Hoy quiero compartir una transacción distribuida con ustedes. Presentaré esquemas de implementación de transacciones distribuidas comunes y sus ventajas y desventajas, así como escenarios aplicables, y mostraré algunas de sus implementaciones variantes.
También echaré un vistazo al modelo mejorado de base de datos distribuida a 2PC y veré cómo se hace la base de datos distribuida.
Luego analice la implementación específica de una ola de marco de transacciones distribuidas Seata para ver cómo se implementan las transacciones distribuidas Después de todo, el acuerdo es útil si se implementa.
En primer lugar, hablemos de qué son las transacciones y las transacciones distribuidas.
asuntos
El ACID de transacciones debe ser familiar para todos, esta es en realidad una definición en sentido estricto, lo que significa que la realización de transacciones debe tener atomicidad, consistencia, aislamiento y durabilidad.
Sin embargo, las transacciones en sentido estricto son difíciles de lograr. Como conocemos las bases de datos, existen varios niveles de aislamiento. Cuanto mayor es el rendimiento, menor es el nivel de aislamiento. Por lo tanto, a menudo encontraremos nuestro propio equilibrio a partir de él y no seguiremos las transacciones en sentido estricto.
Y en nuestras discusiones diarias, la llamada transacción a menudo simplemente se refiere a una serie de operaciones que se ejecutan todas con éxito o todas fallan, y no habrá éxito ni fracaso.
Una vez que hayamos aclarado nuestra definición diaria de transacción, echemos un vistazo a qué es transacción distribuida.
Transacción distribuida
Debido al rápido desarrollo de Internet, la arquitectura monolítica anterior no podía soportar tantas demandas, un negocio tan complejo y una cantidad de tráfico tan grande.
La ventaja de la arquitectura monolítica es que se construye rápidamente y está en línea en la etapa inicial, y los métodos y módulos se llaman todos internamente, y es más eficiente sin la sobrecarga de la red.
Desde cierto aspecto, la implementación también es conveniente, después de todo, es solo un paquete y tíralo.
Sin embargo, con el desarrollo de la empresa, la complejidad del negocio es cada vez mayor y el acoplamiento interno es extremadamente grave, lo que hace que todo el cuerpo se vea afectado, el desarrollo no es fácil y las pruebas no son fáciles.
Y no se puede escalar dinámicamente según los servicios del punto de acceso. Por ejemplo, la cantidad de acceso a bienes y servicios es extremadamente grande. Si se trata de una arquitectura única, solo podemos replicar la aplicación completa para múltiples implementaciones de clúster, lo que desperdicia recursos.
Por lo tanto, la división es imperativa y la arquitectura de microservicio está aquí.
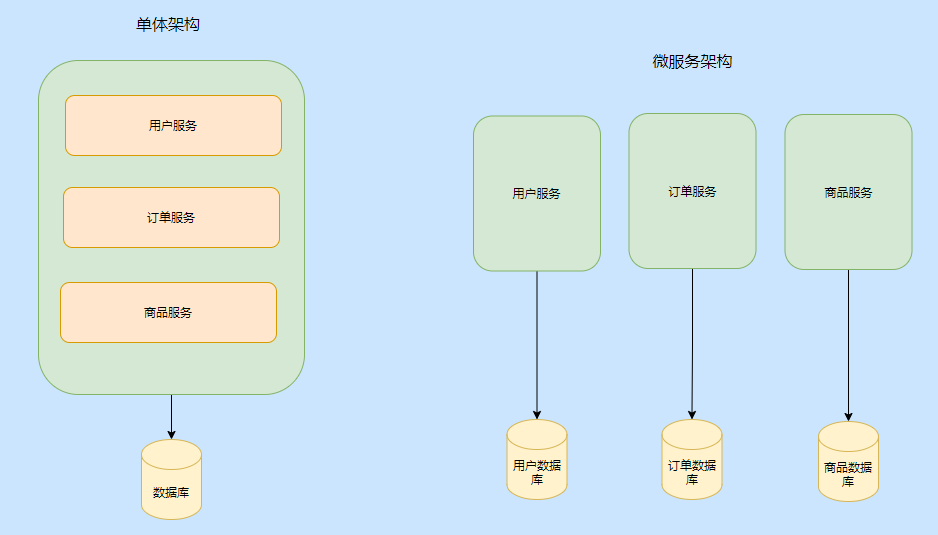
Después de la división, los límites entre los servicios están claros. Cada servicio se puede ejecutar e implementar de forma independiente, por lo que se puede escalar elásticamente a nivel de servicio.
Las llamadas locales entre servicios se convierten en llamadas remotas, el enlace es más largo y el tiempo para una llamada es más largo, pero el rendimiento general es mayor.
Sin embargo, se introducirán otras complicaciones después de la división, como monitoreo del enlace de servicio, monitoreo general, medidas tolerantes a fallas, escala elástica y otros problemas de monitoreo operativo y de mantenimiento, así como problemas como transacciones distribuidas, bloqueos distribuidos y problemas relacionados con el negocio. Espere.
A menudo resuelve un punto débil e introduce otros puntos débiles, por lo que la evolución de la arquitectura es el resultado de compensaciones y depende de los puntos débiles que su sistema pueda soportar.
Hoy hablamos del punto débil de las transacciones distribuidas.
Las transacciones distribuidas se componen de múltiples transacciones locales. Las transacciones distribuidas abarcan múltiples dispositivos y experimentan una red compleja entre ellos. Es concebible que el camino hacia las transacciones estrictas sea difícil y largo.
La versión independiente de la transacción no seguirá estrictamente la implementación estricta de la transacción, y mucho menos la transacción distribuida, por lo que en realidad solo podemos implementar la versión incompleta de la transacción.
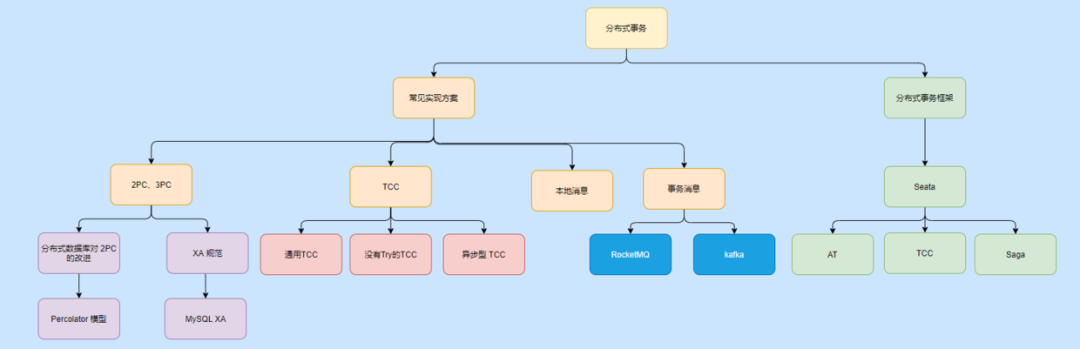
Después de aclarar las transacciones y las transacciones distribuidas, echemos un vistazo a los esquemas de transacciones distribuidas comunes: 2PC, 3PC, TCC, mensajes locales, mensajes de transacción.
