Directorio de artículos
Redis
Prefacio
Debido a la prueba de estrés anterior, el rendimiento del análisis y la obtención de información de la página de inicio es muy bajo. Para esto, optimizamos la lógica, cambiamos varias consultas a la base de datos a una consulta y luego juntamos los datos que queremos en la lógica de Java. , Y luego realizó una prueba de esfuerzo. Aunque el rendimiento ha mejorado, sigue siendo insatisfactorio. Más tarde, se agregó un índice al campo de la base de datos y también se mejoró el rendimiento, pero el cambio no fue grande. Optimice la caché. Básicamente, la página de inicio tiene más lecturas y menos escrituras. Para adaptarse a este escenario empresarial, puede utilizar el esquema de agregar caché.
Coloque parte de los datos en la caché para acelerar el acceso, mientras que la base de datos es responsable de la ubicación de los datos.
Primero, debemos considerar qué datos deben colocarse en el caché:
- Los requisitos de inmediatez y consistencia de los datos no son altos, como logística, clasificación de productos, lista de productos, etc., que son adecuados para el almacenamiento en caché y un tiempo de caducidad (según la frecuencia de actualización de los datos).
- Datos con gran cantidad de visitas y baja frecuencia de actualización, que es lo que solemos llamar el escenario de más lectura y menos escritura. Por ejemplo, es aceptable que el comprador vea la noticia en 5 minutos cuando el producto sale al mercado en segundo plano.
Para los datos que requieren alta inmediatez, consistencia de datos o datos actualizados con frecuencia, ¡vaya a la base de datos para verificar!
Agregar lógica de caché
Primero solucionemos la lógica de agregar caché
- En primer lugar, ¿qué estamos agregando al caché? Si todo el proyecto se implementa en java, entonces podemos usar directamente la serialización jdk y almacenarlo en redis, pero en un proyecto grande, tenemos que considerar varios problemas como la compatibilidad multiplataforma y el lenguaje cruzado, por lo que usamos json string Almacenado en forma de, porque json es compatible con varios idiomas y plataformas
- La lógica de guardar es convertir primero el objeto en una cadena json y almacenarlo en redis. La lógica de buscar es invertir la información obtenida de redis. Este es el proceso de serialización y deserialización.
Hay un episodio al usar redis
Al completar la lógica básica, realicé una prueba de esfuerzo y se produjo una excepción de desbordamiento de memoria fuera del montón. Las razones específicas son las siguientes:
- Después de SpringBoot 2.0, la lechuga se usa como cliente de redis por defecto, y usa netty para la comunicación de red en la parte inferior.
- El error de la lechuga provocó un desbordamiento de la memoria fuera del montón. Cuando aumenté el parámetro de inicio de jvm -Xmx, descubrí que el problema aún no estaba resuelto. Tarde o temprano, se produciría una excepción porque el desbordamiento de la memoria fuera del montón no era la memoria en el montón, sino la memoria fuera del montón. Eso se puede configurar a través de -Dio.netty.maxDirectMemory, pero encontrará que las excepciones seguirán apareciendo.Su función es aumentar la memoria, no desde la raíz.
- Solución: (1), actualice el cliente Lettuce (2) cambie a Jedis; utilicé la segunda solución
Hasta ahora, ¿crees que el almacenamiento en caché es suficiente? La respuesta es, por supuesto, no, en el caso de alta concurrencia, si solo una operación de este tipo, traerá una serie de problemas.
