
En el negocio actual de Internet, la base de datos más utilizada es sin duda la base de datos relacional MySQL. La razón para usar la palabra "o" es que el campo de las bases de datos nacionales también ha tenido grandes avances en los últimos años, como TIDB, OceanBase, etc. Bases de datos distribuidas, pero aún no han formado una cobertura absoluta, por lo que en esta etapa, todavía tenemos que seguir aprendiendo la base de datos MySQL para hacer frente a algunos problemas encontrados en el trabajo, y la investigación de la parte de la base de datos durante la entrevista.
El contenido de hoy le hablará sobre los problemas centrales del control de concurrencia, las transacciones y los motores de almacenamiento en la base de datos MySQL. El gráfico de conocimiento involucrado en este contenido se muestra en la siguiente figura:

Control de concurrencia
El control de concurrencia es un tema enorme, siempre que haya varias solicitudes para modificar datos al mismo tiempo en un sistema de software de computadora, surgirán problemas de control de concurrencia, como la seguridad de múltiples subprocesos en Java. El control de simultaneidad en MySQL analiza principalmente cómo la base de datos controla la lectura y escritura concurrentes de los datos de la tabla.
Por ejemplo, existe una tabla useccount cuya estructura es la siguiente:
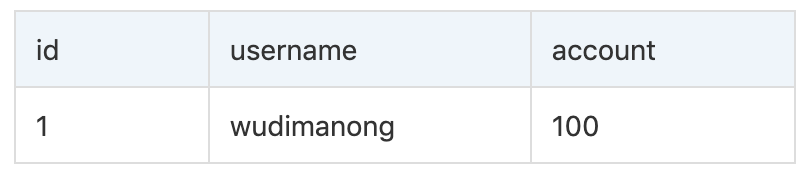
En este momento, si las siguientes dos sentencias SQL inician una solicitud a la base de datos al mismo tiempo:
SQL-A:
update useraccount t set t.account=t.account+100 where username='wudimanong';
SQL-B:
update useraccount t set t.account=t.account-100 where username='wudimanong'
Cuando se ejecutan todas las declaraciones anteriores, el resultado correcto debe ser cuenta = 100, pero en el caso de concurrencia, puede ocurrir tal situación:
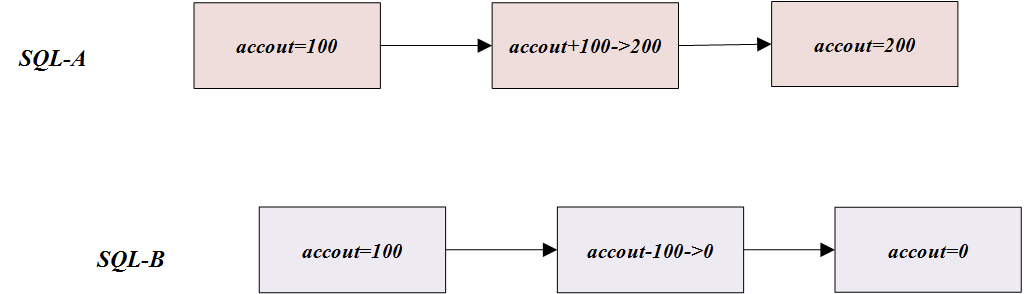
Entonces, ¿cómo es el control de concurrencia en MySQL? De hecho, como la mayoría de los métodos de control de concurrencia, el mecanismo de bloqueo también se utiliza en MySQL para lograr el control de concurrencia.
1. Tipo de bloqueo de MySQL
En MySQL, el control de concurrencia se logra principalmente a través de "bloqueos de lectura y escritura".
** Bloqueo de lectura: ** También llamado bloqueo compartido, varias solicitudes de lectura pueden compartir un bloqueo para leer datos al mismo tiempo sin bloquear.
** Bloqueo de escritura: ** También llamado bloqueo exclusivo, el bloqueo de escritura excluirá todas las demás solicitudes para adquirir el bloqueo y se bloqueará hasta que se complete la escritura y se libere el bloqueo.
El bloqueo de lectura-escritura puede lograr lectura y lectura en paralelo, pero no puede lograr escritura, lectura y escritura en paralelo. El aislamiento de transacciones que se mencionará más adelante se basa en el bloqueo de lectura y escritura.
2. Granularidad de bloqueo de MySQL
Los bloqueos de lectura y escritura mencionados anteriormente se dividen según el tipo de bloqueo de MySQL, y la granularidad que pueden imponer los bloqueos de lectura y escritura se refleja principalmente en las tablas y filas de la base de datos, también conocidas como bloqueos de tabla y bloqueos de fila. ) .
Bloqueo de tabla (bloqueo de tabla) : Es la estrategia de bloqueo más básica en MySQL. Bloquea toda la tabla, por lo que la sobrecarga de mantener el bloqueo es mínima, pero reducirá la eficiencia de lectura y escritura de la tabla. Si un usuario implementa una operación de escritura (insertar, eliminar, actualizar) en la tabla a través de un bloqueo de tabla, primero necesita obtener un bloqueo de escritura que bloquee la tabla, luego, en este caso, se bloqueará la lectura y escritura de otros usuarios en la tabla. . En circunstancias normales, declaraciones como "alterar tabla" utilizarán bloqueos de tabla.
