Sorprendido por el salario mensual original de 5.5k, también puede optimizar la paginación de decenas de millones de tablas
Prefacio
Libro conectado a Wen sorprendido de que también sería capaz de optimizar mysql 5.5k diez millones de salario,
este artículo es correcto, confirme algunos puntos de lo anterior y explique optimizar el mecanismo de operación de paginación
■ Tarea
Optimización y transformación lenta de SQL, transformación del rendimiento del mecanismo de paginación de datos de tablas grandes y mejora de la velocidad de consulta de big data
Antes de disolver dudas
Los siguientes son los índices btree de InnoDB
■ 1. ¿Cuándo elige el optimizador de consultas no utilizar el índice de rango?
La declaración anterior :
Cuando no indexar es más rápido, el optimizador de consultas elige no indexar. El intervalo de tiempo es un ejemplo. Se dice que no funcionará si la selectividad es inferior al 17%. Los detalles no se han verificado. Intenté no indexar cuando el intervalo de tiempo es demasiado grande, pero cuando lo obligo a indexar, la velocidad seguirá siendo Es mucho más rápido, por lo que mi declaración no es muy precisa.
Corregir y responder:
El optimizador de consultas de mysql estimará el plan de ejecución óptimo que piensa en función del modelo de costo de la consulta. Esta parte es más complicada, habrá muchas operaciones mágicas, pero lo cierto es que el optimizador de consultas elige el mejor plan de ejecución en el plan de estimación de costos (puede que no compare todos los planes, por lo que a veces no será el más Excelente solución), en lugar de elegir el plan de consulta más rápido, no se trata simplemente de no ir a un área grande.
Mire el siguiente ejemplo:
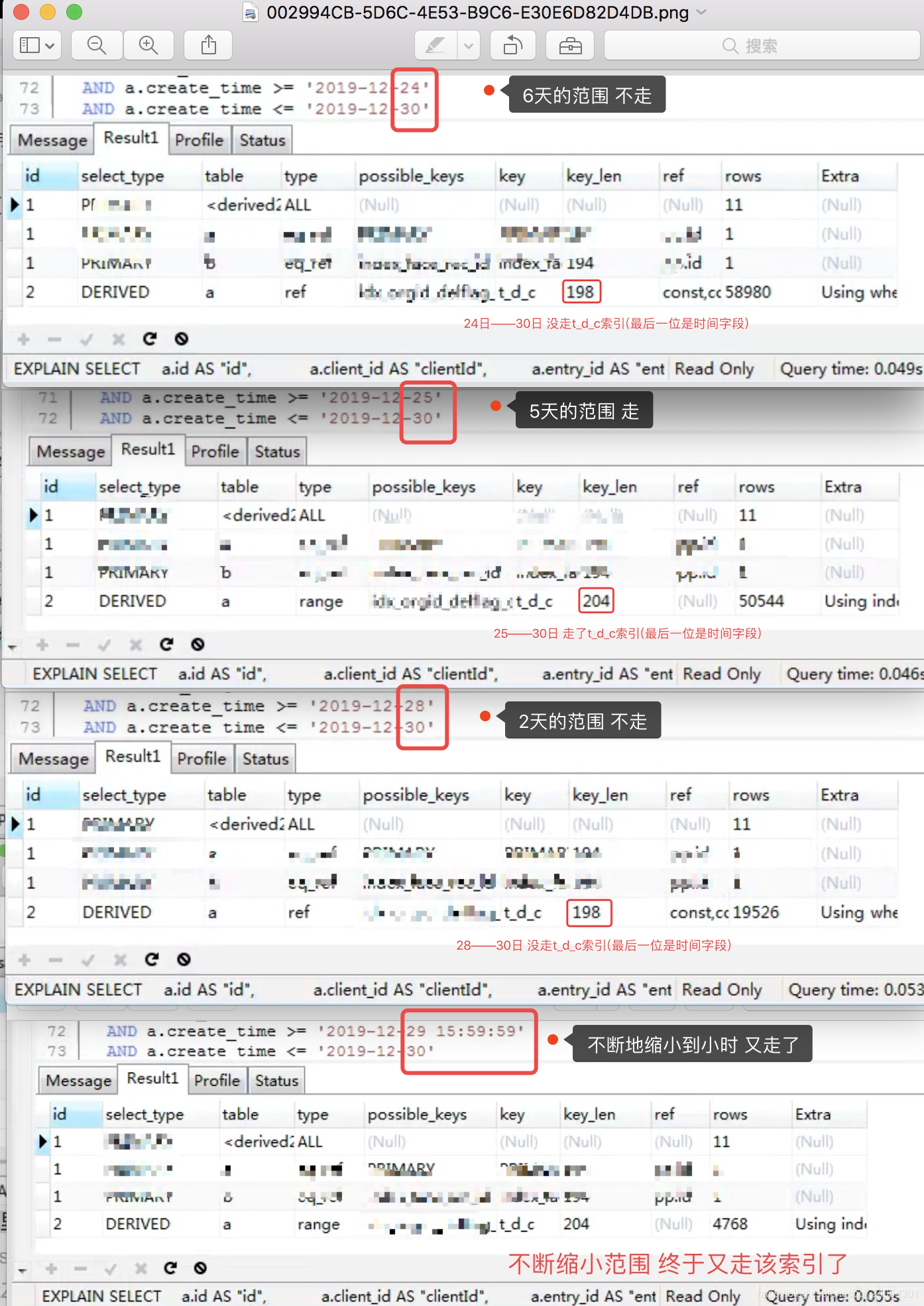
el índice t_d_c en la figura anterior es diferente, lo llamo ligadura de índice, que se discutirá más adelante. Se puede distinguir por key_len, el de 204 es el índice t_d_c real y su último bit es el índice de rango de tiempo. En el caso de que SQL no interfiera con el uso del índice, ajustando el rango de tiempo,Puede encontrar que el índice de alcance no es efectivo -> efectivo -> no efectivo -> efectivo.
Por lo tanto, muchas afirmaciones de amplia circulación son incorrectas.
La selectividad es inferior al 17% no va ,incorrecto. Esta es una conclusión extraída por cierta persona de un sql específico. Los rastreadores copian constantemente las publicaciones y luego las ven más personas, y luego continúan extendiéndose, lo que tiene un cierto impacto, incorrecto y incorrecto.
Si el rango es grande hasta cierto rango, no irá al índice de rango .incorrecto. Esta afirmación es mucho más cautelosa, no dice un valor específico, pero sigue siendo errónea.
Vi una entrevista en vivo sobre Douyin, que trataba sobre el desarrollo avanzado de Java P: ¿El índice de alcance entrará en vigor? El entrevistador respondió muy rápidamente, respondiendo: Esto puede no tener efecto. Si el índice de rango es tan grande como un cierto rango, no se tomará el índice. Este valor puede ser del 40%. Si lo excede, no irá. Entonces el entrevistador también quedó muy satisfecho. Uh ~. . . Ahora puedo decirles que esta afirmación es incorrecta. Por supuesto, el tamaño del rango definitivamente está relacionado con la elección del optimizador, pero de ninguna manera es el único factor.
Por lo tanto, el optimizador de consultas de mysql estima el plan de ejecución óptimo que considera en función del modelo de costo de la consulta.Es una operación complicada determinar si el índice de rango puede ir. Si lo hace correctamente, se indexará en el marco de tiempo de 100 años.
■ 2. Explique que la clave medida puede no ser un índice real.
Mencioné esta situación en el artículo anterior: la clave medida por explicar puede no ser el índice real, entonces, ¿cuál es? Solía llamarlo índices múltiples que se confunden entre sí. Múltiples índices se confunden entre sí, ¿eh? ¿Es esto similar a la fusión de índices?
Fusión de índices:
1. La fusión de índices consiste en fusionar los escaneos de rango de varios índices en un índice.
2. Cuando se fusiona el índice, los índices serán unión, intersección o primera intersección y luego operación de unión, para fusionarse en un índice.
3. Estos índices que deben fusionarse solo pueden pertenecer a una tabla. No se pueden combinar índices en varias tablas.
Si se usa la combinación de índices, index_merge se mostrará en la columna de tipo del contenido de salida, y todos los índices usados se mostrarán en la columna de clave
Uh. . Busqué al azar una introducción, que es muy oficial. Para decirlo sin rodeos, el índice se construye de manera irrazonable. MySQL combina múltiples índices de una sola columna, lo que se denomina combinación de índices, y el plan de ejecución se puede ver en index_merge.
La fusión de índices es para índices de una sola columna. Si se rompe la cabeza, no puede pensar que MySQL comenzará con índices compuestos y el plan de ejecución no le dirá lo que está haciendo. Es una locura. En la imagen del punto anterior puedes ver el olor del índice, lo que puedes ver es que sus columnas clave son todas del mismo índice.
El método de identificación se puede distinguir mirando la columna key_len, y la longitud es diferente. Luego, agregando después del nombre de la tabla SQLignorar índice(Índice a, Índice b ...) Puede averiguar qué índice ha afectado su ingreso a la Universidad de Tsinghua. Encuéntralo pronto y pásaloíndice de fuerza(Índice) Al forzar el índice a ir, puede encontrar que el índice no es el mismo índice cuando el índice es olor, así que lo llamo el índice de olor, en lugar de que el índice se convierta en uno determinado.
Solución:
un pasaje de "MySQL Third Edition de alto rendimiento",No aprueba

Si el optimizador va por el camino equivocado y hace que nuestra consulta se atasque, definitivamente no funcionará y debe resolverse. No puede tener miedo de la optimización debido a problemas desconocidos.
① Eliminar índices inútiles.
②O la declaración sql usa ignore index, force index, use index y luego especifique qué índices se pueden seleccionar a través de la etiqueta mybatis. Este método es bastante flexible y no afecta el índice anterior. Es solo para sql específico y condiciones específicas.
( La diferencia entre force y use : force es que siempre que haya un campo de índice que corresponda al campo de consulta, definitivamente irá. El uso es que el optimizador de consultas cree que el escaneo completo de la tabla es más rápido, él no irá)
■ 3. Enfatice el principio del prefijo más a la izquierda del índice una vez más.
Este es un evento muy interesante. El bloguero está certificado como experto en blogs y escribió una introducción al índice mysql. El bloguero explicó el índice a través de la pregunta del entrevistador y explicó el índice. Es bien recibido y tiene casi 1,000 colecciones. El guerrero en la imagen de abajo es un nuevo blogger.

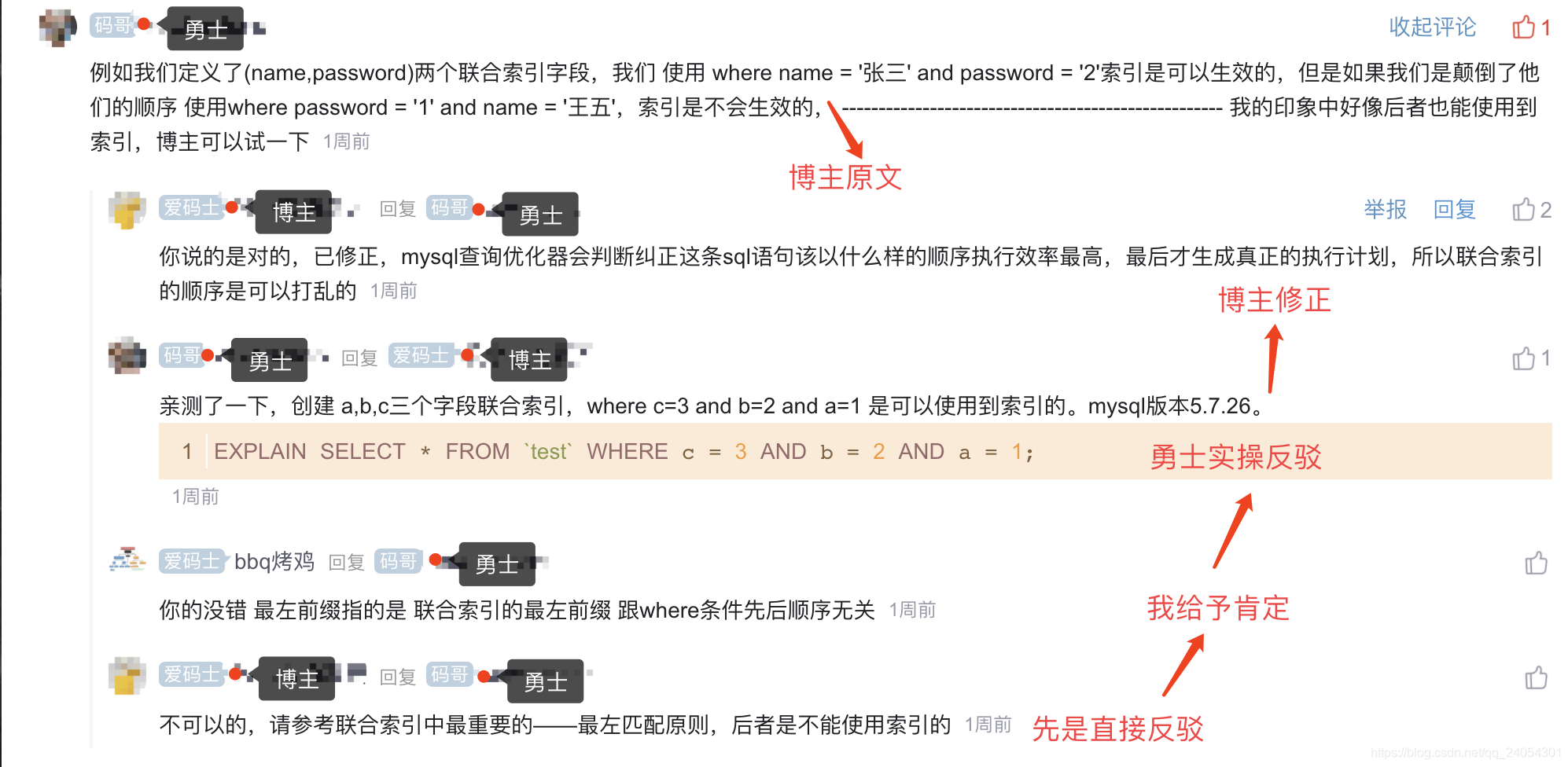
Si no comprende el principio del extremo izquierdo, casi puede suponer que no tiene una experiencia real de ajuste (índice compuesto), pero los blogueros tienen una bonificación por la certificación de expertos en blogs. Lea algunos libros teóricos y resuma algunos clichés. Las personas que no entienden el índice no lo harán. Para dudar de su afirmación, la influencia que trae es muy aterradora. La colección por sí sola se acerca a los 1000. Este tipo de visión errónea es impensable. Debido a que mi conocimiento del principio más a la izquierda del índice es el mismo que el de los bloggers, estoy más atento a este punto de vista erróneo, pero no sé cómo difundirlo y no tengo la capacidad de difundirlo (este es el punto), O (∩_∩ ) Oh jaja ~.
Es probable que la refutación de un experto en blogs haga que un recién llegado dude de la vida y renuncie a su propio punto de vista. Afortunadamente, afirmé lo que dijo el Guerrero. El Guerrero también refutó al bloguero nuevamente con ejemplos. El bloguero rápidamente corrigió el error y lo evitó. Engañar a más personas.
Las computadoras se están desarrollando rápidamente y muchas cosas solo existen desde hace unos años. Todos pueden ser maestros de alguien y, a veces, es más necesario afirmarse a sí mismo.
Entonces, ¿cuál es el principio más a la izquierda?
Preámbulo de la cita
El principio más a la izquierda del índice se refiere a la combinación de definiciones de índice (sexo, edad, tiempo) en orden de izquierda a derecha, no al orden de las condiciones where de la instrucción SQL. A menudo se dice en Internet que el índice no tiene efecto y se utiliza el escaneo completo de la tabla. Por ejemplo, el ejemplo anterior: No significa que el índice no se tome en absoluto si el tiempo no es efectivo. Aún así (sexo, edad). Esta es una oración muy ambigua. La expresión debe expresarse como un escaneo de tabla completo o un escaneo de índice completo.
