面这两行,假如没有这两行,则会删去其余的sheet表,只保留最终合并的sheet表
alldata.to_excel(excel_writer=writer,sheet_name="ALLDATA")
writer.save()
writer.close()
El efecto es el siguiente:
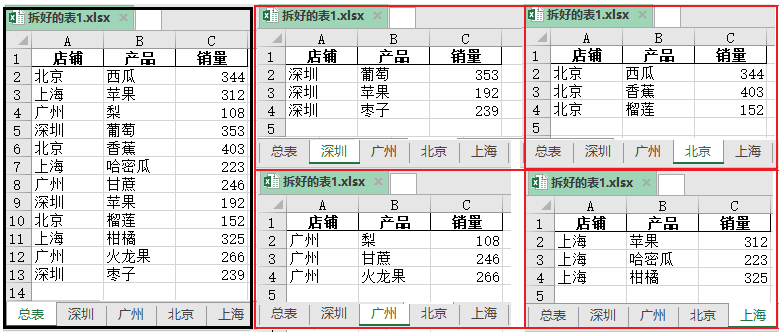
4. Divida una tabla de Excel en varias tablas según una columna determinada
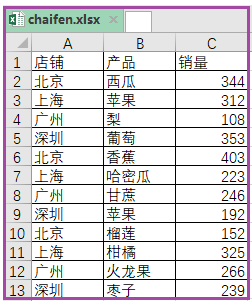
El código de implementación es el siguiente:
import pandas as pd
import xlsxwriter
data=pd.read_excel(r"C:\Users\Administrator\Desktop\chaifen.xlsx",encoding='gbk')
area_list=list(set(data['店铺']))
writer=pd.ExcelWriter(r"C:\Users\Administrator\Desktop\拆好的表1.xlsx",engine='xlsxwriter')
data.to_excel(writer,sheet_name="总表",index=False)
for j in area_list:
df=data[data['店铺']==j]
df.to_excel(writer,sheet_name=j,index=False)
writer.save() #一定要加上这句代码,“拆好的表”才会显示出来
El efecto es el siguiente: