Prefacio
El texto y las imágenes de este artículo provienen de Internet y son únicamente con fines de aprendizaje y comunicación. No tienen ningún uso comercial. Si tiene alguna pregunta, comuníquese con nosotros para su procesamiento.
PD: Si necesita materiales de aprendizaje de Python, puede hacer clic en el enlace de abajo para obtenerlo usted mismo.
Configuración del entorno relacionado
- pitón 3.6
- pycharm
- peticiones
- paquete o empaquetar
Se puede instalar el pip del módulo correspondiente
Determinar la página de destino

Quiero rastrear estas imágenes de material, por lo que primero debo comenzar desde el final, y primero debo saber la dirección de descarga del material
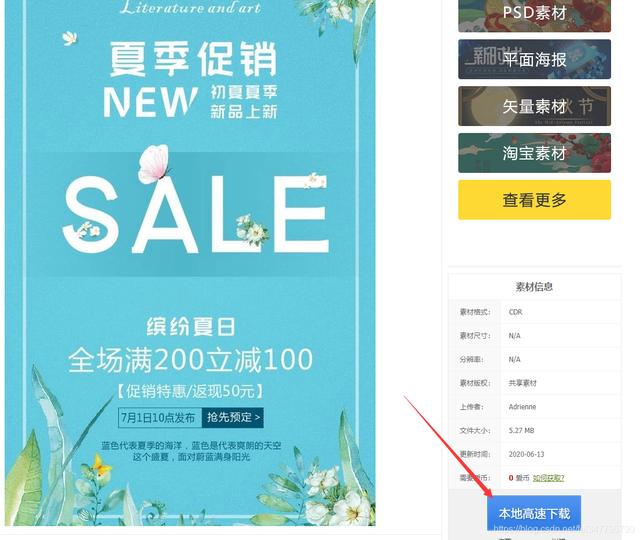
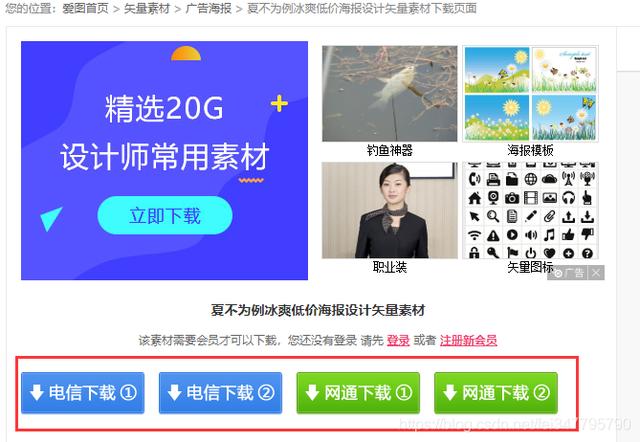
Al hacer clic en el material para ingresar a la página de detalles del material, puede ver la dirección de descarga local y copiar algunos enlaces de direcciones de descarga de material más:
http://www.aiimg.com/sucai.php?open=1&aid=126632&uhash=70a6d2ffc358f79d9cf71392 http://www.aiimg.com/sucai.php?open=1&aid=126630&uhash=99b07c347dc24533cc http: //www.aiimg. com / sucai.php? open = 1 & aid = 126634 & uhash = d7e8f7f02f57568e280190b4 123
La ayuda de cada enlace es diferente. Este debería ser el ID de cada material. ¿Qué es el uhash detrás?
Originalmente pensé si hay datos de interfaz en los datos de la página web. Este parámetro se puede encontrar directamente. La búsqueda en la herramienta para desarrolladores no tiene este parámetro. , Compruebe si existe este enlace de descarga en el código fuente de la página web ~
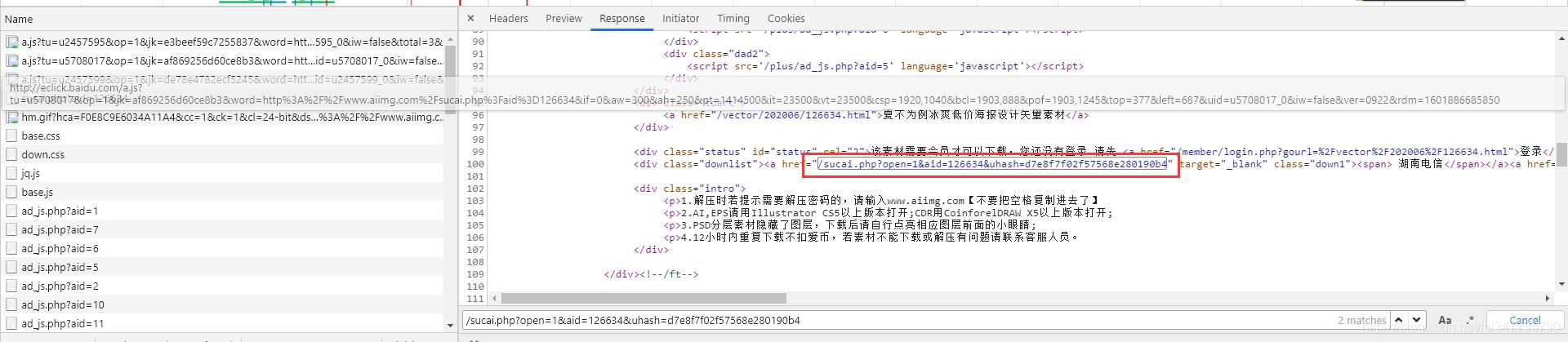
Si existe este enlace, podemos descargarlo directamente después de obtener el enlace ~
Operación de rutina:
1. Abra las herramientas de desarrollo y compruebe si la página web devuelve los datos que desea obtener.
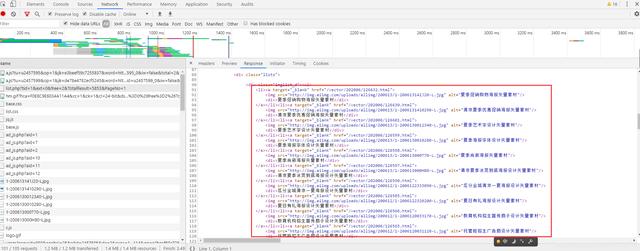
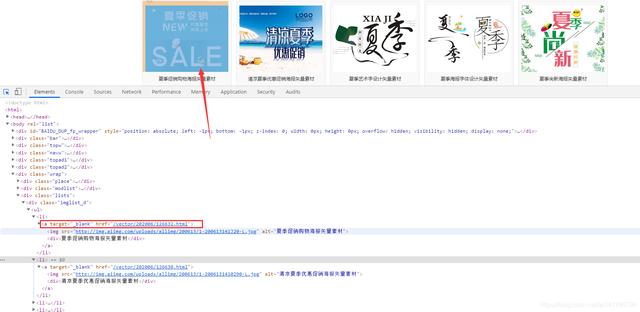
Se puede encontrar que los datos que necesitamos están en la pestaña de la página web, solicite la página web para obtener los datos devueltos.
solicitudes de importación
url = 'http://www.aiimg.com/list.php?tid=1&ext=0&free=2&TotalResult=5853&PageNo=1'
headers = {
'User-Agent': 'Mozilla / 5.0 (Windows NT 10.0; WOW64 ) AppleWebKit / 537.36 (KHTML, como Gecko) Chrome / 81.0.4044.138 Safari / 537.36 '
}
response = orders.get (url = url, headers = headers)
print (response.text)
1234567
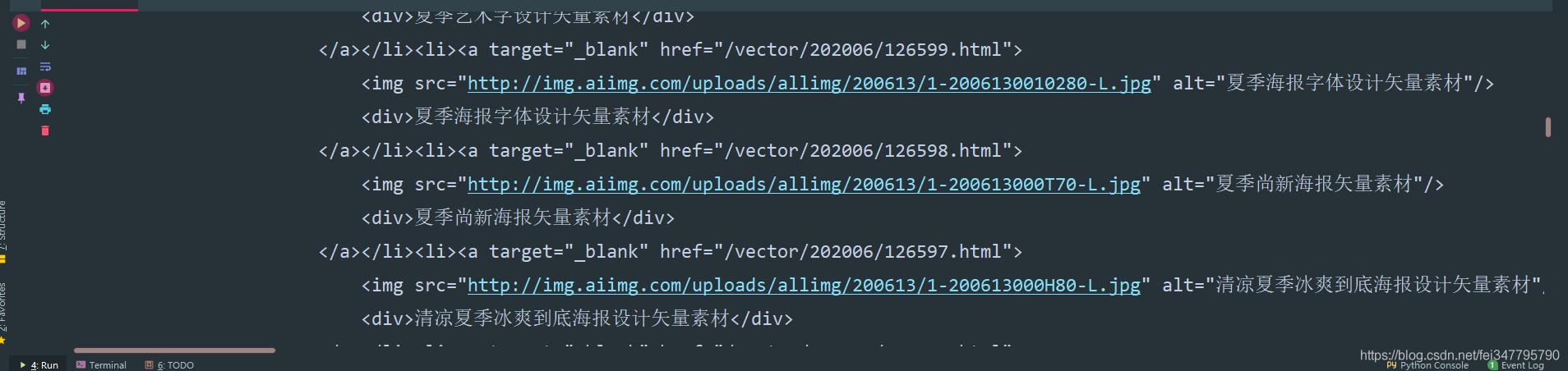
Analizar datos de páginas web
import
parsel selector = parsel.Selector (response.text)
lis = selector.css ('. imglist_d ul li a :: attr (href)'). getall ()
for li in lis:
num_id = li.replace ('. html ',' ') .split (' / ') [- 1]
