Visión de conjunto
Por que optimizar
- Los cuellos de botella del rendimiento del sistema suelen aparecer en la velocidad de acceso de la base de datos
- A medida que se ejecuta la aplicación, habrá más y más datos en la base de datos y el tiempo de procesamiento se ralentizará en consecuencia.
- Los datos se almacenan en el disco y la velocidad de lectura y escritura no se puede comparar con la memoria
Cómo optimizar
- Al diseñar una base de datos: diseño de tablas y campos de la base de datos, motor de almacenamiento
- Haga un buen uso de las funciones que proporciona MySQL, como los índices
- Expansión horizontal: clúster MySQL, equilibrio de carga, separación de lectura y escritura
- Optimización de declaraciones SQL (con poco efecto)

1 Hablar sobre mi comprensión de los dos motores de almacenamiento comunes de MySQL: MyISAM e InnoDB
Sobre la comparación y resumen de los dos:
La diferencia en la operación de conteo: debido a que la caché MyISAM tiene metadatos de tabla (número de filas, etc.), no necesita consumir muchos recursos para una consulta bien estructurada cuando se realiza COUNT (*). Para InnoDB, no existe tal caché.
Ya sea para admitir transacciones y recuperación segura después de un bloqueo: MyISAM enfatiza el rendimiento, cada consulta es atómica y su ejecución es más rápida que el tipo InnoDB, pero no brinda soporte para transacciones. Pero InnoDB proporciona funciones de base de datos avanzadas, como transacciones de soporte de transacciones y claves externas. Tabla de tipo de transacciones seguras (compatible con ACID) con transacciones (confirmación), reversión (reversión) y capacidades de recuperación de fallas (capacidades de recuperación de fallas).
Ya sea para admitir claves externas: MyISAM no es compatible, pero InnoDB es compatible.
MyISAM es más adecuado para tablas de lectura intensiva, mientras que InnoDB es más adecuado para tablas de escritura intensiva. En el caso de la separación de la base de datos, MyISAM se selecciona a menudo como motor de almacenamiento de la base de datos principal. En términos generales, si se requiere soporte de transacciones y hay una mayor frecuencia de lecturas simultáneas (la granularidad del bloqueo de la tabla de MyISAM es demasiado grande, por lo que cuando la concurrencia de escritura de la tabla es alta, habrá muchas consultas que esperar), InnoDB Es una buena eleccion. Si tiene una gran cantidad de datos (MyISAM admite funciones de compresión para reducir el uso de espacio en disco) y no necesita admitir transacciones, MyISAM es la mejor opción.
2 ¿Entiende el índice de la base de datos?

Estos son algunos de los contenidos que agregué
¿Por qué el índice puede mejorar la velocidad de las consultas?
Comencemos con la estructura de almacenamiento básica de MySQL
La estructura de almacenamiento básica de MySQL es la página (los registros se almacenan en la página):
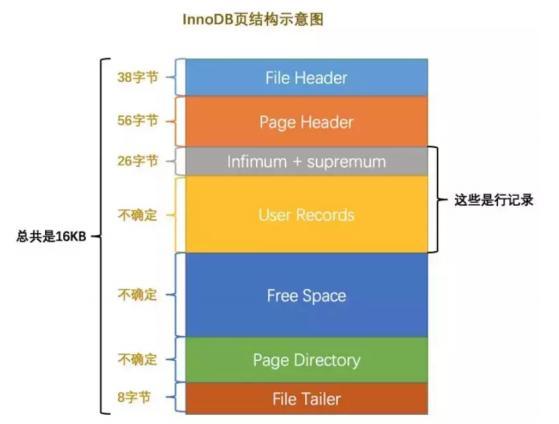
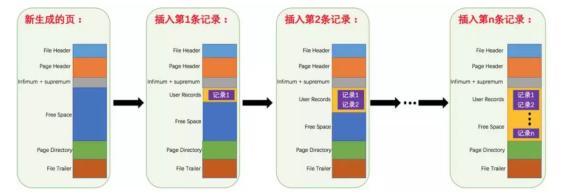
Cada página de datos puede formar una lista doblemente enlazada
Los registros de cada página de datos pueden formar una lista enlazada individualmente
Cada página de datos genera un directorio de páginas para los registros almacenados en ella. Al buscar un registro a través de la clave principal, puede usar la dicotomía en el directorio de páginas para ubicar rápidamente la ranura correspondiente y luego atravesar el grupo correspondiente de la ranura Para encontrar rápidamente el registro especificado
Utilice otras columnas (claves no primarias) como criterio de búsqueda: cada registro de la lista enlazada individualmente solo se puede recorrer secuencialmente comenzando desde el registro más pequeño.