Por ejemplo: penetración de caché, avalancha de caché, desglose de caché, déjame hablar sobre cómo lo resolví en el proyecto
Problemas comunes de almacenamiento en caché y mis soluciones en el proyecto
Déjame explicarte el concepto primero:
- Penetración de caché: Es para consultar un dato que no está en el caché y que no está en la base de datos. Es atacado maliciosamente por criminales. Es para consultar un dato que no existe. De repente enviará cientos de miles de solicitudes a la base de datos. Colapsado
- Avalancha de caché: esto es para un lote de claves en la caché que caducan al mismo tiempo, y cientos de miles de solicitudes concurrentes vienen a solicitar estos datos, luego la solicitud se enviará a la base de datos, lo que provocará que la base de datos se bloquee, lo que es Efecto avalancha
- Desglose de la caché: la clave de un determinado punto caliente extremo en la caché expira en un momento determinado. Se trata de una solicitud simultánea de cientos de miles de llamadas a la base de datos, lo que hace que la base de datos se caiga.
solución:
- Penetración de caché: (La solución que tomé es almacenar en caché un valor nulo y establecer un tiempo de vencimiento corto)
- Al almacenar en caché un valor nulo y agregar un tiempo de vencimiento
- A través del filtro Bloom se bloquean los datos que no existen en absoluto, pero este esquema tendrá ciertos errores de juicio
- Avalancha de caché:
- Para hacer frente a una gran cantidad de claves que caducan al mismo tiempo, podemos agregar un valor aleatorio al establecer el tiempo de caducidad para tratar
- Desglose de la caché:
- Se realiza mediante el bloqueo. Cuando entra una gran cantidad de solicitudes, el método de bloqueo se utiliza para permitir que un determinado hilo vaya a la base de datos para verificar y luego poner los datos detectados en la caché
Eche un vistazo a mi código:
//去数据库中查的业务逻辑
private Map<String, List<Catelog2Vo>> getDataFromDb() {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");
if (!StringUtils.isEmpty(catalogJson)) {
//缓存不为空直接返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库");
/**
* 将数据库的多次查询变为一次
*/
List<CategoryEntity> selectList = this.baseMapper.selectList(null);
//1、查出所有分类