2 piezas
2PC, protocolo de compromiso de dos fases, es decir, protocolo de compromiso de dos fases. Introduce un rol de coordinador de transacciones para administrar a cada participante (es decir, cada recurso de la base de datos).
El conjunto se divide en dos fases, a saber, la fase de preparación y la fase de compromiso / retroceso.
Echemos un vistazo a la primera etapa, la etapa de preparación.
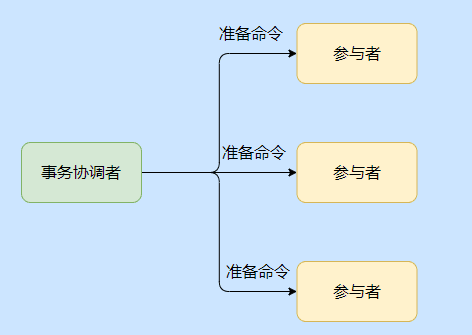
El coordinador de la transacción envía un comando de preparación a cada participante. Después de que cada participante recibe el comando, se ejecutará la operación de transacción correspondiente. Puede pensar que todo, excepto el compromiso de la transacción, se ha realizado.
Luego, cada participante devolverá una respuesta para informar al coordinador si está listo para tener éxito.
Una vez que el coordinador recibe la respuesta de cada participante, ingresa a la segunda etapa. Según la respuesta recopilada, si un participante no se prepara para responder, enviará un comando de retroceso a todos los participantes, de lo contrario enviará un comando de confirmación.
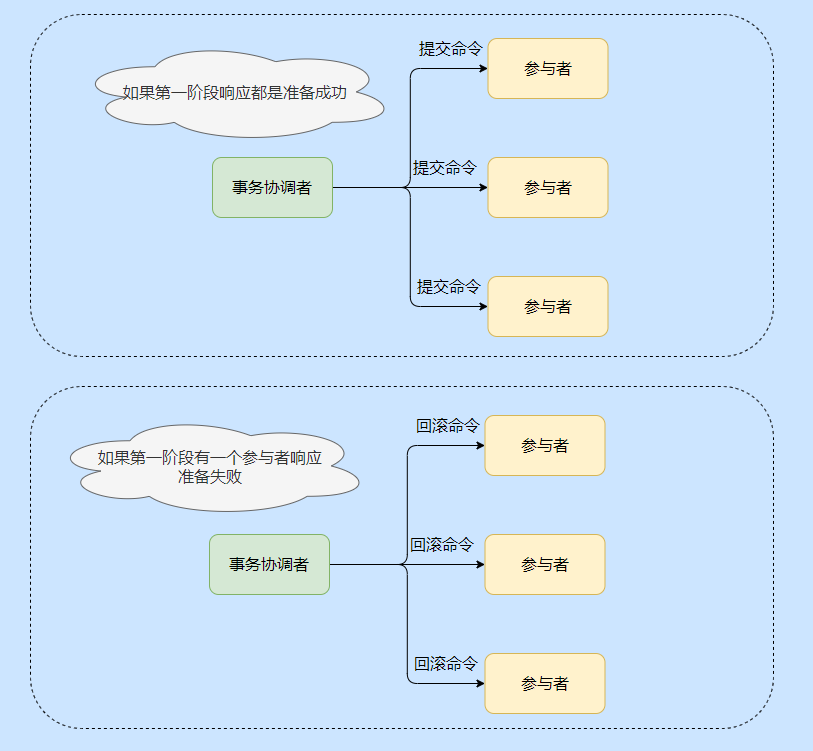
Este acuerdo está en línea con el pensamiento normal, al igual que cuando llamamos a una clase en una universidad, el profesor es en realidad el coordinador y todos somos participantes.
La maestra llamó uno a uno y nosotros gritamos uno a uno, finalmente la maestra comenzó la conferencia de hoy después de recibir la llegada de todos los estudiantes.
La diferencia de pasar lista es que el maestro todavía puede continuar la clase cuando un cierto número de estudiantes está ausente, y nuestros asuntos no lo permiten.
El coordinador de transacciones no recibe una respuesta de los participantes individuales en la primera etapa, y luego de esperar un cierto período de tiempo, la transacción se considerará como un error y se enviará un comando de reversión. Por lo tanto, el coordinador de transacciones tiene un mecanismo de tiempo de espera en 2PC.
Analicemos las ventajas y desventajas de 2PC.
La ventaja de 2PC es que puede usar las funciones propias de la base de datos para confirmar y revertir transacciones locales, lo que significa que no es necesario que implementemos las operaciones reales de compromiso y reversión, y la lógica empresarial no se ve invadida por la base de datos. Después de explicar el TCC, creo que todo el mundo está preocupado por esto Point tendrá algo de experiencia.
2PC tiene tres desventajas principales: bloqueo de sincronización, punto único de falla e inconsistencia de datos.
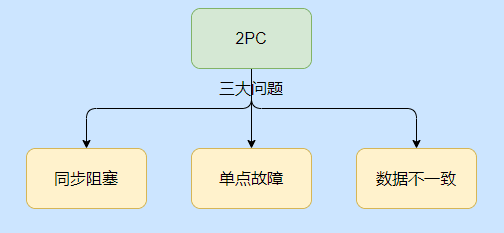
Bloqueo sincrónico
Se puede ver que después de que se ejecutó el comando de preparación en la primera etapa, cada uno de nuestros recursos locales se bloqueó porque hicimos todo menos la confirmación de la transacción.
Entonces, en este momento, si otras solicitudes locales desean acceder al mismo recurso, por ejemplo, si desea modificar los datos de la identificación de la tabla del producto igual a 100, entonces está bloqueado en este momento y debe esperar a que se complete la transacción anterior y recibir el comando commit / rollback. Después de ejecutar la liberación de recursos, la solicitud puede continuar.
Entonces, suponga que esta transacción distribuida involucra a muchos participantes, y luego algunos participantes son particularmente complejos y lentos de procesar, entonces esos nodos que procesan rápido tienen que esperar, por lo que la eficiencia es un poco baja.
Punto único de fallo
Se puede ver que este único punto es el coordinador, y si el coordinador cuelga toda la transacción, no se puede ejecutar.
Si el coordinador cuelga antes de enviar el comando de preparación, después de todo, todos los recursos no han ejecutado el comando, entonces el recurso no está bloqueado.
Lo terrible es que se cuelga después de enviar el comando de preparación. En este momento, todos los recursos locales se ejecutan y bloquean, y es muy rígido. Si se bloquea un recurso activo, se estima que es Es GG.

