Este es el quinto artículo de JVM en la serie de entrevistas.
¿Hablar sobre el diseño de memoria de la JVM?

La máquina virtual Java incluye principalmente varias áreas:
Montón : La porción más grande de memoria en el montón de la máquina virtual Java es un área de memoria compartida por subprocesos. Básicamente, todas las matrices de instancias de objetos tienen espacio asignado en el montón. El área del montón se subdivide en la generación joven en el área de Yound y la generación vieja en el área antigua. La generación joven se divide en tres partes: Edén, S0 y S1. Su proporción predeterminada es 8: 1: 1.
Pila : La pila es un área de memoria privada de subprocesos.Cuando se ejecuta cada método, se crea un marco de pila en la pila.El proceso de invocación del método corresponde al proceso de apilar y hacer estallar la pila. La estructura de cada marco de pila incluye tabla de variables locales, pila de operandos, conexión dinámica, dirección de retorno del método.
La tabla de variables locales se utiliza para almacenar parámetros de métodos y variables locales. Cuando se llama al primer método, sus parámetros se pasarán a la tabla de variables locales continuas a partir de 0.
La pila de operandos se utiliza para transferir algunas instrucciones de código de bytes de la tabla de variables locales a la pila de operandos, también se utiliza para preparar los parámetros de llamada al método y recibir los resultados de retorno del método.
El enlace dinámico se utiliza para convertir el método representado por la referencia simbólica en la referencia directa del método real.
Metadatos : antes de Java 1.7, se incluía el concepto de área de método. El grupo de constantes existía en el área de método (generación permanente) y el área de método en sí era un concepto lógico. Después de 1.7, el grupo de constantes se movió al montón En el interior, después de 1.8, se elimina el concepto de generación permanente (aún se conserva el concepto del área de método), y el método de implementación son los metadatos actuales. Contiene metainformación de la clase y el grupo de constantes en tiempo de ejecución.
El archivo de clase es la información de definición de clase e interfaz.
El grupo de constantes en tiempo de ejecución es la manifestación en tiempo de ejecución del grupo constante de clases e interfaces.
Pila de métodos nativos : el área que se utiliza principalmente para ejecutar métodos nativos nativos
Contador de programa : también es un área privada de subprocesos, utilizada para registrar la dirección de instrucción del código de bytes que está ejecutando la máquina virtual bajo el subproceso actual
¿Conoce el proceso de creación de un nuevo objeto?
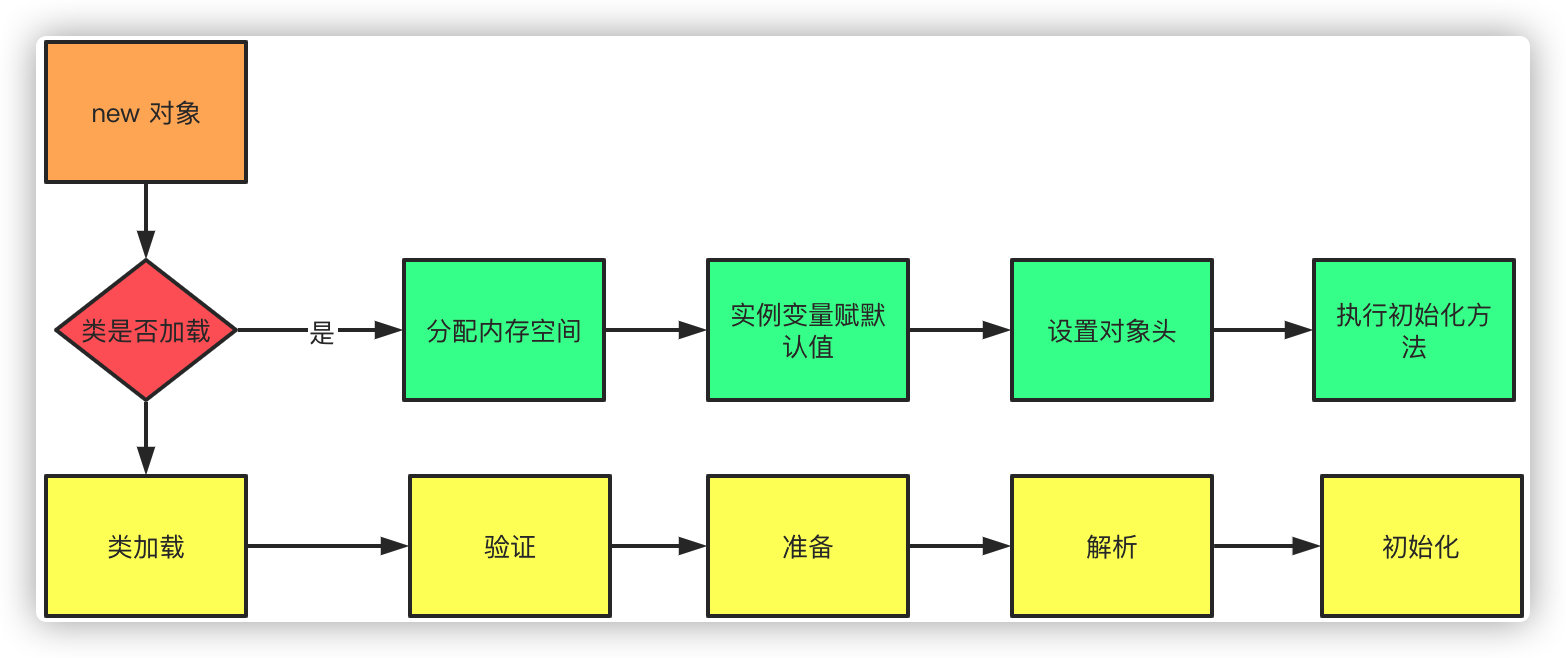
Cuando la oportunidad virtual ve la nueva palabra clave, la realización juzga si la clase actual se ha cargado, si la clase no está cargada, primero ejecute el mecanismo de carga de la clase, y luego asigne espacio e inicialice el objeto después de que se complete la carga.
- Primero verifique si la clase actual está cargada, si no está cargada, ejecute el mecanismo de carga de clases
- Cargando: es el proceso de cargar desde un código de bytes a un flujo binario.
- Verificación: Por supuesto, después de que se complete la carga, por supuesto, debe verificar si el archivo de clase cumple con las especificaciones de la máquina virtual. Al igual que nuestra solicitud de interfaz, lo primero es, por supuesto, hacer una verificación de parámetros.
- Preparación: Asignar valores predeterminados a constantes y variables estáticas
- Resolución: El proceso de reemplazar referencias de símbolos en el grupo constante (usando símbolos para describir el objetivo referenciado) por referencias directas (punteros o identificadores al objetivo, etc.)
- Inicialización: ejecute el bloque de código estático (cinit) para inicializar, si hay una clase principal, inicialice la clase principal primero
Ps: ¡Los bloques de código estático son absolutamente seguros para subprocesos y solo pueden ser inicializados y llamados implícitamente por la máquina virtual Java durante el proceso de carga de clases! (¿Hay algún problema aquí, es seguro el subproceso del bloque de código estático?)
Cuando se carga la clase, se sigue el proceso de asignación e inicialización de objetos
- Primero asigne un tamaño adecuado de espacio de memoria para el objeto
- Luego asigne valores predeterminados a las variables de instancia
- Establezca la información del encabezado del objeto, el código hash del objeto, la edad de generación de GC, la información de metadatos, etc.
- Realizar la inicialización del constructor (init)
¿Conoce el modelo de delegación parental?
