Introducción
Si sabe cocinar, entonces el búfer de aprendizaje del 50% incorporado es una broma. En realidad, el procesamiento del proceso de big data es lo mismo que cocinar. Si comprende el proceso, veamos cómo lo aprendemos. Big data hará más con menos.
Si ya conoce los diversos marcos de big data y desea obtener beneficios directamente, puede pasar directamente a la sección 3.2 o 3.3 para obtener información relevante.
Tabla de contenido
-
Alimentos y big data
-
Flujo de procesamiento de big data
2.1 Recolección de datos
2.2 Almacenamiento de datos
2.3 Análisis de datos
2.4 Aplicación de datos
2.5 Otros marcos
-
Ruta de aprendizaje
3.1 Marco de aprendizaje
3.2 Recolección de datos
3.3 Bienestar
1 Alimentos y big data
Imagina que el proceso de procesamiento de big data es como preparar una comida gourmet. Debes seguir los siguientes pasos:
1、食材采购————菜市场去批量采购不同类型的食材:
猪肉、蔬菜、干货等
2、食材收藏————采购后将这些菜按照类型放到不同区域:
冰箱冷藏区、冰箱冷冻区、干货区
3、食材预处理————不同食材需要进行处理:
蔬菜清洗、猪肉切丝切片、调料剁碎
4、食材加工————爆炒猪肝、清蒸鲈鱼、红烧五花肉...Los alimentos son el procesamiento de ingredientes, por lo que los marcos de big data son el procesamiento de datos:
Adquisición de ingredientes alimentarios: recopilación de datos,
Almacenamiento de datos de recolección por lotes,
Preprocesamiento de datos de preprocesamiento de alimentos,
Aplicación de datos de material alimentario procesado.
2 Flujo de procesamiento de Big Data
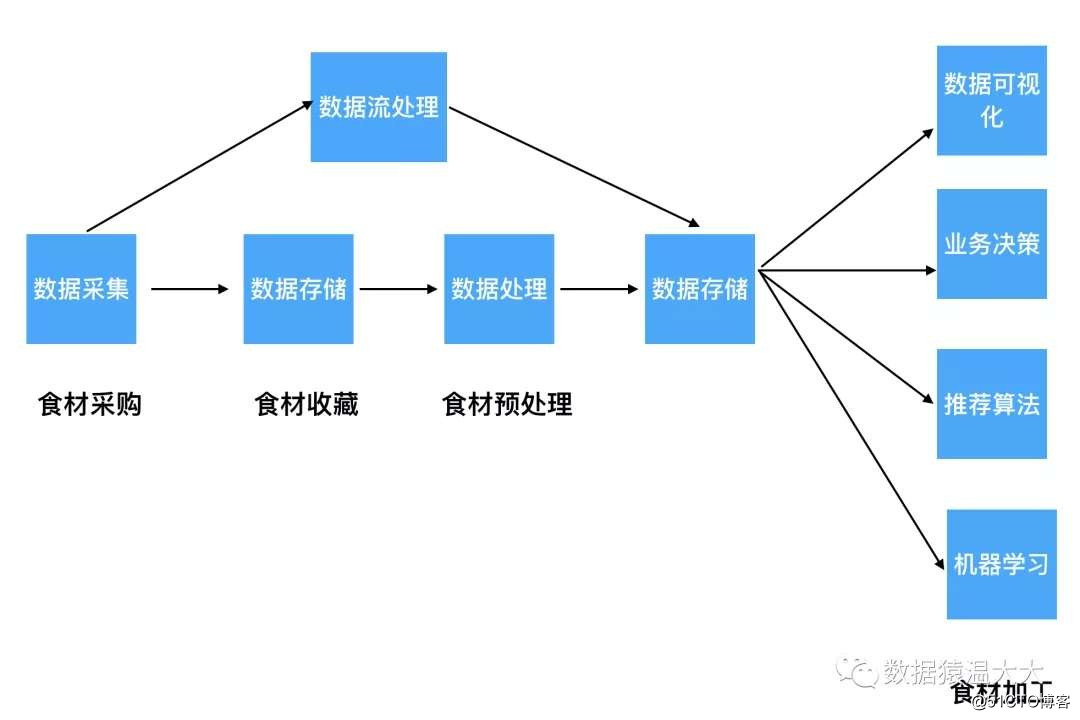
2.1. Recopilación de datos (compra de alimentos)
Al igual que existen diferentes ingredientes en el mercado de las verduras, iremos a diferentes áreas para comprar:

Entonces, la recopilación de datos también es la misma. Generalmente, puede recopilar los registros en el servidor. La forma más estúpida que puede utilizar es exportar todos los registros en el servidor, pero generalmente los proyectos a gran escala se implementan de manera distribuida y no se pueden exportar debido a su comportamiento. Interfiere con el funcionamiento normal del servidor, por lo que en función de esta demanda,
Nacieron algunas herramientas de recopilación de registros: Flume, Logstash, Kibana, pueden recopilar y procesar datos complejos a través de una configuración simple.