Entonces, ¿cuál es el principio más a la izquierda? Vea el siguiente punto:
■ 4. Mi conocimiento del índice
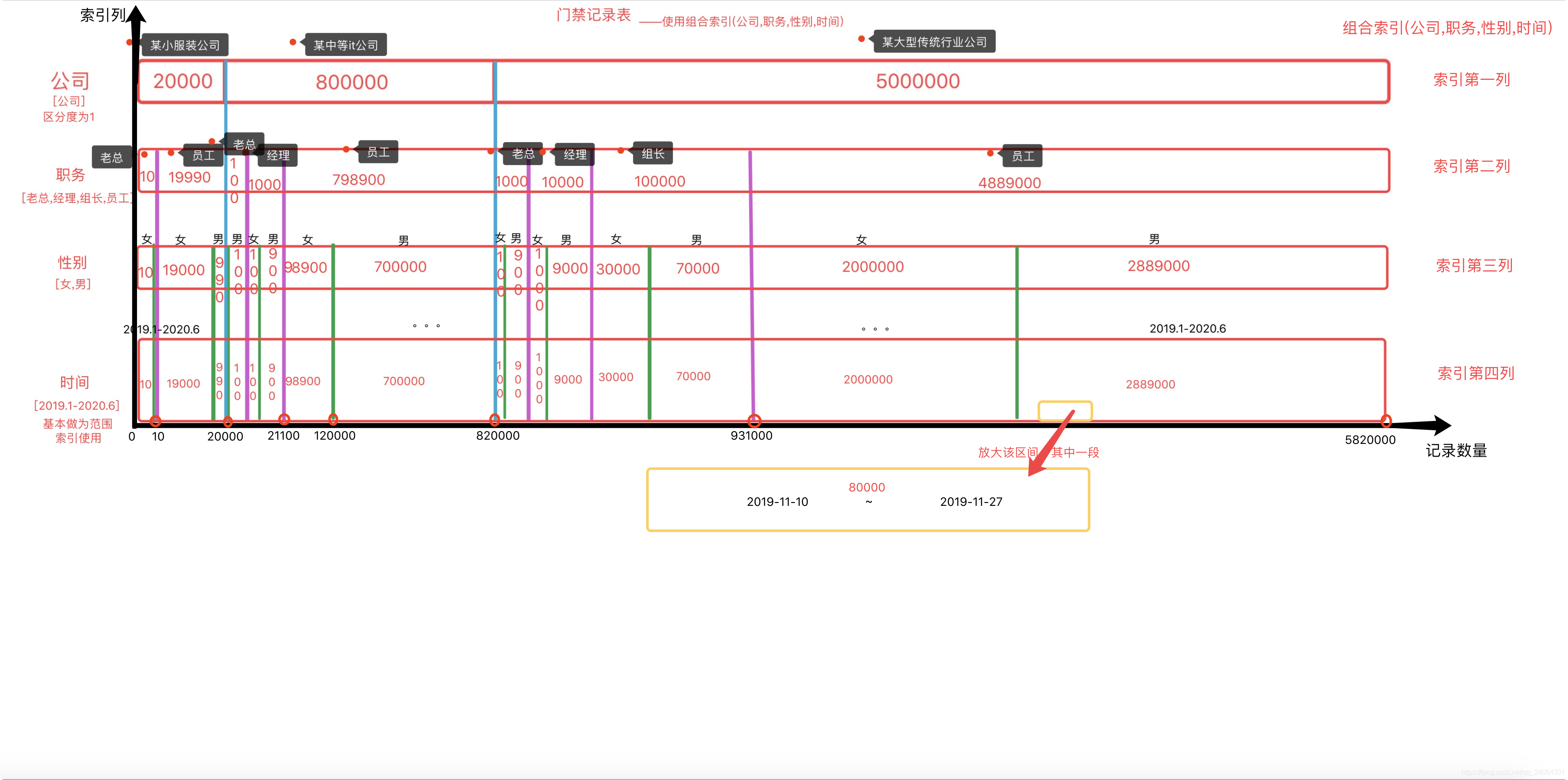
En Internet, todos los índices innodb reciben un diagrama de árbol B +, que no es muy fácil de entender para muchas personas. Eliminé la estructura del árbol de índices para visualizar cómo se puede reducir el índice. Vea la siguiente imagen que di En la imagen, básicamente puede comprender el problema de que el índice no funcione.
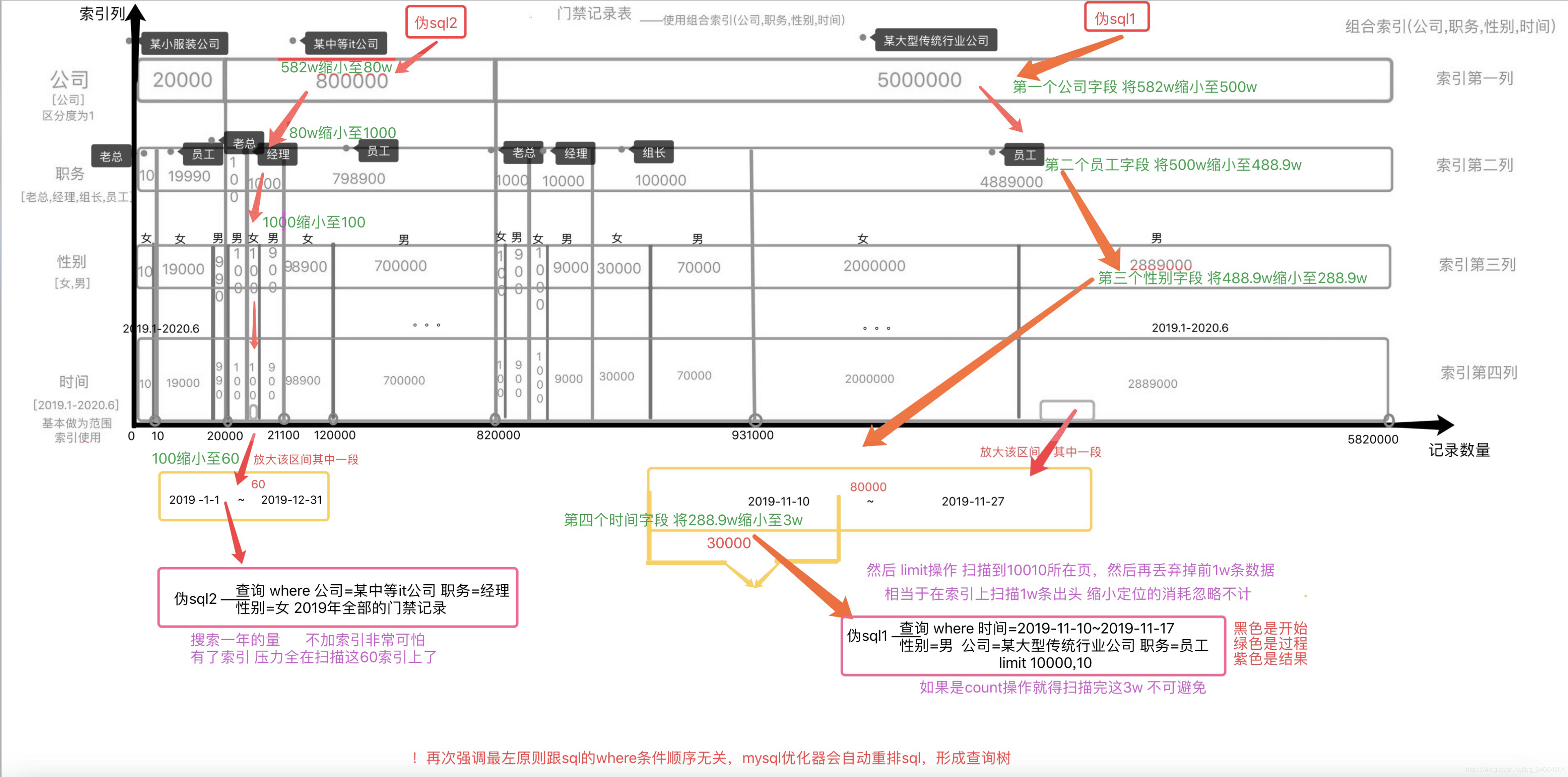
La imagen de ejemplo es un diagrama de estructura visualizado del índice compuesto (empresa, cargo, género, tiempo) de la tabla de registros de control de acceso con 582w registros creados por mí.El orden del índice en la figura de arriba a abajo es equivalente al principio de más a la izquierda de izquierda a derecha. El número de cada cuboide que se corta indica el tamaño del índice, y se ordena y ordena continuamente capa por capa.
A continuación, daré un ejemplo:
dos consultas sql consultas
sql2 registros de control de acceso de todas las gerentes femeninas de una empresa mediana en 2019
consulta sql1 2019-11-10 ~ 2019-11-17 empleados masculinos de una gran empresa límite 10000,10
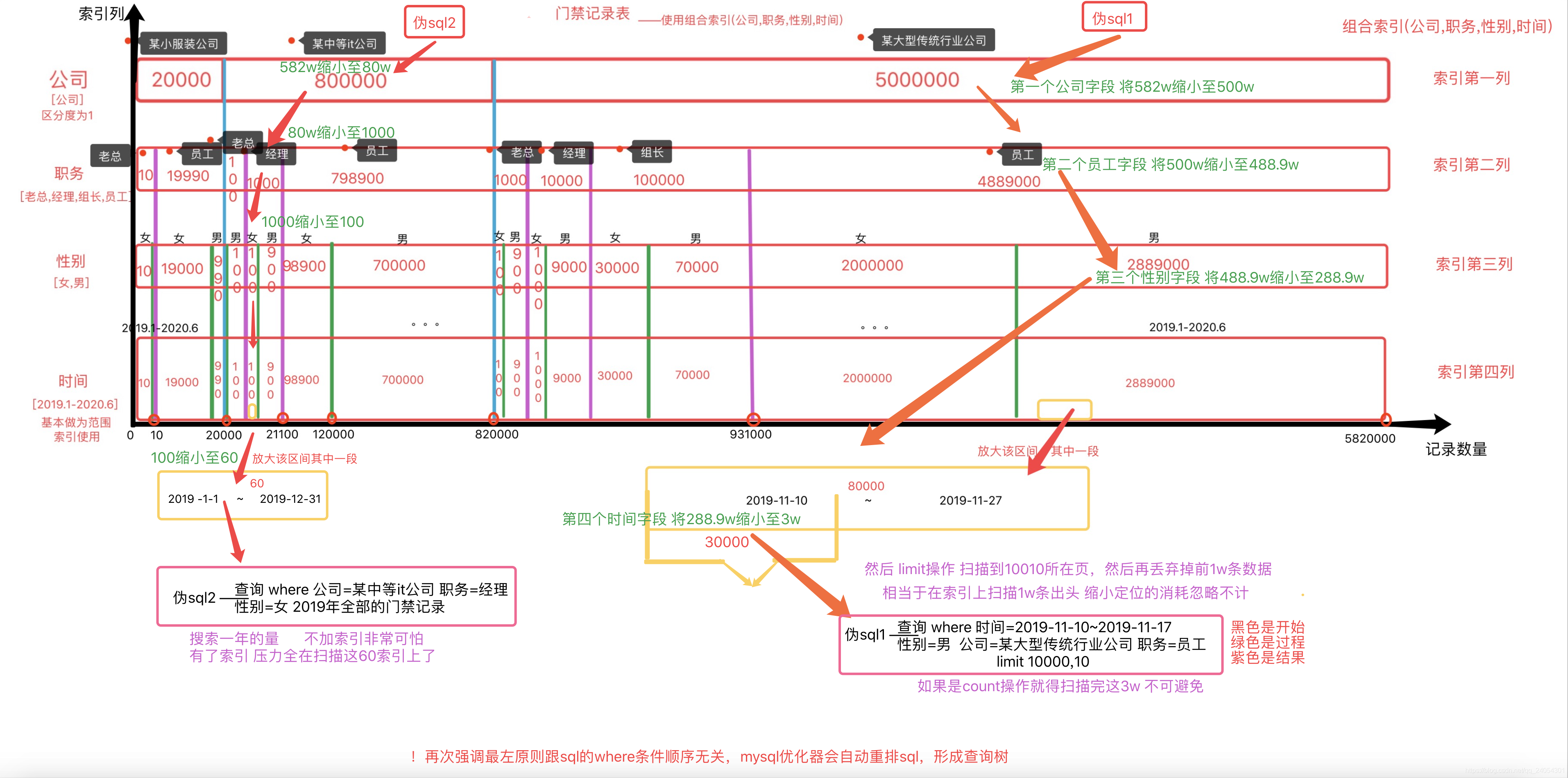
a varios Versión en color——
■ 5. Trate de evitar el uso de
En el artículo anterior dije que in está indexado. Aunque in explica como rang, no es una consulta de rango. Por lo tanto, in se usa en el campo frontal del índice compuesto, y los siguientes campos también están indexados. También se da un ejemplo,
revisando el artículo anterior-
③ Úselo para crear índices de forma menos inteligente. Por ejemplo, si tiene una condición de búsqueda de género, masculino es 1 y femenino es 2, no todos están marcados. Algunas personas pueden crear dos índices (…, sexo ,…) y (…,…) para tratar las condiciones de búsqueda de género. Y sin criterios de búsqueda de género. Luego, si tiene que indexar el género, solo puede construir el índice (…, sex ,…) y luego modificar la declaración sql. Cuando no filtra hombres y mujeres, puede enumerar todos los hombres y mujeres, es decir,
seleccionar… de un dónde… y el sexo en ( 1, 2) y ... De
esta manera, los índices se pueden crear de forma menos inteligente.
Esta es también la solución dada por "High-Performance MySQL Third Edition", que está a más de 7 u 8 años de distancia.
Ahora quiero decirles que esta solución tiene limitaciones en sus escenarios de uso. Si los campos detrás del campo in del índice compuesto están ordenados en SQL, se estima que la conexión de consulta no responde directamente.
Ejemplo: sql3 consulta a los gerentes y empleados masculinos de una empresa mediana y grande.