Inconsistencia de datos
Porque la comunicación entre el coordinador y los participantes se realiza a través de la red, y la red a veces se producen convulsiones o anomalías en la red local.
Entonces puede hacer que algunos participantes no reciban la solicitud del coordinador y que algunos la reciban. Por ejemplo, se envía una solicitud y luego los participantes que recibieron el pedido envían la transacción. En este momento, se produce el problema de la inconsistencia de los datos.
Para resumir 2PC
Hasta ahora, resumamos algo de 2PC, que es un protocolo de compromiso de dos fases con bloqueo síncrono y una fuerte consistencia, que es la fase de preparación y la fase de compromiso / retroceso.
La ventaja de 2PC es que no hay intrusión en el negocio y la base de datos en sí se puede utilizar para confirmar y deshacer transacciones.
Sus desventajas: es un protocolo de bloqueo síncrono, lo que provocará alta latencia y degradación del rendimiento, y habrá un único punto de falla del coordinador, y en casos extremos habrá inconsistencia de datos.
Por supuesto, esto es solo un acuerdo, y la implementación específica aún se puede modificar. Por ejemplo, si el coordinador tiene un solo punto, haré un maestro e implementaré el coordinador, ¿verdad?
Modelo mejorado de 2PC de base de datos distribuida
Quizás algunas personas no estén familiarizadas con las bases de datos distribuidas, no importa, lo que aprendemos principalmente es pensar, mirar las ideas de otras personas.
Permítanme hablar brevemente sobre el modelo Percolator, es un modelo basado en el sistema de almacenamiento distribuido BigTable, no importa si BigTable es un estudiante que no sabe lo que es.
Tomemos el ejemplo de la transferencia. Ahora tengo 200 yuanes y ahora tienes 100 yuanes. Para resaltar los puntos clave, no dibujo esta tabla de acuerdo con la estructura normal.
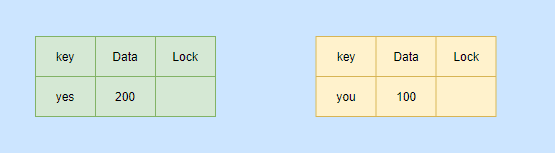
Entonces quiero transferirte 100 yuanes.
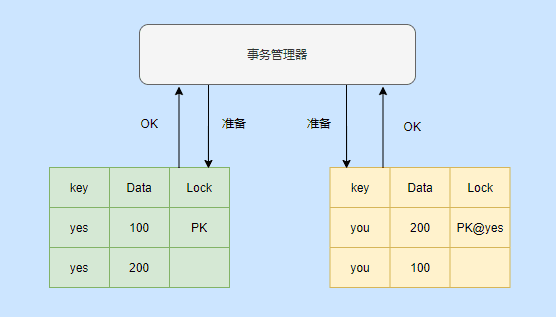
En este momento, el administrador de transacciones inicia una solicitud de preparación, y luego el dinero en mi cuenta es menor y su cuenta tiene más dinero, y el administrador de transacciones también registra el registro de esta operación.
Los datos en este momento siguen siendo una versión privada. Ya sea que otras transacciones no estén disponibles, simplemente comprenda que si hay un valor en Lock, aún es privado.
Puede ver que mi registro Lock está marcado con un PK y su registro está marcado con un puntero a mi registro. Este PK se selecciona al azar.
Luego, el administrador de transacciones iniciará un comando de confirmación en el registro seleccionado como PK.
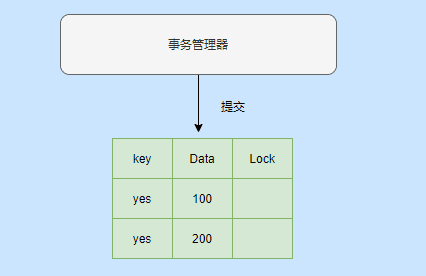
En este momento, el bloqueo de mi registro se borrará, lo que significa que mi registro ya no es una versión privada y se puede acceder a otras transacciones.
¿Hay un candado en su registro? ¿No necesitas actualizar?
Jeje no necesita ser actualizado a tiempo, porque al acceder a su registro, encontrará mi registro basado en el puntero y encontrará que el registro ha sido enviado para que se pueda acceder a su registro.
Algunas personas dicen que la eficiencia no es mala, hay que buscarla todo el tiempo, no te preocupes.
Habrá un hilo en segundo plano para escanear y luego actualizar el registro de bloqueo.
¿No es esto estable?
Mejorado en comparación con 2PC
En primer lugar, Percolator no necesita interactuar con todos los participantes en la fase de presentación, la principal debe ser tratar con un participante, por lo que esta presentación es atómica. Resuelva el problema de la inconsistencia de los datos.
Luego, el administrador de transacciones registrará el registro de operaciones, de modo que cuando el administrador de transacciones cuelgue, el nuevo administrador de transacciones elegido pueda conocer la situación actual a través del registro y continuar trabajando, resolviendo el problema del punto único de falla.
Y Percolator también tendrá un hilo de fondo que escaneará el estado de la transacción y revertirá las transacciones en cada participante después de que el administrador de transacciones deje de funcionar.
Se puede ver que en comparación con 2PC, se han realizado muchas mejoras y también son inteligentes.
De hecho, existen otros modelos de transacciones para bases de datos distribuidas, pero no estoy muy familiarizado con ellos, por lo que no sonaré demasiado y los estudiantes interesados pueden aprenderlo por sí mismos.
Todavía puede ampliar la mente.
Especificación XA
Volvamos a 2PC. Ahora que hablamos de 2PC, también mencioné brevemente la especificación XA. La especificación XA se basa en el envío de dos fases, que implementa el protocolo de envío de dos fases.
Antes de hablar de la especificación XA, debemos mencionar el modelo DTP, a saber, procesamiento de transacciones distribuidas, que regula el diseño del modelo de transacciones distribuidas.
La especificación XA restringe la interacción entre el administrador de transacciones (TM) y el administrador de recursos (RM) en el modelo DTP. En pocas palabras, ¡ustedes dos deben comunicarse de acuerdo con una determinada especificación de formato!
Veamos primero el modelo DTP bajo la restricción XA.
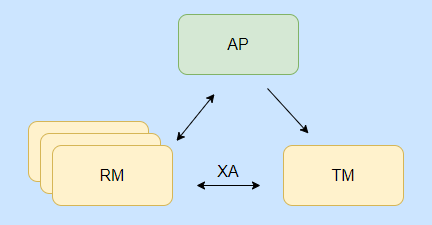
- La aplicación AP es nuestra aplicación, el iniciador de la transacción.
- Administrador de recursos de RM, simplemente piense en ello como una base de datos, con capacidades de confirmación y reversión de transacciones, correspondiente a nuestro 2PC anterior es un participante.
- El administrador de transacciones de MT es el coordinador y se comunica con cada RM.
