Función de densidad de probabilidad (PDF)
Tome la función de densidad de probabilidad (PDF) de la distribución gaussiana como ejemplo,
\ (f (x) = \ frac {1} {\ sigma \ sqrt {2 \ pi}} e ^ {- \ frac {1} {2} \ left (\ frac {x- \ mu} {\ sigma} \ right) ^ 2} \)
Después de determinar el valor esperado \ (\ mu \) y la varianza \ (\ sigma \) , \ (f (x) \) es la función PDF de \ (x \) . Más generalmente, \ (f (x) \) puede considerarse como una función de \ (x \) y \ (\ theta (\ mu, \ sigma) \) ,
\ (f (x; \ theta) = \ frac { 1} {\ sigma \ sqrt {2 \ pi}} e ^ {- \ frac {1} {2} \ left (\ frac {x- \ mu} {\ sigma} \ right) ^ 2} \)
Estimación de máxima verosimilitud
Ahora conocido conjunto de datos \ (X = \ {x_0, x_1, x_2, ... \} \) , por lo que la demanda \ (f (x) \) maximiza parámetro \ (\ Theta \) , en este momento \ ( f (x; \ theta) \) es una función de los parámetros del modelo \ (\ theta \) ,
\ (f (\ theta) = \ frac {1} {\ sigma \ sqrt {2 \ pi}} e ^ {- \ frac {1} {2} \ left (\ frac {x- \ mu} {\ sigma} \ right) ^ 2} \)
Entre todos los valores posibles de \ (\ theta \) , la solución de estimación de máxima verosimilitud hace \ (f (\ theta) \) Valor de parámetro maximizado \ (\ hat {\ theta} \)
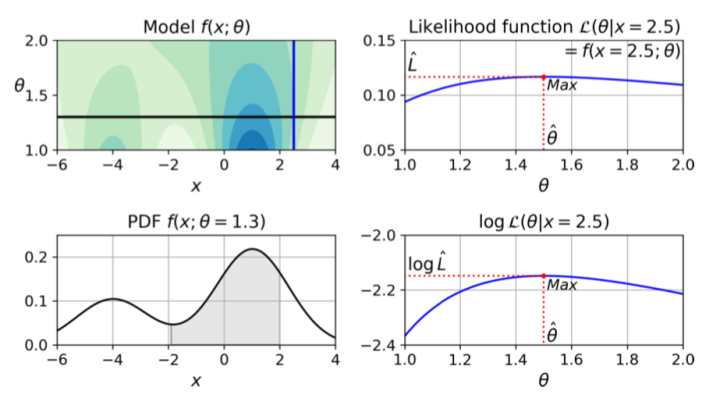
Resuma con una imagen en el libro de Dios Aurélien: