Hola a todos, este es el primero de nuestra serie xgboost. xgboost [1] es un algoritmo que se solicitó durante la entrevista de aprendizaje automático.
Primero, analicemos una cosa para comprender el núcleo de xgboost. Ese es el modelo matemático de xgboost. Si quieres entenderlo, no puedes omitir estas matemáticas.
xgboost se basa en el concepto de levantar árboles. Esta idea significa que aprender un árbol puede tener un efecto pobre, porque un árbol es relativamente inestable. Después de eliminar ciertas características o muestras, la estructura del árbol de reentrenamiento cambiará, lo que lleva a la predicción Los resultados son inestables.
Para hacer que el modelo sea más robusto (el resultado es más estable), podemos entrenar un árbol y luego ver dónde el árbol no está bien entrenado, es decir, la brecha con el objetivo. Luego construya otro árbol para que se ajuste a estas brechas. Esta es la idea
del método de impulso , xgbosot es un tipo de método de impulso.
A continuación, hablaré sobre las características generales de los algoritmos de ciencia de datos: un algoritmo debe conocer primero su función objetivo, luego ver si hay regularización y luego ver los medios de optimización, es decir, cómo minimizar la función objetivo.
Primero, la función objetivo optimizada
Primero, la función objetivo (función de pérdida) de xgboost es la siguiente: el
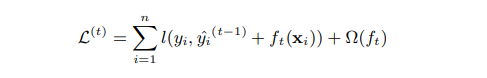
lado izquierdo de la ecuación es la función de pérdida en el tiempo t, y el pequeño l en el lado representa la pérdida de cada muestra, yn representa el número de muestras.
Hay dos ítems en el l pequeño, el primer ítem es:
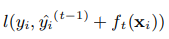
esta es la pérdida que necesita ser optimizada, el valor predicho de xgboost es el valor predicho del paso t-th y todos los valores pronosticados del árbol t-1 como el valor predicho. Para cada muestra, cada árbol se asignará a un nodo hoja. Agregar los nodos de hoja de este árbol t es la predicción en el paso t del árbol.
Esperamos que la diferencia entre la predicción y el valor real sea pequeña, por ejemplo, mse puede seleccionarse como la función de pérdida.
El segundo elemento es:
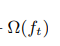
Este es un elemento normal. La t en la fórmula representa el árbol t-th, es decir, esto se hace para cada árbol.
En segundo lugar, la verdadera cara de los elementos regulares
Cuando entré en contacto con xgboost por primera vez, me siento muy ganadora. El árbol no tiene parámetros obvios como LR o redes neuronales. ¿Cómo hacer la regularización?
La esencia de la regularización es reducir la complejidad del árbol, que se puede expresar por la profundidad del árbol y el número de nodos de las hojas.
xgboost también usa una idea similar. La fórmula de regularización de un árbol de xgboost es la siguiente: el
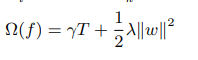
primer término T en el lado derecho de la ecuación representa el número de nodos de hoja. El segundo elemento w se parece a los parámetros de la red neuronal. De hecho, podemos usar el valor del nodo hoja del árbol como el objetivo de la optimización del árbol. Este es el valor de cada nodo hoja. Los coeficientes en ambos lados son parámetros.
3. ¿Cómo minimizar la función objetivo?
Todos hemos aprendido la expansión de Taylor en grandes números, y xgboost también usó el ejemplo de la expansión de Taylor. Si estamos
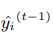
expandiendo la función de pérdida de acuerdo con la fórmula de Taylor de segundo orden, la función de pérdida se convierte en:
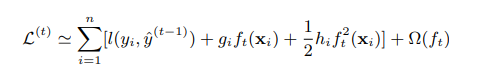
gi es
la primera derivada en, hi es el segundo recíproco.
Después de eliminar la constante, la función de pérdida es:
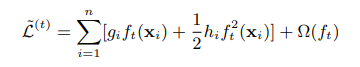
Si Ij se define como el nodo hoja j-ésimo, la fórmula es:
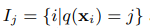
i significa la muestra i-ésimo, y q es una función de mapeo, lo que significa que Xi se asigna al nodo j-ésimo.
Vuelva a escribir la función de pérdida de la siguiente manera:
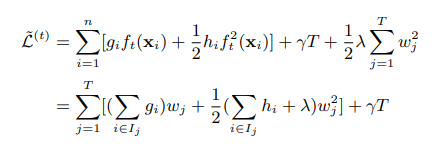
Solicitamos extremum, necesitamos parámetros necesarios son w, es decir, el valor del nodo hoja, la segunda línea de derivación directa puede ser igual a 0 para dar:
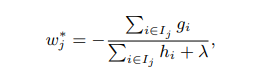 '
'
Trae wj a la fórmula para la función de pérdida anterior:
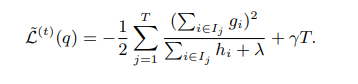
Cuarto, la medición del punto de división
En la tercera sección, sabemos cómo asignar el valor del nodo hoja para minimizar la función de pérdida cuando conocemos la estructura del árbol. Este resumen describe cómo xgboost mide el punto de división. El árbol de decisión puede ser ganancia de información, índice de Gini, etc. xgboost tiene un método de medición similar.
xgboost es un árbol binario, es decir, a partir del nodo raíz, se dividen dos tenedores. Su método de cálculo es dividir un árbol y luego calcular el valor de la reducción de la función de pérdida. Qué método de división cuanto más se reduce la función de pérdida, se selecciona el método. La fórmula de cálculo es la siguiente:
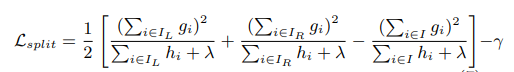
Esta fórmula es restar la pérdida actual La pérdida de los nodos izquierdo y derecho.
Resumen: describimos la función objetivo xgboost, la regularización, cómo optimizar la función objetivo y la medición del punto de división. La siguiente sección describirá el método de división del árbol.
Referencias
[1] https://www.kdd.org/kdd2016/papers/files/rfp0697-chenAemb.pdf