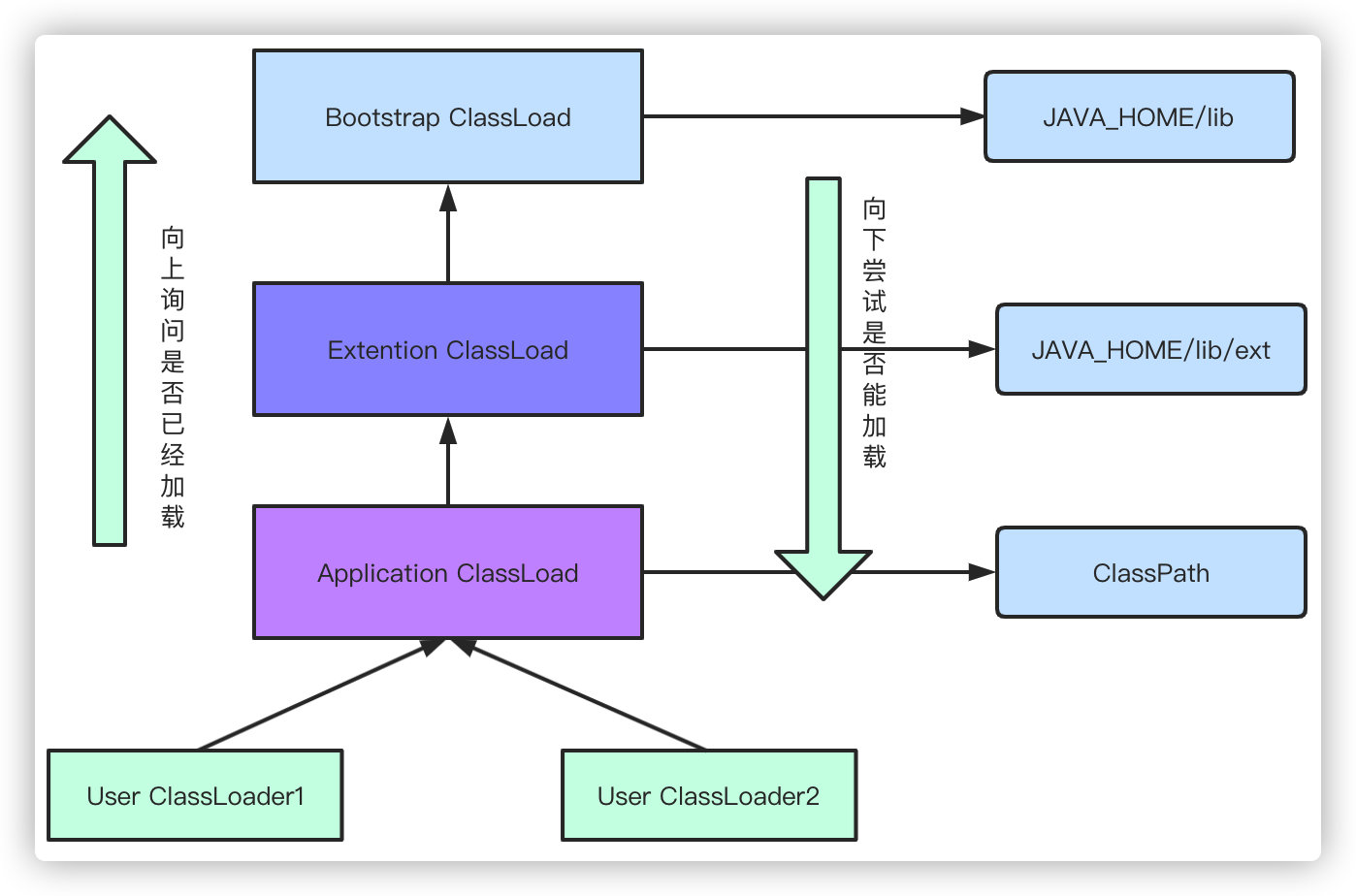
Los cargadores de clases se dividen de arriba a abajo:
- Bootstrap ClassLoader inicia el cargador de clases: de forma predeterminada, cargará el jar en el directorio JAVA_HOME / lib
- Cargador de clases extendido ClassLoader de extensión: predeterminado para cargar el jar en el directorio JAVA_HOME / lib / ext
- Application ClassLoader: por ejemplo, nuestra aplicación web cargará las clases en ClassPath en el programa web
- User ClassLoader cargador de clases definido por el usuario: definido por el usuario
Cuando estemos cargando una clase, primero preguntaremos si nuestro cargador padre se ha cargado. Si no, preguntaremos a su vez. Si no está cargado, intentaremos cargar la clase actual de arriba hacia abajo hasta que la carga sea exitosa.
