Algoritmo de clasificación
En el desarrollo de los seres humanos, hemos aprendido a contar, por ejemplo, sabemos cuántos conejos ha cazado hoy Xiaoming. Por otro lado, también necesitamos juzgar cuál está cazando más hoy, y tenemos que comparar.
Entonces, surgió la necesidad natural de clasificar. Por ejemplo, Xiao Ming golpeó a 5 conejos, Xiao Wang golpeó a 8 y había más de cien personas de la tribu. Tenemos que hablar de recompensas de mérito, quien juega más, las recompensa más grandes.
Cómo ordenar, cómo encontrar a la persona que golpea más conejos en el tiempo más rápido, esta es una pregunta muy simple.
Después de muchos años de investigación, han aparecido muchos algoritmos de clasificación, que van de rápido a lento. Por ejemplo:
- Tipo de inserción: tipo de inserción directa y tipo Hill
- Selección de clasificación: clasificación de selección directa y clasificación de montón
- Tipo de intercambio: tipo burbuja y tipo rápido
Su complejidad es la siguiente:
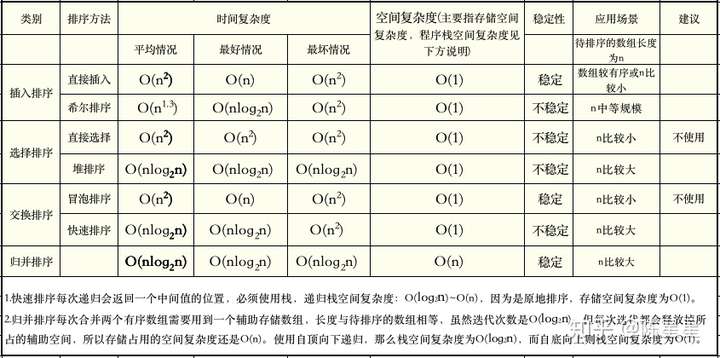
Concepto de estabilidad
Definición: Puede garantizar dos números iguales. Después de la clasificación, el orden de las posiciones antes y después de la secuencia permanece sin cambios. (A1 = A2, A1 está delante de A2 antes de ordenar, y A1 todavía está delante de A2 después de ordenar)
Importancia: La esencia de la estabilidad es mantener el orden de inserción de datos con los mismos atributos. Evita ordenar esta vez.
La clasificación de burbujas es posiblemente el peor algoritmo de clasificación.
Consideramos el ordenamiento de burbujas, el de selección directa y el de inserción directa como el algoritmo de ordenación principal. El rendimiento del ordenamiento de inserción directa es el mejor. En términos generales, cuando la matriz de ordenación es npequeña, el ordenamiento de inserción directa puede ser mejor que cualquier ordenación. El algoritmo debe ser rápido, se recomienda usarlo solo en la clasificación a pequeña escala.
La ordenación en pendiente es una versión mejorada de la ordenación por inserción directa, que es más rápida que la ordenación por selección directa y la ordenación por inserción directa, y esta mejora del rendimiento se hace más evidente a medida que aumenta la escala. Debido a que el algoritmo es fácil de entender, podemos usarlo cuando la matriz ordenada es de tamaño mediano. A una escala muy grande, su rendimiento no es tan malo, pero se recomienda el siguiente algoritmo de clasificación avanzado para la clasificación a gran escala.
La clasificación rápida, la combinación de clasificación y la clasificación de montón son algoritmos de clasificación más avanzados.
En la actualidad, se considera que el mejor algoritmo de clasificación avanzado integral es la clasificación rápida. El tiempo promedio para la clasificación rápida es el más corto, y es el algoritmo de clasificación integrado en la mayoría de las bibliotecas de programación.
La ordenación en montón también es un algoritmo de ordenación rápida. Al mantener un árbol binario, el nodo raíz del árbol es siempre el más grande o el más pequeño para lograr la ordenación.
La ordenación por fusión utiliza el método de dividir y conquistar al igual que la ordenación rápida, ordenando recursivamente cada subsecuencia primero y luego fusionando las dos secuencias ordenadas en una secuencia ordenada.
