Esta serie de blog relacionado, Mu columna de referencia de clase Java de código fuente y del sistema fabricantes entrevistador sucinta Zhenti
por debajo de esta columna es la dirección de GitHub:
Fuente resolvió: https://github.com/luanqiu/java8
artículo Demostración: HTTPS: // GitHub. com / luanqiu / java8_demo los
compañeros de clase pueden verlo si es necesario)
Análisis del código fuente de Java y preguntas de la entrevista: Marvel en el entrevistador: de la cola de escritura superficial a profunda
Lenguaje introductorio
Muchas fábricas grandes ahora requieren códigos escritos a mano durante las entrevistas. He visto una gran entrevista de fábrica que requiere escribir código en línea. El tema es: Sin utilizar la API de cola Java existente, escriba una cola. Implementado, la estructura de datos de la cola, los métodos de cola y de cola están definidos por usted mismo.
Esta pregunta en realidad examina varios puntos:
- Investigue si está familiarizado con la estructura interna de la cola;
- Investigue sus habilidades en la definición de API;
- Examine las habilidades básicas de escribir código, estilo de código.
En este capítulo, trabajaremos con usted para combinar los puntos anteriores y escribir a mano una cola para familiarizarse con las ideas y el proceso. Para obtener el código de cola completo, consulte: demo.four.DIYQueue y demo.four.DIYQueueDemo
1 definición de interfaz
Antes de implementar la cola, primero debemos definir la interfaz de la cola, que es la API que solemos decir. La API es la fachada de nuestra cola. El principio principal al definir es simple y fácil de usar.
La cola que implementamos esta vez solo define dos funciones de poner datos y tomar datos. La interfaz se define de la siguiente manera:
/**
* 定义队列的接口,定义泛型,可以让使用者放任意类型到队列中去
* author wenhe
* date 2019/9/1
*/
public interface Queue<T> {
/**
* 放数据
* @param item 入参
* @return true 成功、false 失败
*/
boolean put(T item);
/**
* 拿数据,返回一个泛型值
* @return
*/
T take();
// 队列中元素的基本结构
class Node<T> {
// 数据本身
T item;
// 下一个元素
Node<T> next;
// 构造器
public Node(T item) {
this.item = item;
}
}
}
Hay algunos puntos que explicamos:
- Al definir una interfaz, asegúrese de escribir comentarios, comentarios de interfaz, comentarios de métodos, etc., para que otros sean mucho más fáciles al mirar nuestra interfaz ';
- Al definir una interfaz, el nombre debe ser conciso y claro. Es mejor que otros sepan lo que hace la interfaz tan pronto como se nombra. Por ejemplo, si la nombramos Cola, otros sabrán que esta interfaz está relacionada con la cola de un vistazo;
- Usa bien los genéricos, porque no sabemos exactamente qué valores se ponen en la cola, por lo que usamos T genérico, lo que significa que podemos poner cualquier valor en la cola;
- No hay necesidad de escribir un método público para el método en la interfaz, porque los métodos en la interfaz son todos públicos de forma predeterminada, y aparecerá en gris cuando escriba el compilador, como se muestra a continuación:
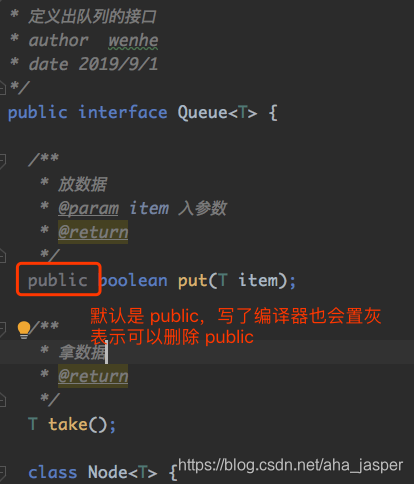
- Definimos el elemento básico Nodo en la interfaz, de modo que si la subclase de cola quiere usarlo, se puede usar directamente, lo que aumenta la posibilidad de reutilización.
2 Implementación de subclase de cola
Luego comenzaremos a escribir la implementación de subclase, vamos a escribir una cola de la estructura de datos de lista enlazada más utilizada.
