Este artículo analiza principalmente el principio de la tubería de cinco etapas y el enclavamiento de la tubería, para que se pueda escribir un código de ensamblaje más eficiente.
1. Tubería de cinco etapas ARM9
ARM7 utiliza una estructura de canalización típica de tres etapas, que incluye tres partes de recuperación, decodificación y ejecución. Entre ellos, la unidad de ejecución realiza una gran cantidad de trabajo, incluidas las operaciones de lectura y escritura de registros y memorias relacionadas con operandos, operaciones de ALU y transmisión de datos entre dispositivos relacionados. Cada una de estas tres fases generalmente toma un ciclo de reloj, pero si tres instrucciones realizan tres etapas de la tubería de tres etapas al mismo tiempo, todavía se puede alcanzar una instrucción por ciclo. Sin embargo, la unidad de ejecución a menudo toma múltiples ciclos de reloj, convirtiéndose así en el cuello de botella del rendimiento del sistema.
ARM9 utiliza un diseño de tubería de cinco etapas más eficiente. Después de recuperar, decodificar y ejecutar, se agregan las etapas LS1 y LS2. LS1 es responsable de cargar y almacenar los datos especificados en la instrucción, y LS2 es responsable de recuperar y firmar la expansión a través de bytes o medias palabras. Los datos cargados por el comando de carga. Pero LS1 y LS2 solo son válidos para los comandos de carga y almacenamiento, otras instrucciones no necesitan ejecutar estas dos etapas. La siguiente es la definición del documento oficial de ARM:
-
Fetch: recupera de la memoria las instrucciones en la dirección pc . La instrucción se carga en el núcleo y luego se procesa en la tubería principal.
-
Decodificar: decodifica la instrucción que se obtuvo en el ciclo anterior. El proceso también lee los operandos de entrada del banco de registro si no están disponibles a través de una de las rutas de reenvío.
-
ALU: ejecuta la instrucción que fue decodificada en el ciclo anterior. Tenga en cuenta que esta instrucción se obtuvo originalmente de la dirección pc - 8 (estado ARM) o pc - 4 (estado Thumb). Normalmente, esto implica calcular la respuesta para una operación de procesamiento de datos, o la dirección para una operación de carga, almacenamiento o sucursal. Algunas instrucciones pueden pasar varios ciclos en esta etapa. Por ejemplo, las operaciones de cambio controladas por multiplicación y registro toman varios ciclos de ALU.
-
LS1: cargar o almacenar los datos especificados por una instrucción de carga o almacenamiento. Si la instrucción no es una carga o almacenamiento, entonces esta etapa no tiene efecto.
-
LS2: Extrae y amplía con cero o con signo los datos cargados por un byte o una instrucción de carga de media palabra. Si la instrucción no es una carga de un byte de 8 bits o un elemento de media palabra de 16 bits, entonces esta etapa no tiene efecto.
2. El problema del enclavamiento de la tubería.
LDR r1, [r2, #4]
ADD r0, r0, r1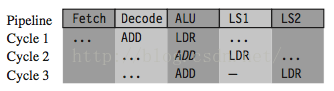
LDRB r1, [r2, #1]
ADD r0, r0, r2
EOR r0, r0, r1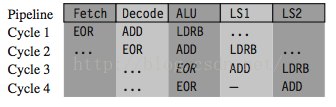
Mira el siguiente ejemplo nuevamente:
MOV r1, #1
B case1
AND r0, r0, r1 EOR r2, r2, r3 ...
case1:
SUB r0, r0, r1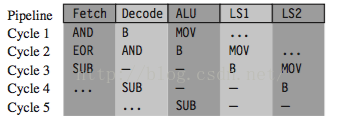
3. Evite el enclavamiento de la tubería para mejorar la eficiencia operativa
void str_tolower(char *out, char *in)
{
unsigned int c;
do {
c = *(in++);
if (c>=’A’ && c<=’Z’)
{
c = c + (’a’ -’A’);
}
*(out++) = (char)c;
} while (c);
}str_tolower
LDRB r2,[r1],#1 ; c = *(in++)
SUB r3,r2,#0x41 ; r3=c-‘A’
CMP r3,#0x19 ; if (c <=‘Z’-‘A’)
ADDLS r2,r2,#0x20 ; c +=‘a’-‘A’
STRB r2,[r0],#1 ; *(out++) = (char)c
CMP r2,#0 ; if (c!=0)
BNE str_tolower ; goto str_tolower
MOV pc,r14 ; return3.1 Programación de carga mediante precarga
out RN 0 ; pointer to output string
in RN 1 ; pointer to input string
c RN 2 ; character loaded
t RN 3 ; scratch register
; void str_tolower_preload(char *out, char *in)
str_tolower_preload
LDRB c, [in], #1 ; c = *(in++)
loop
SUB t, c, #’A’ ; t = c-’A’
CMP t, #’Z’-’A’ ; if (t <= ’Z’-’A’)
ADDLS c, c, #’a’-’A’ ; c += ’a’-’A’;
STRB c, [out], #1 ; *(out++) = (char)c;
TEQ c, #0 ; test if c==0
LDRNEB c, [in], #1 ; if (c!=0) { c=*in++;
BNE loop ; goto loop; }
MOV pc, lr ; return
3.2 Programación de carga desenrollando
out RN 0 ; pointer to output string
in RN 1 ; pointer to input string
ca0 RN 2 ; character 0
t RN 3 ; scratch register
ca1 RN 12 ; character 1
ca2 RN 14 ; character 2
; void str_tolower_unrolled(char *out, char *in)
str_tolower_unrolled
STMFD sp!, {lr} ; function entry
loop_next3
LDRB ca0, [in], #1 ; ca0 = *in++;
LDRB ca1, [in], #1 ; ca1 = *in++;
LDRB ca2, [in], #1 ; ca2 = *in++;
SUB t, ca0, #’A’ ; convert ca0 to lower case
CMP t, #’Z’-’A’
ADDLS ca0, ca0, #’a’-’A’
SUB t, ca1, #’A’ ; convert ca1 to lower case
CMP t, #’Z’-’A’
ADDLS ca1, ca1, #’a’-’A’
SUB t, ca2, #’A’ ; convert ca2 to lower case
CMP t, #’Z’-’A’
ADDLS ca2, ca2, #’a’-’A’
STRB ca0, [out], #1 ; *out++ = ca0;
TEQ ca0, #0 ; if (ca0!=0)
STRNEB ca1, [out], #1 ; *out++ = ca1;
TEQNE ca1, #0 ; if (ca0!=0 && ca1!=0)
STRNEB ca2, [out], #1 ; *out++ = ca2;
TEQNE ca2, #0 ; if (ca0!=0 && ca1!=0 && ca2!=0)
BNE loop_next3 ; goto loop_next3;
LDMFD sp!, {pc} ; return;