En pocas palabras, AP usa TM para definir operaciones de transacción. TM y RM se comunican a través de la especificación XA y realizan un compromiso de dos fases. Los recursos de AP se toman de RM.
Desde la perspectiva del modelo, hay tres roles, pero la implementación real puede ser implementada por un rol para lograr dos funciones, como AP para lograr la función de TM, TM no necesita implementarse por separado.
MySQL XA
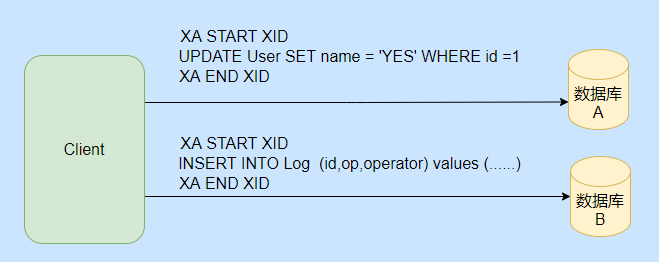
Después de conocer DTP, echemos un vistazo a cómo funciona XA en MySQL, pero solo InnoDB lo admite.
En pocas palabras, es necesario definir primero un XID globalmente único y luego informar a cada rama de transacción para que realice la operación.
Se puede ver que en la figura se han realizado dos operaciones, a saber, cambiar el nombre e insertar el log, lo que equivale a lo primero que se hace bajo el registro. El SQL a ejecutar está envuelto por XA START XID y XA END XID.
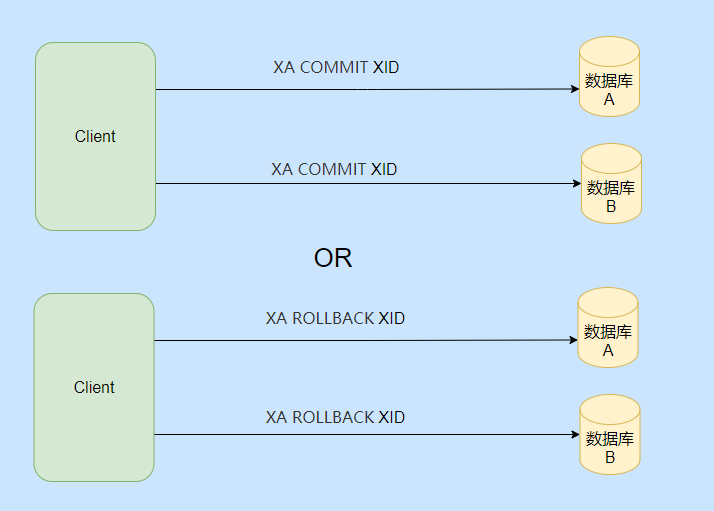
Luego, debe enviar un comando de preparación para ejecutar la primera etapa, que es la etapa en la que se realiza todo excepto la confirmación de la transacción.

Luego, de acuerdo con la situación de preparación, elija ejecutar el comando de transacción de confirmación o revertir el comando de transacción.
Básicamente es un proceso de este tipo, pero el rendimiento de MySQL XA no es alto.
Se puede ver que aunque 2PC tiene deficiencias, todavía hay implementaciones basadas en 2PC. La introducción de 3PC es para solucionar algunas de las deficiencias de 2PC, pero es más caro en su conjunto y no puede resolver el problema de la partición de red. No he encontrado La implementación de 3PC.
Pero déjame mencionarlo un poco, solo conócelo, pura teoría.
3 piezas
La introducción de 3PC es para resolver el bloqueo de sincronización de 2PC y reducir la inconsistencia de datos.
3PC es una etapa adicional, una etapa de investigación, que son las tres etapas de preparación, presentación previa y presentación.
La etapa de preparación es simplemente la visita del coordinador a los participantes ¿Está bien ser similar a usted? Puede aceptar la solicitud.
El compromiso previo es en realidad la fase de preparación de 2PC, excepto el compromiso de transacción.
La fase de envío es la misma que la de 2PC.
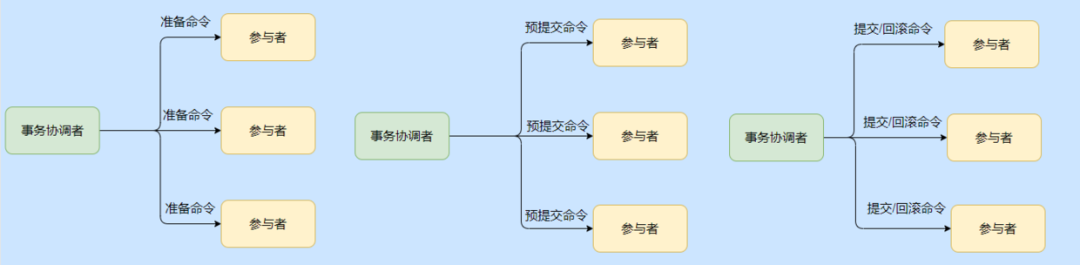
De hecho, 3PC tiene una etapa adicional para confirmar si el participante es normal antes de ejecutar la transacción, evitando que los participantes individuales sean anormales y que otros participantes realicen la transacción y bloqueen los recursos.
El punto de partida es bueno, pero en la mayoría de los casos es definitivamente normal, por lo que no es rentable tener una fase interactiva adicional cada vez.
Luego, 3PC también introdujo un mecanismo de tiempo de espera en los participantes, de modo que si el coordinador cuelga, si se ha alcanzado la fase de compromiso, los participantes automáticamente confirmarán la transacción si esperan mucho tiempo sin recibir al coordinador.
Pero, ¿y si el coordinador emite un comando de reversión? Ves que esto está mal, los datos son inconsistentes.
También existe Wikipedia que después de la fase de preparación del participante de 2PC, si el coordinador cuelga, los participantes no podrán conocer la situación general, porque la situación general está controlada por el coordinador, por lo que no tienen clara la situación entre los participantes.
3PC ha superado la primera etapa de confirmación, aunque el coordinador cuelgue a los participantes, saben que se encuentran en la etapa de pre-compromiso porque han sido aprobados por todos los participantes en la etapa de preparación.
En pocas palabras, es como agregar una valla para unificar el estado de cada participante.
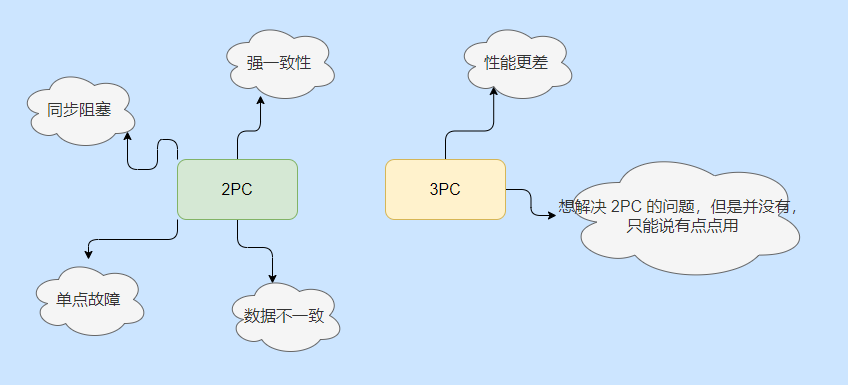
Resumen 2PC y 3PC
Se ha sabido por lo anterior que 2PC es un protocolo de bloqueo síncrono muy consistente, y su rendimiento ya es relativamente pobre.
