Dirección de tesis: https://arxiv.org/abs/1906.00592
Autor: Baosong Yang, Longyue Wang, Derek F. Wong, Lidia S. Chao, Zhaopeng Tu
Organización: Tencent AI lab
Problemas de investigación:
En redes similares a RNN, el modelado de secuencia se utiliza para representar información de ubicación. En la red de red de auto atención (SAN), la capacidad de aprender información de ubicación es débil. Lo que hace este artículo es proponer una tarea de detección de reordenamiento de palabras para cuantificar la información de posición de aprendizaje de san y RNN. Específicamente, es mover aleatoriamente una palabra a otra posición para ver si un modelo entrenado puede detectar la posición original y la posición de inserción al mismo tiempo.
Métodos de investigación:
Tarea de detección de reordenamiento de palabras:
La descripción es la siguiente: dada una oración X, inserte aleatoriamente una palabra en otra posición, el propósito de la tarea es detectar qué palabra se selecciona y dónde se inserta. El resultado del modelo incluye dos marcas "I" O ". Esa es una tarea de detección de puntero. Como se muestra a continuación.
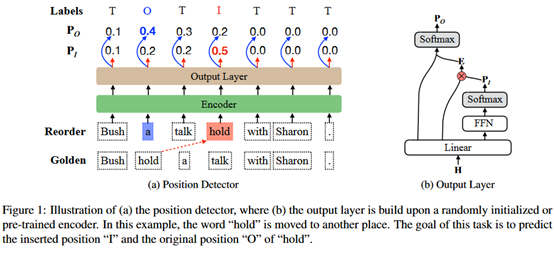
En el proceso de entrenamiento, el objetivo del entrenamiento es minimizar la entropía cruzada de la posición de inserción verdadera y la posición original.
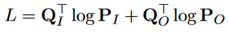
Q_I y Q_O aquí son vectores únicos.
Parte experimental:
Modelo: use tres modelos: RNN, SAN y DiSAN
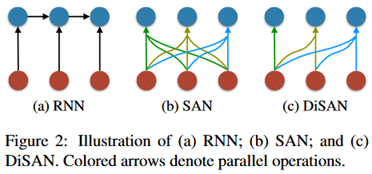
Objetivo de aprendizaje: usar dos estrategias para entrenar el codificador, y la capa de salida es la tarea de detección de reordenamiento de palabras anterior.
Estrategia 1: Use directamente los datos de la tarea de detección de reordenamiento de palabras para entrenar el codificador, entrenarlo junto con la capa de salida y usar la precisión de detección como objetivo de aprendizaje.
Estrategia 2: Tome la traducción automática como objetivo de aprendizaje, primero entrene un modelo NMT, incluyendo codificador y decodificador, y luego entrene solo los parámetros relacionados con la capa de salida en la tarea de detección de reordenamiento de palabras.
Los resultados experimentales son los siguientes:
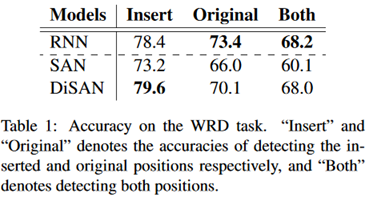
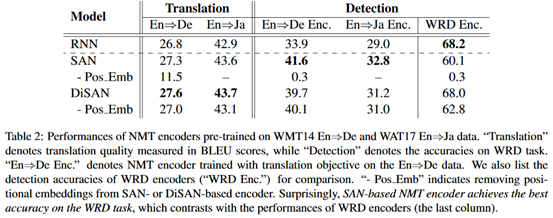
Conclusión
(1) La representación de SAN en esta tarea no es tan buena como RNN, pero no es cierta en la traducción automática.
(2) En las tareas posteriores (como la traducción), el objetivo de aprendizaje es más importante que la estructura del modelo.
(3) En la traducción automática, la codificación de posición es lo suficientemente buena para SAN. DiSAN es un mecanismo para que SAN aprenda información de orden de palabras de manera más efectiva.
Por qué en la traducción automática, SAN funciona mejor. El autor cree que SAN retiene más información sobre el orden de las palabras para compensar sus deficiencias en la estructura paralela, contribuyendo así a una codificación más profunda. El autor agregó un experimento.
Básicamente, todos pueden entender el significado de una oración como "Estudiar la tabla y dejar en claro que el orden de los caracteres chinos no necesariamente puede leer y leer". ¿Puede la máquina entenderlo? El autor utilizó el modelo de traducción después de codificar las oraciones. Los resultados son los siguientes:
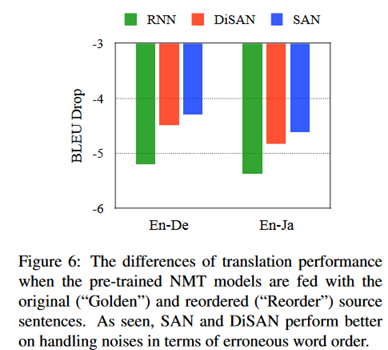
Se puede ver que, en comparación con RNN, la reducción en la calidad de traducción de SAN y DiSAN es menor, lo que indica la efectividad de la auto atención para eliminar el ruido del orden incorrecto.
Evaluación:
Investigue la capacidad de modelado de RNN y la red de auto atención para obtener información de ubicación a través de la tarea de identificar tokens codificados. El experimento en sí es relativamente simple, pero el experimento del autor combinado con escenarios de aplicación específicos (traducción automática) ha llegado a algunas conclusiones nuevas. Sin embargo, aquí solo se discute la traducción automática, y no se menciona si es una conclusión similar en otras tareas de PNL. 3 puntos