Como se
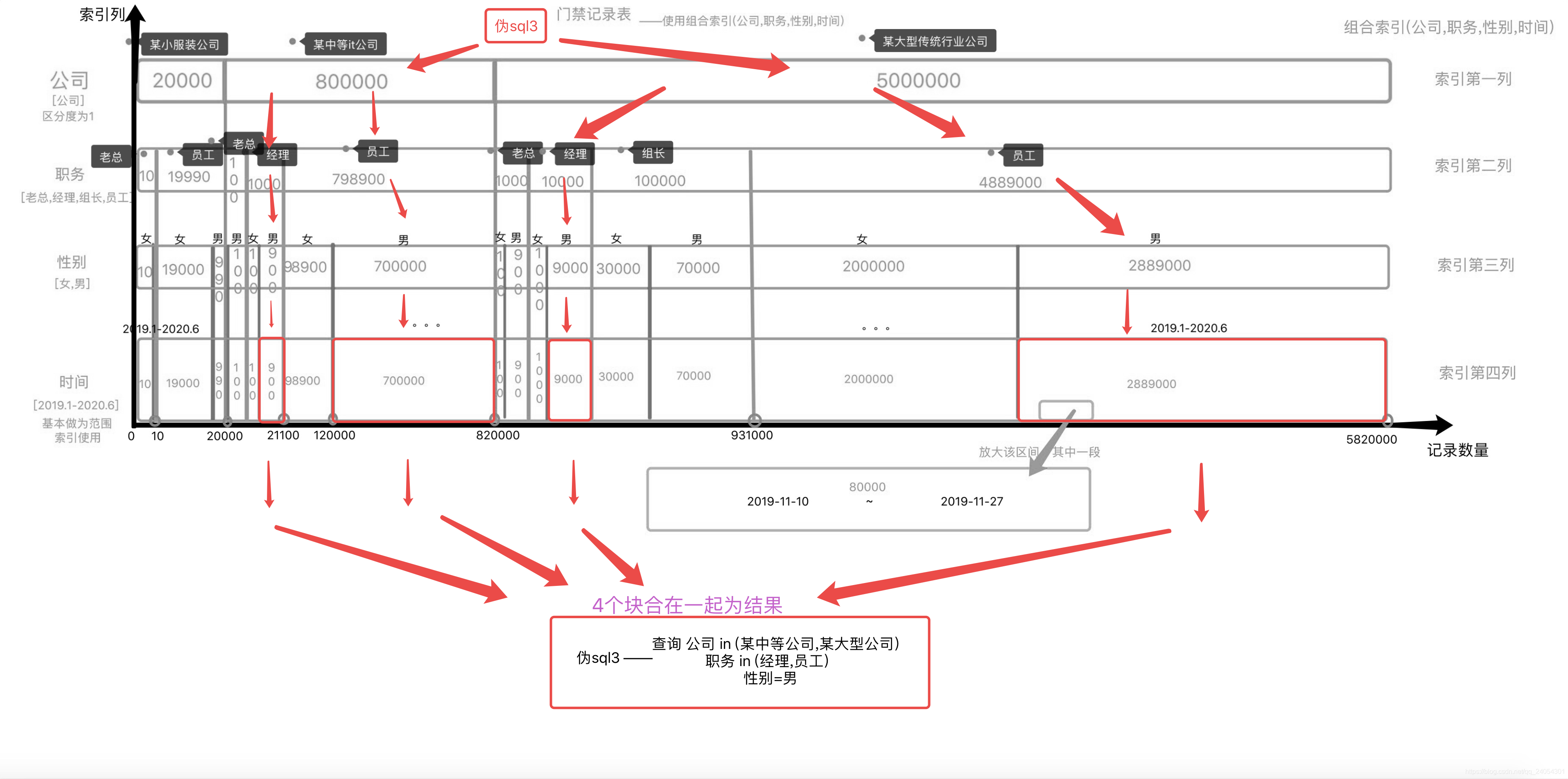
muestra en la imagen , mire esta imagen para comprender cómo está el índice. Este índice es bueno cuando no se requiere ordenar, y encontrará límites Los primeros 900 registros son los registros de gerentes masculinos en empresas medianas.
Es decir, si consulta todos, el resultado final son 4 bloques de intervalos de tiempo continuos independientes y luego se fusionan, cada bloque en sí está ordenado, una vez que ordena, clasificará los 4 bloques. Orden de reorganización de la operación. (Cada bloque se ordena por sí mismo, y las combinaciones de múltiples bloques, naturalmente, deben reorganizarse). Cuanto más se use, más combinaciones de productos cartesianos se clasificarán y el rendimiento, naturalmente, caerá drásticamente.
y entonces,Los campos siguientes están ordenados y los en funcionamiento deben evitarse en la medida de lo posible en los campos anteriores., Solo las consultas que no se preocupan por el orden pueden utilizar este método.
Optimización en curso
La siguiente es una operación de optimización de paginación animal de código 5.5k para mysql (motor innodb) casi decenas de millones de tablas grandes
■ Pantalla de efectos
Me sorprendió Baidu Tieba. Hay 1500w temas en la barra de Li Yi, y la cantidad de páginas se puede verificar en segundos. Es digno de ser una gran fábrica. Más tarde descubrí que solo ubica 201 páginas, y las siguientes son páginas falsas. . . . Bueno, no esperaba encontrar una buena solución lista para usar, así que hice mi propia investigación.