El punto de partida de 3PC es resolver las deficiencias de 2PC, pero una etapa más aumentará la sobrecarga de comunicación, y es una comunicación inútil en la mayoría de los casos.
Aunque el tiempo de espera del participante se introduce para resolver el problema de bloqueo que cuelga el coordinador, los datos seguirán siendo inconsistentes.
Se puede ver que la introducción de 3PC no tiene un avance real y el rendimiento es peor, por lo que solo se implementa la implementación de 2PC.
De nuevo, tanto 2PC como 3PC son protocolos, que pueden considerarse como una ideología rectora, que es diferente de la implementación real.
TCC
No sé si lo ha notado, ya sea 2PC o 3PC, depende de la transacción confirmada y la reversión de la base de datos.
Y, a veces, algunos negocios no solo involucran la base de datos, sino que también pueden enviar un mensaje de texto o cargar una imagen.
Por lo tanto, el compromiso y la reversión de transacciones deben promoverse al nivel empresarial en lugar de al nivel de la base de datos, y TCC es un compromiso de dos fases a nivel empresarial o de aplicación.
TCC se divide en tres métodos que se refieren a Probar, Confirmar y Cancelar, es decir, tres métodos que deben escribirse a nivel empresarial. Se utilizan principalmente para problemas de coherencia de datos en operaciones comerciales entre bases de datos y servicios cruzados.
TCC se divide en dos fases, la primera fase es la fase de reserva de verificación de recursos, es decir, Prueba, la segunda fase es el envío o la reversión, si se envía, es para realizar operaciones comerciales reales, si es la reversión, es para realizar los recursos reservados Cancelar y restaurar el estado inicial.
Por ejemplo, si hay un servicio de deducción, necesito escribir un método Try para congelar los fondos de la deducción, y también necesito un método Confirm para realizar la deducción real, y finalmente necesito proporcionar Cancelar para revertir la operación de congelación, correspondiente a una transacción. Todos los servicios deben proporcionar estos tres métodos.
Se puede ver que había un método, pero ahora debe expandirse a tres métodos, por lo que TCC tiene una gran intrusión en el negocio, como si no hubiera un campo congelado, la estructura debe cambiarse.
Veamos el proceso.
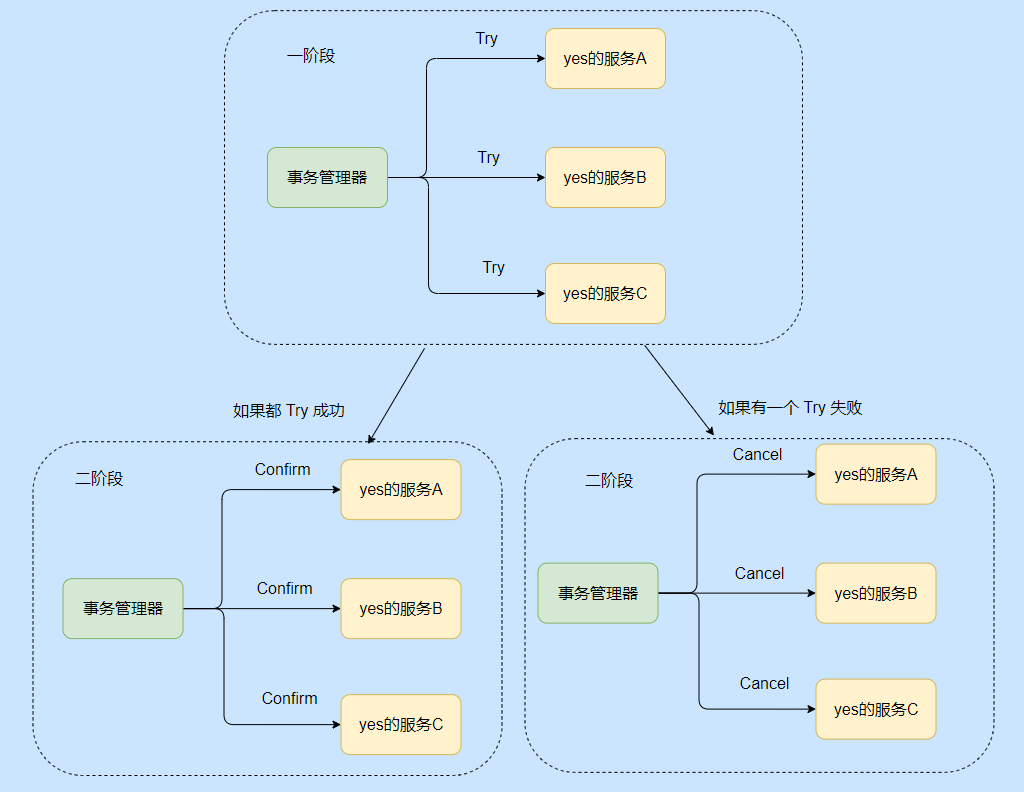
Aunque hay una intrusión en el negocio, TCC no tiene bloqueo de recursos. Cada método envía la transacción directamente. Si ocurre un error, se compensa a través del Cancelar a nivel de negocio, por lo que también se le llama método de transacción compensatoria.
Alguien dijo que si todos lo intentaron y ejecutaron Comfirm, pero algunos Confirm fallaron, ¿qué debería hacer?
En este momento, solo puede volver a intentar y ajustar el Confirmar fallido hasta que tenga éxito. Si realmente no funciona, solo puede grabarlo y luego la intervención manual.
Puntos a tener en cuenta para TCC
Estos puntos son muy importantes y debes prestarles atención cuando los implementes.
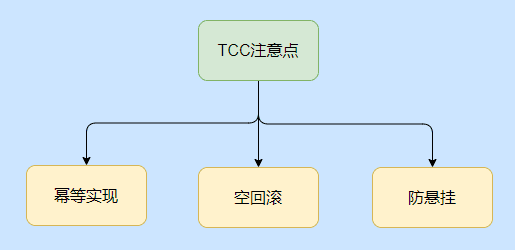
El problema de la idempotencia, porque las llamadas a la red no pueden garantizar que llegue la solicitud, por lo que habrá un mecanismo de reajuste, por lo que los tres métodos de Probar, Confirmar y Cancelar deben implementarse idempotentes para evitar errores por ejecución repetida.
El problema de la reversión vacía significa que el método Try no recibió un tiempo de espera debido a problemas de red. En este momento, el administrador de transacciones emitirá un comando Cancelar, por lo que debe admitir Cancelar para Cancelar normalmente sin ejecutar Try.
Problema de suspensión, este problema también se refiere al método Try debido a que el tiempo de espera de la congestión de la red provocó que el administrador de transacciones emitiera un comando Cancelar, pero después de que se ejecuta el comando Cancelar, llega la solicitud de Prueba y se queda sin aliento.
Cancelar espera a que tenga un Try. Para el administrador de transacciones, la transacción finaliza en este momento y la operación de congelación está "suspendida", por lo que después de la reversión vacía, debe registrarla para evitar que se vuelva a llamar al Try.
Variantes de TCC
Hablamos del TCC de propósito general anterior, necesita transformar la implementación anterior, pero hay una situación que no se puede modificar, es decir, estás llamando a la interfaz de otra empresa.
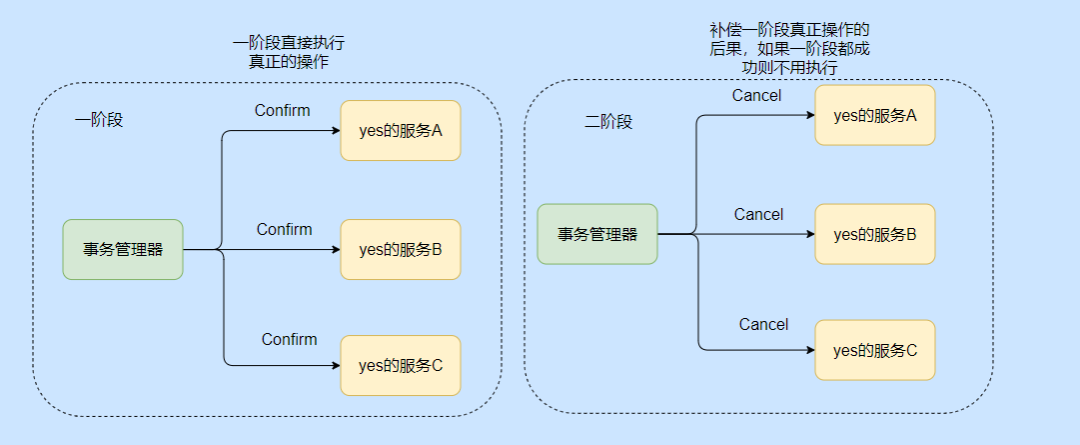
TCC sin probar
Por ejemplo, necesita hacer un transbordo en avión y el transbordo es una aerolínea diferente. Por ejemplo, de A a B, luego de B a C, solo tiene sentido comprar boletos para A-B y B-C.
En este momento, no es necesario que lo intente, puede llamar directamente a la operación de compra de boletos de la aerolínea. Cuando ambas aerolíneas compren correctamente, lo harán directamente. Si una empresa no compra, debe llamar a la interfaz de cancelación de reserva. .
Es decir, toda la operación comercial se ejecuta directamente en la primera etapa, por lo tanto, concéntrese en la operación de reversión. Si la reversión falla, hay un recordatorio y se requiere la intervención manual.
Esta es en realidad la idea de TCC.
TCC asincrónico
¿Puede este TCC ser asíncrono? De hecho, también es una especie de compromiso, por ejemplo, algunos servicios son difíciles de transformar y no afectará la decisión principal del negocio, es decir, no es tan importante y no requiere una ejecución oportuna.
En este momento, se pueden introducir servicios de mensajes confiables y los servicios individuales se pueden reemplazar por servicios de mensajes para Probar, Confirmar y Cancelar.
Al intentarlo, solo se escribe el mensaje y el mensaje aún no se puede consumir. Confirmar es la operación para enviar realmente el mensaje y Cancelar es cancelar el envío del mensaje.
Este confiable servicio de mensajes es realmente similar al mensaje de transacción que se mencionará más adelante Esta solución es equivalente a una combinación de mensaje de transacción y TCC.
Resumen de TCC
Se puede ver que TCC implementa el compromiso y la reversión de transacciones a través del código comercial, que es más intrusivo para el negocio. Es un compromiso de dos fases a nivel comercial.
Su rendimiento es superior a 2PC, porque no habrá bloqueo de recursos y el ámbito de aplicación es mayor que 2PC. Preste atención a los varios puntos mencionados anteriormente en la implementación.
Es un método comúnmente utilizado de implementación de transacciones distribuidas en la industria y se puede conocer a partir de las variantes. Aún depende de la flexibilidad empresarial. No significa que deba usar TCC para transformar rígidamente todos los servicios en esos tres métodos. .
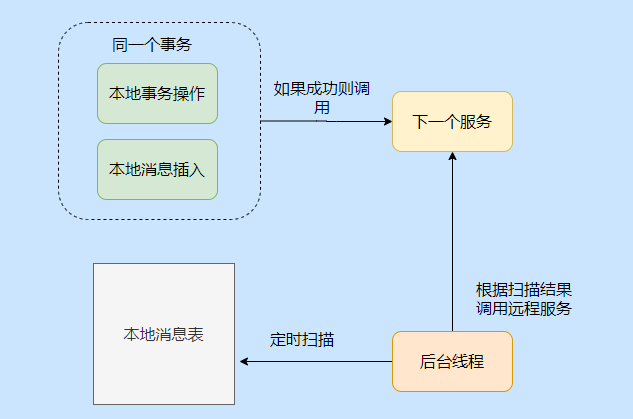
Tabla de mensajes locales
El mensaje local es el uso de transacciones locales, la tabla de mensajes de la transacción local se almacenará en la base de datos y la inserción del mensaje local se agrega en la operación de transacción local, es decir, la ejecución del negocio y la operación de poner el mensaje en la tabla de mensajes se colocan en la misma. Comprometerse en la transacción
De esta forma, si la transacción local se ejecuta exitosamente, el mensaje debe ser insertado exitosamente y luego se llaman otros servicios, si la llamada es exitosa se modifica el estado del mensaje local.
Si falla, no importa. Habrá un escaneo de hilo en segundo plano, y siempre llamará al servicio correspondiente cuando encuentre estos mensajes de estado. Generalmente, se establecerá el número de reintentos. Si no funciona, se grabará especialmente y se procesará mediante intervención manual.
Se puede ver que todavía es muy simple, y también es una especie de pensamiento de notificación de mejor esfuerzo.
Mensaje de transacción
De hecho, escribí un artículo sobre mensajes de transacción, analizando la implementación de mensajes de transacción de RocketMQ y Kafka desde el nivel de origen, y la diferencia entre los dos.
No daré más detalles aquí, porque el artículo anterior es muy detallado, de cuatro a cinco mil palabras. Adjuntaré el enlace: mensaje de transacción
Implementación de Seata
En primer lugar, qué es Seata, extracto del sitio web oficial.
Seata es una solución de transacciones distribuidas de código abierto dedicada a proporcionar servicios de transacciones distribuidas de alto rendimiento y fáciles de usar. Seata proporcionará a los usuarios modos de transacción AT, TCC, SAGA y XA para crear una solución distribuida única para los usuarios.
Puede ver que se proporcionan muchos modos, primero echemos un vistazo al modo AT.
Modo AT
El modo AT es una presentación de dos fases. Anteriormente mencionamos el problema del bloqueo sincrónico en la presentación de dos fases. La eficiencia es demasiado baja. ¿Cómo lo resuelve Seata?
En la primera etapa, AT confirma la transacción directa y directamente libera el bloqueo local. ¿Es tan precipitada y directamente comprometida? Por supuesto que no, esto es similar a la tabla de mensajes local, es decir, al usar transacciones locales, el registro de reversión se insertará durante la operación de transacción real y luego se confirmará en una transacción.
¿Cómo surgió este registro de reversión?
A través de algunas clases del marco proxy JDBC, cuando se ejecuta SQL, el SQL se analiza para obtener el espejo de datos antes de la ejecución, y luego se ejecuta el SQL y se obtiene el espejo de datos después de la ejecución, y luego los datos se ensamblan en un registro de reversión.
El envío posterior de esta transacción local también inserta el registro de reversión en la tabla UNDO_LOG de la base de datos (por lo que la base de datos necesita una tabla UNDO_LOG).
Esta ola de operaciones puede comprometer transacciones sin preocupaciones en una etapa.
Luego, si la primera etapa tiene éxito, la segunda etapa puede eliminar esos registros de reversión de forma asincrónica, y si la primera etapa falla, el registro de reversión se puede utilizar para revertir la compensación y la recuperación.
En este momento, un compañero de clase atento pensó, ¿qué pasa si alguien cambia estos datos? ¿Tu imagen reflejada es incorrecta?
Por lo tanto, también existe el concepto de bloqueo global. Debe obtener un bloqueo global (que puede entenderse como un bloqueo de estos datos) antes de que se confirme la transacción, y luego la transacción local se puede enviar correctamente.
Si no puede obtenerlo, debe revertir la transacción local.
El ejemplo del sitio web oficial es muy bueno, por lo que no lo editaré yo mismo. La siguiente parte es un extracto del ejemplo del sitio web oficial de Seata:
En este momento, hay dos transacciones, a saber, tx1 y tx2, que actualizan el campo m de la tabla a, y el valor inicial de m es 1000.
tx1 comienza primero, abre la transacción local, obtiene el bloqueo local y actualiza m = 1000-100 = 900. Antes de que se confirme la transacción local, primero se obtiene el bloqueo global del registro y se libera el compromiso local para liberar el bloqueo local.
Después de tx2, inicie la transacción local, obtenga el bloqueo local y actualice m = 900-100 = 800. Antes de que se confirme la transacción local, intente obtener el bloqueo global del registro. Antes de que tx1 se confirme globalmente, el bloqueo global del registro lo mantiene tx1, y tx2 debe volver a intentarlo y esperar el bloqueo global.
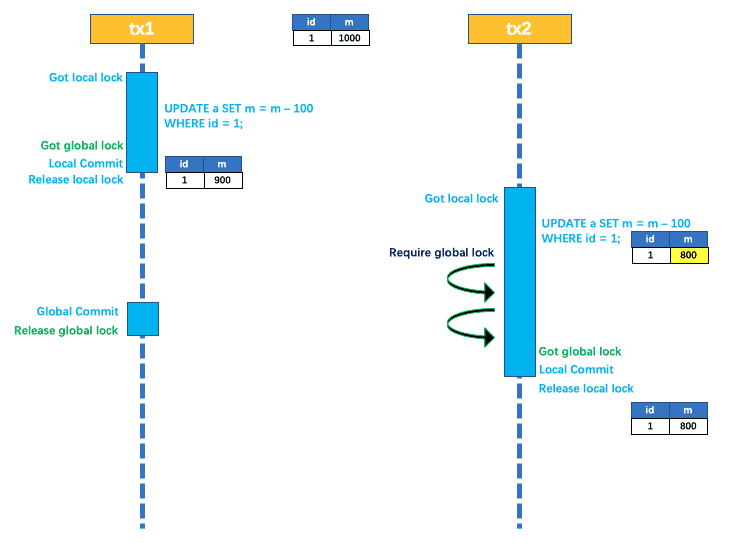
Puede ver que la modificación de tx2 está bloqueada y, después de volver a intentar obtener el bloqueo global, puede confirmar y liberar el bloqueo local.
Si tx1 retrocede globalmente en la segunda etapa, tx1 necesita volver a adquirir el bloqueo local de los datos, realizar una operación de actualización de compensación inversa e implementar la reversión de rama.
En este punto, si tx2 todavía está esperando un bloqueo global para los datos y mantiene un bloqueo local al mismo tiempo, la reversión de la rama de tx1 fallará. La reversión de la rama se reintentará hasta que caduquen los bloqueos como el bloqueo global de tx2, el bloqueo global se abandone y la transacción local se retrotraiga para liberar el bloqueo local y la reversión de la rama de tx1 finalmente sea exitosa.
Dado que tx1 retiene todo el proceso hasta que finaliza la ubicación global tx1, no se producirá el problema de la escritura sucia.
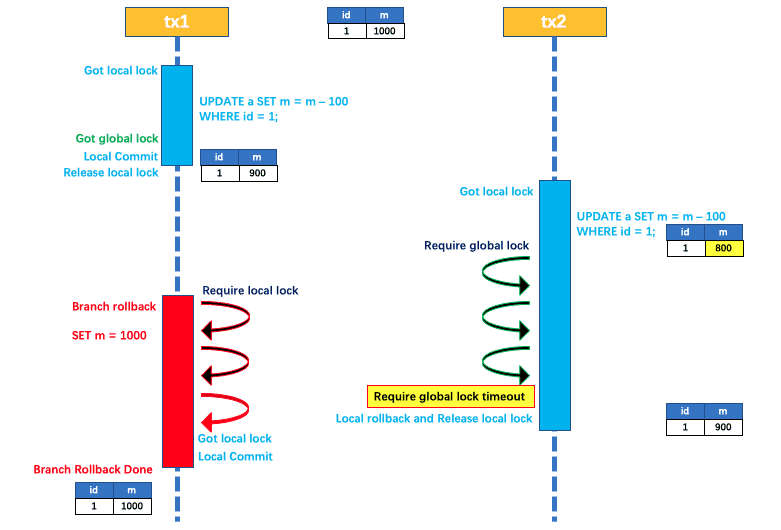
Luego, el modo AT toma por defecto el nivel de aislamiento de lectura no confirmada globalmente. Si la aplicación se encuentra en un escenario específico, se debe solicitar que se envíe la lectura global, que puede delegarse mediante la instrucción SELECT FOR UPDATE.