Entonces, si escribimos select * from user donde indexname = 'xxx' tal declaración SQL sin ninguna optimización, hará esto por defecto:
Localice la página donde se encuentra el registro: debe recorrer la lista doblemente enlazada para encontrar la página
Busque el registro correspondiente en la página donde se encuentra: debido a que no se basa en la consulta de clave principal, solo puede recorrer la lista de enlaces individuales de la página en la que se encuentra.
¡Obviamente, esta búsqueda será muy lenta cuando la cantidad de datos sea grande! Esta vez la complejidad es O (n).
Después de usar el índice
¿Qué puede hacer el índice para acelerar nuestras consultas? De hecho, convierte los datos desordenados en orden (relativamente):
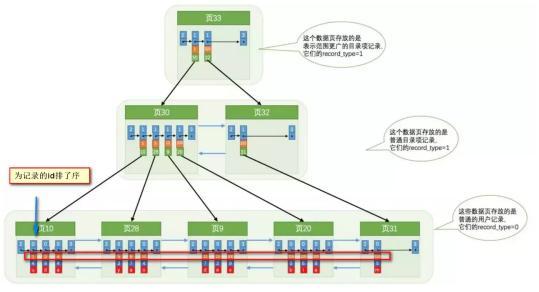
Breves pasos para encontrar el registro con id 8:
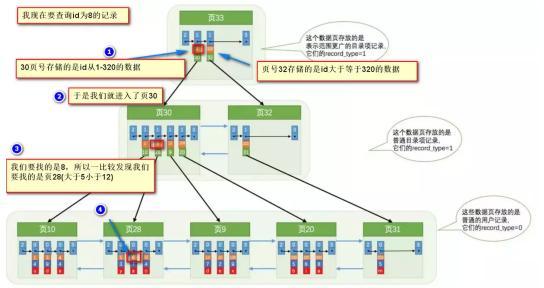
Obviamente: sin indexar, necesitamos recorrer la lista doblemente enlazada para ubicar la página correspondiente ¡Ahora podemos ubicar rápidamente la página correspondiente a través del "directorio" ! (Búsqueda binaria, la complejidad de tiempo es aproximadamente O (logn)) De hecho, la estructura subyacente es el árbol B +. Como implementación del árbol, el árbol B + nos permite encontrar rápidamente el registro correspondiente.
El siguiente contenido está organizado a partir de: "The Way of Java Engineer Practice"
Principio del prefijo más a la izquierda
Un índice en MySQL puede hacer referencia a varias columnas en un orden determinado. Este tipo de índice se denomina índice conjunto. Por ejemplo, el nombre y la ciudad de la tabla de Usuario más el índice conjunto es (nombre, ciudad) o y el principio del prefijo más a la izquierda se refiere a que si la condición de la consulta coincide exactamente con una o varias columnas en el lado izquierdo del índice, esta columna se puede usar A. como sigue:
seleccione * del usuario donde nombre = xx y ciudad = xx; // puede presionar el índice
seleccione * del usuario donde nombre = xx; // puede presionar el índice
seleccionar * del usuario donde ciudad = xx; // No se puede acceder al índice
Cabe señalar aquí que si se utilizan ambas condiciones en la consulta, pero el orden es diferente, como ciudad = xx y nombre = xx, entonces el motor de consulta actual se optimizará automáticamente para que coincida con el orden del índice conjunto, de modo que pueda acertar Indexado.
Debido al principio del prefijo más a la izquierda, al crear un índice conjunto, el orden de los campos del índice debe considerar el número de valores de campo después de la deduplicación y poner más al principio.