A continuación se muestra una visualización del efecto de paginación con un recuento de más de cien w-
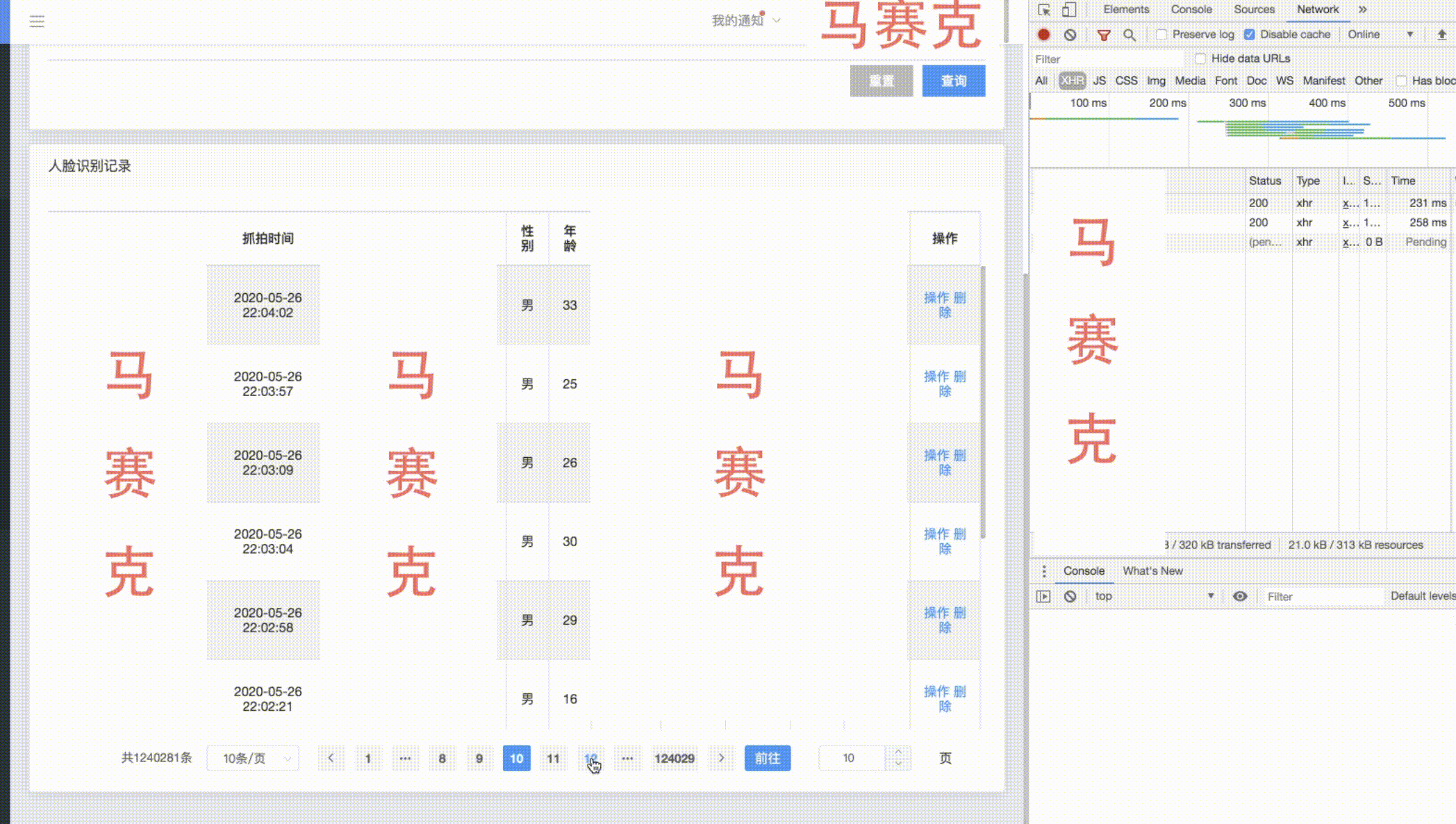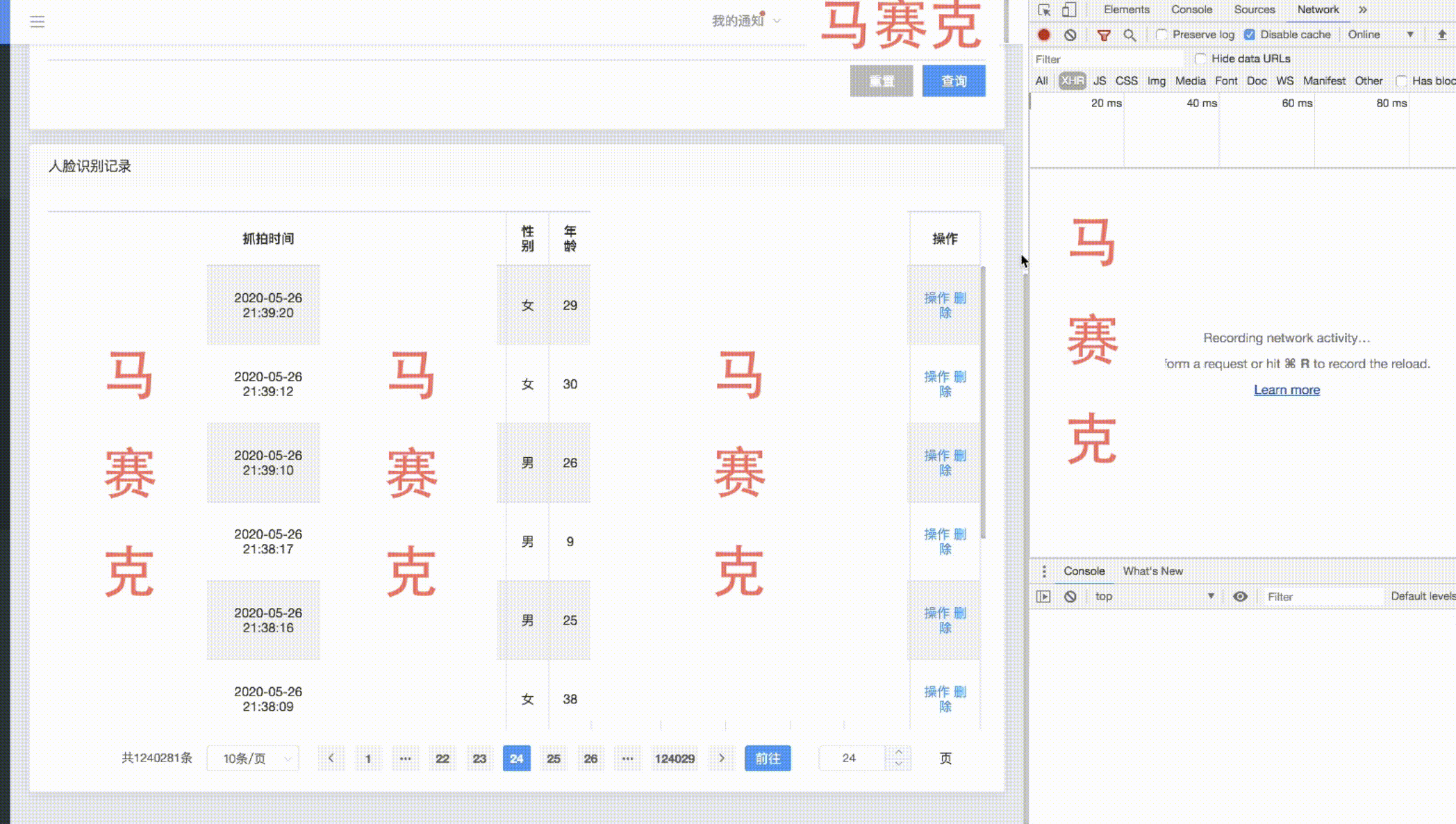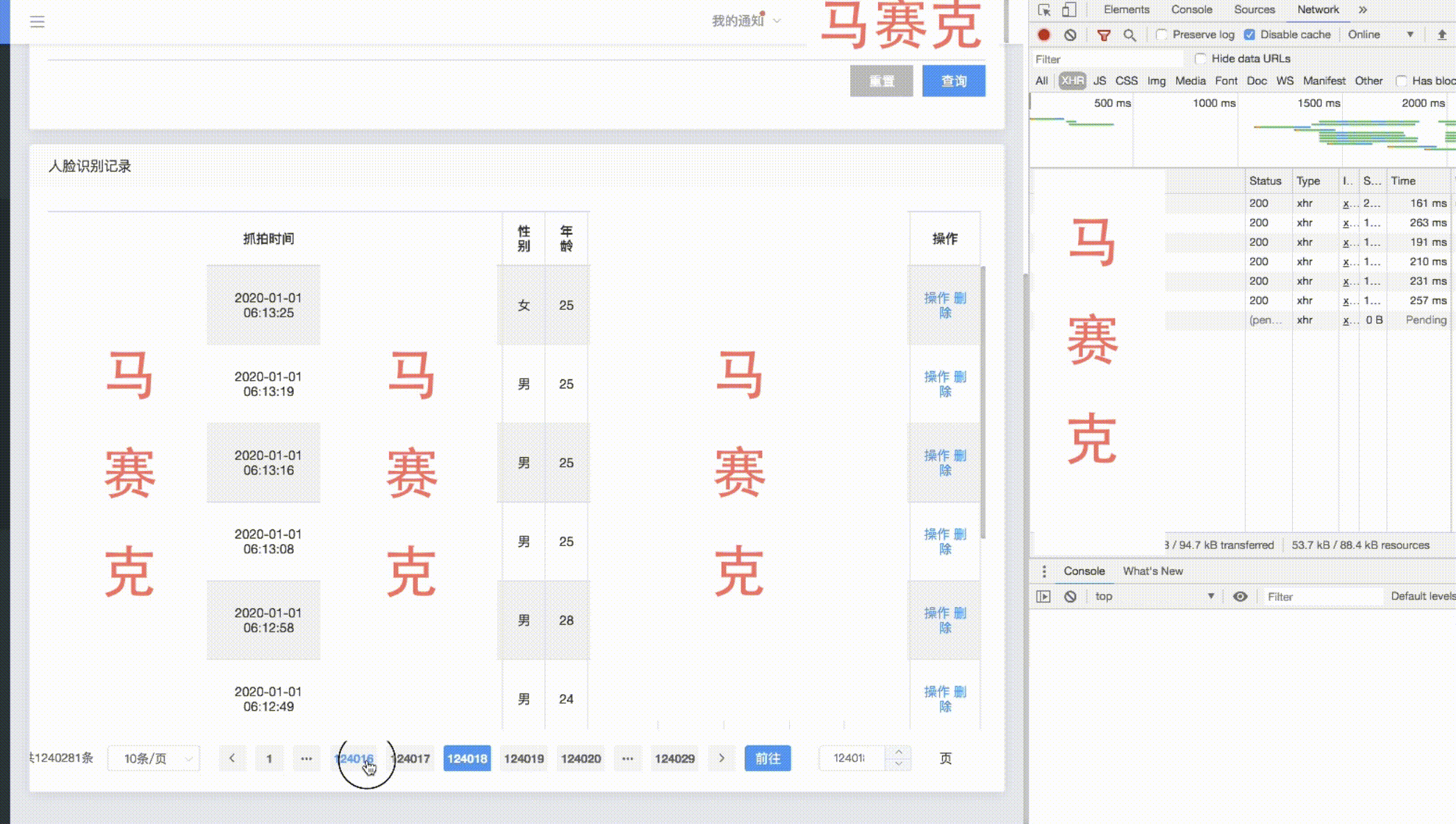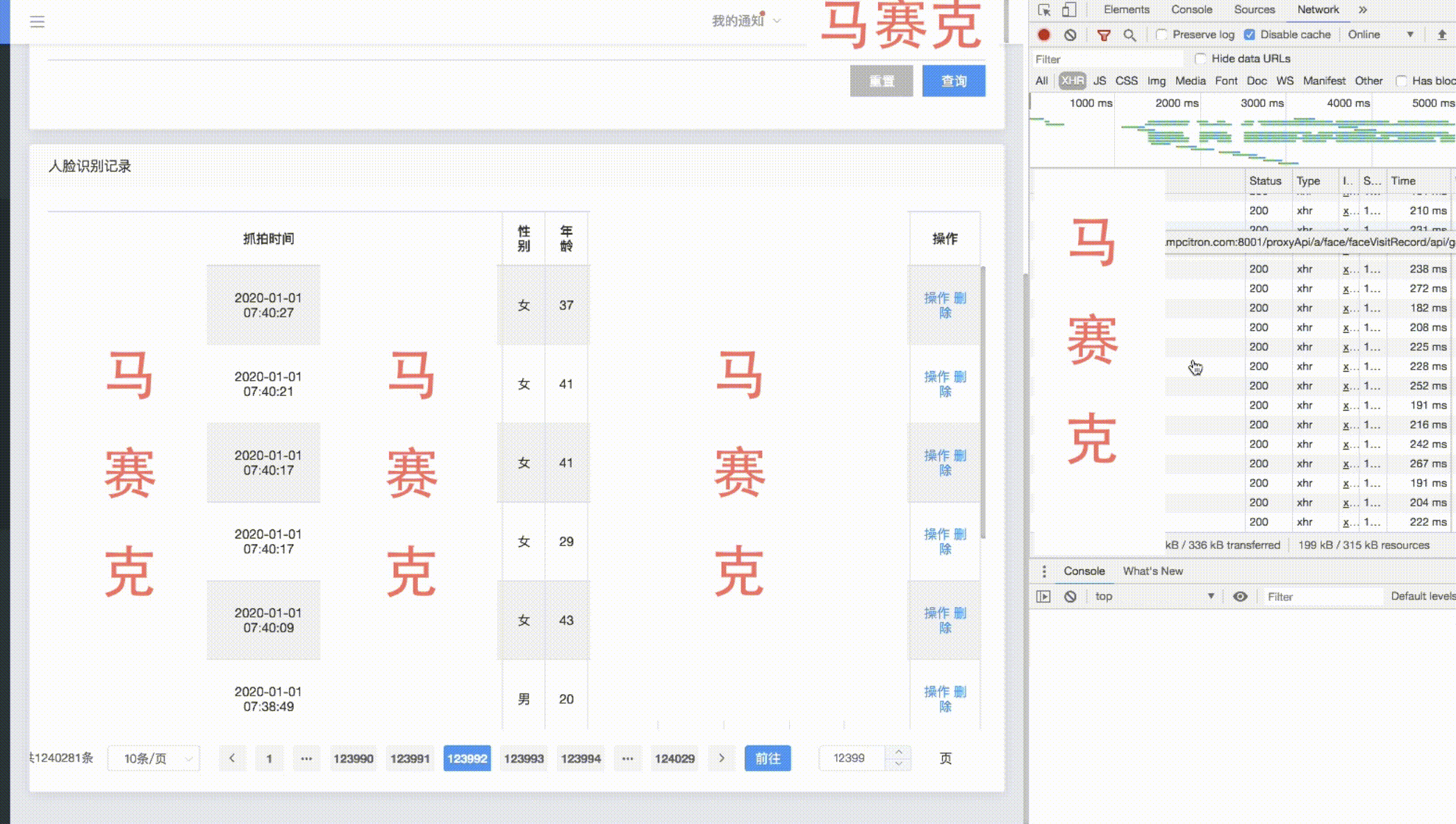
bajo la premisa de asegurar el efecto óptimo del índice, se lleva a cabo una gran transformación de paginación de tabla. Cuando la memoria caché de recuento es buena, los resultados de la consulta para las primeras decenas de miles y las últimas decenas de miles de páginas de grandes volúmenes de datos son buenos. En 1w, solo existe el tiempo consumido para la transmisión de red. El rendimiento de la consulta empeora a medida que avanza hacia la mitad. El valor de visualización de los datos intermedios no es alto y el primer y el último dato siguen siendo los más valiosos, lo que puede impedir que los usuarios salten demasiado lejos para garantizar el rendimiento de las consultas.
■ Esquema del proceso de consulta
Estoy confundido acerca de esta imagen y lo explicaré con palabras más adelante. Sin embargo, dibujar una imagen también puede aclarar algunas ideas y encontré un error que no se descubrió antes: la caché de consultas asincrónicas se está cargando. Después de encontrar los datos, la caché se contó nuevamente y eliminé la caché. Agregue una restricción: esta caché solo se elimina cuando se actualiza su solicitud de interfaz actual.