Bloqueos de fila : los bloqueos de fila pueden admitir lecturas y escrituras simultáneas en la mayor medida, pero la sobrecarga de los bloqueos de mantenimiento de la base de datos será relativamente grande. Los bloqueos de fila son la estrategia de bloqueo más utilizada en nuestra vida diaria. Generalmente, los bloqueos de nivel de fila en MySQL se implementan mediante motores de almacenamiento específicos, no a nivel de servidor MySQL (los bloqueos de tabla se implementarán a nivel de servidor MySQL).
3. Control de concurrencia de múltiples versiones (MVCC)
MVCC (MultiVersion Concurrency Control), control de concurrencia de múltiples versiones. En la mayoría de los motores de transacciones de MySQL (como InnoDB), los bloqueos a nivel de fila no se implementan simplemente, de lo contrario, se producirá una situación de este tipo: "Durante el período en el que un determinado usuario actualiza los datos A (adquiriendo el bloqueo de escritura a nivel de fila), otros usuarios La lectura de este dato (adquirir un bloqueo de lectura) se bloqueará ". Pero la realidad obviamente no es el caso. Esto se debe a que el motor de almacenamiento MySQL se basa en la consideración de mejorar el rendimiento de la concurrencia. A través del control de múltiples versiones de datos MVCC, se logra la separación de lectura y escritura, de modo que los datos se pueden leer sin bloqueos y leer y escribir en paralelo.
Tome la implementación MVCC del motor de almacenamiento InnoDB como ejemplo:
El MVCC de InnoDB se implementa almacenando dos columnas ocultas detrás de cada fila de registros. De estas dos columnas, una contiene el tiempo de creación de la fila y la otra contiene el tiempo de vencimiento de la fila. Por supuesto, lo que almacenan no es el valor de tiempo real, sino el número de versión del sistema. Cada vez que se abre una nueva transacción, el número de versión del sistema se incrementará automáticamente; el número de versión del sistema al comienzo de la transacción se utilizará como el número de versión de la transacción para comparar con el número de versión de cada fila de la consulta.
Los principales medios en los que se basa MVCC en MySQL son " deshacer registro y vista de lectura ".
-
deshacer registro: el registro de deshacer se utiliza para registrar varias versiones de una fila de datos.
-
vista de lectura: se utiliza para determinar la visibilidad de la versión actual de los datos
El registro de deshacer se introducirá más adelante en la transacción. El diagrama esquemático del principio de lectura y escritura de MVCC es el siguiente: La
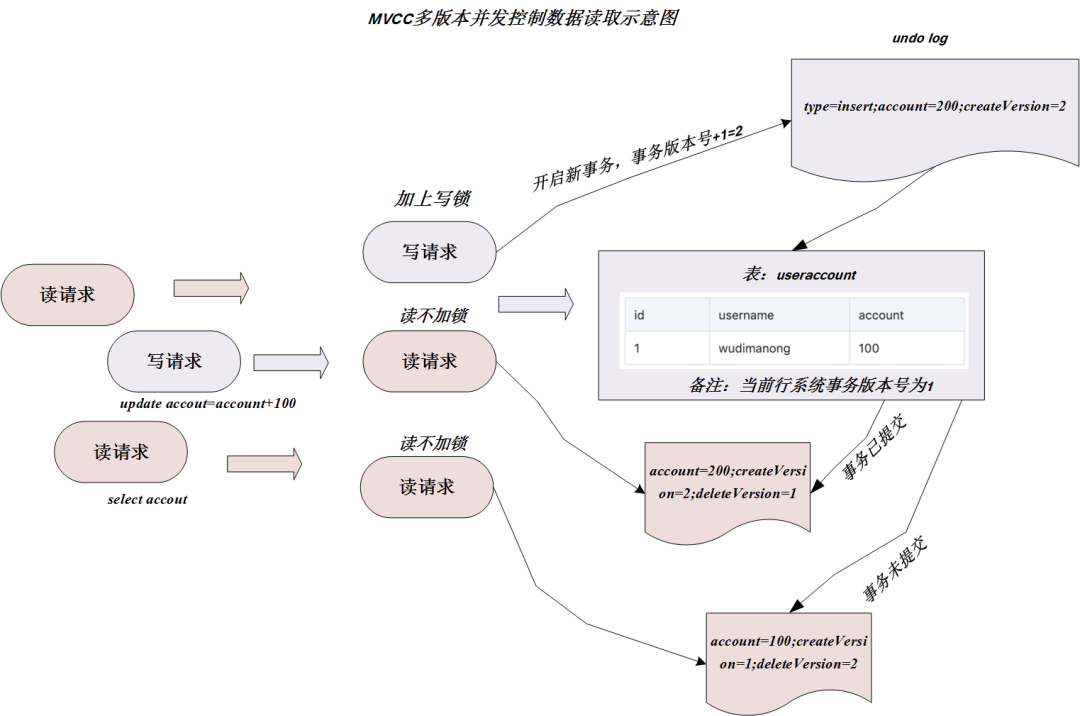
figura anterior muestra el motor de almacenamiento MySQL InnoDB. Bajo el nivel de aislamiento de transacciones REPEATABLE READ (lectura repetible), se guardan dos números de versión del sistema adicionales (número de versión de creación de fila, número de versión de eliminación de fila) Realice MVCC, de modo que la mayoría de las operaciones de lectura se puedan leer sin bloqueo adicional. Este diseño facilita las operaciones de lectura de datos y mejora el rendimiento.
