¿Por qué aprender el código fuente de HashMap?
Como desarrollador de Java, básicamente las estructuras de datos más utilizadas son HashMap y List. El diseño del HashMap de jdk aún es digno de un estudio en profundidad.
Ya sea en una entrevista o en el trabajo, conocer los principios nos ayudará mucho.
El contenido de este artículo es más extenso, se recomienda recopilarlo primero y luego saborearlo con cuidado.
A diferencia del análisis de código fuente simple en Internet, se trata más de las ideas de diseño detrás de la implementación.
El contenido involucrado es bastante extenso, desde la distribución de Poisson en estadísticas, hasta operaciones de bits basadas en computadora, árboles rojos-negros clásicos, listas enlazadas, arreglos y otras estructuras de datos. También habla sobre la introducción de la función Hash. Al final del artículo, también se presenta Meituan. Para el análisis del código fuente de HashMap, la profundidad y amplitud generales son relativamente grandes.
El mapa mental es el siguiente:
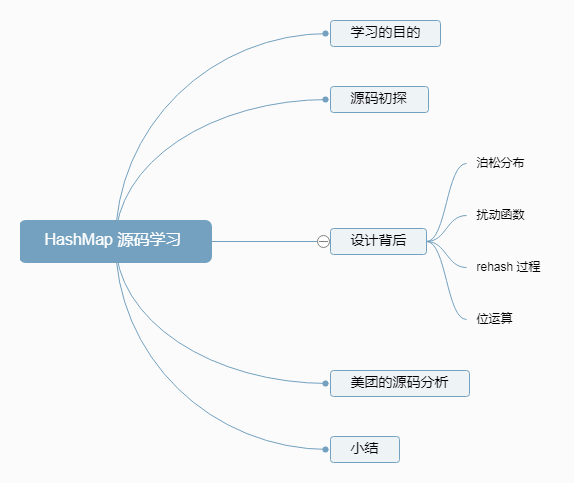
Este artículo fue compilado hace dos años . Es inevitable que haya omisiones y partes desactualizadas en el artículo. Agradecemos sus valiosos comentarios.
El motivo por el que se saca aquí tiene las siguientes finalidades:
(1) Permita que los lectores comprendan la idea de diseño de HashMap y conozcan el proceso de refrito. En la siguiente sección implementaremos un HashMap nosotros mismos
(2) ¿Por qué implementar HashMap usted mismo?
Recientemente, al escribir a mano el marco de redis, se dice que redis es un mapa con características más poderosas y, naturalmente, HashMap es la base para la entrada. Uno de los diseños sobresalientes de alto rendimiento de Redis es el refrito progresivo, y podemos implementar un mapa de refrito progresivo con todos, de modo que podamos apreciar y comprender el ingenioso diseño del autor.
Quiero que una estructura de datos común sea independiente como herramienta de código abierto para su uso posterior. Por ejemplo, esta vez los redis de escritura a mano, la lista enlazada circular, el mapa LRU, etc. están escritos desde cero, lo que no es propicio para la reutilización y es propenso a errores.
Bien, comencemos juntos el viaje del código fuente de HashMap ~
Código fuente de HashMap
HashMap es una clase de colección que generalmente se usa mucho y se siente necesario aprender más.
Primero intente leer el código fuente usted mismo.
versión java
$ java -version
java version "1.8.0_91"
Java(TM) SE Runtime Environment (build 1.8.0_91-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.91-b14, mixed mode)estructura de datos
En términos de realización estructural, HashMap se realiza mediante matriz + lista enlazada + árbol rojo-negro (JDK1.8 agrega la parte del árbol rojo-negro ).
Descripción oficial de la clase actual
Interfaz de mapeo basada en implementación de tabla hash. Esta implementación proporciona todas las operaciones de mapeo opcionales y permite valores y claves nulos. (La clase HashMap es aproximadamente equivalente a Hashtable, pero es asincrónica y se permite que esté vacía).
Esta clase no garantiza el orden del mapeo; en particular, no garantiza que el orden permanecerá igual a lo largo del tiempo.
Esta implementación proporciona un rendimiento en tiempo constante para operaciones básicas (obtener y poner), asumiendo que la función hash distribuye adecuadamente los elementos en cada depósito. La iteración de la vista de colección requiere un tiempo proporcional a la "capacidad" (número de depósitos) de la instancia de HashMap y su tamaño (número de asignaciones de clave-valor). Por lo tanto, si el rendimiento iterativo es importante, es muy importante no establecer la capacidad inicial demasiado alta (o el factor de carga es demasiado bajo).
La instancia de HashMap tiene dos parámetros que afectan su rendimiento: capacidad inicial y factor de carga .
La capacidad es la cantidad de cubos en la tabla hash y la capacidad inicial es solo la capacidad cuando se crea la tabla hash. El factor de carga es una medida de la capacidad máxima que puede alcanzar la tabla hash antes de que la capacidad de la tabla hash aumente automáticamente. Cuando el número de entradas en la tabla hash excede el producto del factor de carga y la capacidad actual, la tabla hash se volverá a generar hash (es decir, se reconstruirá la estructura de datos internos), de modo que el número de cubos en la tabla hash sea aproximadamente el original doble.
En términos generales, el factor de carga predeterminado ( 0.75) proporciona una buena compensación entre el tiempo y el costo del espacio.
Un valor más alto reduce la sobrecarga de espacio, pero aumenta el costo de búsqueda (reflejado en la mayoría de las operaciones de la clase HashMap, incluidas obtener y poner). Al establecer la capacidad inicial del mapa, se debe considerar el número esperado de entradas en el mapa y su factor de carga para minimizar el número de operaciones de refrito. Si la capacidad inicial es mayor que el número máximo de entradas dividido por el factor de carga, no ocurrirá ninguna operación de refrito.
Si desea almacenar muchos mapas en una instancia de HashMap, la creación de un mapa con una capacidad lo suficientemente grande hará que el almacenamiento del mapa sea más eficiente, en lugar de permitirle realizar un refrito automático según sea necesario para hacer crecer la tabla.
Tenga en cuenta que el uso de varias claves con el mismo hashCode () puede reducir el rendimiento de cualquier tabla hash. Para mejorar el impacto, cuando las claves son comparables, esta clase puede utilizar el orden de comparación entre las claves para ayudar a desconectar.
Tenga en cuenta que esta implementación no es síncrona. Si varios subprocesos acceden al mapa hash al mismo tiempo y al menos un subproceso modifica el mapa estructuralmente, entonces debe sincronizarse externamente. (La modificación estructural es cualquier operación que agrega o elimina una o más asignaciones; solo cambiar el valor asociado con la clave ya contenida en la instancia no es una modificación estructural. Esto generalmente se hace sincronizando los objetos que naturalmente encapsulan la asignación.
Si no existe tal objeto, debe utilizar el método de colección "contenedor" Collections.synchronizedMap. Esto se hace mejor en el momento de la creación para evitar el acceso asincrónico accidental al mapa:
Map m = Collections.synchronizedMap(new HashMap(...));Todos los iteradores devueltos por los "métodos de vista de colección" de esta clase fallan rápidamente: si el mapeo se modifica en cualquier momento después de que se crea el iterador, excepto a través del propio método remove del iterador, el iterador arrojará ConcurrentModificationException. Por lo tanto, en el caso de una modificación concurrente, el iterador fallará rápida y limpiamente, en lugar de arriesgar un comportamiento arbitrario e incierto en un momento incierto en el futuro.
Tenga en cuenta que no se puede garantizar el comportamiento de falla rápido de los iteradores, porque en general, es imposible hacer garantías estrictas en presencia de modificaciones concurrentes asíncronas. El iterador de falla rápida arroja ConcurrentModificationException de la mejor manera. Por lo tanto, es incorrecto escribir programas que se basen en esta excepción para garantizar su corrección: el comportamiento de falla rápida del iterador solo debe usarse para detectar errores.
Otra información básica
-
Esta clase es miembro del marco de la colección de Java.
-
@desde 1.2
- paquete java.util
Exploración inicial del código fuente
interfaz
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {}La clase actual implementa tres interfaces, nos preocupa principalmente Mapla interfaz que puede ser.
Heredado de una clase abstracta AbstractMap, esto se estudiará temporalmente más adelante en esta sección.
Definición constante
Capacidad inicial predeterminada
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16- ¿Por qué no usar 16 directamente?
Después de leer statckoverflow, la explicación más confiable es:
-
Para evitar el uso de números mágicos, la definición constante en sí tiene un significado que se explica por sí mismo.
- Enfatice que este número debe ser una potencia de 2.
- ¿Por qué es una potencia de 2?
Está diseñado de esta manera porque permite el uso de operaciones rápidas de suma de bits para empaquetar el código hash de cada clave en la capacidad de la tabla, como puede ver en el método de acceso a la tabla:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { /// <-- bitwise 'AND' here
...Maxima capacidad
La capacidad máxima utilizada cuando se especifica implícitamente un valor más alto.
Por cualquier constructor con parámetros.
Debe ser una potencia de 2 e inferior a 1 << 30.
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;- ¿Por qué es 1 << 30?
Por supuesto, la capacidad máxima del interger es 2^31-1
Además, 2 ** 31 es 2 mil millones, y cada entrada hash requiere un objeto como entrada en sí, un objeto como clave y un objeto como valor.
Antes de asignar espacio para otro contenido en la aplicación, el tamaño mínimo del objeto suele ser de alrededor de 24 bytes, por lo que serán 144 mil millones de bytes.
Es seguro decir que el límite de capacidad máxima es solo teórico.
¡Siento que la memoria real no es tan grande!
Factor de carga
Cuando el factor de carga es grande, la posibilidad de expandir la matriz de la tabla será menor, por lo que ocupará menos memoria (menos espacio), pero habrá relativamente más elementos en cada cadena de entrada y el tiempo de consulta también será Aumentar (más tiempo).
Por el contrario, cuando el factor de carga es pequeño, la posibilidad de expandir la matriz de la tabla es alta y el espacio de memoria está ocupado, pero los elementos de la cadena de entrada serán relativamente pequeños y el tiempo para averiguarlo se reducirá.
Es por eso que el factor de carga es un compromiso entre el tiempo y el espacio.
Entonces, al establecer el factor de carga, debe considerar si está buscando tiempo o espacio.
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;- ¿Por qué es 0,75, no 0,8 o 0,6?
De hecho, hay una explicación en el código fuente de hashmap.
Because TreeNodes are about twice the size of regular nodes, we
use them only when bins contain enough nodes to warrant use
(see TREEIFY_THRESHOLD). And when they become too small (due to
removal or resizing) they are converted back to plain bins. In
usages with well-distributed user hashCodes, tree bins are
rarely used. Ideally, under random hashCodes, the frequency of
nodes in bins follows a Poisson distribution
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
parameter of about 0.5 on average for the default resizing
threshold of 0.75, although with a large variance because of
resizing granularity. Ignoring variance, the expected
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
factorial(k)). The first values are:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.00000006
more: less than 1 in ten millionUna traducción simple es que, en circunstancias ideales, utilizando códigos hash aleatorios, la frecuencia de aparición de los nodos en el cubo de hash sigue la distribución de Poisson, y se proporciona una tabla de comparación del número y la probabilidad de los elementos en el cubo.
En la tabla anterior, se puede ver que cuando el número de elementos en el cubo llega a 8, la probabilidad se ha vuelto muy pequeña, es decir, usando 0,75 como factor de carga, es casi imposible que la longitud de la lista enlazada de cada lugar de colisión supere los 8.
Distribución de Poisson-distribución de Poisson
Límite
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;TREEIFY_THRESHOLD
Utilice árboles rojo-negro en lugar de la lista de umbrales de recuento de contenedores.
Cuando se agrega un elemento a un contenedor con al menos este número de nodos, el contenedor se convierte en un árbol. Este valor debe ser mayor que 2, y debe ser al menos 8, para que coincida con la suposición en la eliminación del árbol sobre la conversión de nuevo a un contenedor normal después de la reducción.
UNTREEIFY_THRESHOLD
Cancele (divida) el umbral de recuento de almacenamiento del repositorio durante la operación de cambio de tamaño.
Debe ser menor que TREEIFY_THRESHOLD y se eliminan hasta 6 cuadrículas con detección de contracción.
MIN_TREEIFY_CAPACITY
La capacidad más pequeña de la mesa se puede colocar en un árbol para el contenedor. (De lo contrario, si hay demasiados nodos en un contenedor, se cambiará el tamaño de la tabla).
Al menos 4 * TREEIFY_THRESHOLD, para evitar conflictos entre el cambio de tamaño y los umbrales de árbol.
Nodo
Código fuente
- Node.java
Definición del nodo hash básico.
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
// 快速判断
if (o == this)
return true;
// 类型判断
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}Comprensión personal
Cuatro elementos centrales:
final int hash; // hash 值
final K key; // key
V value; // value 值
Node<K,V> next; // 下一个元素结点Algoritmo de valor hash
El algoritmo hash es el siguiente.
XOR ( ^) de clave / valor directo .
Objects.hashCode(key) ^ Objects.hashCode(value);El método hashCode () es el siguiente:
public static int hashCode(Object o) {
return o != null ? o.hashCode() : 0;
}Finalmente, se llama al algoritmo hashCode () del propio objeto. Generalmente lo definiremos nosotros mismos.
Herramientas estáticas
picadillo
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}¿Por qué está tan diseñado?
- jdk8 viene con una explicación
Calcule key.hashCode () y esparza los bits altos de (XOR) a los bits bajos.
Debido a que la tabla usa enmascaramiento de potencia de dos, los hash que solo cambian en bits por encima de la máscara actual siempre entrarán en conflicto.
(El ejemplo conocido tiene un conjunto de claves de punto flotante, que almacenan enteros consecutivos en una pequeña tabla).
Por lo tanto, aplicamos una conversión para propagar los efectos de los bits altos hacia abajo.
Existe una compensación entre la velocidad, la utilidad y la calidad de la propagación de bits.
Debido a que muchos conjuntos de hash comunes se han distribuido razonablemente (por lo que no se benefician de la propagación), debido a que usamos árboles para manejar grandes colisiones en el bote de basura, simplemente XOR algunos cambios para reducir la pérdida del sistema de la manera más barata y en la posición más alta. El impacto nunca se debe a la tabla utilizada en el cálculo del índice.
- La explicación de Zhihu
Este código se llama función de perturbación .
El tamaño inicial de la matriz antes de la expansión de HashMap era solo 16. Por tanto, este valor hash no se puede utilizar directamente.
Antes de usar, es necesario realizar una operación de módulo en la longitud de la matriz, y el resto se puede usar para acceder al subíndice de la matriz.
putVal Código fuente de la función
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//...
}Una oración tab[i = (n - 1) & hash])
Este paso es el proceso de búsqueda de cubos, que es el grupo de números total en la figura anterior. Si la capacidad es 16 y el valor hash es menor de 16 bits según la capacidad, entonces el rango del subíndice está dentro del rango de capacidad.
Esto también explica por qué el tamaño del mapa hash debe ser una potencia entera positiva de 2, porque esto (longitud de matriz-1) es exactamente equivalente a una "máscara baja".
Por ejemplo, el tamaño es 16, luego (16-1) = 15 = 00000000 00000000 00001111 (binario);
10100101 11000100 00100101
& 00000000 00000000 00001111
-------------------------------
00000000 00000000 00000101 //高位全部归零,只保留末四位Pero el problema es que no importa cuán suelta sea la distribución de los valores hash, si solo se toman los últimos bits, la colisión será muy grave.
El valor de la función de perturbación es el siguiente:
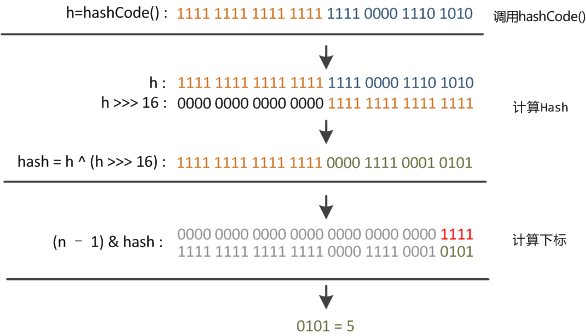
El desplazamiento a la derecha es de 16 bits, que es exactamente la mitad del bit 32. El XOR de la mitad alta y la mitad baja es para mezclar los bits altos y bajos del código hash original para aumentar la aleatoriedad de los bits bajos.
Además, las funciones mixtas de bajo nivel se dopan con funciones de alto nivel, de modo que la información de alto nivel también se retiene disfrazada.
Introducción al principio de hash optimizado
clase comparable
- comparableClassFor ()
Obtenga un objeto de clase x, y si esta clase implementa class C implements Comparable<C>la interfaz.
ps: este método es muy útil como referencia y se puede ampliar fácilmente. Podemos obtener el tipo en cualquier interfaz genérica.
static Class<?> comparableClassFor(Object x) {
if (x instanceof Comparable) {
Class<?> c; Type[] ts, as; Type t; ParameterizedType p;
if ((c = x.getClass()) == String.class) // bypass checks
return c;
if ((ts = c.getGenericInterfaces()) != null) {
for (int i = 0; i < ts.length; ++i) {
if (((t = ts[i]) instanceof ParameterizedType) &&
((p = (ParameterizedType)t).getRawType() ==
Comparable.class) &&
(as = p.getActualTypeArguments()) != null &&
as.length == 1 && as[0] == c) // type arg is c
return c;
}
}
}
return null;
}compareComparables()
Obtenga el resultado de la comparación de dos objetos comparables.
@SuppressWarnings({"rawtypes","unchecked"}) // for cast to Comparable
static int compareComparables(Class<?> kc, Object k, Object x) {
return (x == null || x.getClass() != kc ? 0 :
((Comparable)k).compareTo(x));
}tableSizeFor
Obtén el poder de 2
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}- Lugar llamado
public HashMap(int initialCapacity, float loadFactor) {
// check...
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}- Impresiones
emmm .... ¿Por qué escribes esto? ¿Actuación?
Análisis simple
Al crear una instancia de HashMap, si se da initialCapacity, ya que la capacidad de HashMap es una potencia de 2, este método se usa para encontrar la potencia más pequeña de 2 que es mayor o igual a la initialCapacity (si initialCapacity es una potencia de 2, devolverá Todavía este número).
- Por qué -1
int n = cap - 1;
En primer lugar, ¿por qué quiere restar 1 del límite? int n = cap-1;
Esto es para evitar que cap ya sea una potencia de 2. Si el límite ya es una potencia de 2 y esta operación menos 1 no se realiza, después de realizar las siguientes operaciones de desplazamiento a la derecha sin firmar, la capacidad devuelta será el doble del límite. Si no lo entiende, debe mirar los siguientes turnos a la derecha sin firmar y luego regresar.
Echemos un vistazo a estas operaciones de desplazamiento a la derecha sin firmar:
Si n es 0 en este momento (después de cap-1), el desplazamiento a la derecha sin firmar sigue siendo 0 después de los siguientes desplazamientos sin firmar y la capacidad final devuelta es 1 (hay una operación n + 1 al final).
Aquí solo se analiza el caso en el que n no es igual a 0.
- Operación de primer bit
n |= n >>> 1;
Dado que n no es igual a 0, siempre habrá un bit de 1 en la representación binaria de n, y luego se considerará el bit más alto de 1.
Mediante un desplazamiento a la derecha sin signo en 1 bit, el 1 más significativo se desplaza a la derecha en 1 bit, y luego se realiza la operación OR de modo que el bit derecho junto al 1 más significativo en la representación binaria de n también sea 1, como 000011xxxxxx.
Y así
Ejemplo
Por ejemplo, initialCapacity = 10;
表达式 二进制
------------------------------------------------------
initialCapacity = 10;
int n = 9; 0000 1001
------------------------------------------------------
n |= n >>> 1; 0000 1001
0000 0100 (右移1位) 或运算
= 0000 1101
------------------------------------------------------
n |= n >>> 2; 0000 1101
0000 0011 (右移2位) 或运算
= 0000 1111
------------------------------------------------------
n |= n >>> 4; 0000 1111
0000 0000 (右移4位) 或运算
= 0000 1111
------------------------------------------------------
n |= n >>> 8; 0000 1111
0000 0000 (右移8位) 或运算
= 0000 1111
------------------------------------------------------
n |= n >>> 16; 0000 1111
0000 0000 (右移16位) 或运算
= 0000 1111
------------------------------------------------------
n = n+1; 0001 0000 结果:2^4 = 16; poner () explicado
El siguiente contenido es de la serie Java 8 del blog de Meituan : Recognizing HashMap
Como está muy bien escrito, lo copié aquí directamente.
Explicación del diagrama de flujo
El proceso de ejecución del método put de HashMap se puede entender en la siguiente figura, si estás interesado puedes comparar el código fuente y estudiarlo con mayor claridad.
