El módulo Spark SQL es principalmente para tratar algunos contenidos relacionados con el análisis de SQL. En términos más generales, es cómo analizar una declaración SQL en una tarea de marco de datos o RDD. Tomando Spark 2.4.3 como ejemplo, el módulo grande de Spark SQL se divide en tres submódulos, como se muestra a continuación
Entre ellos, se puede decir que Catalyst es un marco dedicado a analizar SQL dentro de Spark. Un marco similar en Hive es Calcite (analizar SQL en tareas MapReduce). Catalyst divide la tarea de análisis de SQL en varias etapas. Esto se describe más claramente en el documento correspondiente. Gran parte del contenido de esta serie también se referirá al documento. Aquellos interesados en leer el documento original pueden ir aquí: Spark SQL: Procesamiento de datos relacionales en Spark .
El módulo Core es en realidad el proceso de análisis principal de Spark SQL. Por supuesto, se llamará a algún contenido de Catalyst en este proceso. Las clases más utilizadas en este módulo incluyen SparkSession, DataSet, etc.
En cuanto al módulo de la colmena, no hace falta decir que debe estar relacionado con la colmena. Este módulo básicamente no está involucrado en esta serie, por lo que no lo presentaré mucho.
Vale la pena mencionar que cuando se publicó el documento, todavía estaba en la etapa Spark1.x. En ese momento, el SQL se analizó en un árbol léxico utilizando una herramienta de análisis escrita en scala. En la etapa 2.x, antlr4 se utilizó para hacer esta parte Debería ser el mayor cambio). En cuanto a por qué debería cambiarse, supongo que se debe a la legibilidad y la facilidad de uso, por supuesto, esto es solo una suposición personal.
Además, esta serie presentará brevemente el flujo de procesamiento de una instrucción SQL, basada en spark 2.4.3 (el módulo sql no ha cambiado mucho después de spark2.1). Este artículo presenta primero los antecedentes y la resolución de problemas de Spark SQL en su conjunto, cuál es el proceso de Dataframe API y Catalyst, y luego detalla el proceso de Catalyst en etapas.
Los antecedentes y problemas de Spark SQL
En los primeros tiempos, la tecnología para el procesamiento de datos a gran escala era MapReduce, pero la eficiencia de implementación de este marco era demasiado lenta, y algunos procesamientos relacionales (como unir) requerían escribir mucho código. Más tarde, el marco como la colmena permite a los usuarios ingresar sentencias sql, optimizarlas y ejecutarlas automáticamente.
Sin embargo, en sistemas grandes, todavía hay dos problemas principales: uno es que las operaciones de ETL deben interactuar con múltiples fuentes de datos. La otra es que los usuarios necesitan realizar análisis complejos, como el aprendizaje automático y el cálculo de gráficos. Pero es más difícil de realizar en el sistema tradicional de procesamiento relacional.
Spark SQL proporciona dos submódulos para resolver este problema, DataFrame API y Catalyst .
En comparación con RDD, la API de Dataframe proporciona una API relacional más rica y se puede convertir con RDD, y el enfoque del aprendizaje automático de Spark más tarde, también se transfiere de mllib basado en RDD a Spark ML basado en Dataframe ( Aunque la parte inferior del Dataframe también es RDD).
El otro es Catalyst, a través del cual puede agregar fácilmente fuentes de datos (como json o tipos personalizados a través de la clase de caso) a dominios como el aprendizaje automático y optimizar reglas y tipos de datos.
A través de estos dos módulos, Spark SQL logra principalmente los siguientes objetivos:
- Proporcione una API fácil de usar y buena, incluida la lectura de fuentes de datos externas y el procesamiento de datos relacionales (todos los que lo han usado lo saben)
- Use la tecnología DBMS establecida para proporcionar un alto rendimiento.
- Admite fácilmente nuevas fuentes de datos, incluidos datos semiestructurados y bases de datos externas (como MYSQL).
- Expansión en computación gráfica y aprendizaje automático
Luego, introduzca el proceso de Dataframe y Catalyst, por supuesto, la discusión principal es Catalyst.
Marco de datos API unificado
Primero mire una imagen provista en el documento:
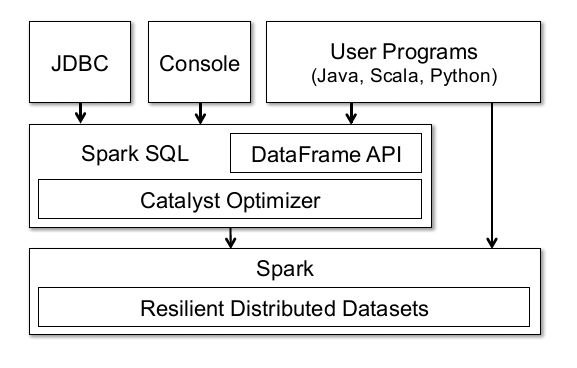
Esta imagen puede explicar mucho, en primer lugar, la capa inferior de la API Dataframe de Spark también se basa en el RDD de Spark. Pero la diferencia con RDD es que Dataframe mantendrá el esquema (esto es realmente difícil de traducir, puede entenderse como la estructura de los datos) y puede realizar una variedad de operaciones relacionales , como Seleccionar, Filtrar, Unir, Agrupar, etc. Desde un punto de vista operativo, es similar al marco de datos de pandas (incluso el nombre es el mismo).
Al mismo tiempo, debido a que se basa en RDD, hay muchas características de RDD que Dataframe puede disfrutar, como la coherencia informática distribuida, la garantía de confiabilidad y puede almacenar datos en caché a través de caché para mejorar el rendimiento informático, etc.
Al mismo tiempo, la página en la figura muestra que el Dataframe se puede conectar a una base de datos externa a través de JDBC, mediante la operación de la consola (spark-shell) o el programa de usuario. Para decirlo sin rodeos, el marco de datos puede convertirse mediante RDD o generarse mediante una tabla de datos externa .
Por cierto, por cierto, muchos zapatos para niños que están expuestos a Spark SQL por primera vez pueden estar confundidos sobre las dos cosas Dataset y Dataframe. En la era 1.x, de hecho son algo diferentes, pero en spark2.x, estas dos API Ha sido unificado. Básicamente, Dataset y Dataframe pueden considerarse equivalentes .
Finalmente, hagamos una presentación práctica en combinación con el código. A continuación se muestra la generación de un RDD, y el correspondiente Dataframe se genera de acuerdo con este RDD, desde el cual puede ver la diferencia entre RDD y Dataframe:
//生成RDD
scala> val data = sc.parallelize(Array((1,2),(3,4)))
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:24
scala> data.foreach(println)
(1,2)
(3,4)
scala> val df = data.toDF("fir","sec")
df: org.apache.spark.sql.DataFrame = [fir: int, sec: int]
scala> df.show()
+---+---+
|fir|sec|
+---+---+
| 1| 2|
| 3| 4|
+---+---+
//跟RDD相比,多了schema
scala> df.printSchema()
root
|-- fir: integer (nullable = false)
|-- sec: integer (nullable = false)
Análisis de flujo de catalizador
Catalyst se llama Optimizer en el documento. Esta parte es el contenido principal del documento, pero el proceso en realidad es bastante fácil de entender. La imagen en el documento todavía está publicada.
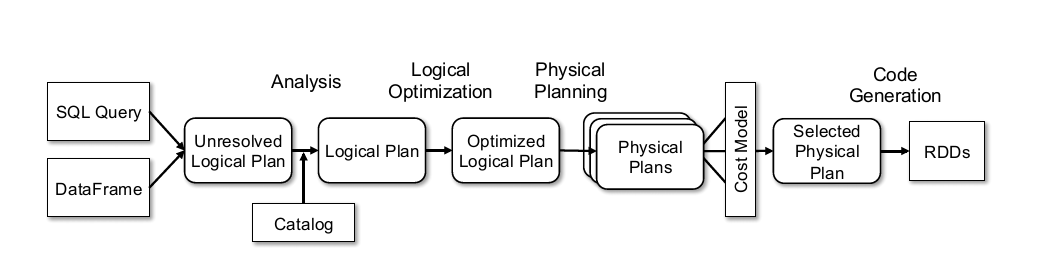
El proceso principal se puede dividir aproximadamente en los siguientes pasos:
- Antlr4 analiza la declaración SQL para generar un plan lógico no resuelto (los zapatos de niños que hayan usado Antlr4 deben estar familiarizados con este proceso)
- El analizador y el catálogo están vinculados (catlog almacena metadatos) para generar el Plan lógico;
- optimizador optimiza el plan lógico y genera un plan lógico optimizado;
- SparkPlan convierte Optimized LogicalPlan en Plan físico;
- prepareForExecution () convierte el plan físico en un plan físico ejecutado;
- execute () ejecuta el plan físico ejecutable y obtiene el RDD;
Permítanme hablar sobre esto con anticipación. La mayoría de los procesos anteriores se encuentran en la clase org.apache.spark.sql.execution.QueryExecution. Esta publicación es un código simple, solo mírelo, simplemente no haga más. Los artículos posteriores detallarán los contenidos aquí.
class QueryExecution(val sparkSession: SparkSession, val logical: LogicalPlan) {
......其他代码
//analyzer阶段
lazy val analyzed: LogicalPlan = {
SparkSession.setActiveSession(sparkSession)
sparkSession.sessionState.analyzer.executeAndCheck(logical)
}
//optimizer阶段
lazy val optimizedPlan: LogicalPlan = sparkSession.sessionState.optimizer.execute(withCachedData)
//SparkPlan阶段
lazy val sparkPlan: SparkPlan = {
SparkSession.setActiveSession(sparkSession)
// TODO: We use next(), i.e. take the first plan returned by the planner, here for now,
// but we will implement to choose the best plan.
planner.plan(ReturnAnswer(optimizedPlan)).next()
}
//prepareForExecution阶段
// executedPlan should not be used to initialize any SparkPlan. It should be
// only used for execution.
lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
//execute阶段
/** Internal version of the RDD. Avoids copies and has no schema */
lazy val toRdd: RDD[InternalRow] = executedPlan.execute()
......其他代码
}
Vale la pena mencionar que cada etapa utiliza la carga diferida perezosa. Si está interesado en esto, puede consultar mi artículo anterior Scala Functional Programming (6) Lazy Loading and Stream .
Lo anterior presenta principalmente los contenidos del módulo Spark SQL, sus antecedentes y sus principales problemas. Luego, presente brevemente el contenido de la API de Dataframe y el marco interno de Spark SQL que analiza SQL Catalyst. El seguimiento presentará principalmente el proceso de cada paso en Catalyst, y realizará algunos análisis en combinación con el código fuente.
Arriba ~