Tabla de contenido
Resumen
Al publicar el registro de eventos, debeConsidere el riesgo de este ataque de reidentificación. En este artículo, mostramos cómo pasar el registro de eventosMedidas de singularidad individual para cuantificar los riesgos de reidentificación. También informamos sobre un estudio a gran escala que exploró la singularidad de las personas en una serie de registros de eventos públicos. Nuestros resultados indican que potencialmente se pueden volver a identificar hasta todas las situaciones en el registro de eventos, lo que destaca la importancia de la tecnología de protección de la privacidad en la minería de procesos.
Introducción
Debido a las conocidas amenazas a la privacidad, la disposición a publicar registros de eventos es baja. Sin embargo, los registros de eventos disponibles públicamente son necesarios para evaluar los modelos de minería de procesos [2-4], por lo queNecesito discutir cómo publicar registros de eventos de forma segura. En este contexto, creemos que es importante comprender los riesgos de la reidentificación de datos en los registros de eventos y la minería de procesos. Con esta información, podemos equilibrar cuánta información puede compartir el registro de eventos y cuánta información debe mantenerse de forma anónima para proteger la privacidad . Aunque muchos ejemplos han confirmado el riesgo general de re-identificación de datos [5-7], el riesgo de re-identificación de los registros de eventos no ha atraído suficiente atención.
El propósito de este artículo es crear conciencia sobre el riesgo de reidentificación de los registros de eventos, por lo queProporcionar medidas para cuantificar este riesgo.. Con este fin, proporcionamos un método para representar la singularidad de los datos, que se deriva del modelo comúnmente utilizado en la tecnología de minería de procesos. Cada evento registrado en el registro de eventos se compone de tipos de datos específicos, como el nombre de la actividad del paso del proceso correspondiente, la marca de tiempo de su ejecución y los atributos del evento que capturan el contexto y los parámetros de la actividad. Además, la secuencia de eventos (también llamados trayectorias) relacionados con el mismo caso del proceso tiene atributos de datos, los llamados atributos de caso, que contienen información general sobre el caso.
Para extraer información confidencial, el atacante utiliza conocimientos previos para correlacionar los atributos del objetivo con los atributos del caso / evento en el registro de eventos., Por ejemplo, correlacionando fuentes disponibles públicamente.Cuanto mayor sea la singularidad del registro de eventos, mayor será la probabilidad de que el oponente identifique el objetivo. Por lo tanto, nuestro método explora el número de casos identificables de forma única por el conjunto de atributos de casos o el conjunto de atributos de eventos.. Usamos esta información para derivar la métrica de unicidad del registro de eventos como base para estimar la probabilidad de volver a identificar el caso. Para demostrar la importancia de la singularidad de los registros de eventos, realizamos un estudio a gran escala sobre 12 registros de eventos disponibles públicamente del almacén de datos de 4TU.Centre for Research. 1 Clasificamos los registros y evaluamos la singularidad de las personas involucradas en el caso. Nuestros resultados en estos registros indican que, con base en el conocimiento previo, es posible que el adversario vuelva a identificar todos los casos.Mostramos que el atacante solo necesita algunos atributos de la trayectoria para lanzar con éxito un ataque de este tipo.. Las contribuciones de este artículo se pueden resumir de la siguiente manera:
- Proponemos un método para cuantificar los riesgos de privacidad asociados con los registros de eventos. De esta manera, apoyamos la identificación de información que debería prohibirse al publicar registros de eventos, promoviendo así el uso responsable de los registros y allanando el camino para casos de uso novedosos basados en el análisis de registros de eventos.
- Al informar los resultados de estudios de evaluación a gran escala, enfatizamos la necesidad de desarrollar una tecnología de protección de privacidad de registros de eventos altamente práctica para el análisis de procesos. Nuestros conceptos de singularidad personal pueden impulsar este esfuerzo porque aclaran los riesgos inherentes a la privacidad.
La estructura de este artículo es la siguiente. La sección 2 ilustra las amenazas a la privacidad en la minería de procesos. La sección 3 presenta métodos para cuantificar los riesgos de reidentificación. Analizamos los registros de eventos que están disponibles públicamente.
Amenazas a la privacidad de la minería de procesos

La minería de procesos utiliza registros de eventos para descubrir y analizar procesos comerciales. El registro de eventos captura la ejecución de actividades como eventos. Una secuencia finita de tales eventos forma una trayectoria, que representa una sola instancia de proceso (también llamada caso). Por ejemplo, el tratamiento de los pacientes en la sala de emergencias incluye muchos eventos, como la toma de muestras y análisis de sangre, que en conjunto siguen una estructura específica determinada por el proceso. Por tanto, un evento relacionado con un solo paciente constituye un caso. Además, los atributos del caso proporcionan información general sobre el caso, como el lugar de nacimiento del paciente. Cada evento se compone de varios tipos de datos, como el nombre de cada actividad, la marca de tiempo de ejecución y los atributos del evento. Los atributos del evento son específicos del evento y pueden cambiar con el tiempo, como la temperatura o el departamento que realiza el tratamiento. La principal diferencia entre los atributos del caso y los atributos del evento es que los atributos del caso no cambiarán el valor del caso durante el período de observación. Mostramos un ejemplo de un registro de eventos completo en la Tabla 1, que captura el flujo de la sala de emergencias.
Teniendo en cuenta la estructura del registro de eventos, se identificaron varias amenazas a la privacidad.Vincular casos a personas puede revelar información confidencialPor ejemplo, en el proceso de la sala de emergencias, ciertos eventos pueden indicar que el paciente se encuentra en una determinada condición. Generalmente, los atributos de los casos pueden contener varios datos confidenciales para revelar el origen racial o étnico, opiniones políticas, creencias religiosas o filosóficas e información financiera o de salud. mismo,El registro de eventos puede mostrar información sobre la productividad del personal del hospital [8] o el horario de trabajo.. Tal vigilancia de los empleados es una seria amenaza a la privacidad. Obviamente, es importante incluir consideraciones de privacidad en los proyectos de minería de procesos. nosotrosSuponga que el objetivo del oponente es identificar a las personas vinculando información externa en el registro de eventos。
Dependiendo del tipo de información de fondo, puede haber diferentes modelos de oponentes .Suponemos una reidentificación dirigida, es decir, el oponente tiene información sobre un individuo específico, que incluye un subconjunto de valores de atributos. Con base en esto, el adversario tiene como objetivo revelar información sensible, como información de diagnóstico.. Aquí, asumimos que el oponente sabe que hay una persona en el registro de eventos . En este artículo, consideramos métricas de unicidad para cuantificar el riesgo de re-identificación de información sensible, proporcionando así una base para gestionar las consideraciones de privacidad.
Volver a identificar el registro de eventos
Para aplicar la medición de unicidad a un caso, agregamos todos los datos de eventos que ocurrieron al caso correspondiente. Esta suposición facilita el manejo de múltiples eventos pertenecientes al mismo caso. Dado que el atributo de caso no cambia con el tiempo, solo debe considerarse una vez, y el atributo de evento puede ser diferente para cada evento, por lo que se debe considerar el cambio de hora. La Tabla 2 proporciona los ejemplos correspondientes.

Cada fila de la tabla pertenece a un caso. Los atributos de caso "género" y "edad" se enumeran en columnas separadas.Las columnas "Actividad", "Marca de tiempo" y "Canal de llegada" contienen una lista ordenada de cada atributo.. Por ejemplo, el caso ID 11 tiene solo dos eventos, por lo que solo hay dos eventos. El segundo evento "Antibióticos" el 4 de marzo de 2019 no tuvo un "canal de acceso" (es decir, "ninguno").La singularidad del registro de eventos se utiliza como base para estimar la posibilidad de volver a identificar el caso.. Hemos estudiado muchas de las llamadas proyecciones, que pueden considerarse técnicas de minimización de datos para reducir de forma eficaz el riesgo potencial de reidentificación en el registro de eventos. La proyección se refiere a un subconjunto de atributos en el registro de eventos. Se pueden utilizar fácilmente para evaluar riesgos en diferentes situaciones . La Tabla 3 resume la proyección del registro de eventos y su uso potencial en la minería de procesos. La proyección A contiene una secuencia de todas las actividades ejecutadas y sus marcas de tiempo, mientras que la proyección F solo contiene atributos de caso . Ha demostrado queIncluso la proyección escasa de registros de eventos traerá riesgos de privacidad [4]. Por lo tanto, en nuestra evaluación, consideraremos el riesgo de reidentificación de varias proyecciones.
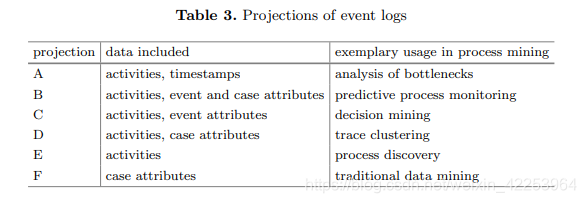
Singularidad basada en atributos de casos
Además del identificador único (UID), el llamado cuasi-identificador también es información que se puede vincular a un individuo. Una combinación de cuasi-identificadores puede ser suficiente para crear un UID. En el registro de eventos, los atributos de casos pueden verse como cuasi-identificadores. Por ejemplo, en el registro de eventos de BPI Challenge 2018 [9], el área de todos los paquetes y el ID del departamento local se pueden considerar como atributos de caso. La medición de la unicidad basada en los atributos del caso es un método común para cuantificar el riesgo de reidentificación == [10] ==. La singularidad del caso y la singularidad individual aumentarán en gran medida el riesgo de reidentificación.Un solo valor del atributo case no dará lugar al reconocimiento. Sin embargo, la combinación con otros atributos puede provocar situaciones especiales. En particular, vincular atributos a otras fuentes de información puede resultar en una reidentificación exitosa。
Definimos la unicidad como parte del caso de unicidad en el registro de eventos. Sea fk la frecuencia de la k-ésima combinación de valores de atributos de casos en la muestra. Si fk = 1, la situación es única, es decir, no hay otras situaciones con el mismo valor de atributo de caso. Por lo tanto, la unicidad del atributo de caso se define como:
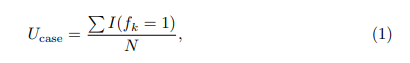
si la combinación k-ésima es única, la función de indicador I (fk = 1) es 1 y N es el número total de casos en el registro de eventos. Con referencia a los datos de la Tabla 2, el valor del atributo "género: mujer" conducirá a dos posibles casos candidatos (id: 11 e id: 11), es decir, fk = 2, lo que significa que la combinación no es única. Teniendo en cuenta la "edad" como un cuasi-identificador adicional, los tres casos enumerados pueden hacerse únicos, a saber, Ucase = 1. Dado que a menudo se publican muestras de registros de eventos, distinguimos entre la singularidad de la muestra y la singularidad general.El número de casos únicos en una muestra se denomina unicidad de muestra. Para la unicidad general, nos referimos al número de casos únicos en el registro de eventos completo (es decir, en general). Basándonos en el registro de eventos públicos, podemos medir la singularidad de la muestra. La unicidad de la población es el número de casos únicos en la muestra, y también es el número de casos únicos en la población básica de la que se extraen los datos. Por lo general, el registro de eventos es una muestra de la población y el registro de eventos original no está disponible. Por lo tanto, la unicidad total no se puede medir y debe estimarse.
Existen varios modelos para estimar la singularidad de una población a partir de una muestra. Estos métodos se basan en el modelo de extrapolación de la tabla de contingencia para simular la unicidad general, de modo que la distribución específica sea adecuada para el recuento de frecuencias [10]. Usamos el método de Rocher y Hendrickx [7] para estimar la singularidad de la población. El autor usa cópulas gaussianas para modelar la unicidad de la población, aproximar el borde de la muestra y estimar la probabilidad de que la unicidad de la muestra sea la unicidad de la población. Para este análisis, asumimos que el registro de eventos es un ejemplo publicado. Al aplicar este método, estimamos la unicidad general del caso en función de los atributos del caso.
Singularidad basada en rastros
La mayoría de los registros de eventos publicados que se utilizan para la minería de procesos no tienen muchos atributos de caso, solo atributos de evento. Por ejemplo, el registro de eventos de sepsis [11] solo tiene un atributo de caso ("edad"). Sin embargo, dependiendo del evento, el caso también puede ser único. Usamos trayectorias para medir la singularidad.
Suponemos que el objetivo principal del oponente es redefinir al individuo con múltiples puntos y revelar otros puntos sensibles.Creemos que el oponente tiene cierto conocimiento y conoce algunos puntos, y puede vincular estos puntos con el registro de eventos. En particular, asumimos que el adversario sabe que alguien está incluido en el registro de eventos.. En otras palabras, tratamos el registro de eventos publicado como un total. Como se muestra en el ejemplo de la Tabla 2, todos los casos son únicos incluso sin considerar los atributos de los casos: el caso 11 es identificable de forma única por su segundo "antibiótico" activo. Al combinar la actividad con la marca de tiempo correspondiente, el Caso 10 y el Caso 12 se pueden identificar de forma única. Por ejemplo, el oponente puede obtener información sobre la llegada del paciente (por ejemplo, "Hora de registro: 5 de marzo de 2019"). Dada esta información como punto clave de seguimiento, el oponente es suficiente para identificar al paciente y mostrar otra información del registro de eventos.
por lo tanto, nosotrosLa tasa a la que los riesgos re-identificados se expresan como circunstancias especiales.. La unicidad de la trayectoria se puede medir de manera similar a la trayectoria de posición == [12,13] ==. En la trayectoria de la posición, el punto consta solo de la posición y la marca de tiempo. Por el contrario, no solo tenemos puntos bidimensionales, sino también puntos multidimensionales de ia. Actividades, recursos y marcas de tiempo. Sea {ci} i = 1, ..., N es un evento compuesto por un conjunto de N trazas. Dado un conjunto de m puntos aleatorios (llamado Mp), contamos el número de trazas que contienen el conjunto de puntos. Si el conjunto de puntos Mp está contenido en una sola trayectoria, la trayectoria es única. La unicidad de una traza de Mp dada se define como

si la traza es única, entonces δi = 1, de lo contrario es 0.
resultado
Para la evaluación, usamos el registro de eventos públicos de 4TU.Centre for Research Data. Dividimos los registros de eventos en registros de eventos personales (R) y de software (S). El identificador de caso de un individuo en la vida real se refiere a una persona física, por ejemplo, == registro de eventos de ADL [14] == incluye las actividades de la vida diaria del individuo. En los registros de eventos que involucran actividades de software, los eventos no se refieren directamente a personas físicas, sino a componentes técnicos. P.ej,El registro de eventos del BPI Challenge 2013 [15] contiene eventos en el sistema de gestión de eventos.. Algunos registros de eventos relacionados con el software incluso contienen un solo caso, lo que hace que sea más difícil medir la singularidad del caso. Sin embargo, si el identificador apropiado se puede vincular al caso, también se puede medir la unicidad del registro de eventos relacionado con el software. Por ejemplo, los eventos en el registro de eventos del BPI Challenge 2013 son procesados por personas físicas. Al utilizar la conversión adecuada, la persona física se puede utilizar como identificador de caso. A continuación, aplicaremos nuestro método para estimar solo la unicidad de los registros de eventos individuales reales (R). Solo usamos varios atributos de casos para medir la singularidad de los atributos de casos del registro de eventos. La Tabla 4 resume los resultados de nuestra clasificación, proporciona algunos indicadores básicos del número de casos y actividades, y señala la métrica de singularidad de la aplicación. Para mejorar la legibilidad y por consideraciones éticas (consulte la sección 4.3 para obtener más detalles), aplicaremos nuestro método y discutiremos los resultados intermedios en detalle solo para los registros de eventos BPI Challenge 2018 [9] y sepsis [11]. Para todos los demás registros de eventos, proporcionamos resultados comprimidos y seudonimizados. Tenga en cuenta que la secuencia de los registros de eventos de seudónimo en las siguientes secciones es diferente a la de la Tabla 4, pero la consistencia del seudónimo es constante durante todo el proceso de evaluación.