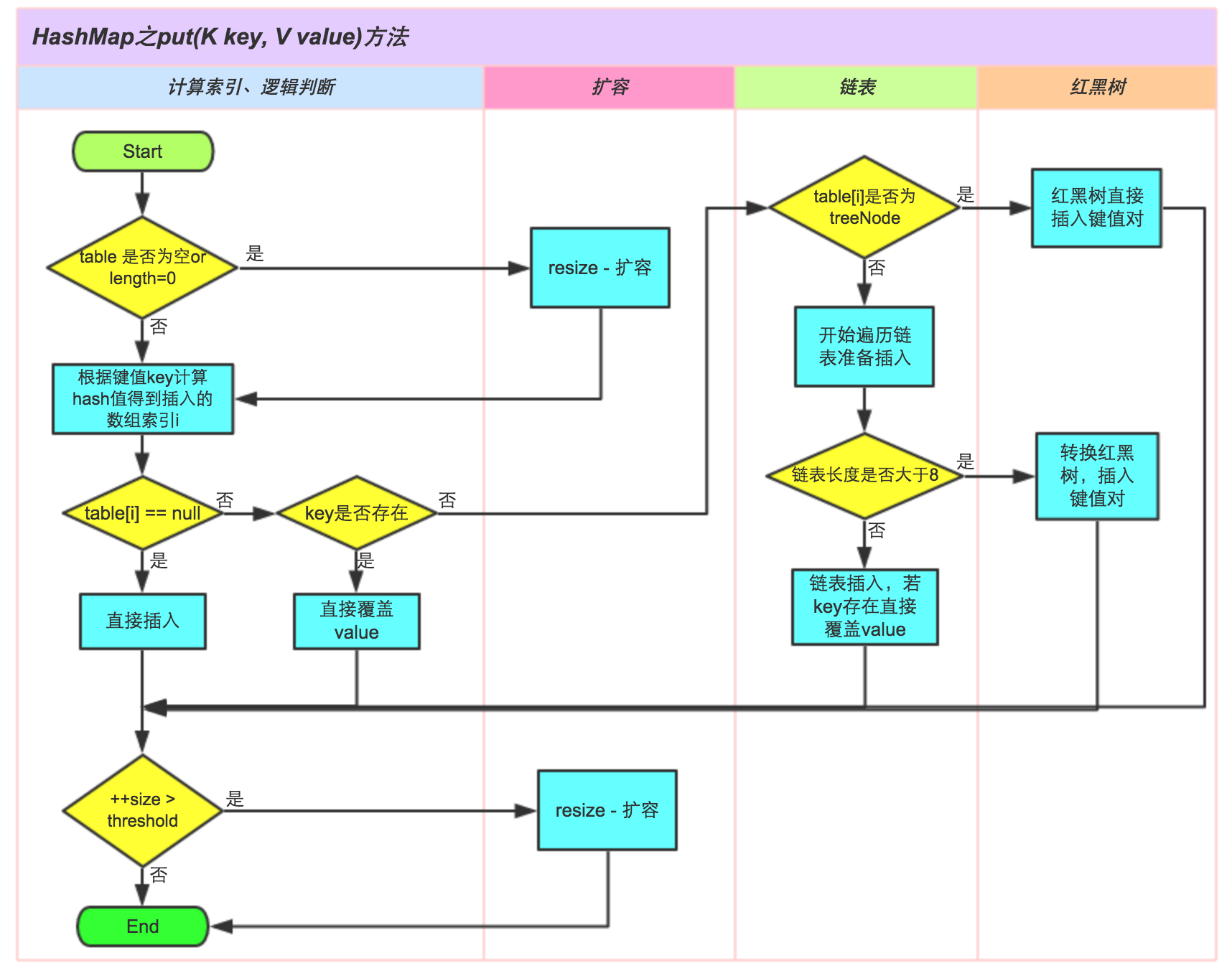
①. Determine si la tabla de matriz de pares clave-valor [i] está vacía o nula, de lo contrario, ejecute resize () para expandir;
②. Calcule el valor hash de acuerdo con la clave de valor clave para obtener el índice de matriz insertado i, si la tabla [i] == nula, cree directamente un nuevo nodo para agregar, vaya a ⑥, si la tabla [i] no está vacía, vaya a ③;
③. Juzgue si el primer elemento de la tabla [i] es el mismo que la clave, si es el mismo, sobrescriba directamente el valor, de lo contrario vaya a ④, donde lo mismo se refiere a hashCode y es igual a;
④. Determine si la tabla [i] es un treeNode, es decir, si la tabla [i] es un árbol rojo-negro, si es un árbol rojo-negro, inserte el par clave-valor directamente en el árbol, de lo contrario, vaya a ⑤;
⑤. Tabla transversal [i], determine si la longitud de la lista vinculada es mayor que 8, si es mayor que 8, convierta la lista vinculada a un árbol rojo-negro y realice la operación de inserción en el árbol rojo-negro; de lo contrario, realice la operación de inserción de la lista vinculada; si la clave ya existe durante el proceso de recorrido Simplemente sobrescriba el valor directamente;
⑥. Una vez que la inserción se haya realizado correctamente, juzgue si el número real de pares clave-valor supera el umbral de capacidad máxima y, si lo supera, amplíe la capacidad.
Código fuente del método
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}Mecanismo de expansión
Introducción
Cambiar el tamaño es recalcular la capacidad y agregar elementos al objeto HashMap continuamente, y cuando la matriz dentro del objeto HashMap no puede cargar más elementos, el objeto necesita expandir la longitud de la matriz para que se puedan cargar más elementos.
Por supuesto, la matriz en Java no se puede expandir automáticamente. El método es usar una nueva matriz para reemplazar la matriz existente con una capacidad pequeña, al igual que usamos un balde pequeño para almacenar agua. Si queremos almacenar más agua, tenemos que cambiar el balde grande. .
Código fuente JDK7
Analicemos el código fuente de resize (), dado que JDK1.8 está integrado en el árbol rojo-negro, que es más complicado, seguimos utilizando el código de JDK1.7 para facilitar la comprensión.
void resize(int newCapacity) { //传入新的容量
Entry[] oldTable = table; //引用扩容前的Entry数组
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) { //扩容前的数组大小如果已经达到最大(2^30)了
threshold = Integer.MAX_VALUE; //修改阈值为int的最大值(2^31-1),这样以后就不会扩容了
return;
}
Entry[] newTable = new Entry[newCapacity]; //初始化一个新的Entry数组
transfer(newTable); //!!将数据转移到新的Entry数组里
table = newTable; //HashMap的table属性引用新的Entry数组
threshold = (int)(newCapacity * loadFactor);//修改阈值
}Aquí se utiliza una matriz de mayor capacidad para reemplazar la matriz de menor capacidad existente El método transfer () copia los elementos de la matriz Entry original a la nueva matriz Entry.
void transfer(Entry[] newTable) {
Entry[] src = table; //src引用了旧的Entry数组
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) { //遍历旧的Entry数组
Entry<K,V> e = src[j]; //取得旧Entry数组的每个元素
if (e != null) {
src[j] = null;//释放旧Entry数组的对象引用(for循环后,旧的Entry数组不再引用任何对象)
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity); //!!重新计算每个元素在数组中的位置
e.next = newTable[i]; //标记[1]
newTable[i] = e; //将元素放在数组上
e = next; //访问下一个Entry链上的元素
} while (e != null);
}
}
}La referencia de newTable [i] se asigna a e.next, es decir, se utiliza el método de inserción de encabezado de una lista enlazada individualmente, y el nuevo elemento en la misma posición siempre se coloca al principio de la lista enlazada;
De esta forma, el elemento colocado primero en un índice eventualmente se ubicará al final de la cadena de Entrada (si ocurre un conflicto de hash), esto es diferente de Jdk 1.8, que se explica en detalle a continuación.
Los elementos de la misma cadena de entrada en la matriz anterior se pueden colocar en diferentes posiciones en la nueva matriz después de recalcular la posición del índice.
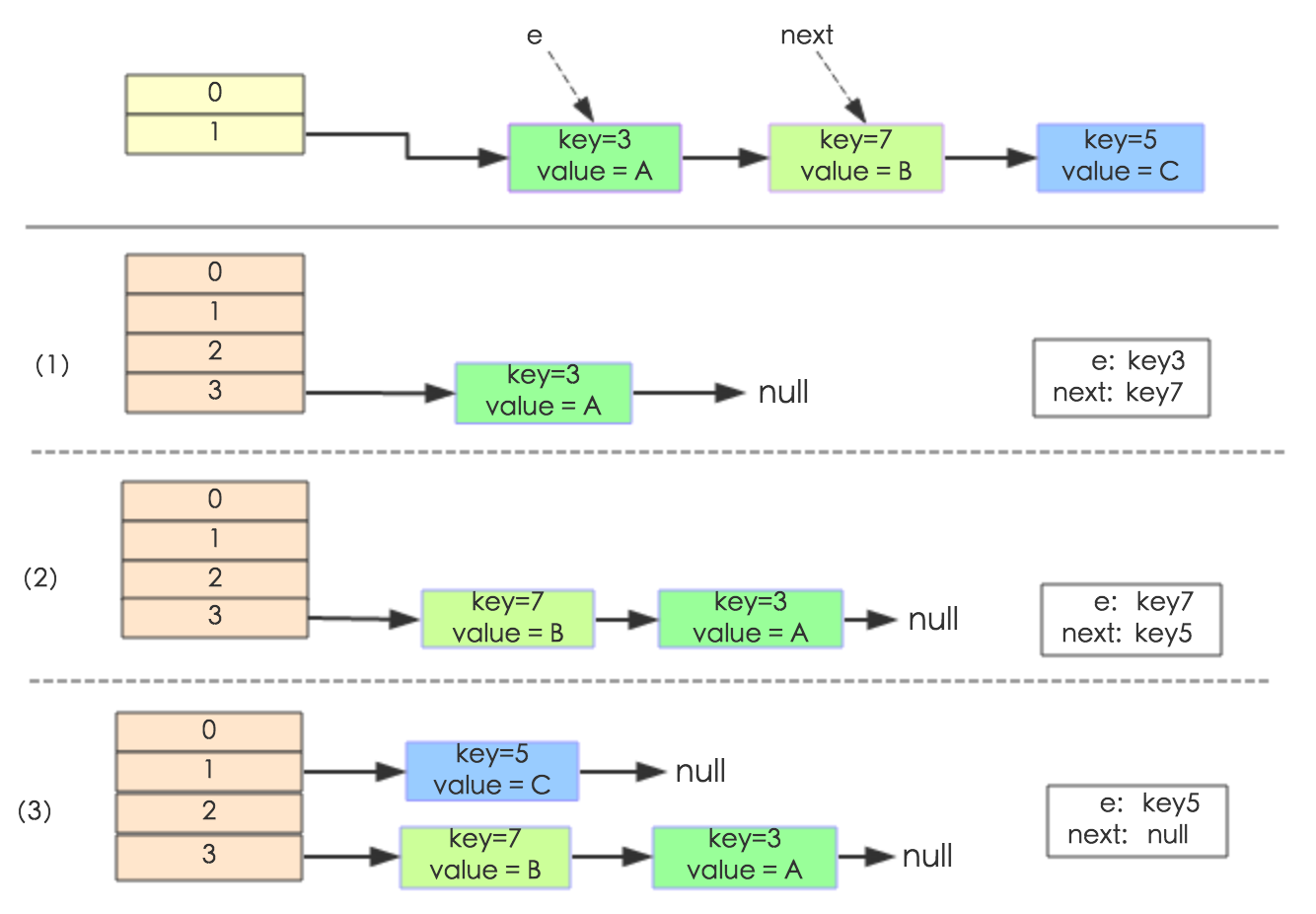
Caso
A continuación se muestra un ejemplo para ilustrar el proceso de expansión. Supongamos que nuestro algoritmo hash es simplemente el tamaño de la tabla (es decir, la longitud de la matriz) usando key mod.
