Directorio de artículos
Prefacio
Mirando hacia atrás en el proyecto b2c anterior, en el área de servicio de pedidos, implica el problema de las transacciones distribuidas. El escenario es el siguiente: cuando se envía un pedido, se debe crear un pedido y se debe llamar al servicio de inventario remoto para bloquear el inventario y esperar hasta el pago Después del éxito, el inventario bloqueado se reducirá. Cuando se trata de llamadas remotas, puede haber inconsistencias en el estado de las dos transacciones.
Transacción local y transacción distribuida
Simplemente pon
Transacción local: Es una transacción dentro de un servicio.
Transacción distribuida: Bajo microservicios, involucra llamadas entre múltiples servicios. En este momento, es necesario mantener la consistencia de transacciones bajo múltiples servicios. Esta es la categoría de transacciones distribuidas Arriba.
Asuntos locales
Repasemos los puntos de conocimiento relevantes de los asuntos locales:
las características de los asuntos: (ACID)
- R: Atomicidad, es decir, todas las operaciones de una transacción se ejecutan correctamente o todas fallan.
- C: consistencia, es decir, los datos generales de la operación antes y después de la transacción son consistentes
- I: Aislamiento, es decir, transacciones y operaciones transaccionales no se afectan entre sí.
- D: Persistencia, es decir, una vez que se completa la transacción, se conservará en el disco para su almacenamiento permanente y no se perderá.
Nivel de aislamiento de la transacción:
| Preparar | descripción |
|---|---|
| Serializable | Puede evitar la ocurrencia de lectura sucia, lectura no repetible y lectura virtual. (Publicación por entregas) |
| Lectura repetible | Puede evitar la aparición de lecturas sucias y lecturas no repetibles. (Puede leerse repetidamente) |
| Leer comprometido | Puede evitar la aparición de lecturas sucias (se han enviado lecturas). |
| Leer sin compromiso | El nivel más bajo, ninguna de las condiciones anteriores puede garantizarse. (Leer no comprometido) |
La forma de propagación de la transacción es:
En Spring, @Transactional (propagation = Propagation.REQUIRED) establece el nivel de propagación de la transacción. Esto significa que cuando se llama al método interno,
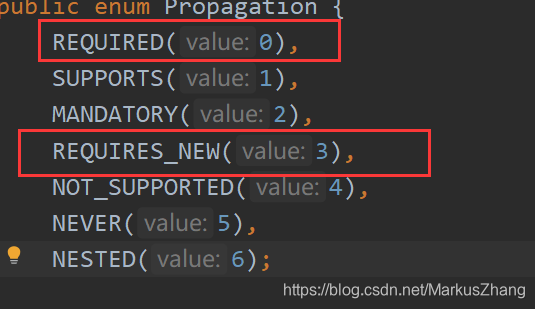
se comparte una transacción. Lo siguiente es crear una nueva transacción.
Pero hay un error al compartir una transacción, es decir, Spring usa un método de proxy cuando procesa una transacción, por lo que cuando llama a un método, debe pasar por esta clase de proxy, de lo contrario, no es una transacción.
Transacción distribuida
¿Por qué hay transacciones distribuidas?
Bajo el módulo de microservicio, es común realizar llamadas remotas entre múltiples servicios, y con él, a menudo habrá excepciones: tiempo de inactividad de la máquina, anomalías de la red, pérdida de mensajes, desorden de mensajes, errores de datos, falta de confiabilidad TCP, pérdida de datos de almacenamiento, etc., en este momento, se necesitan transacciones distribuidas para garantizar la coherencia de las transacciones globales.
Teoría CAP y teoría BASE
CAP:
- C: consistencia de datos
- A: disponibilidad del clúster
- P: La tolerancia a fallas de partición
solo puede lograr dos de estos tres puntos como máximo, y los tres no pueden tener ambos. Generalmente, debemos asegurarnos de la tolerancia a fallas de la partición y C / A depende de la situación.
BASE: - BA: Básicamente disponible: cuando ocurre una falla en un sistema distribuido, se permite perder parte de la disponibilidad, como el tiempo de respuesta y la disponibilidad funcional
- S: Estado suave: se refiere a permitir que el sistema tenga estados intermedios, lo que no afectará la disponibilidad del sistema
- E: Consistencia eventual: Significa que todas las copias de datos en el sistema pueden finalmente alcanzar un estado consistente después de un cierto período de tiempo.
Solución de transacciones distribuidas:
- Modo 2PC: una gestión total de transacciones, múltiples administradores de recursos locales. Al actualizar los datos, el administrador de transacciones primero enviará un mensaje que está listo para enviar datos, y cada administrador de recursos enviará una confirmación. Mientras no haya nadie, esta transacción de operación de datos no se puede realizar.
- Transacción flexible-TCC: cuando se revierte la transacción, los datos recuperados se revierten en el registro. (Esta pieza es incierta, obtenga más información más adelante)
- Mensaje flexible de transacción confiable + solución de consistencia eventual (tipo garantizado asíncrono) La solución en mi proyecto es así, que es enviar mensajes al servicio de mensajes de hechos después de que se procesa el negocio y antes de enviar la transacción. Realmente no enviando. Una vez que se envía la transacción, el servicio comercial confirma el envío al servicio de mensajes en tiempo real, y el servicio de mensajes en tiempo real solo lo enviará después de recibir la instrucción de envío de confirmación.
