Prólogo
El conjunto de datos del encabezado se usa en el proyecto, y la mayoría de los encabezados en el conjunto de datos de imagen abierta en el artículo anterior no tienen imágenes generales, lo que no es adecuado para mi escenario de aplicación. Por casualidad, el conjunto de datos de lavado de cerebro se encontró en guthub aditya-vora / FCHD-Fully-Convolutional-Head-Detector . Su formato de archivo de anotación es muy diferente del formato de anotación yolo, este artículo tiene como objetivo lograr la conversión de los dos.
Listo
- python3
- cmd
- Enlace de disco de red del conjunto de datos de lavado de cerebro : https://pan.baidu.com/s/1Vgr6jZByU41TPd2tkiPMwA código de extracción: rnk3
lavar el cerebro
El conjunto de datos de lavado de cerebro es un conjunto de datos de detección de la cabeza densa, que es un conjunto de datos obtenido al marcar a un grupo de personas que aparecen en un café y luego etiquetar a este grupo de personas. Contiene tres partes, el conjunto de entrenamiento: 10769 imágenes con 81975 cabezas, y el conjunto de validación: 500 imágenes con 3318 cabezas. Conjunto de prueba: 500 imágenes con 5007 cabezas. Este artículo solo discute su conjunto de entrenamiento.

Sus archivos de anotación están en varios archivos idl, como el conjunto de entrenamiento en brainwash_train.idl, y su formato de anotación es el siguiente: "ruta de imagen": anotación. Cada cuadro está encerrado entre paréntesis, las coordenadas están separadas por comas y los cuadros están separados por comas. Cada imagen está en su propia línea y el final está separado por un punto y coma.
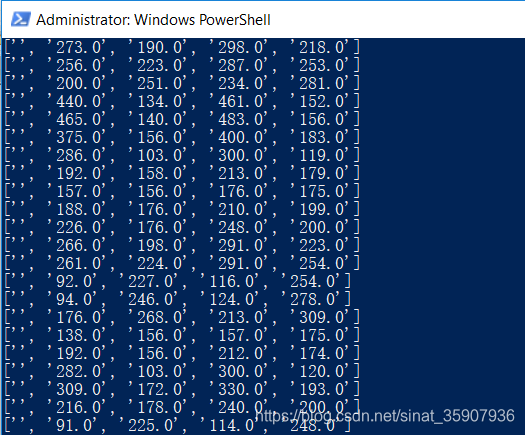
"brainwash_11_13_2014_images/04231500_640x480.png": (316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
"brainwash_11_13_2014_images/04232000_640x480.png": (485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
"brainwash_11_24_2014_images/00000500_640x480.jpg": (385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
"brainwash_11_24_2014_images/00001000_640x480.jpg": (160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0);El siguiente paso es sacar cada fila de datos de acuerdo con este formato de datos y luego cambiarlo al formato yolo:
<Categoría> <centro coordinado normalizado x> <centro coordinado normalizado y> <imagen normalizada w> <imagen normalizada h>
<Categoría> <centro coordinado normalizado x> <centro coordinado normalizado y> <imagen normalizada w> <imagen normalizada h>
........
<Categoría> <centro coordinado normalizado x> <centro coordinado normalizado y> <imagen normalizada w> <imagen normalizada h>
Luego, colóquelos en un archivo txt con el nombre de la imagen.
Conversión de formato
Split:
Después de la observación, descubrimos que algunas cosas no son necesarias, y algunas cosas deben usarse como nombres de archivo, y algunas cosas deben usarse como contenido de archivo, por lo que primero debemos dividirlo y luego hacer diferentes tratamientos para cada parte. Primero dividí cada línea en dos partes, a saber, la parte de la ruta de la imagen y la parte de anotación de la imagen. Tenga en cuenta que las dos partes se dividen por ":", pero el final de cada línea se divide por ";", primero podemos dividir ":" Reemplace con ";" y luego divida según ";", puede eliminar estos dos símbolos adicionales.
import os
idl_file_dir = "brainwash_train.idl" #相对地址
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir) #用于存生成的txt文件
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";") #用;替换:
#print(line)Después de realizar la operación anterior, todo el archivo de etiqueta se convierte en dos partes, la ruta se almacena en line.split (";") [0] y la etiqueta se almacena en line.split (";") [1]. Primero procese la parte de la ruta, observe que hay punto y coma a ambos lados de la ruta, y luego el símbolo redundante, así que bórrelo primero, y luego divídalo por "/" para obtener el nombre de la imagen, y finalmente por "." Para obtener la división Nombre de imagen sin sufijo. Por supuesto, este nombre también es el nombre del archivo sin el sufijo del archivo marcado más adelante.
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"") #删除分号
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0] #得到后缀名与文件名
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)Después de realizar las operaciones anteriores, el nombre del archivo y el nombre del sufijo están disponibles, el primero será el nombre del archivo marcado y el segundo se convertirá en una condición de filtrado. Ahora, dividamos la parte de la etiqueta, la parte de la etiqueta se ve así. Primero borre todo "," ( porque hay un espacio antes de cada "," en el archivo de etiquetado original, si reemplaza "," con un espacio, entonces habrá más espacios después de la división final ). Luego borre los corchetes de "(", y finalmente use ")" para separar los diferentes cuadros.
(316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
(485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
(385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
(160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0); img_boxs = img_boxs.replace(",","") #删除“,”
#print(img_boxs)
img_boxs = img_boxs.replace("(","") #删除“(”
img_boxs = img_boxs.split(")") #删除“)”
#print(img_boxs)Hasta ahora, los datos se han dividido básicamente: una imagen y una img_boxs, cada cuadro es una dimensión de img_boxs, y el número de cuadros es la dimensión total de img_boxs. Tenga en cuenta que el último elemento de cada img_boxs es un elemento de espacio, y este elemento se elimina solo atravesando len (img_boxs) -1 menos uno (no visite img_boxs [m], aparecerá el índice de lista fuera de rango cuando m> 0 Error)
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1): #消除空格项影响
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])

El último paso es convertir el formato de lavado de cerebro [xmin, ymin, xmax, ymax] al <categoría> <coordenada central normalizada x> <coordenada central normalizada y> <imagen normalizada w> <normalizada Imagen h>, debe calcular las coordenadas normalizadas, el ancho y la altura normalizados, y luego agregar el archivo de anotación de una imagen al archivo txt con el nombre del nombre de la imagen, y se completa la conversión del tipo de datos. El resultado se muestra a continuación. Vea el apéndice para el código completo.
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')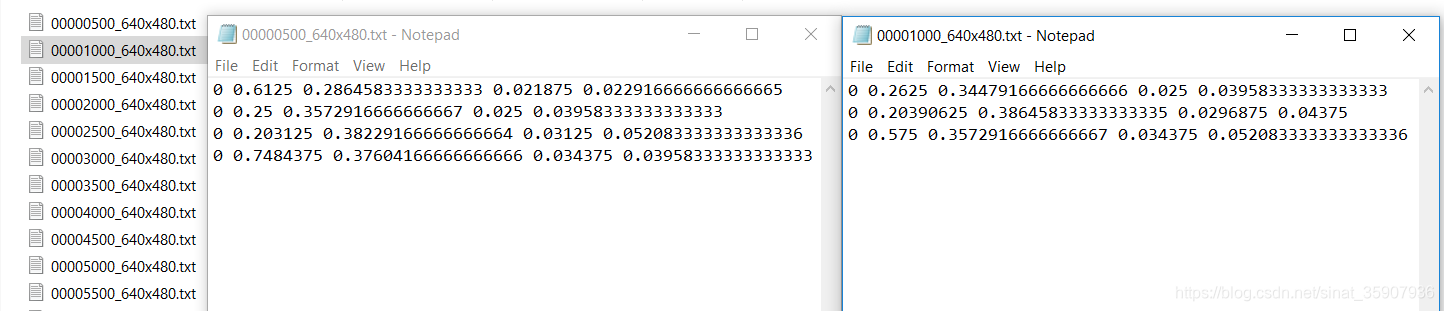
verificación de yolo_mark
La etiqueta y la imagen de yolo_mark están en la misma carpeta, y ahora estamos en una carpeta diferente y la imagen, y la etiqueta aquí está filtrada, por lo que el guión que escribí en otro artículo puede ser muy Es fácil fusionar el contenido de las dos carpetas en función de la etiqueta. Luego abra la verificación yolo_mark, el método de uso yolo_mark vea mi otro artículo . Al azar, consulte dos, puede ver que no hay problema con la etiqueta, lo que indica que la conversión se realizó correctamente.
