Rastrear datos de red
1.1 Primero lea el sitio web`
https: //www.kugou.com/yy/rank/home/1-6666.html? from = rank`
1.2 Defina la parte de texto del código HTML seleccionado con beautifulsoup:
def explica_HTML (mi lista, html):
soup = BeautifulSoup (html, 'html.parser')
songs = soup.select ('div.pc_temp_songlist> ul> li> a')
ranks = soup.select ('span.pc_temp_num')
times = soup.select ('span.pc_temp_time')
para rango, canción, tiempo en zip (rangos, canciones, tiempos):
data = [
rank.get_text (). strip (),
song.get_text (). split (" - ") [1],
song.get_text (). Split (" - ") [0],
time.get_text (). Strip ()
]
mylist.append (data)
12345678910111213
## Para que los resultados impresos sean más hermosos, el formato de datos de la impresión debe ajustarse:
def print_HTML (mylist):
para i en el rango (500):
x = mylist [i]
with open ("D: \ Anew \ kugou.txt", 'a', encoding = 'UTF-8') como f:
f .write ("{0: <10} \ t {1: {4} <25} \ t {2: {4} <20} \ t {3: <10} \ n" .format (x [0] , x [1], x [2], x [3], chr (12288)))
12345
Para evitar fallas de rastreo causadas por una velocidad de rastreo rápida, la función time.sleep (1) está configurada para prevenir los riesgos anteriores.
1.4 Los resultados del rastreo se muestran a continuación:

1.5 Visualización de código
importar solicitudes
desde bs4 importar BeautifulSoup
tiempo de importación
def get_HTML (url):
headers = {
"user-agent": "Mozilla / 5.0 (Windows NT 10.0; WOW64) AppleWebKit / 537.36 (KHTML, como Gecko) Chrome / 72.0.3626.81 Safari / 537.36 ",
" referer ":" https://www.kugou.com/yy/rank/home/1-6666.html?from=rank "
}
intente:
r = request.get (url, headers = headers)
r .raise_for_status ()
r.encoding = r.apparent_encoding
return r.text
excepto:
return ""
def explica_HTML (mylist, html):
soup = BeautifulSoup (html, 'html.parser')
canciones = soup.select ('div.pc_temp_songlist> ul> li> a')
ranks = soup.select ('span.pc_temp_num')
times = soup.select ('span.pc_temp_time')
para rango, canción, tiempo en zip (rangos, canciones, tiempos):
data = [
rank.get_text (). strip (),
song.get_text (). split ("-") [1],
song.get_text (). split ("-") [ 0],
time.get_text (). Strip ()
]
mylist.append (data)
def print_HTML (mylist):
for i in range (500):
x = mylist [i]
with open ("D: \ Anew \ kugou. json ", 'a', encoding = 'UTF-8') como f:
f.write ("{0: <10} \ t {1: {4} <25} \ t {2: {4 } <20} \ t {3: <10} \ n ".format (x [0], x [1], x [2], x [3], chr (12288)))
if __name__ == '__main__ ':
url_0 =' http: //www.kugou.com / aa / rank / home / '
url_1 =' -8888.html '
mylist = []
con open ("D: \ Anew \ kugou.json", 'a', encoding = "UTF-8") como f:
f.write ("{0: <10} \ t {1: { 4} <25} \ t {2: {4} <20} \ t {3: <10} \ n ".format (" 排名 "," 歌曲 "," 歌手 "," 时间 ", chr (12288) ))
para j en el rango (1,24):
url = url_0 + str (j) + url_1
html = get_HTML (url)
Explique_HTML (mylist, html)
print_HTML (mylist)
time.sleep (1)
123456789101112131415161718192021222324252627282930313502394034
1.6 El documento antes de la transcodificación json debe ser

La pantalla en la herramienta json de análisis en línea debe ser:

El código de verificación se muestra de la siguiente manera al ejecutar el código:
con open ("D: //Anew//Kugou.json", 'r', encoding = "utf-8") como rdf:
json_data = json.load (rdf)
print ('数据 展示 :', json_data)
123

Genere archivos CSV mediante programación y conviértalos a formato JSon
Codificar información en forma de matriz
import csv
test = [["Nombre", "Sexo", "Ciudad natal", "Departamento"],
["Zhang Di", "Hombre", "Chongqing", "Departamento de informática"],
["Lambo", "Hombre", "Jiangsu", "Departamento de ingeniería de comunicaciones"],
["Huang Fei", "Hombre", "Sichuan", "Departamento de Internet de las cosas"],
["Deng Yuchun", "Mujer", "Shaanxi", " Departamento de Ciencias de la Computación "],
[" Zhou Li "," 女 "," Tianjin "," Departamento de Arte "],
[" Li Yun "," 女 "," Shanghai "," Departamento de Idiomas Extranjeros "]
]
con abierto ('信息
Input.csv ',' w ', encoding = "utf8") como archivo: csvwriter = csv.writer (archivo, lineterminator =' \ n ')
csvwriter.writerows (prueba)
123456789101112
2.2 conversión de código csv a formato json
importar csv, json
csvfile = open ('D: \\ Anew \\ test.csv', 'r')
jsonfile = open ('D: \\ Anew \\ test.json', 'w')
nombres de campo = ('姓名 ',' 性别 ',' 籍贯 ',' 系 别 ')
reader = csv.DictReader (csvfile, fieldnames)
para la fila en el lector:
json.dump (row, jsonfile)
jsonfile.write (' \ n ')
12345678910
Dado que el archivo json tiene su propio efecto de cifrado, debe encontrar una herramienta de verificación de formato json en Internet. Esta vez se utiliza la herramienta BEJSON y el diagrama de visualización de verificación es el siguiente:
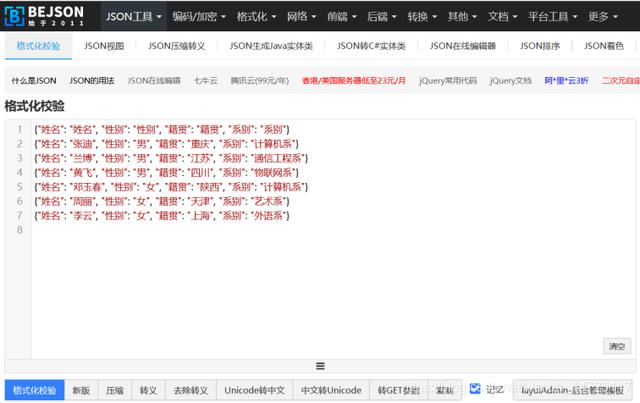
2.3 Consultar información sobre niñas en archivos
importar json
con open ('D: \\ Anew \\ 名单 .json', 'r') como f:
para la línea en f.readlines ():
línea = json.loads (línea)
if (línea ['性别'] == '女'):
imprimir (línea)
123456

Conversión de archivos en formato XML y JSon
3.1 (1) Lea el siguiente archivo de formato XML, el contenido es el siguiente:
<? xml version = ”1.0” encoding = ”gb2312”> <Libro> <Título del libro> Un sueño de mansiones rojas
Haga clic aquí para obtener el código completo del proyecto