Esta serie de blog relacionado, Mu columna de referencia de clase Java de código fuente y del sistema fabricantes entrevistador sucinta Zhenti
por debajo de esta columna es la dirección de GitHub:
Fuente resolvió: https://github.com/luanqiu/java8
artículo Demostración: HTTPS: // GitHub. com / luanqiu / java8_demo los
compañeros de clase pueden verlo si es necesario)
Análisis del código fuente de Java y preguntas-inferencia de la entrevista: la aplicación de colas en otro código fuente de Java
Además de proporcionar API para que los desarrolladores las usen, la cola de introducción también se integra estrechamente con otras API en Java, como grupos de subprocesos y bloqueos. El grupo de subprocesos utiliza directamente la API de cola. El bloqueo toma prestada la idea de la cola y vuelve a implementar la cola y el subproceso. Las agrupaciones y los bloqueos son las API que usamos a menudo en nuestro trabajo, y los entrevistadores también nos preguntan con frecuencia. Las colas juegan un papel vital en la realización de las dos. Echemos un vistazo juntos.
1 La combinación de cola y grupo de subprocesos
1.1 El papel de las colas en el grupo de subprocesos
Todos deberían haber usado el grupo de subprocesos. Por ejemplo, queremos crear un grupo de subprocesos de tamaño fijo y dejar que el subproceso en ejecución imprima una oración. Escribiremos código como este:
ExecutorService executorService = Executors.newFixedThreadPool(10);
// submit 是提交任务的意思
// Thread.currentThread() 得到当前线程
executorService.submit(() -> System.out.println(Thread.currentThread().getName() + " is run"));
// 打印结果(我们打印出了当前线程的名字):
pool-1-thread-1 is run
Los Ejecutores en el código son clases de herramientas concurrentes, principalmente para ayudarnos a construir el grupo de subprocesos más convenientemente. El método newFixedThreadPool indica que se construirá un grupo de subprocesos de tamaño fijo. El parámetro de entrada que damos es 10, lo que significa que se puede construir el grupo de subprocesos máximo 10 hilos salen.
En el trabajo real, no podemos controlar el tamaño del flujo. Aquí establecemos un máximo de 10 hilos, pero si llegan 100 solicitudes a la vez, entonces 10 hilos deben estar demasiado ocupados, entonces ¿Qué pasa con las 90 solicitudes restantes?
En este momento, la cola necesita ser sacada. Pondremos los datos que el hilo no puede digerir en la cola, dejaremos que la cola de datos en la cola, y esperemos a que el hilo se consuma, y luego lo sacaremos de la cola y lo consumiremos lentamente.
Dibujemos una imagen para explicar:
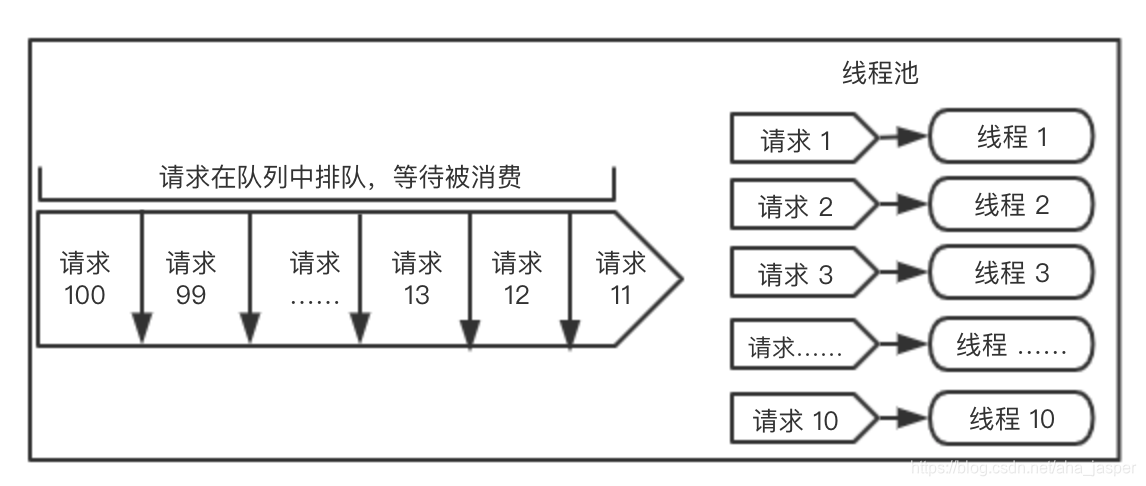
el lado derecho de la figura anterior indica que 10 subprocesos están consumiendo solicitudes con toda su fuerza, y el lado izquierdo indica que las solicitudes restantes están en cola en la cola y esperando el consumo.