Entonces, ¿cómo garantiza la operación de lectura de datos en modo MVCC que los datos se lean correctamente? Tomando InnoDB como ejemplo, cada fila de registros se comprobará de acuerdo con las siguientes dos condiciones al seleccionar:
-
Solo busque filas de datos cuyo número de versión sea menor o igual que la versión de la transacción actual. Esto asegura que las filas leídas por la transacción ya existían antes de que comenzara la transacción, o fueron insertadas o modificadas por la transacción misma.
-
El número de versión de eliminación de la fila no está definido o es mayor que el número de versión de la transacción actual. Esto asegura que las filas leídas por la transacción no se eliminen antes de que comience la transacción.
¡Solo los registros que cumplan las dos condiciones anteriores se pueden devolver como resultado de la consulta! Tome la lógica que se muestra en la figura como ejemplo. En el proceso de cambiar la cuenta a 200 en la solicitud de escritura, InnoDB insertará un nuevo registro (cuenta = 200) y usará el número de versión actual del sistema como el número de versión de creación de línea (createVersion = 2). Al mismo tiempo, el número de versión actual del sistema se usa como la fila original para eliminar el número de versión (deleteVersion = 2), luego hay dos versiones de la copia de datos para estos datos, como sigue:
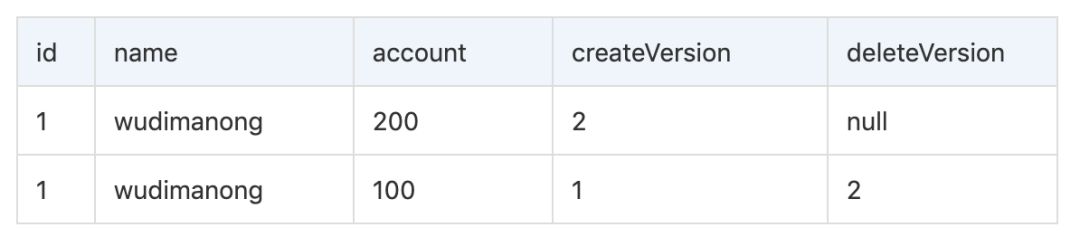
Si la operación de escritura no ha finalizado, la transacción es para otros usuarios Es temporalmente invisible De acuerdo con la condición Seleccionar verificación, solo los registros con cuenta = 100 son elegibles, por lo que el resultado de la consulta devolverá registros con cuenta = 100.
El proceso anterior es el principio básico del motor de almacenamiento InnoDB en la implementación de MVCC, pero luego debe tener en cuenta que la lógica del control de concurrencia de múltiples versiones de MVCC solo puede funcionar bajo los dos niveles de aislamiento de transacciones de " REPEATABLE READ (repetible read) y READ COMMITED (commit read)" . Los otros dos niveles de aislamiento no son compatibles con MVCC, porque READ UNCOMMITED (lectura no confirmada) siempre lee la última fila de datos, no la fila de datos que se ajusta a la versión de transacción actual; y SERIALIZABLE se agregará a todas las filas leídas La cerradura no se ajusta a la idea de MVCC.
Transacción MySQL
En la explicación anterior sobre el proceso de control de concurrencia de MySQL, también se mencionó el contenido relacionado con la transacción. A continuación, clasificaremos el conocimiento básico sobre la transacción de manera más completa.
Creo que todo el mundo ha utilizado las transacciones de bases de datos en el proceso de desarrollo diario y pueden abrir la boca sobre las características de las transacciones-ACID. Entonces, ¿cómo se implementa dentro de la transacción? En el siguiente contenido, ¡hablemos de este tema específicamente contigo!
1. Descripción general de la empresa
El efecto que debe lograr la propia transacción de la base de datos se refleja principalmente en: ** "confiabilidad" y "procesamiento concurrente" ** estos dos aspectos.
-
Fiabilidad: la base de datos debe garantizar que la operación de datos sea coherente cuando una operación de inserción o actualización genera una excepción o la base de datos falla.
-
Procesamiento concurrente: Cuando entran múltiples solicitudes concurrentes, y una de las solicitudes es modificar los datos, para evitar que otras solicitudes lean datos sucios, es necesario aislar la lectura y escritura entre transacciones.
Hay tres tecnologías principales para realizar la función de transacción de la base de datos MySQL, a saber, archivos de registro (rehacer registro y deshacer registro), tecnología de bloqueo y MVCC.
2.redo registro 与 deshacer registro
Rehacer el registro y deshacer el registro son las tecnologías centrales para realizar la función de transacción MySQL.
1) 、 rehacer registro
El registro de rehacer se denomina registro de rehacer y es la clave para lograr la durabilidad de las transacciones. El archivo de registro de rehacer se compone principalmente de dos partes: búfer de registro de rehacer (búfer de registro de rehacer), archivo de registro de rehacer (archivo de registro de rehacer) .
Para mejorar el rendimiento de la base de datos en MySql, todas las modificaciones no se sincronizarán con el disco en tiempo real, sino que se almacenarán en un grupo de búfer llamado "Boffer Pool", y luego se utilizarán subprocesos en segundo plano para implementar el grupo de búfer y el disco. Sincronización entre.
Si adopta este modelo, puede haber un problema de este tipo: si hay un tiempo de inactividad o un corte de energía antes de sincronizar los datos, es posible que pierda parte de la información de modificación de la transacción comprometida. Esta situación es inaceptable para el software de base de datos.