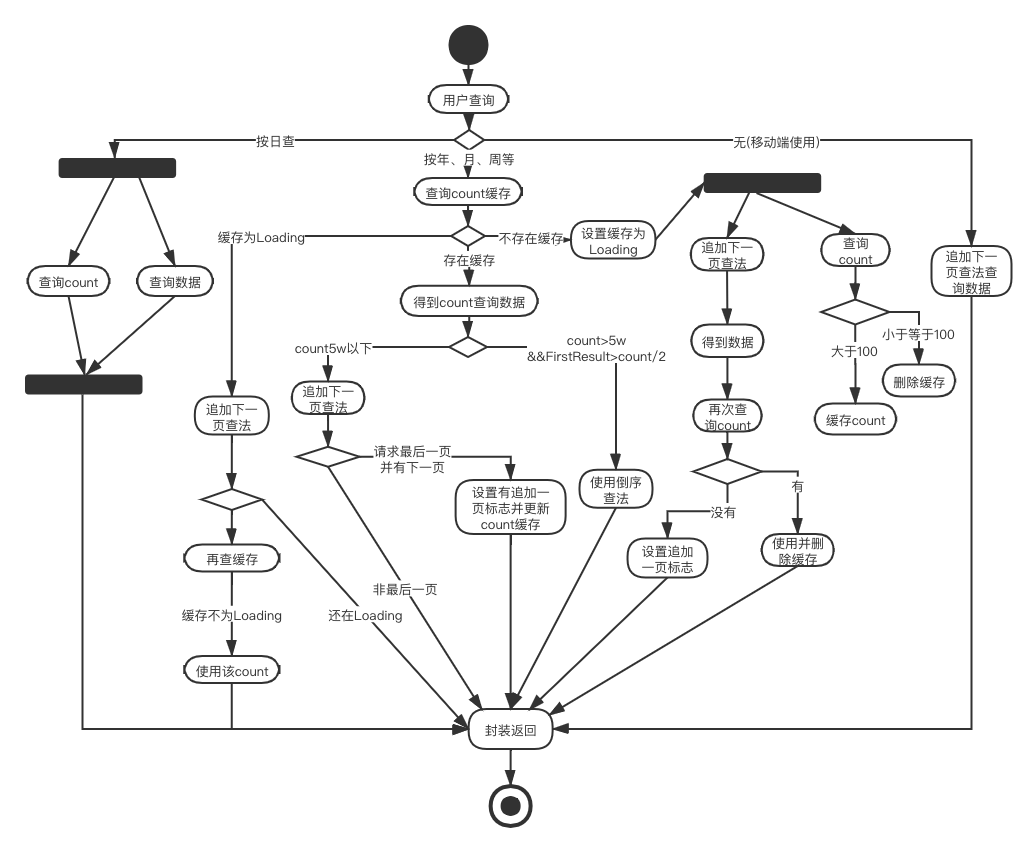
■ Proceso de consulta detallado
# etapa de preparación
① Recuerde el método de agregar dinámicamente la página siguiente mencionada anteriormente
Ejemplo: el terminal móvil requiere datos de las páginas 3 y 5. Tradicionalmente, eliminamos el límite y verificamos el recuento primero, que puede ser 100w, y luego consultamos el límite de datos específico 10, 5. Se necesitan varios segundos para consultar el recuento, y los datos específicos del límite se verifican en segundos. ¿Cómo optimizar esto?
Lo llamo:
agrego dinámicamente el método de la página siguiente: el límite 10,6 es resultList; return count = (3-1) * 5 + resultList.size; si siz es 6, la resultList devuelta, mueva el último dato
si resultList. El tamaño devuelve 1 ~ 5, lo que indica que esta consulta es la última página. El recuento calculado de esta manera es coherente con el recuento tradicional. Si resultList.size devuelve 6, significa que la consulta puede tener una página siguiente y el terminal móvil también puede determinar si hay una página siguiente.
En pocas palabras, es verificar una pieza más de datos para determinar si hay una página siguiente, y luego, después del posprocesamiento, los datos se clasifican en el mismo efecto que una verificación normal, para lograr el efecto de juzgar si hay una página siguiente.