Se puede ver que la cola ocupa una posición muy importante en el grupo de subprocesos. Cuando los subprocesos en el grupo de subprocesos no están ocupados, las solicitudes se pueden esperar en la cola y consumirse lentamente.
A continuación, echemos un vistazo a qué tipos de colas se usan en el grupo de subprocesos y qué papel desempeñan.
1.2 Tipos de colas utilizadas en el grupo de subprocesos
1.2.1 Cola LinkedBlockingQueue
newFixedThreadPool newFixedThreadPool
que acabamos de decir es un conjunto de subprocesos de tamaño fijo, lo que significa que cuando se inicializa el conjunto de subprocesos, el tamaño del subproceso en el conjunto de subprocesos no cambiará (la configuración predeterminada del conjunto de subprocesos no reciclará el número de subprocesos centrales) Echemos un vistazo al código fuente de newFixedThreadPool:
// ThreadPoolExecutor 初始化时,第一个参数表示 coreSize,第二个参数是 maxSize,coreSize == maxSize,
// 表示线程池初始化时,线程大小已固定,所以叫做固定(Fixed)线程池。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
En el código fuente, puede ver que ThreadPoolExecutor se inicializa. ThreadPoolExecutor es la API del grupo de subprocesos. Desarrollaremos en el capítulo del grupo de subprocesos. Su quinto parámetro de construcción es la cola. El grupo de subprocesos seleccionará diferentes colas según el escenario. Aquí usamos LinkedBlockingQueue es el parámetro predeterminado de Queue, lo que significa que la capacidad máxima de esta cola de bloqueo es el valor máximo de Integer, es decir, cuando la capacidad de procesamiento del grupo de subprocesos es limitada, el número máximo de tareas se puede almacenar en la cola de bloqueo.
Pero en nuestro trabajo real, a menudo no se recomienda usar newFixedThreadPool directamente, principalmente porque usa el constructor predeterminado de LinkedBlockingQueue, la capacidad de la cola es demasiado grande y en las solicitudes que requieren una respuesta en tiempo real, la capacidad de la cola es demasiado grande y a menudo dañina. .
Por ejemplo, si usamos el grupo de subprocesos anterior, hay 10 subprocesos, y la cola es el valor máximo de Integer. Cuando el tráfico concurrente es grande, como una solicitud de 1w / qps, entonces no se consumen 10 subprocesos, y habrá muchas solicitudes. Está bloqueado en la cola. Aunque 10 subprocesos todavía se consumen continuamente, lleva tiempo consumir todos los datos en la cola. Suponga que toma 3 segundos consumir todos los datos, y todas estas solicitudes en tiempo real tienen tiempos de espera. El tiempo de espera predeterminado es de 2 segundos. Cuando el tiempo llega a 2 segundos, la solicitud ha excedido el tiempo de espera y se devuelve un error. En este momento, muchas tareas en la cola están esperando el consumo. Incluso si el consumo se completa más tarde, no puede devolverse a la persona que llama. .
La situación anterior hará que la persona que llama vea que la interfaz devolvió un error después del tiempo de espera, pero la tarea del servidor todavía está en cola para su ejecución. Después de 3 segundos, la tarea del servidor puede ejecutarse con éxito, pero la persona que llama no ha podido percibir, llamar Cuando la persona vuelva a llamar, verá que la solicitud ha sido exitosa.
Si la persona que llama se originó en la página, la experiencia será peor. La primera llamada en la página da un error. Cuando el usuario actualiza la página, la página muestra que la solicitud anterior ha sido exitosa. Esta es una experiencia muy mala.