Por lo tanto, la función principal del registro de rehacer es registrar la información de modificación de la transacción confirmada con éxito, y conservará el registro de rehacer en el disco en tiempo real después de que se envíe la transacción, de modo que el registro de rehacer se pueda leer después de que el sistema se reinicie para restaurar los datos más recientes.
A continuación, tomamos la transacción abierta por SQL-A como ejemplo para demostrar cómo funciona el registro de rehacer, como se muestra en la figura siguiente:
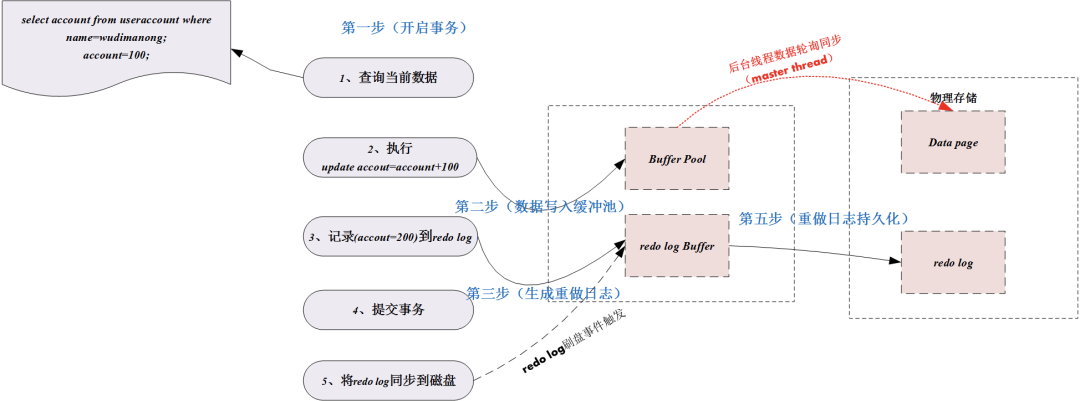
Como se muestra en la figura anterior, cuando se abre la transacción que modifica una fila de registros, el motor de almacenamiento MySQL elimina los datos de El disco se lee en el grupo de búfer de la memoria para su modificación. En este momento, los datos en la memoria se modifican y los datos en el disco son diferentes. Este tipo de datos de diferencia también se llama ** "página sucia" **.
En general, el motor de almacenamiento no descarga las páginas sucias al disco cada vez que se genera una página sucia, sino que utiliza un hilo de fondo ** "hilo maestro" ** para ejecutarse aproximadamente una vez cada segundo o una vez cada 10 segundos. La frecuencia para actualizar el disco. En este caso, si la base de datos está inactiva o sin energía, es posible que se pierdan los datos que no se han devuelto al disco.
La función del registro de rehacer es conciliar la diferencia de velocidad entre la memoria y el disco. Cuando se envía la transacción, el motor de almacenamiento primero escribirá los datos que se modificarán en el registro de rehacer, luego modificará la página de datos reales en el grupo de búfer y actualizará la sincronización de datos en tiempo real. Si durante este proceso, la base de datos se cuelga, ya que el archivo de registro físico del registro de rehacer ha registrado modificaciones de transacciones, los datos de la transacción se pueden recuperar basándose en el registro de rehacer después de reiniciar la base de datos.
2) 、 deshacer registro
Anteriormente hablamos sobre el registro de rehacer, que se utiliza principalmente para restaurar datos y garantizar la persistencia de las transacciones comprometidas. Hay otro tipo de registro de deshacer registro muy importante en MySQL, también llamado registro de reversión. Se utiliza principalmente para registrar información antes de que se modifiquen los datos, que es lo opuesto al registro de rehacer, que registra información después de que se modifican los datos.
El registro de deshacer registra principalmente la información de datos de la versión anterior de la modificación de la transacción. Si se revierte debido a un error del sistema o una operación de reversión, los datos se pueden revertir al estado anterior a la modificación de acuerdo con el registro de registro de deshacer.
Cada vez que se escriben o modifican datos, el motor de almacenamiento registra la información antes de la modificación en el registro de deshacer.