Solución de proyecto
Proceso de envío de pedidos:

Cola de retardo de RabbitMQ (implementar tareas de tiempo)
Se puede realizar una cola retrasada mediante el uso de TTL de mensajes e Intercambio de letra muerta
¿Qué es TTL de mensajes? El tiempo de supervivencia del mensaje es
lo que es Dead Letter Exchange? Una vez que un mensaje cumple las condiciones, ingresará al enrutamiento de letra muerta. De hecho, el intercambio de letra muerta aquí no es diferente de los intercambios ordinarios. Es solo que si un mensaje caduca en un determinado conjunto de cola de intercambio de letra muerta, automáticamente activará el reenvío del mensaje. Reenviar a este conmutador
Esto implementa una cola de retardo.
Mi idea es enviar una solicitud y crear un pedido después de hacer clic en el botón Enviar pedido. Una vez que el pedido se haya creado correctamente, envíe un mensaje a MQ y luego bloquee el inventario de forma remota. Después de que el inventario esté bloqueado, envíe un mensaje a MQ bajo el servicio de inventario. El resto es monitoreo. Después de 30 minutos, el mensaje de bloqueo de inventario expira. Después de recibir el mensaje para desbloquear el inventario, lo liberaré. Después de un tiempo, el mensaje de pedido expira y recibo el mensaje de pedido cerrado, así que lo desbloquearé. Inventario
A continuación, necesitamos aclarar bajo qué circunstancias es necesario desbloquear el inventario:
recibimos el mensaje de que el mensaje de bloqueo de inventario expira, este mensaje incluye: ID de orden de trabajo, detalles de inventario de bloqueo. Podemos obtener el número de pedido a través del ID de la orden de trabajo y luego llamar al módulo de pedidos de forma remota para verificar si el pedido existe. Si el pedido no existe, el inventario debe estar desbloqueado. Si es así, necesitamos ver el estado del pedido. Necesito desbloquear el inventario para el estado cancelado. Los pagos no necesitan ser desbloqueados. En el proceso de desbloqueo, también debemos mirar el estado de bloqueo en la tabla de detalles del inventario de bloqueo. Si el inventario se ha desbloqueado, no es necesario que lo desbloqueemos. Solo es necesario desbloquear el estado de bloqueo.
También necesitamos monitorear este mensaje si el pedido ha expirado y no se ha pagado, y también debemos desbloquearlo.
Sin embargo, el pensamiento anterior todavía tiene ciertos problemas. Cuando estamos desbloqueando el pedido, hay un retraso en la red y otras condiciones que hacen que el desbloqueo del inventario ocurra antes de que se desbloquee el pedido, entonces parte de la información del inventario del pedido se perderá y no se podrá desbloquear. En este caso, también monitoreamos el mensaje de cierre del pedido en el servicio de inventario. Después de recibir el mensaje de cierre del pedido, desbloqueamos el inventario y luego desbloqueamos el inventario que no estaba desbloqueado.
Bueno, algunas de las estrategias que hemos adoptado cuando el mensaje expira arriba incluyen: consumimos mensajes que no han sido pagados cuando el pedido vence, cerramos la operación de servicio del pedido y realizamos el mensaje de que el servicio de inventario vence y no encuentra ningún pedido o el estado del pedido está cancelado. Al final, también garantiza evitar esta situación: evitar que el servicio de pedidos se atasque, lo que hace que el mensaje de estado del pedido permanezca inmutable, la prioridad de inventario caduca, el estado del pedido se crea nuevamente y no se procesa nada, lo que provoca que el pedido se bloquee. El problema del inventario nunca se puede desbloquear.
Después de resolver la consistencia final, ¿cómo asegurar la confiabilidad del mensaje?
Las noticias no son fiables y cualquier operación es una nube. ¿Qué pasa si el mensaje se pierde mientras estamos transmitiendo el mensaje en la red? Las principales razones de la pérdida de mensajes son las siguientes:
- El mensaje se envió pero no llegó al servidor por motivos de red: esta situación es inevitable. Necesitamos almacenar la información del registro en la base de datos. Después de que el diseño falla, tenemos un mecanismo de retransmisión y escaneamos periódicamente la base de datos en busca de estos mensajes fallidos. .
- Cuando el mensaje llega al Broker, el Broker debe conservar el mensaje en el disco para que se considere exitoso. Si la persistencia no es exitosa, el broker está inactivo y el mensaje se perderá. En este momento, debemos confirmar el mecanismo de devolución de llamada para que el editor confirme el mensaje exitoso. Modifique el estado del mensaje de la base de datos.
- En el estado ACK automático, el consumidor recibe el mensaje, pero no hay tiempo para confirmar la respuesta. Si la máquina está inactiva, el mensaje se perderá. En este momento, debemos habilitar la confirmación manual para eliminar correctamente el mensaje; de lo contrario, el mensaje se devolverá a la cola.
Para la repetición de mensajes, podemos diseñar una tabla anti-peso en la base de datos, y solo se consumirá la información que no haya sido manipulada, o podemos diseñarla para que sea idempotente en nuestro negocio.
Para la acumulación de mensajes: puede conectarse en línea con más consumidores; también puede conectarse con una cola dedicada a procesar mensajes, monitorear estos mensajes y almacenarlos en datos en lotes, y luego procesar estos mensajes en la base de datos en un programa fuera de línea.
para resumir
En resumen, en el proceso de hacer esto, es muy difícil. Necesitamos considerar varias situaciones. Tal vez haya problemas debajo de estas cosas en las que pienso. Esto requiere acumular experiencia lentamente. Para consultar la base de datos, podemos Agregue almacenamiento en caché para resolver el problema de los datos almacenados en caché inconsistentes y mejorar el rendimiento del sistema. Debe tener cuidado al modificar los mensajes de la base de datos.