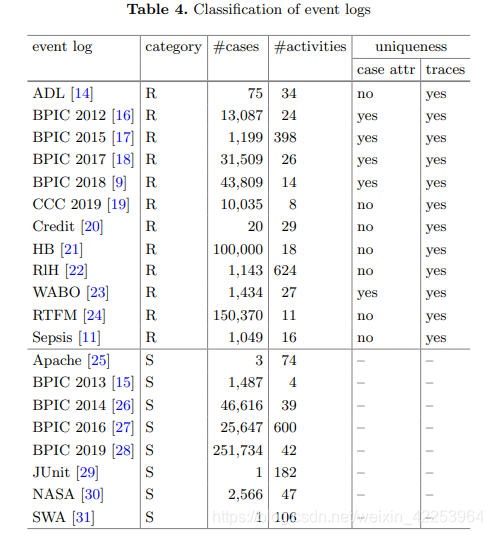
El registro de eventos del BPI Challenge 2018 es proporcionado por la empresa alemana "Data Expert". Contiene eventos relacionados con la aplicación del programa de pagos del Fondo Agrícola de Garantía de la UE. El registro de eventos contiene 43,809 casos, cada uno de los cuales representa una solicitud de pago directo realizada por los agricultores dentro de los tres años. Hemos identificado "Pago real" (PYMT), "Área" (ARA), "Departamento" (DPT), "Parcela" (#PCL), "Pequeño agricultor" (SF), "Joven agricultor" (YF) " Año ”(Y) y“ Monto aplicable ”(AMT) se utilizan como atributos de caso. Los contribuyentes de datos resumen los atributos PYMT, #PCL y AMT agrupando valores en 100 bins, donde los bins se identifican por el valor mínimo [9].
Para determinar el impacto de los atributos del caso, utilizamos varias combinaciones para evaluar su singularidad. Específicamente, estudiamos qué combinaciones de valores de atributos hacen que el caso sea más único y, por lo tanto, único. Cuanto más extenso sea el conocimiento previo del adversario, más probable será que este individuo se vuelva identificable.
Cuantos más atributos de caso, más exclusivo se vuelve el caso. No consideramos los atributos del caso que incluyen la actividad del registro de eventos (es decir, la primera actividad realizada), porque asumimos que el adversario no conoce el orden exacto en el que se realizan las actividades.
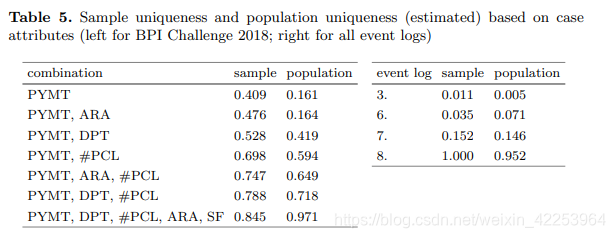
No todos los registros de eventos muestran un alto grado de exclusividad en función de los atributos del caso. En el caso del registro de eventos del BPI Challenge 2018, se puede observarIncluso unos pocos atributos de caso tendrán una gran singularidad, lo que conlleva un alto riesgo de reidentificación.。
El registro de eventos de sepsis se obtuvo del sistema de información de un hospital holandés. Contiene eventos relacionados con la logística y el tratamiento de los pacientes que ingresan a la sala de emergencias y se sospecha que tienen sepsis, que es una afección potencialmente mortal que requiere tratamiento inmediato. Inicialmente, el registro de eventos se analizó para comprender si se siguieron las pautas para el uso oportuno de antibióticos y, de manera más general, se relacionó con la trayectoria general del paciente [32]. Con fines de investigación, estos datos se han puesto a disposición del público [11].
Se han tomado varias medidas para evitar la identificación, que incluyen:
- Aleatorice la marca de tiempo alterando el comienzo del caso y ajustando la marca de tiempo de cada evento posterior en consecuencia
- Un seudónimo para actividades relacionadas con la asistencia, como "problema A"
- Resuma la información de los empleados explicando solo el departamento
- Seudonimización del diagnóstico laboral
- Extienda la edad a personas menores de 5 años y al menos a 10 personas.
El registro de eventos contiene 1.049 casos que involucran 16 actividades diferentes. Cada caso representa la forma en que una persona física pasa por el hospital. La longitud media de la traza es de 14 puntos (mínimo = 3, máximo = 185). A diferencia del registro de eventos del BPI Challenge 2018, el registro de eventos de sepsis solo tiene un atributo que se puede usar como atributo de caso.
Para estimar la unicidad de la trayectoria, utilizamos el método introducido en la Sección 3.2. Los puntos en el registro de eventos de sepsis incluyen actividades actuales a cargo del tratamiento del paciente, marcas de tiempo y departamentos. "Edad" se utiliza como atributo de caso. Dado que los pacientes reciben tratamiento en diferentes departamentos, el "departamento" no cumple con los criterios invariantes en el tiempo para los atributos del caso (ver sección 2).