Por lo tanto, esperamos que el tamaño de la cola no sea tan grande y que el tamaño de la cola se pueda establecer de acuerdo con la situación de consumo real, a fin de garantizar que las solicitudes en cola se puedan ejecutar antes de que se agote el tiempo de espera de la interfaz.
La escena es más complicada. Para facilitar la comprensión, hicimos un dibujo y explicamos todo el proceso:
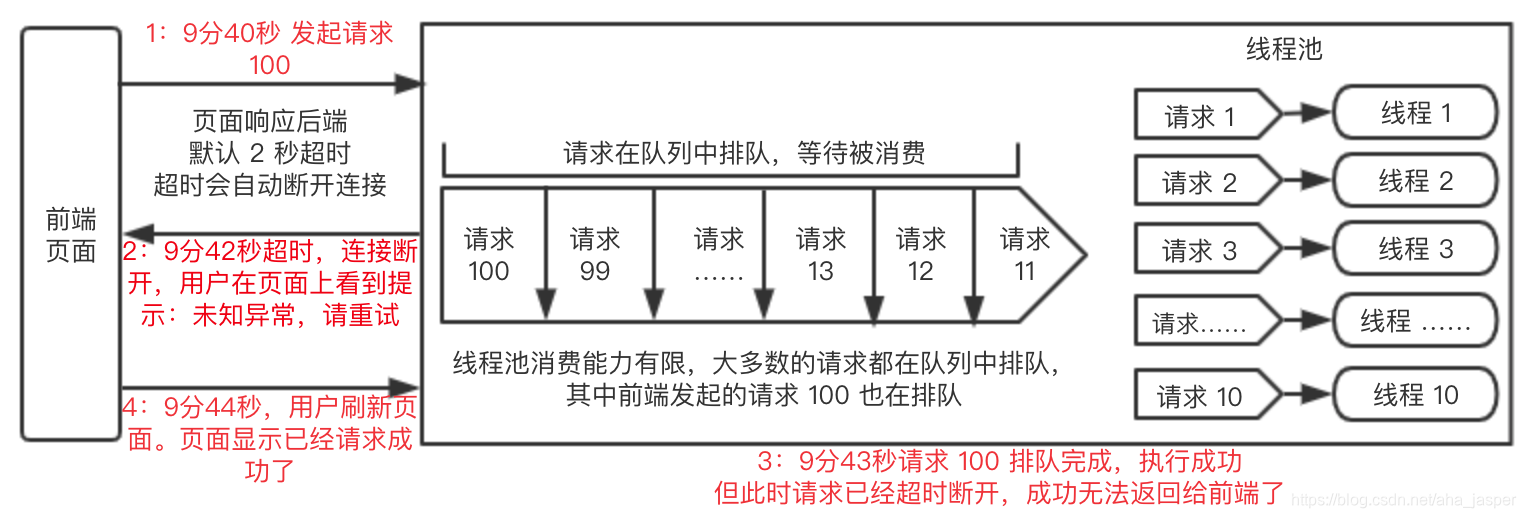
este tipo de problema ya ha sido un accidente de producción muy serio en el trabajo real. Debemos tener cuidado al usarlo.
NewSingleThreadExecutor
y newFixedThreadPool son iguales, la parte inferior del método newSingleThreadExecutor también es LinkedBlockingQueue, el grupo de subprocesos newSingleThreadExecutor solo tendrá un subproceso inferior, lo que significa que este grupo de subprocesos solo puede manejar una solicitud a la vez, y las solicitudes restantes se pondrán en cola para su ejecución en la cola. Mire la implementación del código fuente de newSingleThreadExecutor:
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
// 前两个参数规定了这个线程池一次只能消费一个线程
// 第五个参数使用的是 LinkedBlockingQueue,说明当请求超过单线程消费能力时,就会排队
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
Se puede ver que la capa inferior utiliza los parámetros predeterminados de LinkedBlockingQueue, lo que significa que el valor máximo de la cola es el valor máximo de Integer.