//1、1)查出所有一级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
//封装数据
Map<String, List<Catelog2Vo>> parentCid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(category3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、将查到的数据放入缓存,将对象转为json
String valueJson = JSON.toJSONString(parentCid);
stringRedisTemplate.opsForValue().set("catalogJson", valueJson, 1, TimeUnit.DAYS);
return parentCid;
}
/**
* 从数据库查询并封装数据::本地锁
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithLocalLock() {
// //如果缓存中有就用缓存的
// Map<String, List<Catelog2Vo>> catalogJson = (Map<String, List<Catelog2Vo>>) cache.get("catalogJson");
// if (cache.get("catalogJson") == null) {
// //调用业务
// //返回数据又放入缓存
// }
//只要是同一把锁,就能锁住这个锁的所有线程
//1、synchronized (this):SpringBoot所有的组件在容器中都是单例的。
//TODO 本地锁:synchronized,JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
return getDataFromDb();
}
}
Al ver el código anterior, ¿cree que establecer un bloqueo local no es un problema? Si es una sola aplicación, está completamente bien, pero para proyectos distribuidos, todavía hay algunos problemas. Permítanme mostrarles una imagen:
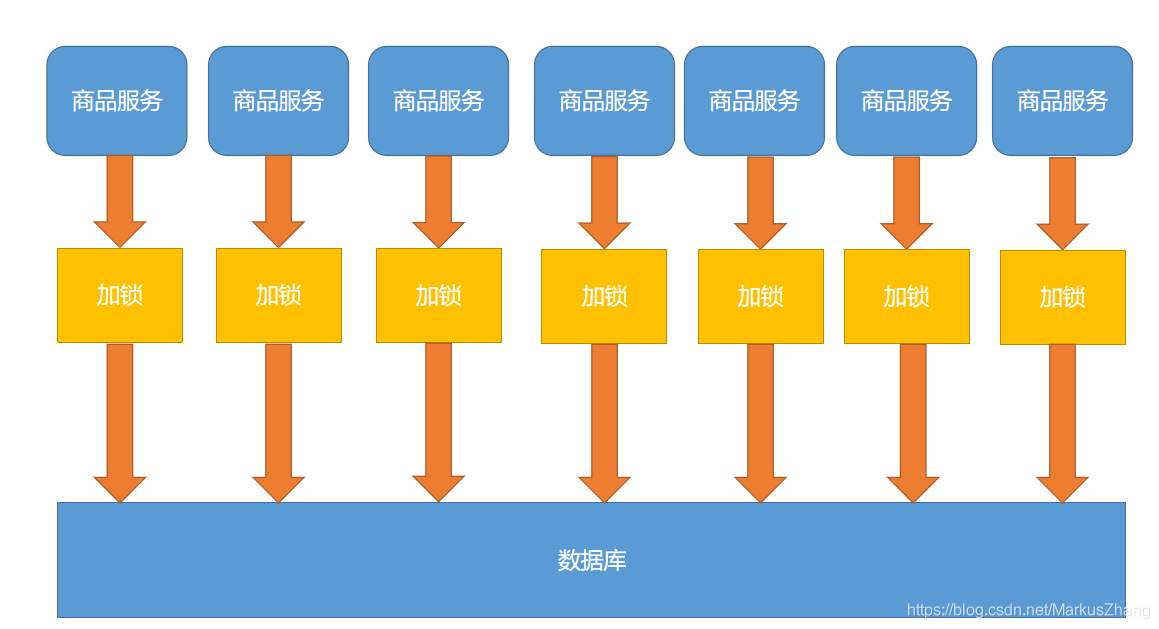
Nuestro proyecto es un proyecto de clúster distribuido. Por supuesto, un servicio debe tener muchos servidores. Supongamos que llamamos a 100,000 solicitudes y las solicitudes a cada servidor después del balanceo de carga son 10,000 solicitudes. Al mismo tiempo, se considera que no hay ninguna en la caché, entonces Cada servidor enviará una solicitud a la base de datos. Si hay pocos servidores, todavía está bien, pero no está en línea con nuestra intención original. Solo queremos verificar la base de datos una vez, y las solicitudes posteriores se transferirán a redis. ¡Entonces podemos usar bloqueos distribuidos para resolver!
¿Cómo se diseña la cerradura distribuida? Hagamos un dibujo para entender mejor
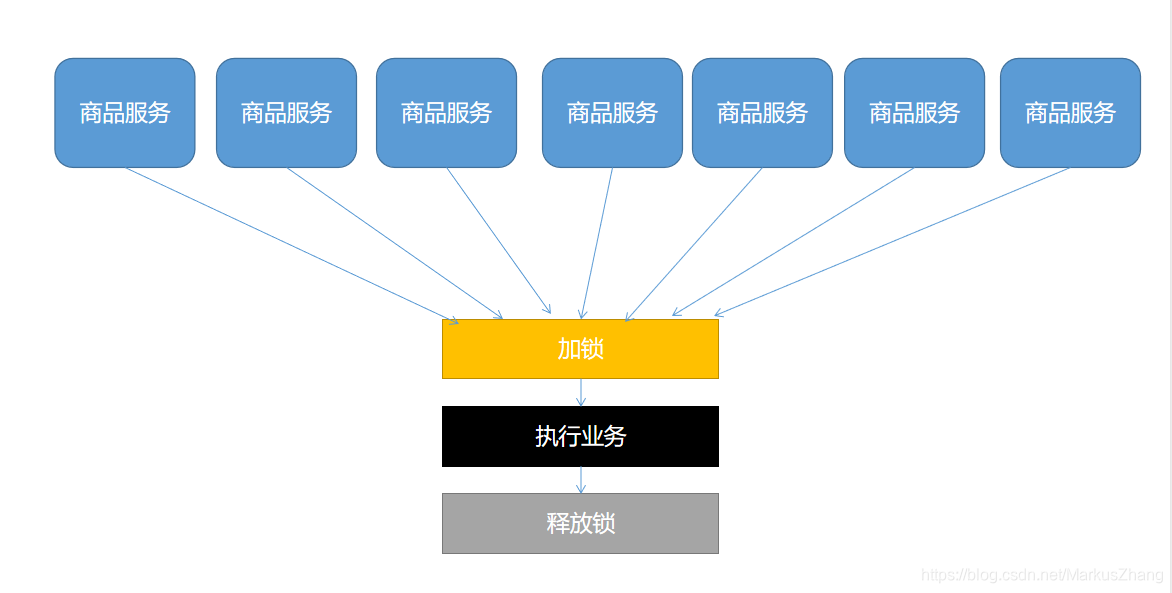
En términos sencillos, podemos ir al mismo lugar para "ocupar el hueco", y si lo hacemos, ejecutaremos la lógica. De lo contrario, debe esperar hasta que se libere el bloqueo. Ocupar el candado puede ir a redis, puede ir a la base de datos, puede ir a cualquier lugar al que todos puedan acceder, esperando poder usar el método de giro.