Para cada caso, seleccionamos aleatoriamente m puntos de la traza y contamos el número de trazas con el mismo punto. En otras palabras, buscaremos otros rastros, como las mismas actividades que incluyen el mismo departamento. Elegimos puntos seleccionados al azar para evitar hacer suposiciones sobre el conocimiento del oponente. Sabemos que esto puede subestimar el riesgo de reidentificación. Como resultado, el alto grado de singularidad de nuestros resultados enfatiza el riesgo de reidentificación, porque una selección de puntos más compleja y optimizada puede conducir a una mayor singularidad. En la Figura 1, mostramos la singularidad de los diferentes valores de m puntos y las trazas de diferentes proyecciones. Como era de esperar, solemos observar que más puntos conducen a una mayor singularidad. Suponiendo que la marca de tiempo es correcta (no correcta), la proyección A muestra que cuatro puntos, incluida la actividad y la marca de tiempo, son suficientes para identificar todos los rastros. Al resumir la marca de tiempo, es decir, reducir la resolución a unos pocos días, al considerar cuatro puntos, solo el 31% de los trazos son únicos, y al considerar todos los puntos del trazo, solo el 70% son únicos. Por tanto, los resultados muestran claramente el impacto de la inducción en la reidentificación de riesgos.
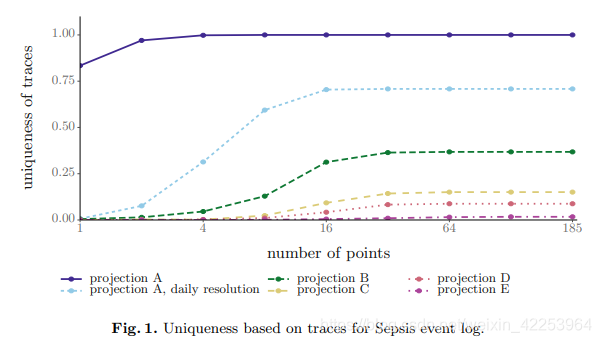
Al considerar otras proyecciones, el efecto de mejora de la privacidad de eliminar valores del registro de eventos se vuelve obvio. Por ejemplo, la proyección B omite la marca de tiempo, pero en otros casos asume que el oponente tiene conocimientos previos de todas las actividades, casos y atributos de eventos. Sin embargo, puede limitar significativamente la unicidad a aproximadamente el 37%. La proyección D, que todavía contiene atributos y actividades de casos, puede incluso limitar la unicidad de la traza a un máximo del 9%. La unicidad de la traza se mantiene estable más allá de los 64 puntos, porque solo el 2% de las trazas tiene más de 64 puntos.
Nuestro método de estimación de la unicidad basado en el seguimiento se puede aplicar a todos los registros de eventos clasificados como "personas en la vida real (R)". La Figura 2 muestra la singularidad de todos los registros de eventos para diferentes proyecciones. Damos 10%, 50% y 90% de puntos posibles por cada trazo, es decir, el oponente conoce este punto en cada caso para evaluar la unicidad. Un campo gris sin un número indica que la proyección no se puede evaluar debido a la falta de atributos.
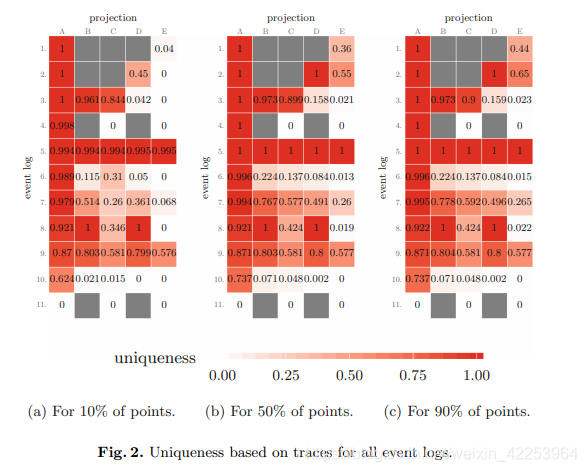
En la Figura 2, observamos una tendencia similar al registro de eventos de sepsis:La proyección A generalmente da como resultado una gran singularidad. Al omitir la información representada por varias proyecciones, se reduce la unicidad. Al comparar las proyecciones B y C, el atributo de situación se eliminará, lo que se vuelve obvio.Proyección E, que solo considera actividades, resultando en una pequeña singularidad, Excepto por los registros de eventos 5 y 9. Explicamos por el hecho de que estos registros de eventos tienen muchas actividades diferentes y la longitud de la traza es diferente en cada caso. Para el registro de eventos 10, hemos visto que la singularidad de la proyección B se reduce significativamente. Esto puede explicarse por una pequeña cantidad de atributos de casos y una pequeña cantidad de actividades únicas.