② Es inevitable sacrificar la cuenta en tiempo real
El fundamento del principio de la PAC es universal: en muchos casos, hay que sacrificar algo si se quiere algo. La verificación diaria aquí generalmente requiere inmediatez, y la cantidad de datos es pequeña y el rendimiento del recuento no se almacena en caché. Cuanto mayor sea el recuento, mayor será el tiempo de caché y la necesidadSacrifique el rendimiento en tiempo real del recuento para mejorar el rendimiento de las consultas. Es imposible generar el recuento en tiempo real de la consulta de tabla grande de mysql en segundos, incluso MyIsam no admite el recuento de la segunda consulta con la consulta condicional.
③ Método de búsqueda inversa
Por ejemplo, limite 100000, 10; como se mencionó anteriormente, MySQL debe escanear los primeros 10w y luego descartarlos. Esto no tiene nada que ver con si ir o no al índice, no se escaneará porque ha creado el índice, este es un proceso inevitable. Entonces podemos hacer esto: si sabe que el recuento es 10w, y ahora desea verificar los últimos 10, ¿son en realidad los primeros 10 en orden inverso?
como sigue--
public void reverse() {
this.firstResultReverse = (int)count - this.firstResult - pageSize;
if(this.firstResultReverse < 0) {
this.pageSizeReverse = this.firstResultReverse + this.pageSize;
this.firstResultReverse = 0;
} else {
this.pageSizeReverse = this.pageSize;
}
}
Ejemplo: El
total es 9995; ordenar por límite DESC 9980, 10; El resultado es la segunda página desde la
parte inferior , 10 datos; parámetros disponibles: count = 9995; firstResult = 9980; pageSize = 10;
Sustituya el método anterior para obtener:
firstResultReverse=5;
=> 判断大于等于0
pageSizeReverse=10;
重组 sql —— orden por límite ASC 5, orden 10 por DESC;
El total es 9995; ordenar por límite desc 9990, 10; El resultado es la última página, 5 piezas de datos;
Parámetros disponibles: count = 9995; firstResult = 9990; pageSize = 10;
Sustituya el método anterior para obtener:
firstResultReverse=-5;
=> 判断小于0
pageSizeReverse=5;
firstResultReverse=0
重组 sql —— orden por límite desc 0, 5 orden por DESC;
De esta manera, el número de páginas al final de la búsqueda puede ser tan rápido como el número de páginas al frente, por supuesto, la búsqueda en el medio se volverá cada vez más lenta. Este enfoque entra en conflicto un poco con el método de agregar una página. Anteriormente, usé el método de agregar la página siguiente para consultar continuamente la última página, y actualizaba constantemente la memoria caché de conteo, pero al usar el método de orden inverso, la última página es la última página, y debe ser la última Los datos anteriores, pero el recuento no se actualizarán, por lo que es necesario configurar un mecanismo adicional para actualizar el caché del recuento para garantizar que el recuento no se mantenga sin cambios.
1. Consulta por día
La consulta diaria se clasifica como consulta de datos bajos por mí. El volumen de datos de un solo usuario por día es como máximo decenas de miles de pequeños, por lo que aquí el recuento de consultas de varios subprocesos y datos específicos al mismo tiempo, y luego los vuelve a integrar.
2. Consulta incondicional
La consulta incondicional está clasificada por mí como consulta móvil. La consulta móvil es la más fácil. No necesita el recuento de consultas y se puede resolver fácilmente mediante el método dinámico de agregar página siguiente. O use la última marca de tiempo como cursor para llevar el cursor a la siguiente consulta. Este método es mejor que agregar dinámicamente la página siguiente. Mientras el índice entre en vigencia, no habrá problemas de rendimiento independientemente del fin del mundo. Lo único que debe resolverse es la misma hora. Posicionamiento de datos sellados.
3. Consultar otras condiciones
Otras consultas condicionales-consultas que están casi pegadas a ráfagas, que es el foco de lo que quiero hablar, la mayoría de las operaciones se utilizan aquí.
① ¿Cuál es el
mayor problema de almacenar en caché la consulta de paginación de la tabla de conteo grande? No hay duda de que el recuento total, y la necesidad de inmediatez y rapidez, se puede decir que es imposible (en el caso de una sola condición, el recuento se puede mantener por separado, aquí es el caso de condiciones de consulta complejas), por supuesto que solo se puede usar Para el método de paginación de abrir algunos elementos cercanos, lo que estoy explicando aquí es la consulta de paginación del recuento de visualización tradicional.
Ordene los parámetros de la consulta (elimine algunos parámetros que no están involucrados en la clasificación, ordene los parámetros de la consulta y genere valores únicos para las condiciones) -
// 获取升序参数map
public static Map getSortParmMap(ServletRequest request) {
Enumeration<?> pNames = request.getParameterNames();
Map<String, String> params = new HashMap<>();
while (pNames.hasMoreElements()) {
String pName = (String) pNames.nextElement();
if ("pageSize".equals(pName) || "pageNo".equals(pName) || "token".equals(pName) || "sign".equals(pName) || "appSecret".equals(pName))) {
continue;
}
String pValue = request.getParameter(pName).replace(":","-");
if (StringUtils.isNotBlank(pValue)) {
params.put(pName, pValue);
}
}
return params;
}
Generar valor de clave de redis (consejos:Usa dos puntos: En la herramienta de gestión visual de redis, se archivará para facilitar la gestión). No se preocupe por la degradación del rendimiento causada por la clave demasiado larga, esa longitud de bit es pan comido para redis.
Map<String, Object> params = LargePage.getSortParmMap(request);
String paramStr = "face:" + rcd.getCurrentUser().getTenantId()+ ":" + params;
② En el caso de que se hayan consultado los datos del hilo principal, el recuento no se haya almacenado en caché, los datos siempre son más importantes que el recuento, no espere, asegure la prioridad de los datos, utilice directamente el método dinámico de agregar la página siguiente.
Por ejemplo, me toma 200 ms consultar los datos y el resultado de los datos ha salido. El hilo principal vuelve a consultar la caché y sabe que el recuento todavía se está cargando, así que no espere, devuelva el resultado e informe al front-end que hay una página siguiente.

Como se muestra en la figura, e informar al front-end del método actual de adición dinámica de la página siguiente, no muestre el recuento devuelto por el método de adición dinámica de la siguiente página, pero muestre un estado de carga, lo que indica que el recuento aún se está consultando y que el recuento falso devuelto solo se usa Calcule el número de páginas mostradas en el complemento de paginación.
③ Si se consultan los datos y el caché de recuento se obtiene al consultar de nuevo, el recuento se puede usar en este momento. Si el caché de recuento lo realiza su consulta actual, puede borrar el caché porque los datos están agotados , Count también se encuentra, lo que indica que la consulta del recuento es rápida y no es necesario el almacenamiento en caché. Incluso puede configurar la condición para que se almacene en caché durante un cierto período de tiempo, lo que significa que no es necesario almacenar en caché la condición más adelante y consultar la base de datos cada vez. Rendimiento en tiempo real de pequeños recuentos.
#Efecto resumen
Por lo general, verifique diariamente y
otros tipos de conteo de verificación asincrónico, el conteo primero se descubre y se asigna directamente para garantizar que el
conteo en tiempo real 1000 (configurable) no se almacene en caché y el
conteo aún se esté consultando. El conteo de la interfaz muestra un círculo, pero definitivamente sabe si hay una página siguiente
El recuento es inferior a 5 w (configurable). El límite convencional para el número de páginas posteriores será un poco más lento, pero determinará si hay una página siguiente. El
recuento es mayor que 5 w (configurable). El número de páginas que siguen es en realidad el orden inverso para comprobar las primeras páginas , El principio y el final son rápidos, el medio es lento
Mi mecanismo de almacenamiento en caché de recuento es que cuanto mayor sea el recuento, más tiempo se almacenará en caché, y luego un mecanismo de actualización del recuento completará el mecanismo de paginación de una tabla grande.
Al final
Hay un largo camino por recorrer, la optimización de mysql y la optimización de paginación aún tienen un largo camino por recorrer, todavía estoy en camino.