La cláusula ORDERBY también sigue esta regla.
Tenga cuidado de evitar índices redundantes
El índice redundante se refiere a la misma función del índice. Si puede acertar, definitivamente lo hará. Entonces es un índice redundante. Los dos índices (nombre, ciudad) y (nombre) son índices redundantes. La consulta que puede acertar a este último debe ser En la mayoría de los casos, si puede alcanzar el primero, debería intentar expandir el índice existente en lugar de crear uno nuevo.
Después de la versión MySQLS.7, puede verificar el índice redundante consultando la tabla schema_r dundant_indexes de la biblioteca sys
¿Cómo agrega Mysql índices a los campos de la tabla? ? ?
1. Agregue PRIMARY KEY (índice de clave principal)
ALTER TABLE `table_name` AÑADIR CLAVE PRIMARIA (` columna`)
2. Agregue UNIQUE (índice único)
ALTER TABLE `table_name` AÑADIR UNIQUE (` column`)
3. Agregue INDICE (índice normal)
ALTER TABLE `table_name` ADD INDEX index_name (` columna`)
4. Agregar FULLTEXT (índice de texto completo)
ALTER TABLE `table_name` AÑADIR FULLTEXT (` column`)
5. Agregue un índice de varias columnas
ALTER TABLE `table_name` ADD INDEX index_name (` columna1`, `columna2`,` columna3`)
3 Hable sobre métodos de optimización comunes para tablas grandes
4 Cuando el número de registros en una sola tabla MySQL es demasiado grande, el rendimiento CRUD de la base de datos disminuirá significativamente. Algunas medidas de optimización comunes son las siguientes:
Cuando el número de registros en una sola tabla MySQL es demasiado grande, el rendimiento CRUD de la base de datos disminuirá significativamente. Algunas medidas de optimización comunes son las siguientes:
1. Restringir el rango de datos : asegúrese de prohibir las declaraciones de consulta sin condiciones que restrinjan el rango de datos. Por ejemplo: cuando nuestros usuarios consultan el historial de pedidos, podemos controlarlo en un mes. ;
2. Separación de lectura / escritura : el esquema clásico de división de la base de datos, la biblioteca principal es responsable de la escritura y la biblioteca secundaria es responsable de la lectura;
3. Partición vertical : se divide según la correlación de las tablas de datos en la base de datos. Por ejemplo, si la tabla de usuarios contiene tanto la información de inicio de sesión del usuario como la información básica del usuario, la tabla de usuarios puede dividirse en dos tablas separadas o incluso colocarse en una base de datos separada para la subbase de datos. En pocas palabras, la división vertical se refiere a la división de las columnas de la tabla de datos, dividiendo una tabla con muchas columnas en varias tablas. Como se muestra en la figura siguiente, debería ser más fácil de entender para todos.
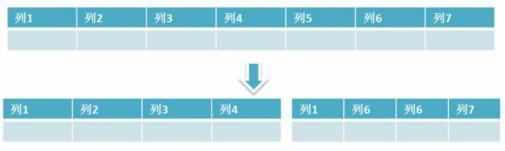
Las ventajas de la división vertical : puede hacer que los datos de la fila sean más pequeños, reducir el número de bloques leídos durante la consulta y reducir el número de E / S. Además, la división vertical puede simplificar la estructura de la mesa y es fácil de mantener.
Desventajas de la división vertical : la clave principal será redundante, las columnas redundantes deben administrarse y provocarán operaciones de unión, que se pueden resolver uniendo en la capa de aplicación. Además, la partición vertical complicará las transacciones;
4. Partición horizontal : mantenga la estructura de la tabla de datos sin cambios y almacene fragmentos de datos mediante una estrategia determinada. De esta forma, cada dato se dispersa en diferentes tablas o bibliotecas, logrando el propósito de distribución. La división horizontal puede admitir una gran cantidad de datos. La división horizontal se refiere a la división de las filas de la tabla de datos. Cuando el número de filas de la tabla supera los 2 millones de filas, se ralentizará. En este momento, los datos de una tabla se pueden dividir en varias tablas para su almacenamiento.