Mi plan es llevar el candado en redis, es un producto que implementa naturalmente candados distribuidos, con sus instrucciones se pueden realizar candados distribuidos.
set key value ex|px nx|xx;
// 我们可以采用这个指令:
set key value ex nx;
// 也就是当这个键不存在的是设置锁
¿Cómo realizar este candado distribuido?
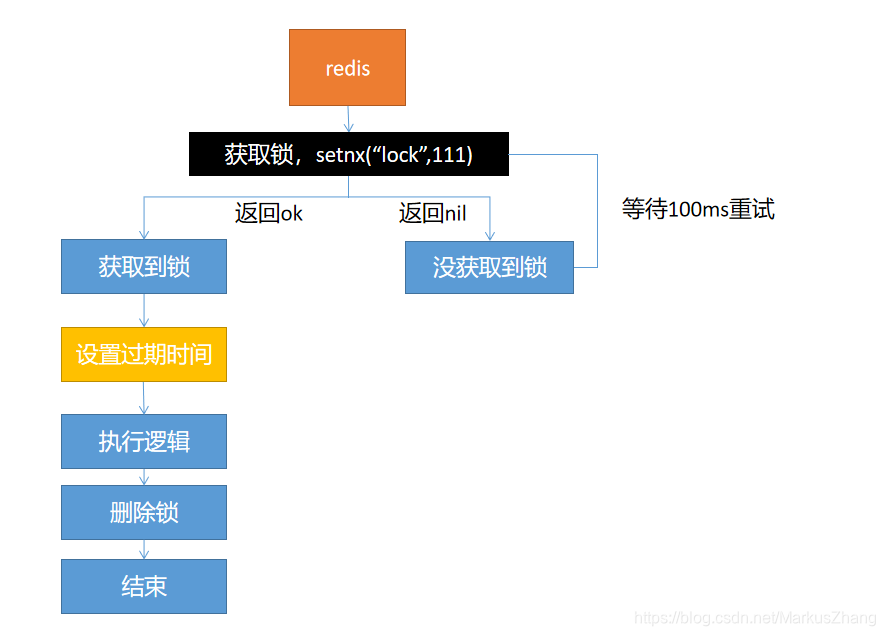
Opcion uno:

Con este esquema de diseño, habrá un problema: cuando el hilo adquiere el bloqueo y luego ejecuta la lógica de negocio y se prepara para eliminar el bloqueo, de repente el servidor se cae, lo que hará que el bloqueo siempre exista, y causará la muerte si no se puede liberar. La situación de la cerradura.