1.2.2 SynchronousQueue
Además del método newFixedThreadPool, existen varios otros métodos correspondientes a diferentes colas cuando se crea el grupo de subprocesos. Echemos un vistazo a newCachedThreadPool. La capa inferior de newCachedThreadPool corresponde a la cola SynchronousQueue. El código fuente es el siguiente:
public static ExecutorService newCachedThreadPool() {
// 第五个参数是 SynchronousQueue
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
La cola SynchronousQueue no tiene límite de tamaño, y el número de solicitudes puede resistir la cola. Se puede decir que esta es su ventaja. La desventaja es que cada vez que los datos se colocan en la cola, no pueden regresar de inmediato, pero deben esperar a que un hilo los tome. Para volver normalmente, si la cantidad de solicitudes es grande y la capacidad de consumo es baja, Hodler retendrá una gran cantidad de solicitudes. Debe liberarse después de que se complete el consumo lento, por lo que debe tener cuidado en el trabajo normal.
1.2.3 Cola DelayedWorkQueue
newScheduledThreadPool representa el grupo de subprocesos de tareas programadas, el código fuente subyacente es el siguiente:
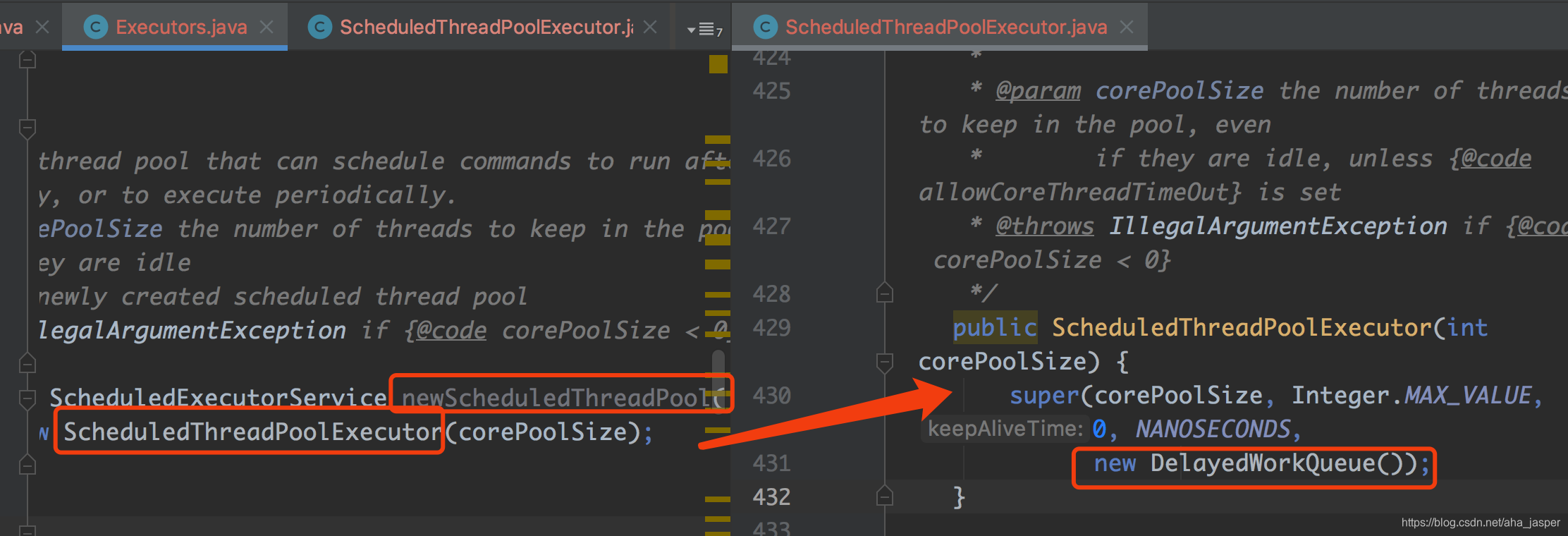
de izquierda a derecha en la captura de pantalla, podemos ver que la cola inferior usa la cola de retraso DelayedWorkQueue, lo que indica que la función del retraso inferior del grupo de subprocesos es proporcionada por la cola DelayedWorkQueue, todas las nuevas solicitudes de retraso son primero A la cola, cuando se agota el tiempo de retraso, el grupo de subprocesos puede tomar el subproceso de la cola para su ejecución.