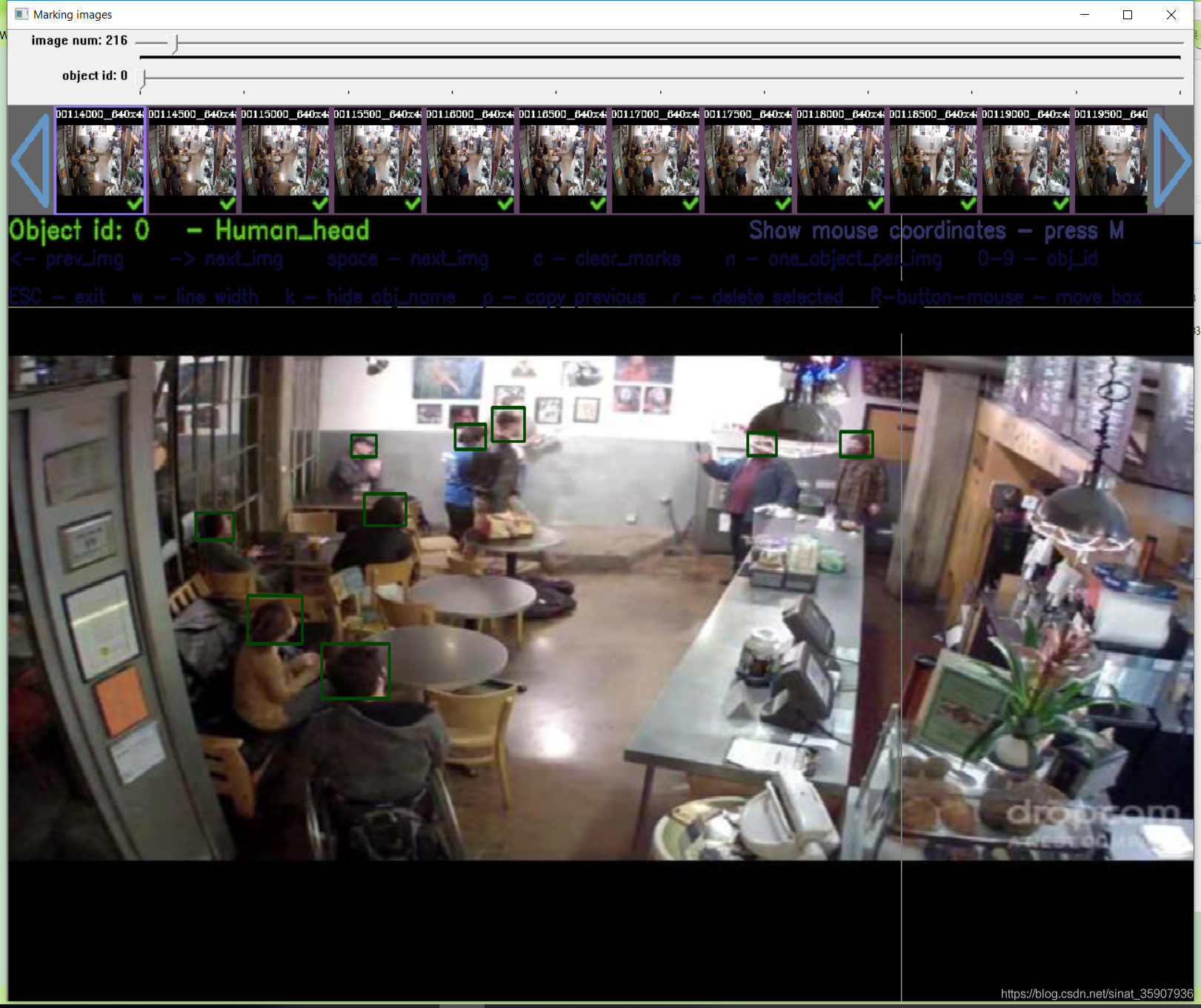
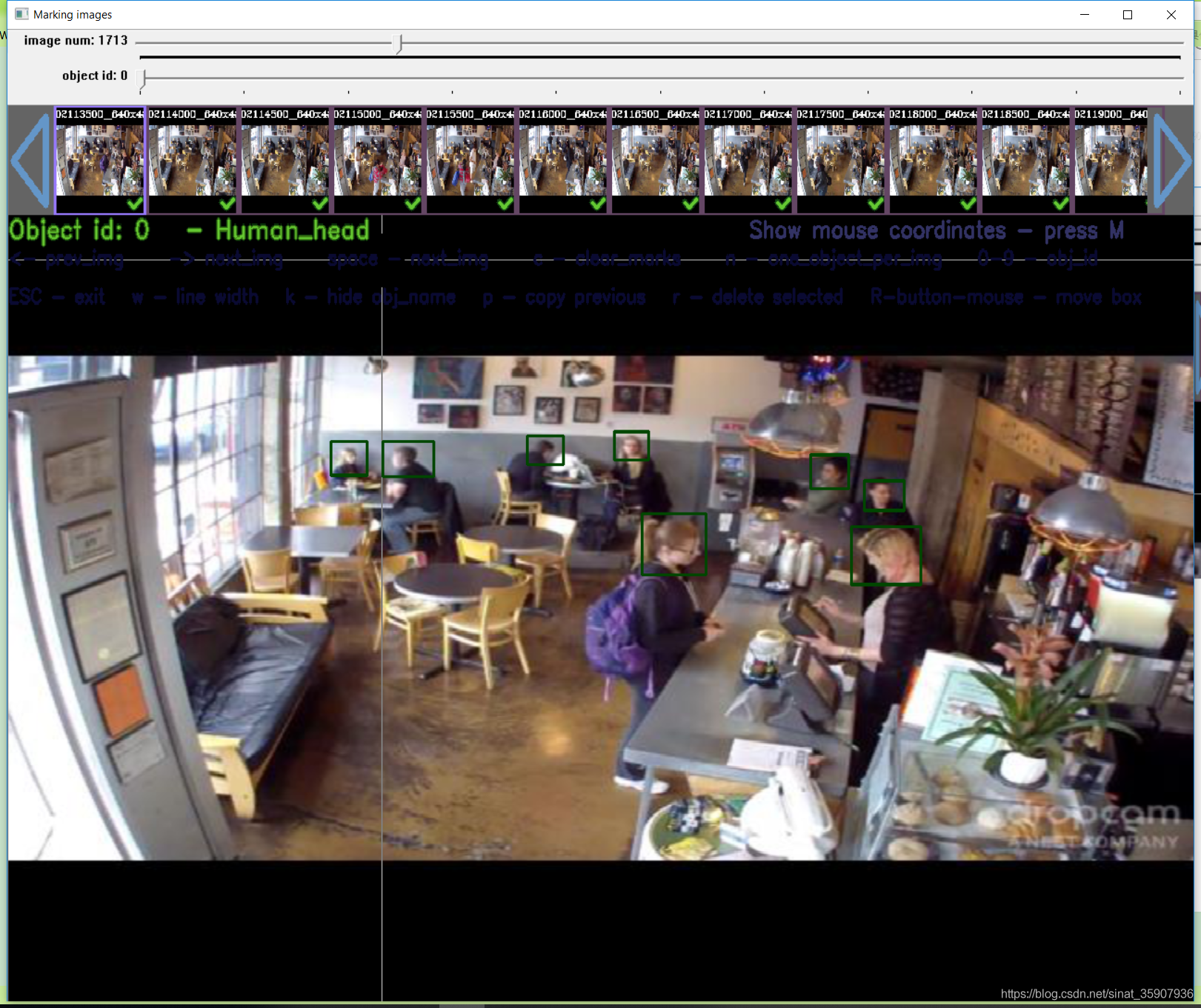
Resumen
La conversión entre formatos de etiquetado de datos no es más que dividir los datos de acuerdo con ciertas reglas, y luego calcular y reorganizar los datos para obtener otro tipo de datos de etiquetado. Arriba, si un amigo está destinado a leer este artículo, es realmente un honor. Si tiene alguna pregunta, deje un mensaje para discutir a continuación. Le responderé después de verlo.
Referencia
https://blog.csdn.net/sinat_35907936/article/details/88911770
https://blog.csdn.net/sinat_35907936/article/details/89605978
https://blog.csdn.net/sinat_35907936/article/details/89086081
http://arxiv.org/abs/1506.04878
Apéndice
import os
idl_file_dir = "brainwash_train.idl"
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir)
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";")
#print(line)
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"")
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0]
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)
img_boxs = img_boxs.replace(",","")
#print(img_boxs)
img_boxs = img_boxs.replace("(","")
img_boxs = img_boxs.split(")")
#print(img_boxs)
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1):
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')