La solución es: establecer un tiempo de vencimiento, incluso si el servidor está inactivo y no se puede liberar manualmente, se puede liberar automáticamente después de la fecha de vencimiento
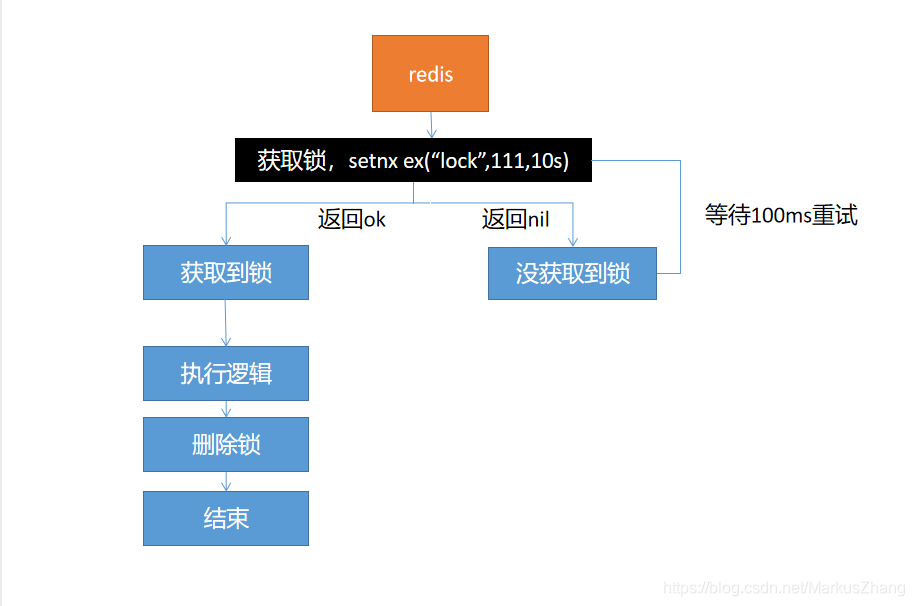
Opción II:
El problema de la solución uno está resuelto, pero aún habrá problemas, si vamos a establecer el tiempo de caducidad luego de adquirir el bloqueo, el servidor está caído en este momento, lo que también provocará un interbloqueo.
Solución: asegúrese de que la adquisición de bloqueos y la configuración del tiempo de vencimiento sean atómicos, y el comando setnx ex puede garantizar la atomicidad
tercera solución:
Esta solución resuelve la atomicidad de establecer bloqueos, pero al eliminar bloqueos, ¿deberían eliminarse directamente? Cuando nuestro tiempo de ejecución comercial es muy largo, se asume que el bloqueo ha expirado y otros subprocesos han adquirido el bloqueo. Después de que el subproceso anterior haya ejecutado el negocio, para eliminar el bloqueo, se eliminará el bloqueo de otros.
Solución: especifique su propio UUID al configurar el bloqueo. Después de ejecutar el negocio, obtenga el bloqueo y verifique si lo configuró usted mismo antes. Si lo configuró usted mismo, elimínelo, de lo contrario omítalo y asegúrese de eliminar el bloqueo. Atomicidad, ¿por qué? Si obtenemos el bloqueo que establecimos antes, pero aún hay un período de tiempo entre la obtención del valor y la eliminación del bloqueo, si el bloqueo falla durante este período y alguien más obtiene el bloqueo, seguiremos pensando que el bloqueo somos nosotros. , Dará lugar a una eliminación accidental.