Por ejemplo: podemos dividir la tabla de información del usuario en varias tablas de información del usuario, de modo que podamos evitar el impacto en el rendimiento de una sola tabla que es demasiado grande.
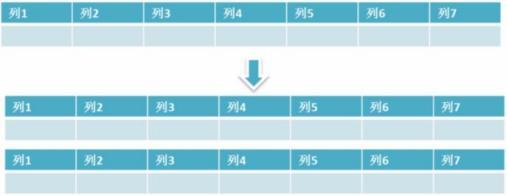
La división horizontal puede admitir una gran cantidad de datos. Una cosa a tener en cuenta es: dividir la tabla solo resuelve el problema de datos demasiado grandes en una sola tabla, pero debido a que los datos de la tabla aún están en la misma máquina, no es significativo mejorar la concurrencia de MySQL, por lo que la división horizontal es mejor para dividir la base de datos. . La división horizontal puede admitir una gran cantidad de almacenamiento de datos y hay pocas transformaciones del lado de la aplicación, pero las transacciones de fragmentación son difíciles de resolver, el rendimiento de la unión transfronteriza es deficiente y la lógica es complicada.
El autor de "The Practice of Java Engineers" recomienda no fragmentar los datos tanto como sea posible, porque la división traerá diversas complejidades de lógica, implementación, operación y mantenimiento , y la tabla de datos generales puede admitir menos de 10 millones bajo la condición de una optimización adecuada. La cantidad de datos no es un gran problema. Si realmente desea fragmentar, intente elegir la arquitectura de fragmentación del cliente, que puede reducir la E / S de red una vez y el middleware.
Aquí hay dos escenarios comunes para la fragmentación de la base de datos:
Proxy de cliente: la lógica de fragmentación está en el lado de la aplicación, encapsulada en un paquete jar y se implementa modificando o encapsulando la capa JDBC . Sharding-JDBC de Dangdang y TDDL de Ali son dos implementaciones de uso común.
Agente de middleware: se agrega una capa de agente entre la aplicación y los datos. La lógica de fragmentación se mantiene uniformemente en el servicio de middleware. Ahora estamos hablando de Mycat , Atlas de 360, DDB de Netease, etc. son implementaciones de esta arquitectura.
Escribir al final
Por razones de espacio, solo algunos de ellos se enumeran arriba. Los he compilado en archivos pdf y los comparto gratis con quienes los necesitan.
He compilado un video de aprendizaje de arquitectura de Java y la información de la entrevista de back-end de Java para la temporada de cambio de trabajo "Golden Nine y Silver Ten" para todos los aquí presentes;
Materiales de aprendizaje para arquitectos de Java :
- Mybatis de escritura a mano
- ¿Cómo debo aprender la JVM que deben preguntar las entrevistas de Ali?
- El principio subyacente del bloqueo JDK de escritura a mano de programación concurrente
- Análisis de código fuente de transacciones de Spring
- Trucos de rendimiento de alta concurrencia cada segundo
- y muchos más
Preguntas de la entrevista de Java :
- Temas y respuestas de la entrevista de Linux
- Temas y respuestas de la entrevista de JVM
- Preguntas de la entrevista básica de Java
- Temas y respuestas de la entrevista de Kafka
- Entrevista y respuestas de Dubbo
- Temas y respuestas de la entrevista de Netty
- Tema de entrevista de middleware de mensajes de ActiveMQ
- Temas y respuestas de la entrevista de middleware de mensajes
- Temas y respuestas de las entrevistas de la base de datos
- Temas y respuestas de la entrevista de microservicio
- Cerraduras optimistas y pesimistas para entrevistas
- Temas y respuestas de la entrevista del marco de código abierto
- Temas y respuestas de la entrevista de patrón de diseño
- Temas y respuestas de entrevistas de varios subprocesos
- Temas y respuestas de la entrevista de Zookeeper
- Temas y respuestas de entrevistas de programación concurrente
- y muchos más
Con el espíritu de "compartir desinteresadamente", amigos que necesitan el esquema del curso (versión PDF) resumido en este artículo, videos de aprendizaje de arquitectos de Java y preguntas de la entrevista de Java