3. La realización de la transacción
Anteriormente hablamos de bloqueos, control de concurrencia de múltiples versiones (MVCC), registro de rehacer (registro de rehacer) y registro de reversión (registro de deshacer), que son la base para que MySQL implemente transacciones de base de datos. De las cuatro características principales de las transacciones, la relación correspondiente se refleja principalmente de la siguiente manera:
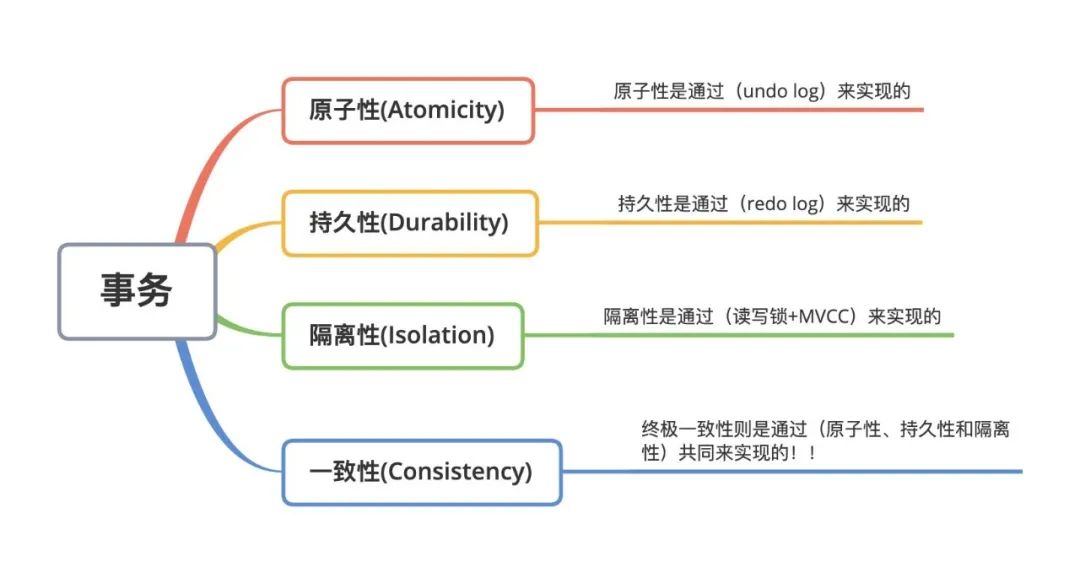
De hecho, el propósito último de la atomicidad, la durabilidad y el aislamiento de las transacciones es garantizar la coherencia de los datos de las transacciones. ACID es solo un concepto y el objetivo final de las transacciones es garantizar la confiabilidad y coherencia de los datos.
A continuación, analizaremos el principio de implementación de la función ACID de la transacción.
1), la realización de la atomicidad
La atomicidad significa que una transacción debe considerarse como una unidad indivisible más pequeña. Todas las operaciones de una transacción se ejecutan con éxito o todas fallan y se deshacen. Es imposible que una transacción realice solo una parte de las operaciones. Esto es El concepto de atomicidad transaccional.
La atomicidad de la base de datos MySQL se logra principalmente mediante operaciones de reversión. La llamada operación de reversión consiste en restaurar los datos a la apariencia original cuando se produce un error o la declaración de reversión se ejecuta explícitamente, y este proceso debe llevarse a cabo con la ayuda del registro de deshacer. Las reglas específicas son las siguientes:
-
Cada operación de cambio de datos (insertar / actualizar / eliminar) va acompañada de la generación de un registro de deshacer, y el registro de reversión debe conservarse en el disco antes de los datos;
-
La llamada reversión consiste en realizar operaciones inversas basadas en el registro de registro de deshacer. Por ejemplo, la operación inversa de eliminar es insertar, la operación inversa de insertar es eliminar y la operación inversa de actualización es actualizar, etc .;
2), la realización de la persistencia
La persistencia se refiere al hecho de que una vez comprometida la transacción, los cambios realizados se guardarán permanentemente en la base de datos, en este momento los datos modificados no se perderán aunque el sistema falle.
La durabilidad de la transacción se logra principalmente a través del registro de rehacer. El registro de registro de rehacer puede compensar la diferencia de datos causada por la sincronización de la caché, principalmente porque tiene las siguientes características:
-
El almacenamiento de registros de rehacer es secuencial, mientras que la sincronización de la caché es una operación aleatoria;
-
La sincronización de la caché se basa en páginas de datos y el tamaño de los datos transmitidos cada vez es mayor que el registro de rehacer;
Para conocer la lógica del registro de rehacer para lograr la persistencia de la transacción, consulte el contenido del registro de rehacer anteriormente en este artículo.
3), la realización del aislamiento
El aislamiento es la más complicada de las características ACID de las transacciones. En el estándar SQL se definen cuatro niveles de aislamiento, cada nivel de aislamiento especifica la modificación en una transacción, los que son visibles entre transacciones y los que son invisibles.
Hay cuatro niveles de aislamiento de MySQL (de menor a mayor):
-
LEER SIN COMPROMISO (leer sin compromiso);
-
LEER COMITADO
-
LECTURA REPETIBLE (lectura repetible)
-
SERIALIZABLE (serializable)
Cuanto menor sea el nivel de aislamiento, mayor será el grado de simultaneidad que puede realizar la base de datos, pero mayor será la complejidad y la sobrecarga de la implementación. Siempre que comprenda a fondo el nivel de aislamiento y sus principios de implementación, es equivalente a comprender el aislamiento de transacciones en ACID.
Como se mencionó anteriormente, el propósito de la atomicidad, la persistencia y el aislamiento es, en última instancia, lograr la coherencia de los datos, pero el aislamiento es diferente de los otros dos. La atomicidad y la persistencia son principalmente para garantizar la confiabilidad de los datos. Por ejemplo, recuperación de datos después de un tiempo de inactividad y reversión de datos después de errores. El objetivo principal del aislamiento es administrar la secuencia de acceso de múltiples solicitudes de lectura y escritura simultáneas para lograr un acceso seguro y eficiente a los datos de la base de datos. En esencia, es un juego de compensación entre la seguridad de los datos y el rendimiento.
Nivel de aislamiento de alta confiabilidad, bajo rendimiento de concurrencia (por ejemplo, nivel de aislamiento SERIALIZABLE, porque todas las lecturas y escrituras estarán bloqueadas); baja confiabilidad, alto rendimiento de concurrencia (por ejemplo, READ UNCOMMITED, porque las lecturas y escrituras no están bloqueadas en absoluto).