2.2. Almacenamiento de datos (recolección de alimentos)
Al igual que almacenamos diferentes ingredientes, los colocaremos en la toallita fría del refrigerador, en el área del congelador o en el área de productos secos según los atributos y tamaño de los ingredientes:
Lo mismo se aplica al almacenamiento de datos. Sabemos que los datos se dividen en datos estructurados, datos semiestructurados y datos no estructurados:
2.2.1. Los datos estructurados tienen este aspecto:
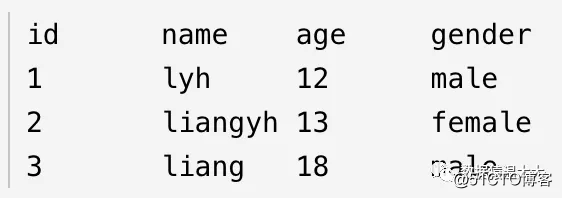
Explicación: Los datos estructurados se representan y almacenan en bases de datos relacionales. Por ejemplo, los datos que almacenamos en tablas mysql y Oracle son datos estructurados.
2.2.2. Los datos semiestructurados se ven así:

Explicación: Los datos semiestructurados son una forma de datos estructurados. XML y JSON que usamos habitualmente son datos semiestructurados comunes.
2.2.3. Los datos no estructurados son todo tipo de documentos, imágenes, video / audio, pero se almacenan en binario, se ve así:

Explicación: Los datos no estructurados son todo tipo de documentos, imágenes, video / audio.
Los datos estructurados generalmente se almacenan a través de bases de datos relacionales, como MySQL y Oracle, su ventaja radica en un almacenamiento rápido y un acceso rápido.
Para procesar datos semiestructurados (datos de registro) y no estructurados (datos de audio, imagen, video), nació: GFS, sistema de procesamiento de archivos HDFS, su ventaja radica en el procesamiento: puede manejar una gran cantidad de datos estructurados, semiestructurados, no estructurados Los datos estructurados, debido a que no pueden acceder a los datos de forma aleatoria, se han convertido en un problema de velocidad de acceso total. Para heredar las ventajas del acceso aleatorio rápido de las bases de datos relacionales + y retener el procesamiento masivo de datos no estructurados, finalmente nacieron Hbase y MongoDB.
2.3. Procesamiento de datos (pretratamiento de alimentos)
Una vez recolectados los ingredientes, preprocesamos los ingredientes en lotes: lavando hojas de vegetales, lonchas de cerdo / desmenuzado, jengibre y rodajas de ajo:

Big Data también preprocesará los datos y realizará etl (limpieza, conversión y carga) en los datos por adelantado. Según los diferentes escenarios de aplicación, se divide en procesamiento por lotes y procesamiento de flujo:
-
Procesamiento por lotes: procesamiento de datos sin conexión, por ejemplo: generamos un informe de los datos del producto comprado por el usuario hace 1 año. En este momento, la puntualidad de los datos no es alta, por lo que el procesamiento por lotes correspondiente. Los marcos de procesamiento incluyen Hadoop MapReduce, Spark, Flink Espere
- Procesamiento de flujo: procese datos en tiempo real, por ejemplo: consulte los datos actuales del inventario de productos básicos. En este momento, la puntualidad de los datos es muy alta, por lo que el procesamiento correspondiente es el flujo, es decir, los datos se procesan al mismo tiempo que se reciben los datos. El marco de procesamiento tiene Storm , Spark Streaming, Flink Streaming, etc.