¿Cuáles son los algoritmos de recolección de basura?
Mark-clear
Los objetos que deben reciclarse se marcan uniformemente y todos los objetos marcados se reciclan uniformemente después de que se completa el marcado. Dado que el proceso de marcado debe atravesar todas las RAÍCES de GC, el proceso de limpieza también atraviesa todos los objetos en el montón, por lo que la eficiencia del algoritmo de barrido de marcas Baja, pero también trae el problema de la fragmentación de la memoria.
Copiar algoritmo
Para resolver el problema de rendimiento, se creó el algoritmo de replicación. Divide la memoria en dos áreas de igual tamaño y utiliza una de ellas cada vez. Cuando se agota una memoria, los objetos supervivientes se copian en otra área de memoria. , Y luego borre la memoria actual, para que se puedan resolver los problemas de fragmentación de memoria y rendimiento. Pero también trae otro problema, ¡el espacio de memoria utilizable se reduce a la mitad!
Por lo tanto, nació nuestra actual estructura común de memoria de generación joven + generación anterior: Eden + S0 + S1, porque según la investigación de IBM, el 98% de los objetos están vivos y muriendo, por lo que los objetos reales que sobreviven no son Hay mucho desperdicio de memoria, por lo que la proporción predeterminada es 8: 1: 1.
De esta manera, cuando está en uso, solo se usa uno del área de Edén y S0S1, y los objetos supervivientes se copian a otra área de Superviviente no utilizada cada vez, y Edén y el Superviviente usado se borran al mismo tiempo, de modo que el desperdicio de memoria es solo del 10%. .
Si el último Superviviente no utilizado no puede dejar los objetos supervivientes, estos objetos entrarán en la vejez.
PD: Entonces, hay algunas preguntas básicas que le preguntarán por qué está dividido en distritos de Eden y 2 distritos de Survior. cual es el efecto? Es para ahorrar memoria y solucionar el problema de la fragmentación de la memoria, estos algoritmos se producen para solucionar el problema, si entiendes el motivo, no necesitas memorizarlo.
Margen
Obviamente, es inapropiado usar el algoritmo de replicación para la vejez, porque la tasa de supervivencia de los objetos que ingresan a la vejez es relativamente alta. En este momento, la replicación frecuente tendrá un mayor impacto en el rendimiento y no habrá más espacio para tocar fondo. Por lo tanto, de acuerdo con las características de la vejez, todos los objetos supervivientes se marcan a través del algoritmo de organización de marcas, de modo que todos los objetos supervivientes se mueven a un extremo y luego se borra el espacio de memoria fuera del límite.
Entonces, ¿qué es GC ROOT? ¿Qué son las RAÍCES de GC?
El algoritmo de marcado mencionado anteriormente, ¿cómo marcar si un objeto está vivo? Simplemente use el método de conteo de referencias para establecer un contador de referencia para el objeto. Siempre que haya una referencia a él, el contador es +1, de lo contrario el contador es -1, pero este algoritmo simple no puede resolver el problema de las referencias circulares.
Java utiliza el algoritmo de análisis de accesibilidad para lograr el propósito de marcar los objetos supervivientes. Define una serie de GC ROOT como punto de partida y busca desde el punto de partida hacia abajo. La ruta de búsqueda se denomina cadena de referencia. Cuando un objeto llega a GC ROOT, no hay nada Si la cadena de referencia está conectada, se puede determinar que el objeto se recicla.