El tamaño de la tabla de matriz de cubos hash es 2, por lo que key = 3, 7, 5 y el orden de venta es 5, 7 y 3.
Después del mod 2, todos los conflictos están en la tabla [1].
Se supone que el factor de carga loadFactor = 1, es decir, cuando el tamaño real del par clave-valor es mayor que el tamaño real de la tabla, la capacidad se expande.
Los siguientes tres pasos son el proceso de cambiar el tamaño de la matriz de cubos hash a 4 y luego volver a hacer un refrito de todos los nodos.
Optimización jdk8
Después de la observación, podemos encontrar que estamos usando la expansión de la potencia de 2 (lo que significa que la longitud se expande 2 veces), por lo que la posición del elemento está en la posición original o se mueve a la posición de la potencia de 2 en la posición original.
Mire la figura a continuación para comprender el significado de esta oración, n es la longitud de la tabla, la figura (a) muestra un ejemplo de cómo determinar la posición de índice de las dos claves antes de la expansión, clave1 y clave2.
La figura (b) muestra un ejemplo en el que dos claves, clave1 y clave2, determinan la posición del índice después de la expansión, donde hash1 es el hash y el resultado de la operación de orden superior correspondiente a clave1.
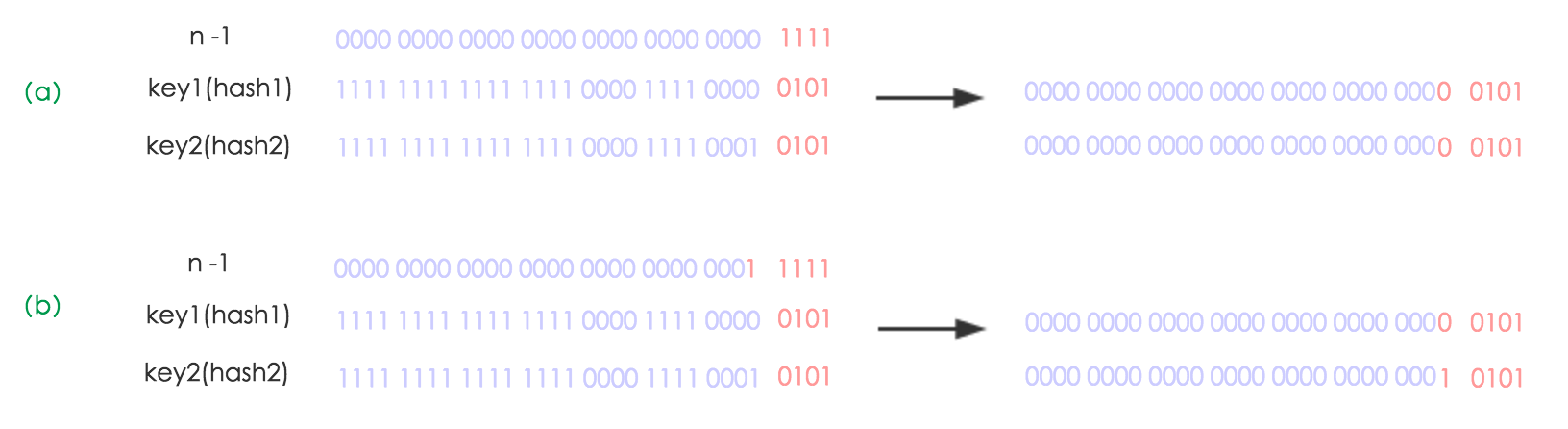
Después de que el elemento recalcula el hash, debido a que n se duplica, el rango de máscara de n-1 es 1 bit (rojo) más alto, por lo que el nuevo índice cambiará así:
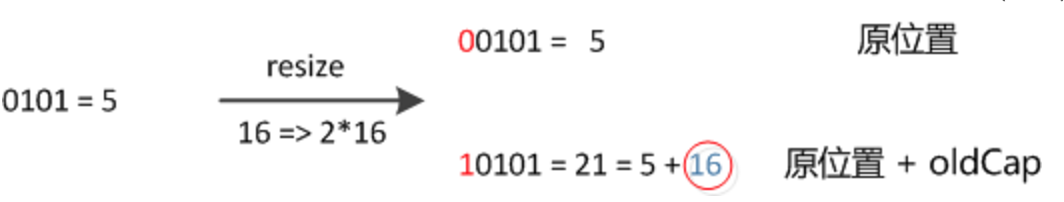
Por lo tanto, cuando expandimos el HashMap, no necesitamos recalcular el hash como la implementación de JDK1.7. Solo necesitamos ver si el bit agregado por el valor hash original es 1 o 0. Si es 0, el índice permanece sin cambios. Si es 1, el índice se convierte en "índice original + oldCap", puede ver el diagrama de cambio de tamaño de 16 expandido a 32 en la siguiente figura:
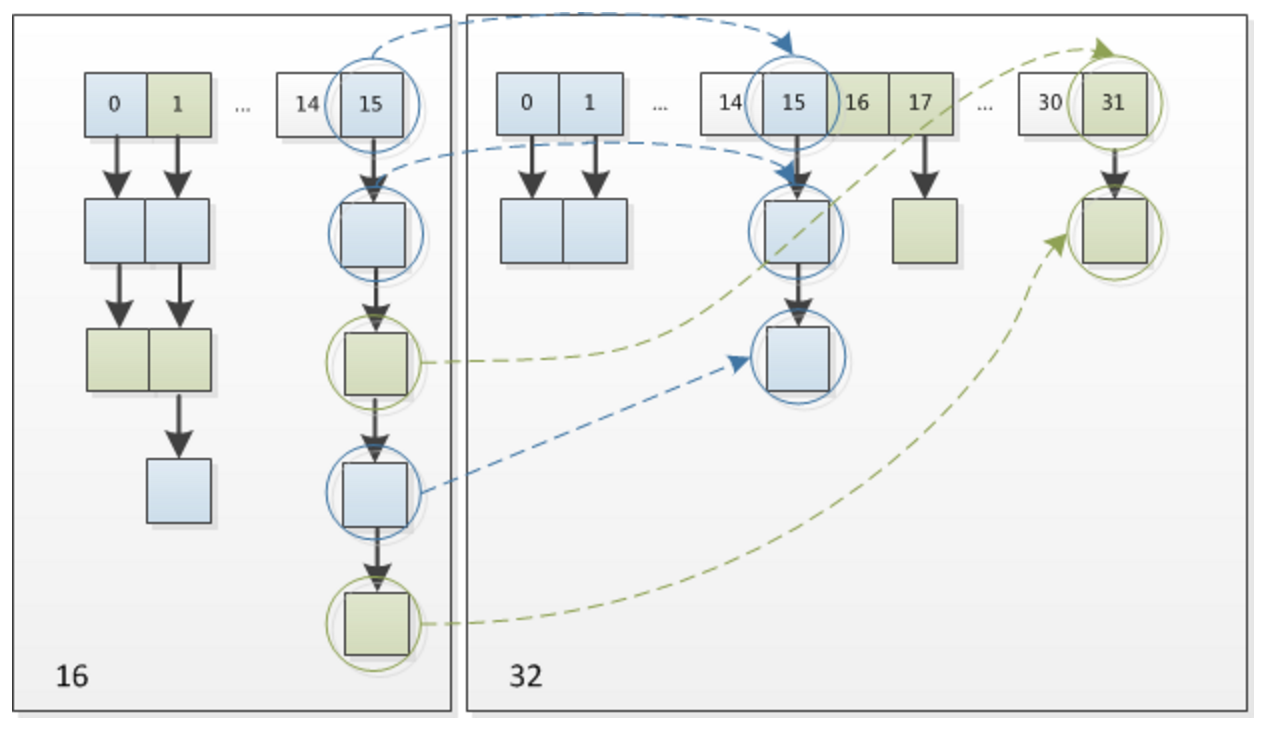