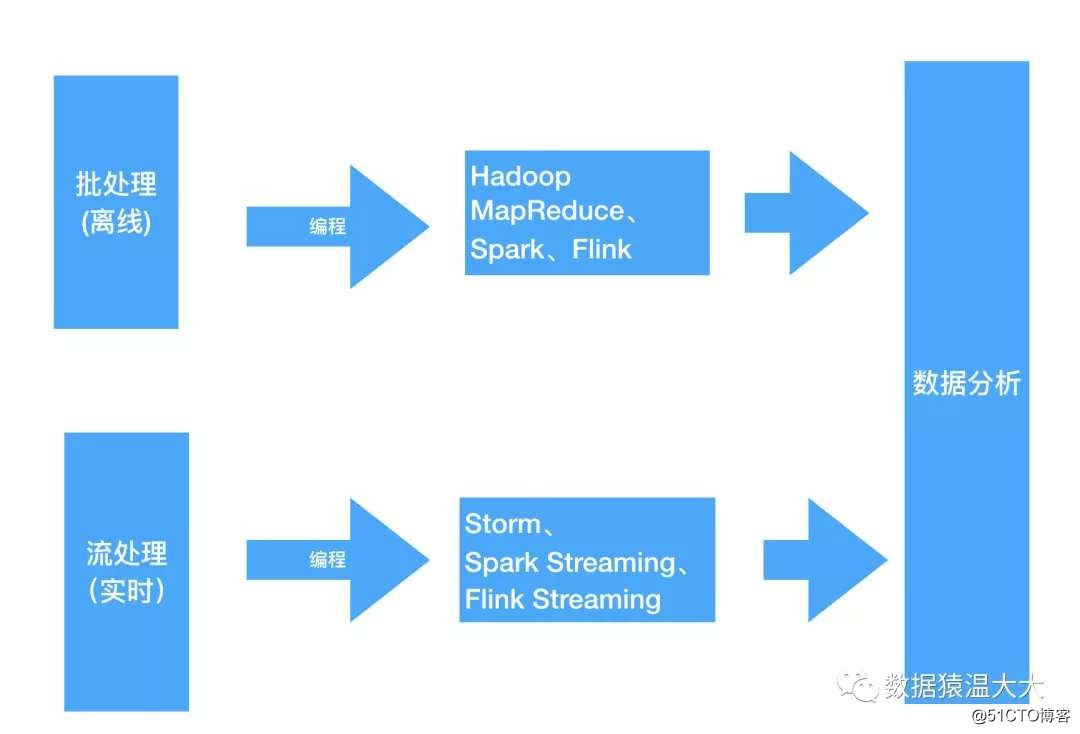
Si los estudiantes que conocen algo de programación pueden preprocesar los datos a través del marco anterior,
Entonces, ¿si los estudiantes que no entienden la programación deben aprender el marco anterior? ———— La respuesta es No. Para permitir que las personas que están familiarizadas con sql también analicen datos, se crearon marcos de consulta ———— Hive, Spark SQL, Flink SQL, Pig, Phoenix y otros marcos.