El método newSingleThreadScheduledExecutor también es el mismo que newScheduledThreadPool, que utiliza la función retardada de DelayedWorkQueue, pero el primero se ejecuta mediante un solo subproceso.
1.3 Resumen
Desde el código fuente del grupo de subprocesos, podemos ver:
- En el diseño del grupo de subprocesos, la cola desempeña el papel de almacenar los datos en el búfer y retrasar la ejecución de los datos.
- De acuerdo con diferentes escenarios, el grupo de subprocesos elige usar una variedad de colas como DelayedWorkQueue, SynchronousQueue y LinkedBlockingQueue, para implementar sus propias funciones diferentes, como usar la función Delay de DelayedWorkQueue para implementar el grupo de subprocesos para la ejecución regular.
2 La combinación de cola y bloqueo
Generalmente escribimos esto cuando escribimos el código de bloqueo:
ReentrantLock lock = new ReentrantLock();
try{
lock.lock();
// do something
}catch(Exception e){
//throw Exception;
}finally {
lock.unlock();
}
Inicialice el bloqueo-> bloqueo-> ejecute la lógica empresarial-> libere el bloqueo, este es un proceso normal, pero sabemos que solo puede haber un hilo a la vez para obtener el bloqueo, entonces, ¿qué otros hilos no deberían obtener el bloqueo en este momento? Que?
En espera, otros hilos que no pueden obtener el bloqueo esperarán en una cola de espera y esperarán a que se libere el bloqueo antes de competir por el bloqueo.
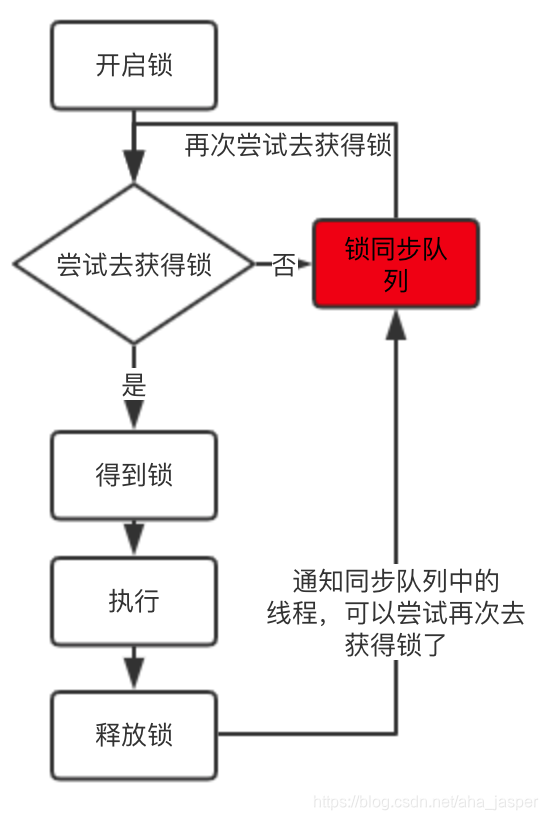
La marca roja en la figura es la cola de sincronización. Los hilos que no pueden obtener el bloqueo se colocarán en la cola de sincronización. Cuando se libera el bloqueo, los hilos en la cola de sincronización comenzarán a competir por el bloqueo.
Se puede ver que una de las funciones de la cola en el bloqueo es ayudar a administrar los hilos que no pueden obtener el bloqueo, de modo que estos hilos puedan esperar pacientemente.
Las colas de sincronización no se implementan utilizando la API de colas existente, pero la estructura y las ideas subyacentes son consistentes con las colas actuales, por lo que aprendemos bien el capítulo de colas y es muy útil para comprender las colas de sincronización de bloqueo.
3 Resumen
La estructura de datos de la cola es realmente importante. Desempeña un papel muy importante en las dos API pesadas de grupo de subprocesos y bloqueo. Necesitamos ser muy claros acerca de la estructura de datos general en la parte inferior de la cola, y entender cómo se ponen en cola y se eliminan los datos. Sí, este capítulo de la cola también es más complicado. Le sugiero que depure mucho. También proporcionamos algunas demostraciones de depuración en github. Puede intentar depurarlo.