2.1 Estructura de datos
Utilizamos listas vinculadas para la estructura de datos subyacente. Cuando se trata de listas vinculadas, debe pensar inmediatamente en tres elementos clave: encabezado de lista vinculada, cola de lista vinculada y elementos de lista vinculados. También lo hemos implementado. El código es el siguiente:
/**
* 队列头
*/
private volatile Node<T> head;
/**
* 队列尾
*/
private volatile Node<T> tail;
/**
* 自定义队列元素
*/
class DIYNode extends Node<T>{
public DIYNode(T item) {
super(item);
}
}
Además de estos elementos, también tenemos la capacidad del contenedor de la cola, el tamaño actual de la cola, el bloqueo de datos, el bloqueo de datos, etc. El código es el siguiente:
/**
* 队列的大小,使用 AtomicInteger 来保证其线程安全
*/
private AtomicInteger size = new AtomicInteger(0);
/**
* 容量
*/
private final Integer capacity;
/**
* 放数据锁
*/
private ReentrantLock putLock = new ReentrantLock();
/**
* 拿数据锁
*/
private ReentrantLock takeLock = new ReentrantLock();
2.2 Inicialización
Proporcionamos dos formas de usar la capacidad predeterminada (el valor máximo de Integer) y la capacidad especificada, el código es el siguiente:
/**
* 无参数构造器,默认最大容量是 Integer.MAX_VALUE
*/
public DIYQueue() {
capacity = Integer.MAX_VALUE;
head = tail = new DIYNode(null);
}
/**
* 有参数构造器,可以设定容量的大小
* @param capacity
*/
public DIYQueue(Integer capacity) {
// 进行边界的校验
if(null == capacity || capacity < 0){
throw new IllegalArgumentException();
}
this.capacity = capacity;
head = tail = new DIYNode(null);
}
2.3 Implementación del método put
public boolean put(T item) {
// 禁止空数据
if(null == item){
return false;
}
try{
// 尝试加锁,500 毫秒未获得锁直接被打断
boolean lockSuccess = putLock.tryLock(300, TimeUnit.MILLISECONDS);
if(!lockSuccess){
return false;
}
// 校验队列大小
if(size.get() >= capacity){
log.info("queue is full");
return false;
}
// 追加到队尾
tail = tail.next = new DIYNode(item);
// 计数
size.incrementAndGet();
return true;
} catch (InterruptedException e){
log.info("tryLock 500 timeOut", e);
return false;
} catch(Exception e){
log.error("put error", e);
return false;
} finally {
putLock.unlock();
}
}
La implementación del método put tiene varios puntos a los que debemos prestar atención:
- Preste atención al ritmo de tratar de atrapar finalmente, atrapar puede atrapar muchos tipos de excepciones, hemos detectado excepciones de tiempo de espera y excepciones desconocidas aquí, debemos recordar liberar finalmente el bloqueo, de lo contrario el bloqueo no se liberará automáticamente, esto no debe usarse mal, Refleja la precisión de nuestro código;
- Las comprobaciones lógicas necesarias son necesarias, como la comprobación de puntero nulo si el parámetro de entrada está vacío y la comprobación crítica si la cola está llena. Estos códigos de comprobación pueden reflejar el rigor de nuestra lógica;
- También es muy importante agregar registros y comentarios en lugares clave del código. No queremos tener comentarios y registros de códigos lógicos clave, lo que no es propicio para leer el código y solucionar problemas;
- Preste atención a la seguridad del hilo Además del bloqueo, para el tamaño de la capacidad, elegimos una clase de conteo seguro para el hilo: AtomicInteger para garantizar la seguridad del hilo;
- Al bloquear, es mejor que no usemos el método de bloqueo permanente. Debemos usar el método de bloqueo con un período de tiempo de espera. El período de tiempo de espera que establezcamos aquí es de 300 milisegundos, lo que significa que si el bloqueo no se ha adquirido dentro de los 300 milisegundos, El método put devuelve directamente false, por supuesto, puede establecer el tamaño del tiempo de acuerdo con la situación;
- Establezca diferentes valores de retorno de acuerdo con diferentes situaciones. El método put devuelve falso. Cuando ocurre una excepción, podemos elegir devolver falso o directamente lanzar una excepción;
- Al colocar datos, se agrega al final de la cola, por lo que solo necesitamos convertir los nuevos datos en DIYNode y colocarlos al final de la cola.
2.4 Implementación del método take
La implementación del método take es muy similar al método put, excepto que take toma datos del encabezado. La implementación del código es la siguiente:
public T take() {
// 队列是空的,返回 null
if(size.get() == 0){
return null;
}
try {
// 拿数据我们设置的超时时间更短
boolean lockSuccess = takeLock.tryLock(200,TimeUnit.MILLISECONDS);
if(!lockSuccess){
throw new RuntimeException("加锁失败");
}
// 把头结点的下一个元素拿出来
Node expectHead = head.next;
// 把头结点的值拿出来
T result = head.item;
// 把头结点的值置为 null,帮助 gc
head.item = null;
// 重新设置头结点的值
head = (DIYNode) expectHead;
size.decrementAndGet();
// 返回头结点的值
return result;
} catch (InterruptedException e) {
log.info(" tryLock 200 timeOut",e);
} catch (Exception e) {
log.info(" take error ",e);
}finally {
takeLock.unlock();
}
return null;
}
A través de los pasos anteriores, nuestra cola ha sido escrita, el código completo puede verse: demo.four.DIYQueue.