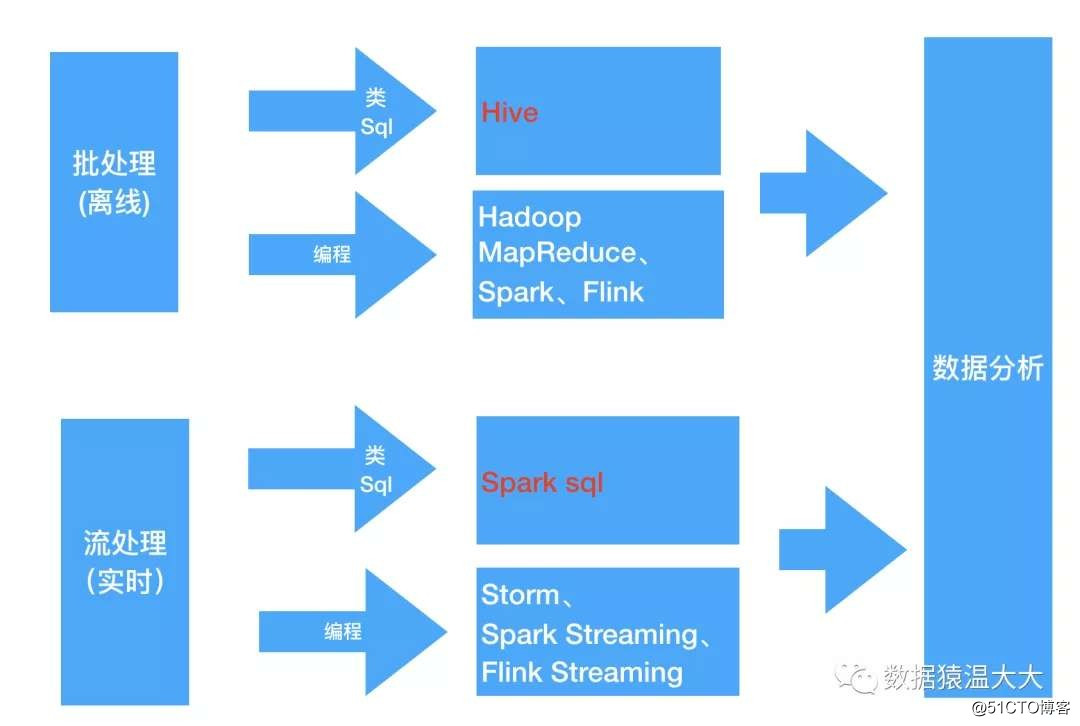
Estos marcos de consulta admiten el uso de gramática SQL estándar o gramática similar a SQL para consultar datos. Después del análisis de SQL, se convierte en los trabajos correspondientes. Hive básicamente convierte SQL en trabajos MapReduce. Spark SQL convierte SQL en una serie de RDD y Transformaciones
2.4 Aplicación de datos (procesamiento de alimentos)
Los ingredientes procesados se procesan, estofan, cuecen al vapor, se fríen y luego se les pone nuestro sabor de sal favorito, y finalmente se sacan de la olla y se sirven: 
Para el procesamiento final de big data, podemos convertir los datos preprocesados en el producto que queremos y utilizar los datos para optimizar su algoritmo de recomendación.
Ejemplos: recomendación personalizada de video corto, recomendación de producto de comercio electrónico, recomendación de noticia de título