Explicaremos diferentes algoritmos de clasificación en este capítulo.
Entrada de artículo de serie
Soy la estrella Chen, bienvenido he escrito personalmente estructuras de datos y algoritmos (Golang lograr) , comenzando en el artículo para leer más amigable GitBook .
- Estructura de datos y algoritmo (implementación de Golang) (1) Una introducción simple a Golang-Prefacio
- Estructuras de datos y algoritmos (implementación de Golang) (2) Una introducción simple a los paquetes, variables y funciones de Golang
- Estructura de datos y algoritmo (implementación de Golang) (3) Una introducción simple a la declaración de control de flujo de Golang
- Estructuras de datos y algoritmos (implementación de Golang) (4) Una introducción simple a las estructuras y métodos de Golang
- Estructura de datos y algoritmo (implementación de Golang) (5) Una introducción simple a la interfaz de Golang
- Estructura de datos y algoritmo (implementación de Golang) (6) Una introducción simple a la concurrencia, las rutinas y los canales de Golang
- Estructura de datos y algoritmo (implementación de Golang) (7) Una introducción simple a la biblioteca estándar de Golang
- Estructura de datos y algoritmo (implementación de Golang) (8.1) Conocimientos básicos-Prefacio
- Estructura de datos y algoritmo (implementación de Golang) (8.2) Conocimiento básico: dividir y conquistar y recurrir
- Estructura y algoritmo de datos (implementación de Golang) (9) Complejidad del algoritmo de conocimiento básico y símbolo progresivo
- Estructura de datos y algoritmo (implementación de Golang) (10) Conocimientos básicos: el método principal de complejidad del algoritmo
- Estructuras de datos y algoritmos (implementación de Golang) (11) Estructuras de datos comunes-Prefacio
- Estructuras de datos y algoritmos (implementación de Golang) (12) Listas enlazadas de estructuras de datos comunes
- Estructuras de datos y algoritmos (implementación de Golang) (13) Estructuras de datos comunes: matrices de longitud variable
- Estructuras de datos y algoritmos (implementación de Golang) (14) Estructuras de datos comunes: pila y cola
- Estructuras de datos y algoritmos (implementación de Golang) (15) Lista de estructuras de datos comunes
- Estructuras de datos y algoritmos (implementación de Golang) (16) Estructuras de datos comunes-Diccionario
- Estructuras de datos y algoritmos (implementación de Golang) (17) Estructuras de datos comunes: árboles
- Estructura de datos y algoritmo (implementación de Golang) (18) Algoritmo de clasificación-Prefacio
- Estructura de datos y algoritmo (implementación de Golang) (19) Algoritmo de clasificación-clasificación de burbujas
- Estructura de datos y algoritmo (implementación de Golang) (20) Clasificación de algoritmos de selección
- Estructura de datos y algoritmo (implementación de Golang) (21) Clasificación de algoritmo de inserción
- Estructura de datos y algoritmo (implementación de Golang) (22) Algoritmo de clasificación-Clasificación de Hill
- Estructura de datos y algoritmo (implementación de Golang) (23) Clasificación de algoritmo de fusión
- Estructura de datos y algoritmo (implementación de Golang) (24) Algoritmo de clasificación prioritario y clasificación de montón
- Estructura de datos y algoritmo (implementación de Golang) (25) Algoritmo de clasificación: clasificación rápida
- Estructura de datos y algoritmo (implementación de Golang) (26) Tabla de algoritmo de búsqueda de hash
- Estructura de datos y algoritmo (implementación de Golang) (27) Árbol de búsqueda binario de algoritmo de búsqueda
- Estructura y algoritmo de datos (implementación de Golang) (28) Árbol de algoritmo de búsqueda-AVL
- Estructura de datos y algoritmo (implementación de Golang) (29) Árbol de algoritmo de búsqueda-2-3 y árbol rojo-negro inclinado a la izquierda
- Estructura de datos y algoritmo (implementado por Golang) (30) Árbol de algoritmo de búsqueda-2-3-4 y árbol rojo-negro ordinario