El registro de eventos más sorprendente es el 11. No tiene una situación única. La razón principal de esta diferencia es la marca de tiempo y una pequeña cantidad de actividades únicas en la solución diaria. Vale la pena agregar que, en comparación con la singularidad, aumentar el número de puntos del 10% al 50% tiene sentido en relación con aumentar el número de puntos del 50% al 90%. Por ejemplo, la unicidad de la proyección A del registro de eventos 10 aumenta del 62,4% en la Fig. 2a al 73,7% en la Fig. 2b. Dado el punto del 90% de la trayectoria, no podemos observar un aumento en la unicidad del registro de eventos 10. También se puede observar para otros registros de eventos y otras proyecciones. La razón principal es que la longitud de la traza varía mucho.
En general, en nuestra investigación, encontramos que la unicidad basada en los rastros es mayor que la unicidad basada en los atributos del caso (consulte los resultados en la Tabla 5). Por ejemplo, el registro de eventos 3 tiene una unicidad de muestra del 1,1% según el atributo case. Sin embargo, según la trayectoria, para la proyección C, su singularidad de caso es 84,4%.Concluimos que las trayectorias son particularmente vulnerables a los ataques de reidentificación de datos.。
discutir
Nuestros resultados muestran que incluso para los puntos de seguimiento seleccionados al azar, 11 de los 12 registros de eventos evaluados son únicamente superiores al 62%. La información más específica, como la secuencia de actividades individuales, puede aportar mayor singularidad con menos puntos. Los atacantes generalmente pueden usar otros conocimientos sobre el proceso para predecir ciertas actividades, lo que también se confirma en == [33] ==. pero,La selección aleatoria muestra claramente que un poco de conocimiento previo es suficiente y ha traído un gran riesgo de re-identificación en el registro de eventos.. a diferencia de,La generalización de atributos ayuda a reducir el riesgo [34]. Sin embargo, los resultados muestran que la combinación de múltiples atributos (como los atributos del caso y las actividades) aún produce casos únicos. La combinación con la resolución de valor reducido, por ejemplo, la publicación solo del año de nacimiento en lugar de la fecha de nacimiento completa, puede reducir el riesgo de reidentificación. Dichas técnicas de generalización (generalización) también se pueden aplicar a marcas de tiempo, actividad o atributos de casos.
Seguir el principio de minimización de datos, es decir, limitar la cantidad de datos personales. La omisión de datos es sólo la forma más profunda de reducir el riesgo. Esto lo veremos claramente cuando consideremos la proyección. Por lo tanto, estas proyecciones se pueden utilizar para reducir el riesgo de reidentificación.
Aplicamos nuestro método a los registros de eventos publicados para señalar los riesgos re-identificados en el área de minería de procesos. Para tal fin,Solo cuantificamos riesgo, Evite correlacionar otros registros de eventos, de lo contrario, la persona podría volver a identificarse. Adicionalmente,Hemos tomado algunas medidas durante el proceso de evaluación, como pseudonimizar los registros de eventos, para no exponer o atribuir registros de eventos específicos.。
Trabajo relacionado
Vuelva a identificar el ataque. En el pasado, muchos investigadores han resuelto y llevado a cabo con éxito ataques de reidentificación [6,7,12,13,35,36]. Narayanan y Shmatikov [35] anonimizaron el conjunto de datos que contiene clasificaciones de películas de Netflix mediante la correlación cruzada de múltiples conjuntos de datos.El objetivo de nuestro oponente es volver a identificar a una persona, no reconstruir todos los valores de los atributos de una persona. Por lo tanto, medimos la singularidad. Medimos la unicidad con base en dos métodos bien conocidos [7,12,13].
Rocher y col. [7] Estime la unicidad general basada en el valor del atributo dado. Usamos su método para estimar la unicidad en función de los atributos del caso. Nuestro método basado en la unicidad de la estimación de la trayectoria se basa en el método propuesto en [12, 13], que estima la unicidad en la trayectoria en movimiento con datos de posición. Debido a la estructura del registro de eventos, estos dos métodos por sí solos no son suficientes para determinar la unicidad del registro de eventos y se requiere la preparación de datos. Por ejemplo, el registro de eventos tiene un formato específico que debe convertirse para aplicar una medida de unicidad al seguimiento.