Este diseño es realmente muy inteligente, no solo ahorra tiempo para volver a calcular el valor hash y, al mismo tiempo, porque el nuevo 1 bit es 0 o 1 puede considerarse aleatorio, por lo que el proceso de cambio de tamaño distribuye uniformemente los nodos en conflicto anteriores Al cubo nuevo.
Este es el nuevo punto de optimización de JDK1.8.
Una cosa a la que hay que prestar atención es la diferencia. Cuando se repite en JDK1.7, cuando la antigua lista vinculada se migra a la nueva lista vinculada, si la posición del índice de matriz de la nueva tabla es la misma, los elementos de la lista vinculada se invertirán, pero como se puede ver en la figura anterior, JDK1.8 no lo hará. Al revés.
Código fuente JDK8
Los estudiantes interesados pueden estudiar el código fuente de cambio de tamaño de JDK1.8, que es muy bueno:
/**
* Initializes or doubles table size. If null, allocates in
* accord with initial capacity target held in field threshold.
* Otherwise, because we are using power-of-two expansion, the
* elements from each bin must either stay at same index, or move
* with a power of two offset in the new table.
*
* @return the table
*/
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}resumen
Si has leído el texto completo, ya eres muy bueno.
De hecho, no importa si no lo entiende completamente la primera vez, solo sepa que HashMap tiene un proceso de reHash, similar al cambio de tamaño de ArrayList.
En la siguiente sección, aprenderemos cómo implementar un refrito progresivo de HashMap a mano, si estás interesado, puedes prestarle atención para recibir el contenido más reciente en tiempo real.
Si cree que este artículo es útil para usted, por favor, comente, marque como favorito y reenvíe una ola. Tu aliento es mi mayor motivación ~
No sé lo que has ganado O si tiene más ideas, bienvenido a discutir conmigo en el área de mensajes y esperamos conocer sus pensamientos.