Los objetos que se pueden utilizar como GC ROOT incluyen:
-
Objetos referenciados en la pila
-
Objetos referenciados por constantes y variables estáticas
-
El objeto al que hace referencia el método nativo de la pila de métodos nativos
¿Entiende el recolector de basura? ¿Qué recolectores de basura hay en las generaciones jóvenes y mayores?
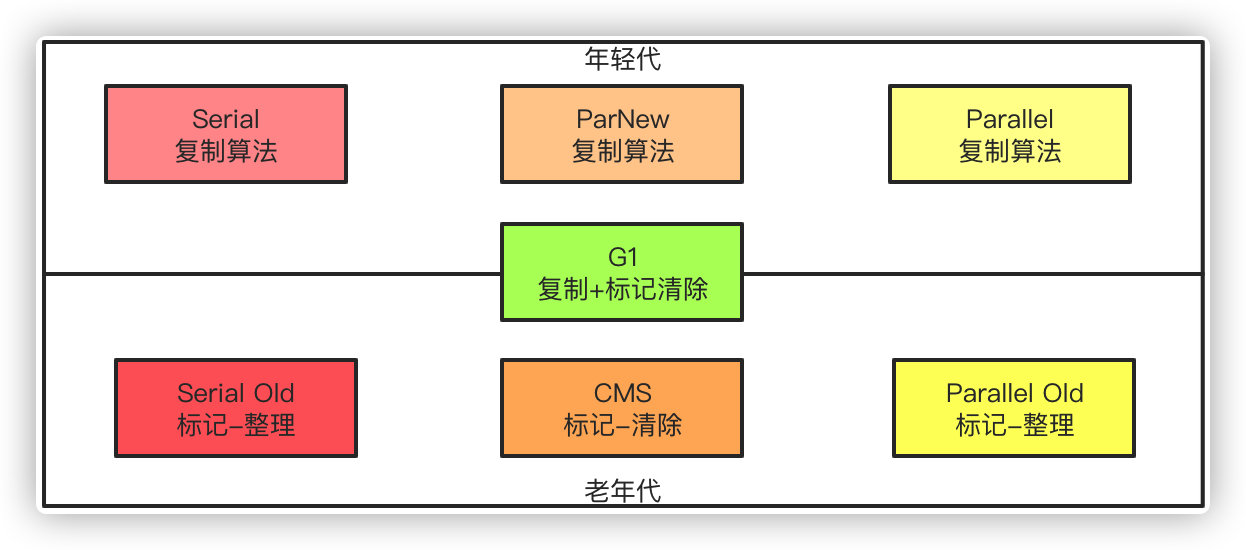
La generación joven de recolectores de basura incluye Serial, ParNew y Parallell, y la generación anterior incluye Serial Old, CMS, Parallel Old y el nuevo recolector G1 del barco en JDK11.
Serie : versión de un solo subproceso del recolector, STW (Stop The World) se utilizará durante la recolección de basura, es decir, otros subprocesos de trabajo deben suspenderse durante la recolección de basura
ParNew : versión multiproceso de Serial, utilizada junto con CMS
Parallel Scavenge : un recolector de basura multiproceso que puede recolectar en paralelo
Serial Old : la versión antigua de Serial, también de un solo subproceso
Parallel Old : la versión antigua de Parallel Scavenge
CMS (Concurrent Mark Sweep) : El colector CMS es un colector cuyo objetivo es obtener el menor tiempo de pausa. En comparación con otros colectores, el tiempo STW es más corto. Puede recolectar en paralelo y se basa en el algoritmo de marca-barrido. Todo el proceso de GC se divide en 4 pasos.