Privacidad en minería de procesos . Especialmente desde que entró en vigor el Reglamento General de Protección de Datos (RGPD), ha aumentado la conciencia sobre los problemas de privacidad en la minería de procesos [37]. Aunque el manifiesto de minería de procesos [38] requiere equilibrar la utilidad y la privacidad de las aplicaciones de minería de procesos, el número de contribuciones relacionadas es todavía pequeño. Fahrenkrog-Petersen et al.han resuelto el problema de descubrir el comportamiento correcto del proceso principal mientras se preserva la privacidad en el registro de eventos. [4]. Su algoritmo garantiza k-anonimato y t-compactibilidad, mientras maximiza la utilidad del registro de eventos limpio. Generalmente, el k-anonimato agrega datos de tal manera que no todos pueden distinguirse de al menos k-1 otros en el conjunto de datos en función de su valor [39,40]. Sin embargo, se ha demostrado en el pasado que ni k el anonimato ni t la compacidad son suficientes para proporcionar sólidas garantías de privacidad [41].
Hasta la fecha, el modelo de privacidad más poderoso que puede proporcionar garantías de privacidad demostrables es la privacidad diferencial. Recientemente, se incorporó a la primera tecnología de protección de la privacidad para la minería de procesos [2]. Este método propone un motor de privacidad que puede mantener la privacidad de los datos personales agregando ruido a la consulta. Las técnicas de privacidad de [2,4] se han combinado en herramientas basadas en web [3]. La seudonimización de conjuntos de datos relacionados con la minería de procesos se ha discutido en [42,43]. Los valores del conjunto de datos original se reemplazan por alias. Sin embargo, el cifrado aún permite a los adversarios potencialmente volver a identificarse con el conocimiento sobre el dominio y la distribución estadística de los datos cifrados. Además de los desafíos técnicos de privacidad para la minería de procesos, el método de [44] también analiza los desafíos de privacidad organizacional a través de un marco. Aunque este método señala algunos problemas de privacidad en la minería de procesos, no proporciona ninguna solución técnica. Recogida, etc. [33] Evaluar la idoneidad de los métodos de protección de la privacidad existentes para procesar datos de minería. Propusieron un marco para apoyar la minería y el análisis del proceso de protección de la privacidad. Y camionetas y demás. Aunque se analiza la aplicabilidad de los métodos de conversión de datos existentes para el procesamiento anónimo de datos de proceso,No proporcionan métodos para respaldar la información de identificación (como comportamientos de proceso atípicos) y deben suprimirse para reducir el riesgo de reidentificación del sujeto. Nuestras métricas llenan este vacío y ayudan a los propietarios de datos a identificar casos únicos con un comportamiento de proceso atípico.。
En comparación con el trabajo existente relacionado con los métodos de percepción de la privacidad para la minería de procesos, este artículo intenta cuantificar el riesgo de reidentificación. Los editores de datos pueden determinar qué información debe suprimirse antes de publicar registros de eventos para la minería de procesos. Si el riesgo de reidentificación es alto, los métodos anteriores pueden reducir el riesgo de reidentificación, proporcionando así una mayor garantía de privacidad.
En conclusión
Este documento identifica y evalúa el riesgo de reidentificación para la minería de procesos en el registro de eventos. Encontramos en la comunidadHay graves fugas de privacidad en la mayoría de los registros de eventos más utilizados. Para resolver este problema, recomendamos el uso de métodos para estimar la singularidad, de modo que los editores de registros de eventos puedan evaluar cuidadosamente sus registros de eventos antes de publicarlos y si es necesario suprimir cierta información.. En general, el seguimiento de datos del mundo real es un medio necesario para evaluar y comparar algoritmos. Este artículo muestra que, como comunidad,Debemos tomar acciones más cautelosas al publicar registros de eventos y, al mismo tiempo, enfatizar la necesidad de desarrollar tecnología de protección de privacidad para registros de eventos.. Creemos que este trabajo aumentará la confianza y aumentará la voluntad de compartir registros de eventos mientras brinda garantía de privacidad.