Por supuesto, la premisa es si el nivel de aislamiento de la transacción local se ha confirmado y es superior.
Resumen del modo AT
Se puede ver que los espejos frontal y posterior de los datos se obtienen sin intrusión a través del agente, y el registro de reversión se ensambla en un registro de reversión y se envía con la transacción local, lo que resuelve el problema del bloqueo de sincronización de dos fases.
Y use bloqueos globales para lograr el aislamiento de escritura.
Por consideraciones de rendimiento general, el valor predeterminado es el nivel de aislamiento de lectura no confirmada y solo se utiliza el agente SELECT FOR UPDATE para realizar el aislamiento de lectura enviada.
Esta es en realidad una implementación variante del compromiso de dos fases.
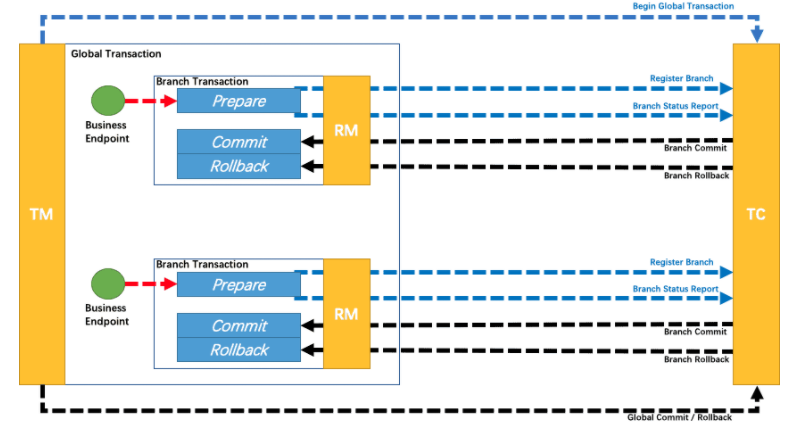
Modo TCC
No hay nada sofisticado, es decir, necesitamos hacer tres métodos analizados anteriormente y luego incorporar transacciones de sucursales personalizadas en la gestión de transacciones globales
Publiqué una imagen del sitio web oficial que debería ser bastante clara.
Modo saga
Esta Saga es una solución de transacciones largas proporcionada por Seata, que es adecuada para el caso de muchos y largos procesos de negocios. En este caso, si desea implementar un TCC general o algo así, es posible que tenga que anidar varias transacciones.
Y algunos sistemas no pueden proporcionar las tres interfaces de TCC, como los proyectos antiguos o las empresas de otras empresas, por lo que han desarrollado un modo Saga.Esta Saga fue propuesta en un artículo publicado por Hector & Kenneth en 1987.
¿Cómo lo hace Saga? Eche un vistazo a esta imagen.
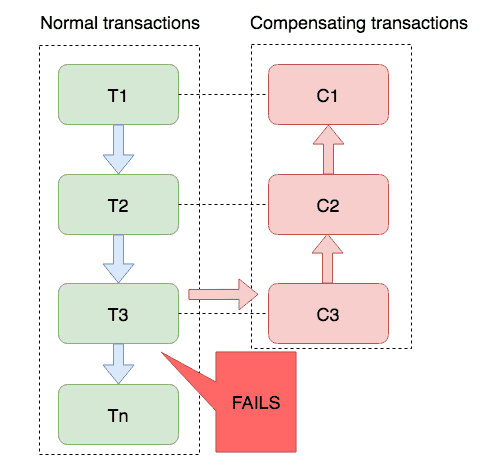
Suponiendo que hay N operaciones, comenzar directamente desde T1 es ejecutar directamente la transacción de confirmación y luego ejecutar T2, puede ver que es una confirmación directa sin bloqueo. En T3, se encuentra que la ejecución ha fallado, y luego entra en la fase de compensación y comienza a compensar una por una. Arriba.
La idea es cubrirse la cabeza y hacerlo al principio, no se deje persuadir, si algo sale mal, volveremos a cambiar uno a uno.
Se puede ver que esta situación no garantiza el aislamiento de las cosas, y Saga también tiene los mismos puntos de atención de TCC, que requiere compensación aérea, anti-ahorcamiento e idempotencia.
Y en casos extremos, los datos no se pueden revertir porque se han modificado. Por ejemplo, en el primer paso, me llamé 20.000 yuanes y lo saqué y lo gasté. En este momento, retrocedes y el saldo de mi cuenta ya es 0. ¿Qué piensas? ¿Será que no me basta con fallar?
Esta situación solo se puede iniciar en el proceso de negocio, de hecho, siempre he escrito el código así, toma el escenario de comprar un skin, siempre deduzco el dinero antes de dar el skin.
Suponga que si no puede deducir el dinero de la piel primero, ¿no lo dará a cambio de nada? ¿Puedes recuperar este dinero? ¿Crees que los usuarios darán retroalimentación de que el skin no ha descontado el dinero?
Tal vez un pequeño fantasma inteligente dijo que cambiaría mi piel en ese entonces, jeje, este tipo de cosas sí sucedieron, colmillo, es terrible que me regañen.
Por lo tanto, el proceso correcto debería ser primero deducir el dinero y luego dar la máscara. El dinero está en su bolsillo primero. Si la máscara no se le da al usuario exitoso, el usuario la encontrará naturalmente. Luego, dásela. Aunque puede haber escrito un ERROR, no es algo bueno. ERROR dado por nada.
Por lo tanto, se debe prestar atención a este punto al codificar.

Al final
Se puede ver que las transacciones distribuidas todavía tienen varios problemas y la implementación de transacciones distribuidas generales solo puede lograr la consistencia final.
En casos extremos, la intervención manual sigue siendo necesaria, por lo que un buen registro de registros es fundamental.
También existen procesos comerciales de codificación. Escriba en una dirección que sea beneficiosa para la empresa. Por ejemplo, primero obtenga el dinero del usuario y luego déle algo. Recuerde.
Antes de pasar a transacciones distribuidas, piénsalo, ¿es necesario, puedes cambiarlo para evitar transacciones distribuidas?
Para ser más extremo, ¿su empresa necesita ir a la empresa?
Lectura recomendada para artículos de alta calidad:
Preguntas avanzadas de la entrevista de Alibaba (primer número, 136 preguntas de alta frecuencia, incluidas las respuestas)
https://blog.csdn.net/weixin_45132238/article/details/107251285
Las 4 guías de entrevistas de bajo nivel de GitHub Biaoxing 20w (capa inferior de la computadora + sistema operativo + algoritmo), titulares de entrevistas / ¡Tencent tiene razón!
https://blog.csdn.net/weixin_45132238/article/details/108640805
Combate de arquitectura interna de Alibaba: SpringBoot / SpringCloud / Docker / Nginx / distribuido
https://blog.csdn.net/weixin_45132238/article/details/108666255