- Marca inicial: marca los objetos a los que se puede asociar GC ROOT, se requiere STW
- Marcado concurrente: el proceso de atravesar todo el gráfico de objetos desde los objetos directamente asociados de GCRoots, sin STW
- Remarcado: para corregir el marcado que cambia debido al funcionamiento continuo del programa de usuario durante el marcado simultáneo, se requiere STW
- Limpieza concurrente: limpie y elimine los objetos muertos juzgados en la fase de marcado, no se requiere STW
Desde la perspectiva de todo el proceso, el marcado simultáneo y el borrado simultáneo son los que llevan más tiempo, pero no es necesario detener el hilo del usuario, mientras que el marcado y el remarcado iniciales llevan menos tiempo, pero el hilo del usuario debe detenerse. En general, todo el proceso provocó El tiempo de pausa es corto y la mayoría de las veces puede funcionar con subprocesos de usuario.
G1 (Garbage First) : el recolector G1 es el recolector de basura predeterminado de JDK9 y ya no distingue entre la generación joven y la generación anterior para la recolección.
¿Entiendes el principio de G1?

G1 es el recolector predeterminado del servidor después de JDK9, y ya no distingue entre la generación joven y la generación anterior para la recolección de basura. Divide la memoria en múltiples regiones, y el tamaño de cada región se puede establecer mediante -XX: G1HeapRegionSize, el tamaño es 1 ~ 32M, para el almacenamiento de objetos grandes, se deriva el concepto de Humongous. Los objetos que excedan la mitad del tamaño de la Región se considerarán objetos grandes, y los objetos que excedan el tamaño de toda la Región se considerarán objetos supergrandes y se almacenarán en N consecutivos. En la Región Humongous, G1 mantiene una lista de prioridades en segundo plano cuando se recicla, y cada vez que la región con los ingresos más altos se recicla primero de acuerdo con el tiempo de pausa de recolección establecido por el usuario.
El proceso de reciclaje de G1 se divide en los siguientes cuatro pasos:
- Marca inicial: marca los objetos a los que se puede asociar GC ROOT, se requiere STW
- Marcado concurrente: el proceso de atravesar todo el gráfico de objetos desde los objetos directamente asociados de GCRoots, y después de que se completa el escaneo, los objetos que han cambiado durante el proceso de marcado concurrente serán reprocesados
- Puntuación final: suspenda brevemente el hilo del usuario y vuelva a procesarlo, se requiere STW
- Cribado y reciclaje: Actualice los datos estadísticos de las Regiones, clasifique el valor y el costo del reciclaje de cada Región y formule planes de reciclaje de acuerdo con el tiempo de pausa establecido por el usuario. A continuación, copie los objetos supervivientes de la Región que deben reciclarse en la Región vacía y limpie la Región anterior. Se requiere STW
En general, además del marcado concurrente, varios otros procesos todavía requieren STW corto El objetivo de G1 es aumentar el rendimiento tanto como sea posible con pausas y retrasos controlables.
¿Cuándo se activarán YGC y FGC? ¿Cuándo entrará el sujeto en la vejez?
Cuando un nuevo objeto solicita espacio de memoria, si el área de Edén no puede cumplir con los requisitos de asignación de memoria, se activa YGC y los objetos vivos en el área de Superviviente y el área de Edén en uso se envían al área de Superviviente no utilizada. Si aún no hay suficiente espacio después de YGC , Se ingresará directamente a la generación anterior para asignar. Si la generación anterior no puede asignar espacio, se activa el FGC. Después del FGC, se informará la excepción OOM.

Después de YGC, los objetos supervivientes se copiarán en el área de Superviviente no utilizada. Si el área S no se puede dejar, se promoverán directamente a la generación anterior. Para aquellos objetos que se han copiado de ida y vuelta en el área de Superviviente, el umbral de intercambio se configura a través de -XX: MaxTenuringThreshold, el valor predeterminado es 15 veces, y si se excede el número, también ingresará la vejez.
Además, existe un mecanismo de juicio de edad dinámico, que puede promover la generación anterior sin esperar MaxTenuringThreshold. Si la suma de los tamaños de todos los objetos de la misma edad en el espacio de Superviviente es mayor que la mitad del espacio de Superviviente, los objetos cuya edad sea mayor o igual a esta edad pueden ingresar directamente a la vejez.
¿Cómo solucionar problemas de FullGC frecuentes?