3 prueba
Se escribe la API. A continuación, escribiremos algunas pruebas de escena y pruebas unitarias para la API. Escribamos una prueba de escena para ver si la API puede ejecutarse. El código es el siguiente:
public class DIYQueueDemo {
// 我们需要测试的队列
private final static Queue<String> queue = new DIYQueue<>();
// 生产者
class Product implements Runnable{
private final String message;
public Product(String message) {
this.message = message;
}
@Override
public void run() {
try {
boolean success = queue.put(message);
if (success) {
log.info("put {} success", message);
return;
}
log.info("put {} fail", message);
} catch (Exception e) {
log.info("put {} fail", message);
}
}
}
// 消费者
class Consumer implements Runnable{
@Override
public void run() {
try {
String message = (String) queue.take();
log.info("consumer message :{}",message);
} catch (Exception e) {
log.info("consumer message fail",e);
}
}
}
// 场景测试
@Test
public void testDIYQueue() throws InterruptedException {
ThreadPoolExecutor executor =
new ThreadPoolExecutor(10,10,0,TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>());
for (int i = 0; i < 1000; i++) {
// 是偶数的话,就提交一个生产者,奇数的话提交一个消费者
if(i % 2 == 0){
executor.submit(new Product(i+""));
continue;
}
executor.submit(new Consumer());
}
Thread.sleep(10000);
}
El escenario de prueba de código es relativamente simple, pasando de 0 a 1000. Si es uniforme, deje que el productor produzca los datos y los ponga en la cola. Si es extraño, deje que el consumidor saque los datos de la cola para consumo y ejecutar. Los siguientes resultados son los siguientes:
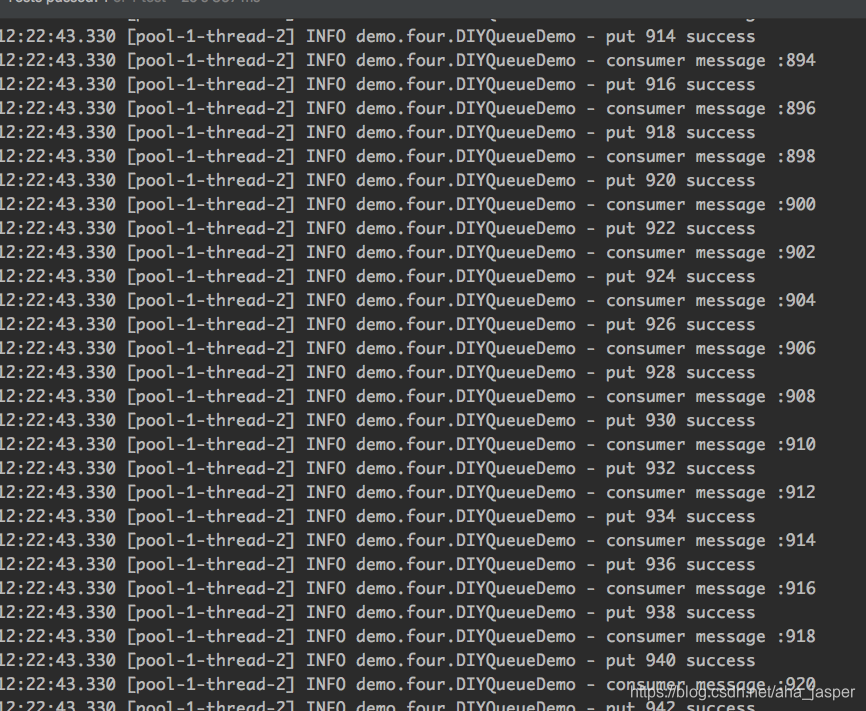
De los resultados mostrados, el DIYQueue que escribimos no tiene muchos problemas. Por supuesto, si desea usarlo a gran escala, necesita pruebas unitarias detalladas y pruebas de rendimiento.
4 Resumen
A través del estudio de este capítulo, no sé si tiene la sensación de que la cola es muy simple. De hecho, la cola en sí es muy simple, no tan complicada como se imagina.
Siempre y cuando comprendamos los principios básicos de las colas y comprendamos varias estructuras de datos de uso común, el problema de las colas de escritura a mano no es realmente grande. Debe intentarlo rápidamente.