Para lograrlo, se utilizarán algunos algoritmos. Los dos algoritmos más utilizados en el campo del comercio electrónico son los siguientes:
- Algoritmo de recomendación de contenido:
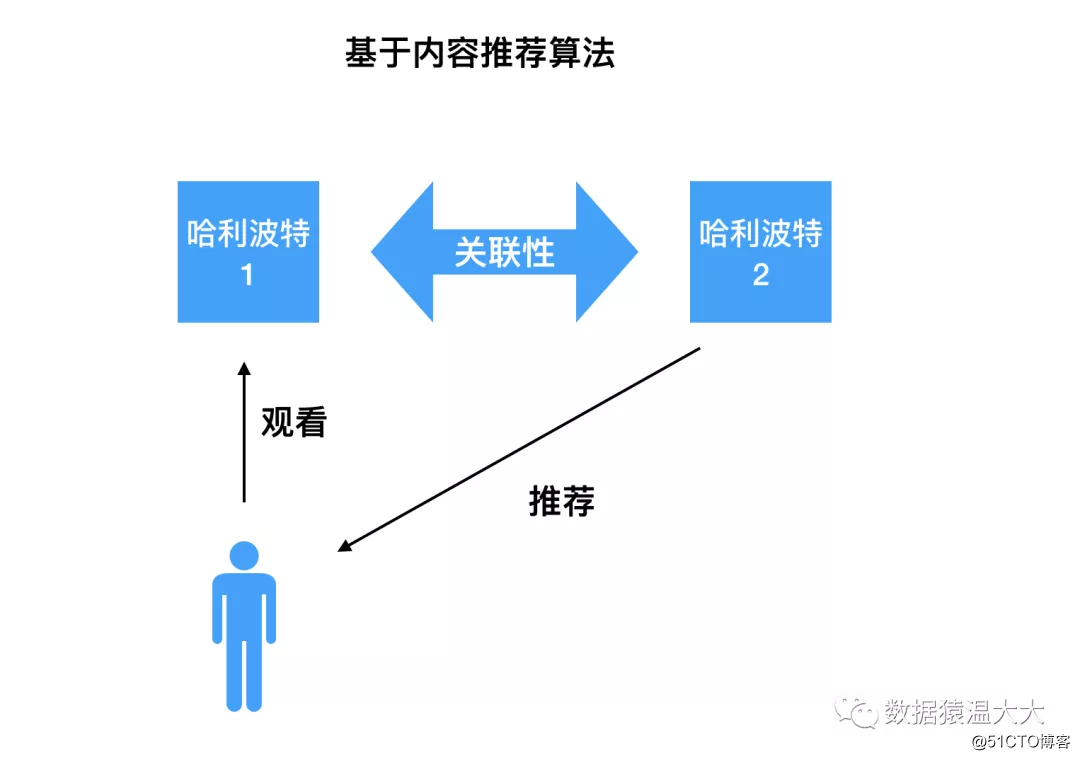
Principio: A los usuarios les gustan los elementos que son similares en contenido a los elementos que han seguido
Ejemplo: por ejemplo, si miras Harry Potter 1, el algoritmo de recomendación basado en contenido encuentra que Harry Potter 2 está estrechamente relacionado con el contenido que miraste antes (hay muchas palabras clave), así que recomiéndalo. tú.
- Algoritmo de recomendación de filtrado colaborativo
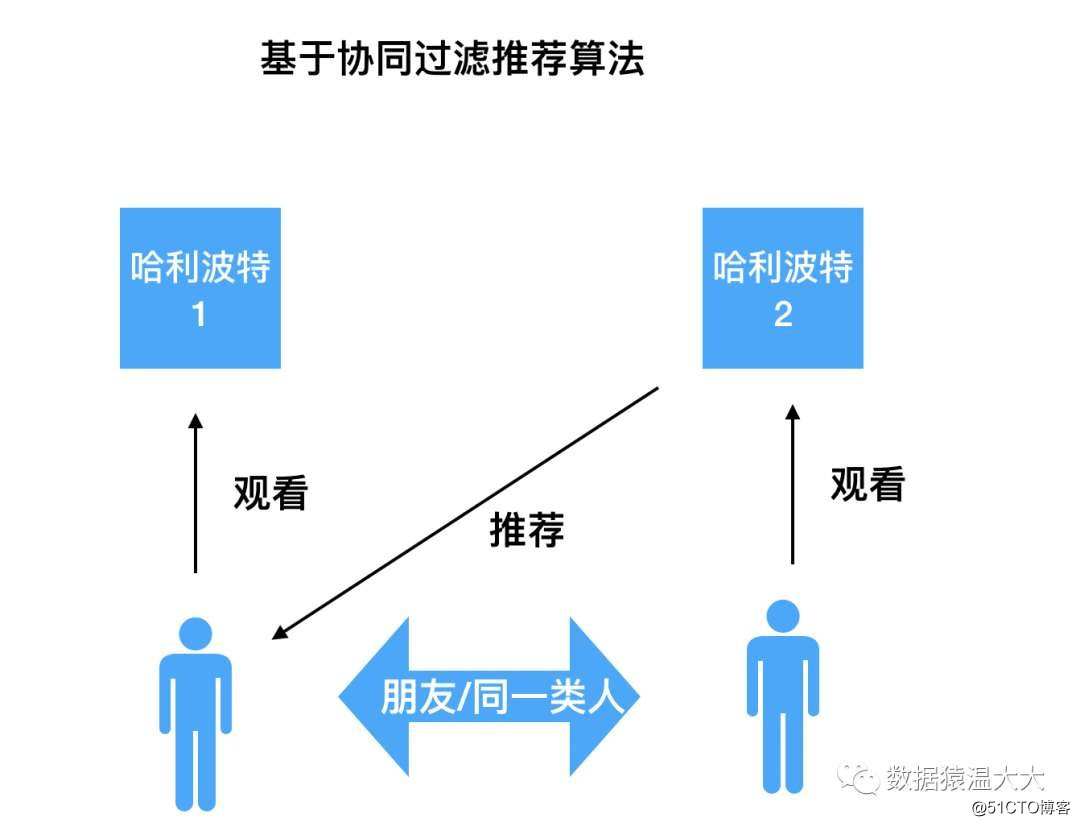
Principio: A los usuarios les gustan los productos que les han gustado a usuarios con intereses similares,
Ejemplo: a tu amigo le gusta la película Harry Potter 2 y luego te la recomendará. Este es el algoritmo de filtrado colaborativo más simple basado en el usuario.