La mejor forma de resolver este tipo de problemas es analizar con ejemplos específicos, si no, hablar sobre los pasos generales del análisis. FGC puede ocurrir debido a una asignación de memoria no razonable. Por ejemplo, el área de Eden es demasiado pequeña, lo que hace que los objetos ingresen a la vejez con frecuencia. Esto se puede ver a través de la configuración de parámetros de inicio. Además, puede haber una pérdida de memoria, que se puede verificar mediante los siguientes pasos:
- jstat -gcutil o ver el registro de gc.log para ver la recuperación de memoria

S0 y S1 representan respectivamente la proporción de las dos áreas de supervivientes
E representa la proporción del área del Edén, como se puede ver en la figura 78% se usa
O representa la vejez, M representa el metaespacio, YGC ocurre 54 veces, YGCT representa el tiempo acumulativo consumido por YGC y GCT representa el tiempo acumulativo consumido por GC.
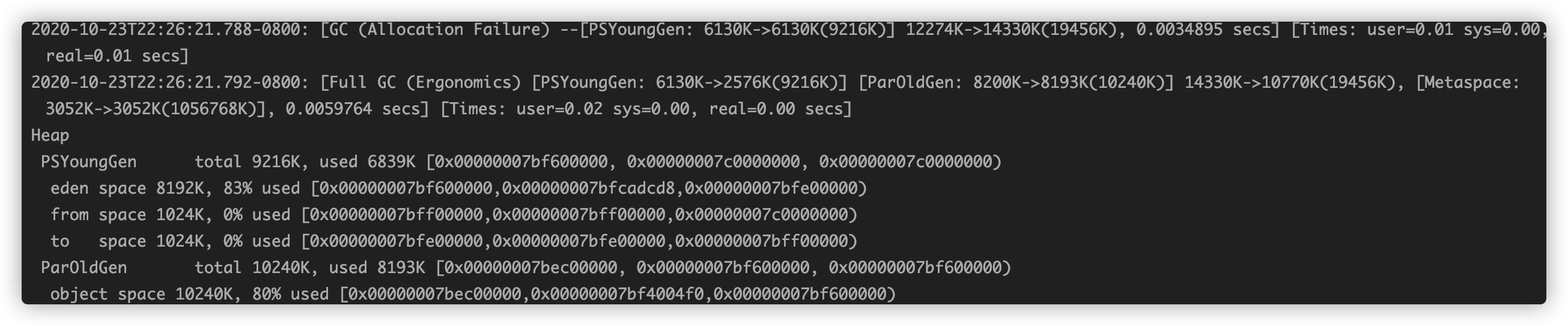
[GC [FGC al principio representa el tipo de recolección de basura
PSYoungGen: 6130K-> 6130K (9216K)] 12274K-> 14330K (19456K), 0.0034895 segundos representa el uso de memoria antes y después de YGC
Tiempos: usuario = 0.02 sys = 0.00, real = 0.00 segundos, el usuario representa el tiempo de CPU consumido en modo de usuario, sys representa el tiempo de CPU consumido en modo kernel y real representa el tiempo de espera de varios relojes de pared
Estas dos cifras son solo ejemplos y no tienen correlación. Por ejemplo, puede ver en la figura si se realiza FGC, cuánto tiempo tarda la FGC, si la memoria de la generación joven se reduce después de la GC y se obtiene alguna información preliminar. juicio.
- Volcar el archivo de memoria para un análisis específico, por ejemplo, use el comando jmap jmap -dump: format = b, file = dumpfile pid, y luego analícelo con Eclipse Memory Analyzer y otras herramientas después de exportar para ubicar el código y arreglarlo
También puede haber una pregunta aquí, como el aumento de la CPU, y ¿qué pasa con FGC? El método es similar
- Encuentre el pid del proceso actual, top -p pid -H vea la ocupación de recursos, encuentre el hilo
- printf "% x \ n" pid, convierte el pid del hilo a hexadecimal, como 0x32d
- jstack pid | grep -A 10 0x32d Ver el registro de pila del hilo, pero no se encuentra que el problema continúe
- Volcar el archivo de memoria y analizarlo con MAT y otras herramientas, localizar el código y arreglarlo
¿Tiene alguna experiencia en el ajuste de JVM?