A continuación, analizaremos las características de estos cuatro niveles de aislamiento por separado:
LEER SIN COMPROMISO
Bajo el nivel de aislamiento READ UNCOMMITTED, incluso si la modificación en una transacción no se ha confirmado, es visible para otras transacciones, lo que significa que la transacción puede leer datos no confirmados.
Debido a que la lectura no agrega bloqueos, las operaciones de escritura que modifican los datos durante el proceso de lectura causarán "lecturas sucias". El diagrama de lectura y escritura del nivel de aislamiento de lectura no confirmada es el siguiente:
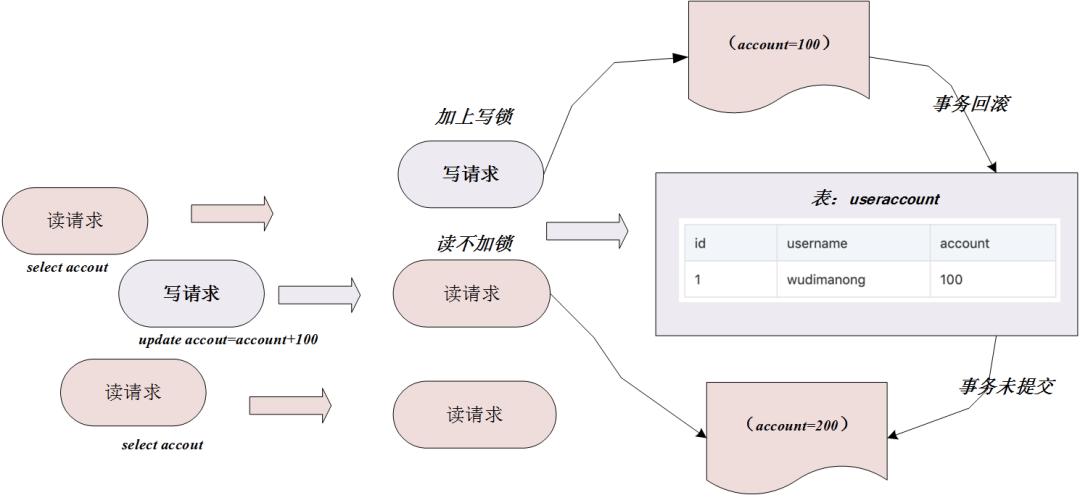
como se muestra en la figura anterior, la solicitud de escritura cambia la cuenta a 200 y la transacción no se confirma en este momento; pero la solicitud de lectura puede leer la cuenta de datos de la transacción no confirmada = 200; luego, la transacción de solicitud de escritura falla Revertir cuenta = 100; entonces los datos con cuenta = 200 leídos por la solicitud de lectura en este momento son datos sucios.
La ventaja de este nivel de aislamiento es la lectura y escritura en paralelo y el alto rendimiento, pero la desventaja es que es fácil provocar lecturas sucias. Por lo tanto, este nivel de aislamiento no se adopta generalmente en la base de datos MySQL.
LEER COMITADO
Este nivel de aislamiento de transacciones también se denomina ** "lectura no repetible o lectura de confirmación". ** Su característica es que todas las modificaciones de una transacción antes de que se confirme son invisibles para otras transacciones; otras transacciones solo pueden leer los cambios confirmados.
Este nivel de aislamiento se ve perfecto y está en línea con la mayoría de los escenarios lógicos, pero este nivel de aislamiento de transacciones tendrá los problemas de " lectura no repetible" y "fantasma".
** No legible: ** se refiere a los datos de la misma fila leídos varias veces en una transacción, pero el resultado es diferente. Por ejemplo, la transacción A lee los datos de la fila a, y la transacción B modifica los datos de la fila a en este momento y confirma la transacción, entonces la próxima vez que la transacción A lee los datos de la fila a, se encuentra que es diferente de la primera vez.
** Lectura fantasma: ** se refiere a una transacción que recupera datos de acuerdo con las mismas condiciones de consulta, pero los resultados de los datos recuperados varias veces son diferentes. Por ejemplo, la transacción A recupera datos con la condición x = 0 por primera vez y obtiene 5 registros; en este momento, la transacción B inserta un dato con x = 0 en la tabla y envía la transacción; luego, la transacción A usa la condición x = por segunda vez 0 ¡Al buscar los datos, se encontró que se obtuvieron 6 registros!
Entonces, ¿por qué las lecturas no repetibles y las lecturas fantasma ocurren bajo el nivel de aislamiento READ COMMITED?
De hecho, el nivel de aislamiento de transacciones de lectura no repetible también utiliza el mecanismo MVCC (control de concurrencia de múltiples versiones) que mencionamos anteriormente. Sin embargo, el mecanismo MVCC bajo el nivel de aislamiento READ COMMITED generará un nuevo número de versión del sistema cada vez que seleccione, por lo que cada operación de selección en la transacción lee no una copia sino una copia diferente de los datos, por lo que cada Entre selecciones, si otras transacciones actualizan y envían los datos que leemos, se producirán lecturas no repetibles y lecturas fantasmas.