2.5. Otros marcos
El anterior es el marco técnico utilizado para el proceso de procesamiento de big data. De hecho, los siguientes marcos se utilizan en los escenarios de agrupación de big data (instalación y monitoreo), migración de datos y alta concurrencia:
- Agrupación de plataformas de big data:
instalación
Con el fin de facilitar la implementación, monitoreo y administración de clústeres, se derivan herramientas de administración de clústeres como Ambari y Cloudera Manager
Asignación de recursos
Para garantizar la alta disponibilidad del clúster, debe utilizar ZooKeeper. ZooKeeper es el servicio de coordinación distribuida más utilizado. Puede resolver la mayoría de los problemas del clúster, incluida la elección del líder, la recuperación de fallas, el almacenamiento de metadatos y su garantía de coherencia. Al mismo tiempo, en respuesta a las necesidades de gestión de recursos del clúster, se derivó Hadoop YARN;
Programación de tareas
Múltiples trabajos complejos que dependen unos de otros: en base a esta demanda, han surgido marcos de programación de flujo de trabajo como Azkaban y Oozie
- migración de datos:
A veces, necesita migrar datos de una base de datos relacional a HDFS, o de HDFS a una base de datos relacional, necesita usar el marco de trabajo Sqoop
- Problemas de concurrencia:
Cuando la simultaneidad es muy alta, cuando los datos no se pueden escribir directamente en HDFS, el marco de Kafka debe usarse para almacenar los datos en una cola y luego consumirlos lentamente.
3 Ruta de aprendizaje
Cuando descubramos qué problema resuelve cada marco y está en la parte del procesamiento de big data, aprenderemos este marco nuevamente y será el doble del resultado con la mitad del esfuerzo.
- Clasificación de cuadros
Marco de recopilación de registros: Flume, Logstash, Filebeat
Sistema de almacenamiento de archivos distribuido: Hadoop HDFS
Sistema de base de datos: Mongodb, HBase
Marco de computación distribuida:
Marco de procesamiento por lotes: Hadoop MapReduce
Marco de procesamiento de transmisión: Storm
Marco de procesamiento híbrido: Spark, Flink
Marco de análisis de consultas: Hive, Spark SQL, Flink SQL, Pig, Phoenix
Administrador de recursos del clúster: Hadoop YARN
Servicio de coordinación distribuida: Zookeeper
Herramienta de migración de datos: Sqoop
Marco de programación de tareas: Azkaban, Oozie
Implementación y monitoreo de clústeres: Ambari, Cloudera Manager