Debe entenderse que el propósito de todo el ajuste es lograr un mayor rendimiento con un menor costo de hardware, y el ajuste de JVM es el mismo, para lograr el mejor rendimiento mediante el ajuste del recolector de basura y la asignación de memoria.
Significado de parámetro simple
Primero, necesita conocer el significado de varios parámetros principales.
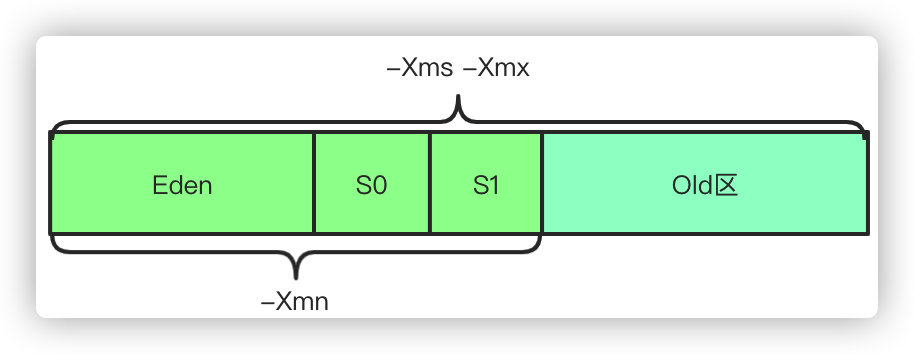
- -Xms establece el tamaño de pila inicial, -Xmx establece el tamaño de pila máximo
- -XX: tamaño de generación joven NewSize, -XX: valor máximo de generación joven MaxNewSize, -Xmn es equivalente a configurar -XX: NewSize y -XX: MaxNewSize con el mismo valor
- -XX: NewRatio establece la relación entre la generación joven y la generación anterior. Si es 3, la relación entre la generación joven y la generación anterior es 1: 3 y el valor predeterminado es 2.
- -XX: SurvivorRatio La relación entre la generación joven y los dos Supervivientes, el valor predeterminado es 8, lo que significa que la relación es 8: 1: 1
- -XX: PretenureSizeThreshold Cuando el objeto creado excede el tamaño especificado, asigne directamente el objeto en la generación anterior.
- -XX: MaxTenuringThreshold establece el umbral de edad máximo para que los objetos se repliquen en Survivor y se transfiere a la vejez más allá del umbral.
- -XX: MaxDirectMemorySize Cuando la memoria fuera del montón asignada por Direct ByteBuffer alcanza el tamaño especificado, se activa Full GC
Afinación
- Para imprimir registros para facilitar la resolución de problemas, es mejor habilitar los registros de GC. La habilitación de registros de GC tiene un impacto mínimo en el rendimiento, pero puede ayudarnos a solucionar y localizar problemas rápidamente. -XX: + PrintGCTimeStamps -XX: + PrintGCDetails -Xloggc: gc.log
- Por lo general, establezca -Xms = -Xmx para obtener un tamaño fijo de memoria de montón, reducir el número de GC y consumir mucho tiempo, y hacer que el montón sea relativamente estable
- -XX: + HeapDumpOnOutOfMemoryError permite que la JVM genere automáticamente una instantánea de la memoria cuando se produce un desbordamiento de la memoria, lo cual es conveniente para la resolución de problemas
- -Xmn establece el tamaño de la generación joven, demasiado pequeño aumentará YGC, demasiado grande reducirá el tamaño de la generación anterior, generalmente establecido en 1/4 a 1/3 de todo el montón
- Establezca -XX: + DisableExplicitGC para deshabilitar el sistema System.gc () para evitar que la activación manual de FGC cause problemas
- FINAL -