El motivo de la lectura no repetible es el siguiente:
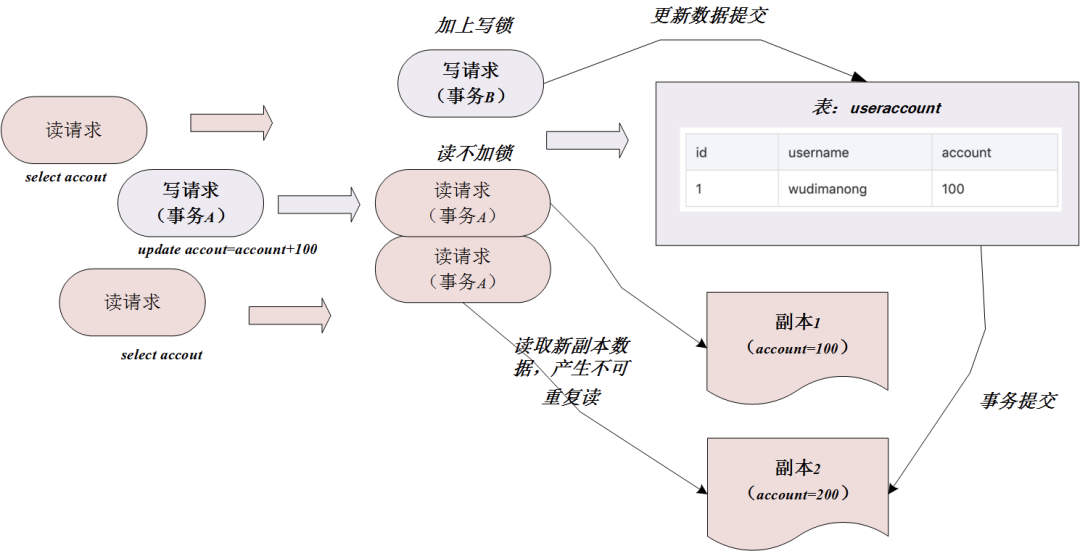
LECTURA REPETIBLE
El nivel de aislamiento de transacciones REPEATABLE READ, también llamado repetible read, es el nivel de aislamiento de transacciones predeterminado de la base de datos MySQL. Bajo este nivel de aislamiento de transacciones, los resultados de múltiples lecturas dentro de una transacción son consistentes. Este nivel de aislamiento puede evitar problemas de consulta como lecturas sucias y lecturas no repetibles.
La realización de este nivel de aislamiento de transacciones es principalmente utilizar el mecanismo de bloqueo de lectura-escritura + MVCC. El diagrama esquemático específico es el siguiente:
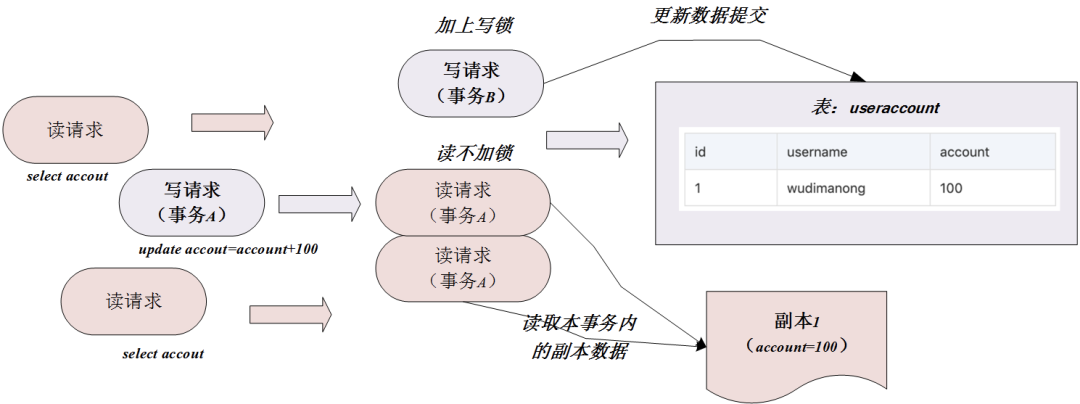
como se muestra en la figura anterior, el mecanismo MVCC bajo el nivel de aislamiento de la transacción no genera un nuevo número de versión del sistema para cada consulta dentro de una transacción, por lo que varias consultas dentro de una transacción, las copias de datos son Uno, por lo que no hay un problema de lectura no repetible. Para obtener más detalles sobre MVCC en este nivel de aislamiento, consulte el contenido anterior.
Pero cabe señalar que este nivel de aislamiento resuelve el problema de las lecturas no repetibles, pero no resuelve el problema de las lecturas fantasmas, por lo que si hay una consulta condicional en la transacción A, otra transacción B agrega o elimina los datos de la condición durante este período. Confirme la transacción, entonces aún hará que la transacción A produzca lecturas fantasmas. ¡Por lo tanto, debe prestar atención a este problema al usar MySQL!
SERIALIZABLE
Este nivel de aislamiento es el más simple de entender, ya que agregará bloqueos exclusivos para leer y escribir solicitudes, por lo que no causará ninguna inconsistencia en los datos, pero el rendimiento no es alto, por lo que hay pocas bases de datos que usen este nivel de aislamiento.
4), la realización de la coherencia
La consistencia se refiere principalmente a la consistencia de los datos de la base de datos a través de la reversión, la recuperación y el aislamiento en condiciones concurrentes. ¡La atomicidad, durabilidad y aislamiento descritos anteriormente son, en última instancia, para lograr consistencia!