Su estructura jerárquica es la siguiente: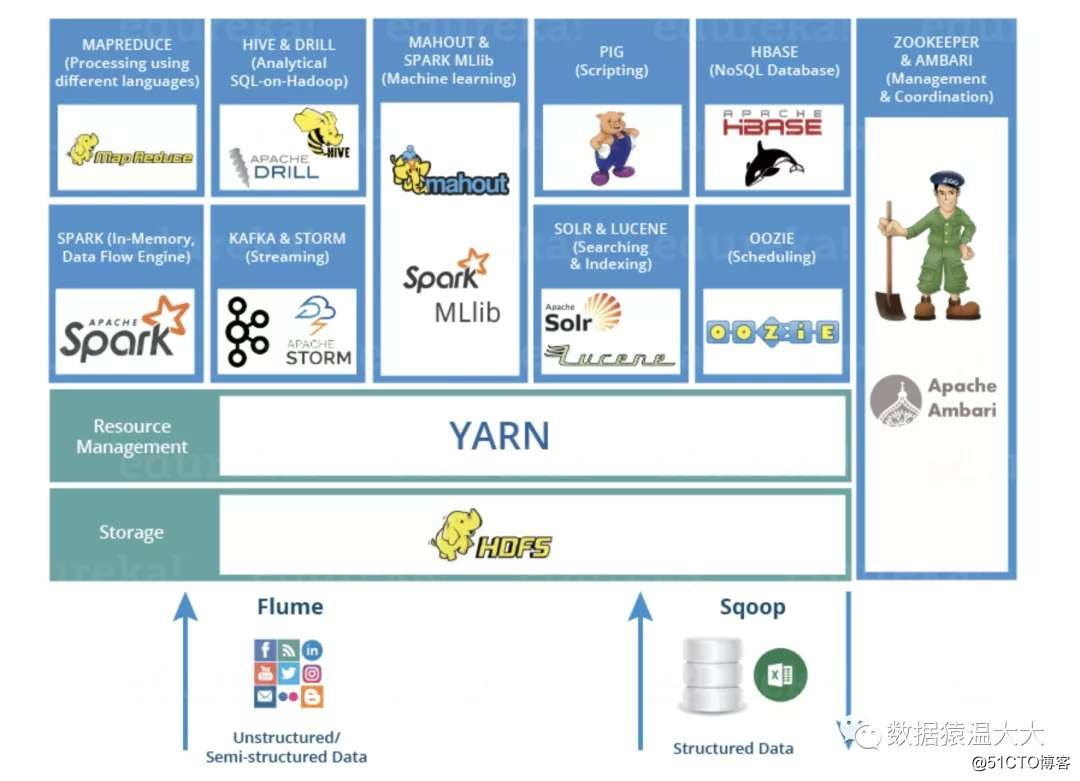
La capa inferior se recopila a través de datos estructurados y no estructurados flume + sqoop, y luego se almacena en hdfs, la administración de recursos agrupados se realiza a través de zookeeper (yarn) y se determina el tamaño de los diferentes recursos de asignación de tareas. La aplicación de nivel superior puede usar hadoop, Storm , Spark, Flink y otros frameworks calculan y acceden a datos. También puede usar lenguajes similares a SQL: hive, pig, spark sql y otros lenguajes para calcular y acceder a datos. Se programan diferentes tareas a través de Oozie.
- Recursos de aprendizaje
Los materiales de aprendizaje más autorizados y completos para big data son los documentos oficiales:
"Guía autorizada de Hadoop (cuarta edición) .pdf"
" Guía autorizada de Kafka.pdf"
"Principio y práctica de coherencia distribuida de Zookeeper.pdf"
"Principio de implementación y diseño de la arquitectura central de Spark.pdf" " Guía
autorizada de HBase.pdf"
" Hive Programming Guide.pdf "
" Flume Building a Highly Available and Scalable Mass Log Collection System.pdf "
" Introducción a la minería de datos_Versión completa.pdf "
- bienestar
Si desea comenzar rápidamente porque está demasiado ocupado en el trabajo, el siguiente es un enlace a mi explicación anterior de algunas de las tecnologías, espero que pueda ayudarlo a comprenderlo o dominarlo rápidamente:
función de colmena:
Un artículo para obtener la función de colmena, se recomienda recopilar
función de los pandas:
Un artículo para obtener la función Pandas, ¡se recomienda recopilarlo!
Principio de hadoop-MapReduce:
Ya no tienes que tener miedo de que el entrevistador te pregunte MapRedue
Principios de hadoop-HDFS:
HDFS! Una biblioteca distribuida ...
De repente,
en el primer año de aprendizaje de Big Data, siempre sentí que todavía era un estudiante de primaria frente al marco de Big Data. Por lo general, lo aprendí debido a necesidades laborales. No tenía una comprensión sistemática de Big Data. Cuando llegue a un punto de conocimiento en big data, primero descubrirá conscientemente qué problemas puede resolver, por qué puede resolver estos problemas y qué puntos de conocimiento de big data están relacionados con él, de modo que el aprendizaje pueda obtener el doble de resultado con la mitad del esfuerzo.
Seguir mi cuenta pública de WeChat [Data Ape Wen Da]
Aquí hay más productos secos de big data aquí.