Opción cuatro:
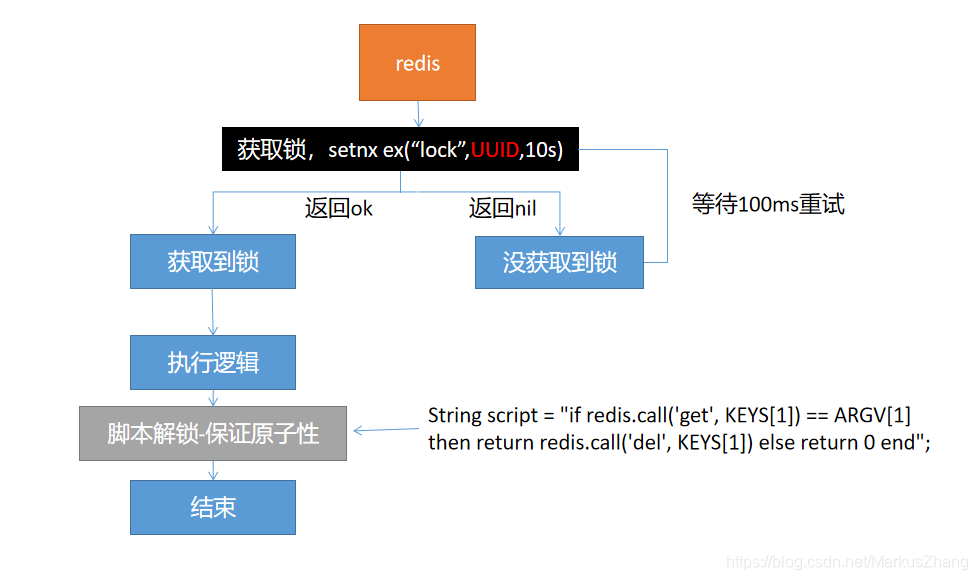
La opción cuatro es la solución definitiva. En resumen, ¡es necesario asegurar la atomicidad al adquirir y eliminar cerraduras!
Luego vino un enlace clave: ¿cómo resolver la coherencia de los datos de la caché?
Hay dos opciones:
- Modo de escritura doble
- Modo de fallo
Hagamos un dibujo y analicemos el flujo de trabajo del modo de escritura dual:

Hagamos un dibujo para analizar el flujo de trabajo del modo de falla:

De hecho, estos dos esquemas causarán inconsistencia en los datos. Por ejemplo, en el modo de escritura doble, dos solicitudes de escritura entran una tras otra. Después del procesamiento, la caché de escritura se debe a demoras en la red y otras razones. La primera solicitud de escritura se escribe en la caché, lo que da como resultado una inconsistencia de datos, y los datos en la caché no son los datos más recientes; por ejemplo, en el modo de falla, mire la imagen para saber que cuando no he completado la segunda solicitud de escritura , Fui a leer el caché, pero no lo leí, y luego lo revisé en la base de datos. Cuando lo leí, asumiendo que la segunda solicitud no se ha completado, cuando se complete la segunda solicitud, elimine el caché y volveré a actualizar al caché. Causar problemas de inconsistencia de datos.
¿Cómo podemos solucionar los problemas anteriores?
solución:
- Si se trata de datos de latitud del usuario (datos de pedido, datos del usuario), la posibilidad de esta simultaneidad es muy pequeña, por lo que no es necesario considerar el problema de la inconsistencia de los datos. Los datos almacenados en caché más el tiempo de vencimiento se pueden activar cada vez para leer y actualizar activamente
- Si se trata de datos básicos como menús e introducciones de productos, también puede usar canal para suscribirse a binlog. La información en la base de datos se cambia y canal recopila la información, realiza algún procesamiento y luego se sincroniza con redis.
- Los datos almacenados en caché + el tiempo de caducidad son suficientes para resolver la mayoría de los requisitos comerciales de almacenamiento en caché
- Si hay un poco más de operaciones de escritura, podemos garantizar lecturas y escrituras simultáneas bloqueando, alineando al escribir y escribiendo, asegurando el orden y sin bloqueo durante la lectura, por lo que se utilizan bloqueos de lectura y escritura (el negocio no está relacionado con los datos del corazón , Permitiendo que se ignoren los datos sucios temporales)
Aquí hay un resumen
Dicho esto, ¡resumámoslo!
Los datos que podemos poner en la caché no deberían requerir una alta consistencia de datos en tiempo real. Por lo tanto, agregue el tiempo de vencimiento al almacenar datos en caché para asegurarse de obtener los datos más recientes todos los días. No debemos sobre-diseñar y aumentar la complejidad del sistema, cuando nos encontramos con datos con altos requisitos de consistencia y tiempo real, debemos consultar la base de datos, más lento que más lento.