new_url =' http://www.aiimg.com/sucai.php?aid={}'.format(num_id)
response_2 = orders.get (url = new_url, headers = headers)
selector_2 = parsel.Selector (response_2.text)
data_url = selector_2.css ('. downlist a.down1 :: attr (href)'). get ()
title = selector_2.css ('. toart a :: texto '). get ()
download_url =' http://www.aiimg.com '+ data_url
1234567891011
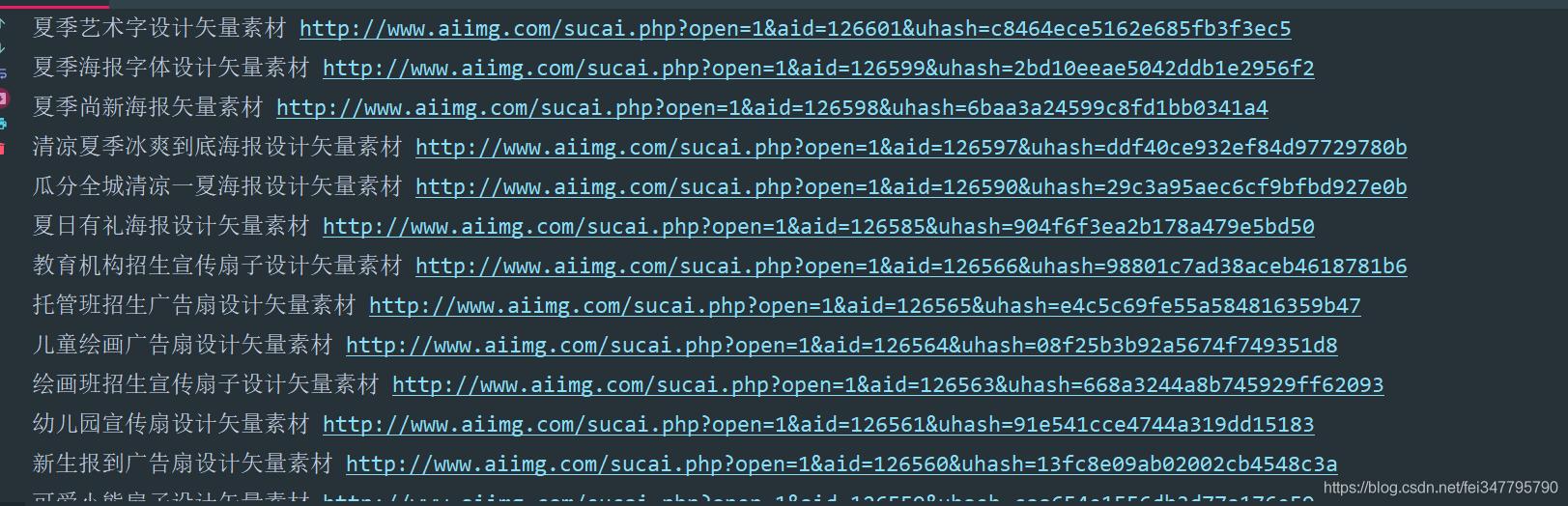
guardar datos
Los materiales son todos archivos psd, ai o cdr después de ser guardados en forma de paquete de compresión zip
def descargar (url, título):
ruta = '路径' + título + '.zip'
respuesta = solicitudes.get (url = url, encabezados = encabezados)
con abierto (ruta, modo = 'wb') como f:
f. escribir (respuesta.contenido)
imprimir ('{} 已经 下载 完成' .format (título))
123456

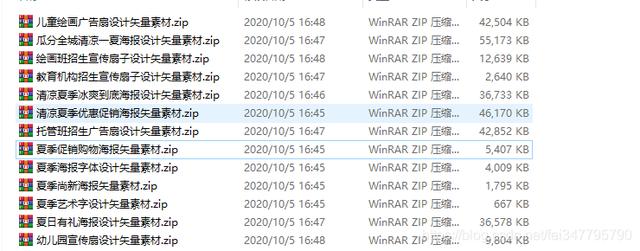

Este es solo un rastreo de una página, pero también un rastreo de varias páginas ~