Motor de almacenamiento MySQL
En el contenido anterior, describimos respectivamente el contenido del control y las transacciones de concurrencia de MySQL, pero de hecho, el motor de almacenamiento MySql implementa los detalles específicos del control de concurrencia y las transacciones. La característica más importante y distintiva de MySQL es su arquitectura de motor de almacenamiento, este diseño de arquitectura que separa el procesamiento de datos y el almacenamiento permite a los usuarios seleccionar el motor de almacenamiento correspondiente según el rendimiento, las características y otros requisitos específicos.
Aun así, se elige el motor de almacenamiento InnoDB cuando se usa la base de datos MySQL en la mayoría de los casos, pero esto no nos impide comprender adecuadamente las características de otros motores de almacenamiento. A continuación, le daré un breve resumen, como sigue:
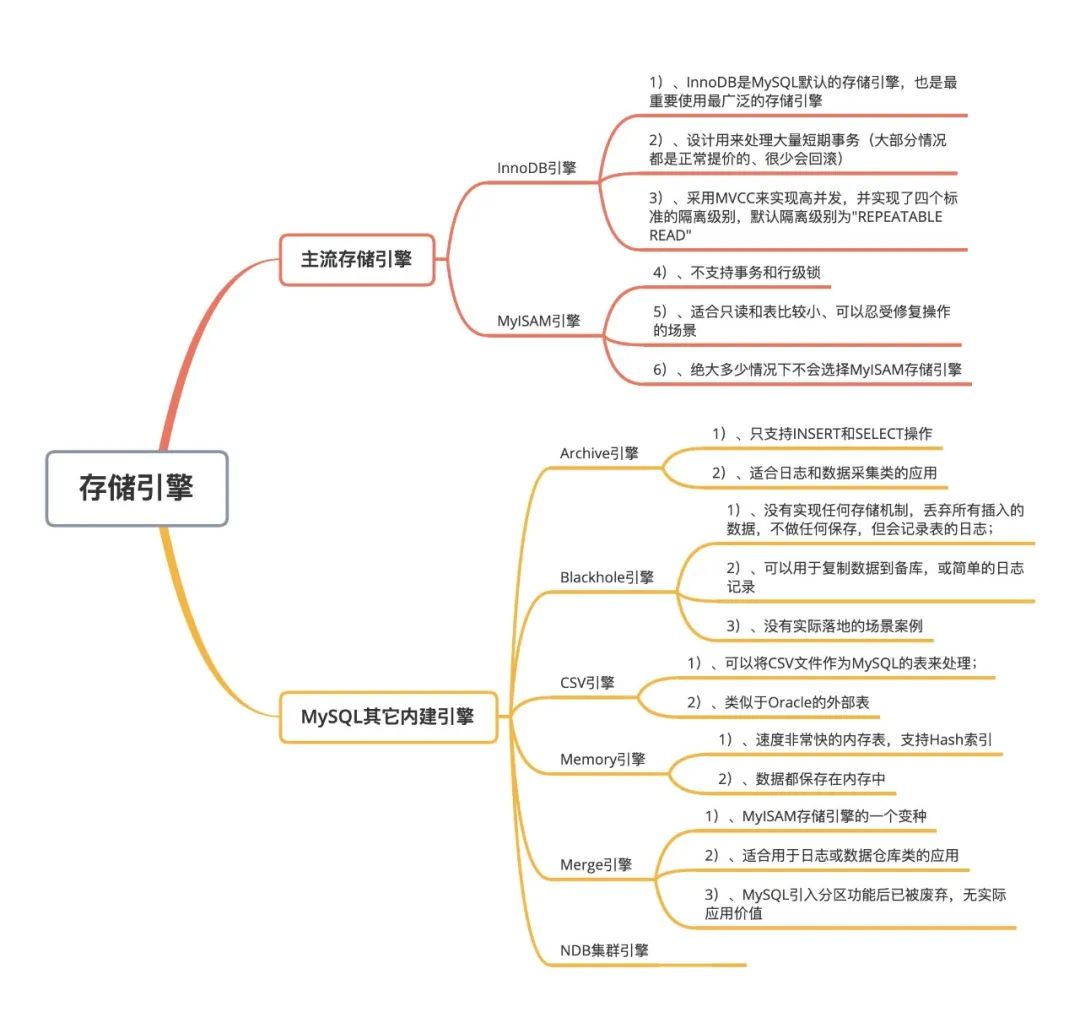
Arriba resumimos brevemente las características generales de los motores de almacenamiento MySQL y sus escenarios generales aplicables, pero de hecho, además del motor de almacenamiento InnoDB, rara vez se ven otros en los negocios de Internet. La figura del motor de almacenamiento. Aunque MySQL tiene una variedad de motores de almacenamiento integrados para escenarios específicos, la mayoría de ellos tienen tecnologías alternativas correspondientes. Por ejemplo, las aplicaciones de registro ahora tienen Elasticsearch, mientras que las aplicaciones de almacenamiento de datos ahora tienen Hive, HBase y otros productos. En cuanto a las bases de datos de memoria, existen MangoDB. Productos de datos NoSQL como Redis, etc., ¡por lo que solo InnoDB puede jugar para MySQL!
Escribir al final
Bienvenidos todos para que presten atención a mi cuenta pública [El viento y las olas son tranquilos como el código ], una gran cantidad de artículos relacionados con Java, materiales de aprendizaje se actualizarán en ella y los materiales clasificados también se colocarán en ella.
Si crees que la escritura es buena, dale me gusta y agrega un seguidor. ¡Presta atención, no te pierdas, sigue actualizando! ! !