Mapper se da cuenta de la fusión de tablas ayb
1.mapeador
package
com.cevent.hadoop.mapreduce.order.distribute;
import
java.io.BufferedReader;
import
java.io.File;
import
java.io.FileInputStream;
import
java.io.IOException;
import
java.io.InputStreamReader;
import
java.util.HashMap;
import
java.util.Map;
import
org.apache.commons.lang.StringUtils;
import
org.apache.hadoop.io.LongWritable;
import
org.apache.hadoop.io.NullWritable;
import
org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapreduce.Mapper;
/**
*
mapper需求:合并product.txt和order.txt的内容
*
* @author cevent
* @date 2020年4月13日
*/
public class OrderDistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
//保存缓存集合
private Map<String,String> productMap=new HashMap<>();
//初始化读取文件
@Override
protected void setup(Context context)
throws
IOException, InterruptedException {
// 1.读取product.txt,根据driver直接读取到当前目录
BufferedReader bufferedReader=new BufferedReader(
new InputStreamReader(
//这里声明:new File路径不可以为直接文件名,否则会找不到路径,必须写全路径
new FileInputStream(new File("D:/DEV_CODE/eclipse_code/hadoopTMP/inputOrderProductCache/product.txt"))));
// 2.将数据保存到缓存集合
String productLine;
// 3.循环遍历数据,bufferedReader.readLine()读取出一行数据:02 华为
while(StringUtils.isNotEmpty(productLine=bufferedReader.readLine())){
//截取数据
String [] fields=productLine.split("\t");
//存储数据put(key=id value=name)
productMap.put(fields[0], fields[1]);
}
//4.关闭资源
bufferedReader.close();
}
//合并product.txt和order.txt的内容:1002 02 2 productName
Text proKey=new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws
IOException, InterruptedException {
// 1.获取一行
String orderLine=value.toString();
// 2.截取product id
String[] fields=orderLine.split("\t");
String productName=productMap.get(fields[1]);
//3.拼接
proKey.set(orderLine+"\t"+productName);
//4.输出
context.write(proKey, NullWritable.get());
}
}
2.controlador
package
com.cevent.hadoop.mapreduce.order.distribute;
import
java.net.URI;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.Path;
import
org.apache.hadoop.io.NullWritable;
import
org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapreduce.Job;
import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class OrderDistributedCacheDriver {
public static void main(String[] args) throws Exception
{
//1.获取job信息
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration);
//2.设置加载的jar包
job.setJarByClass(OrderDistributedCacheDriver.class);
//3.关联map
job.setMapperClass(OrderDistributedCacheMapper.class);
//4.设置最终输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//5.设置输入/输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//6.加载缓存数据,order与product在不同的文件夹,这里的读取缓存是mapper读取product,在设置run-argu时将order所在文件夹作为input输出
//file:/必须加斜杠
job.addCacheFile(new URI("file:/D:/DEV_CODE/eclipse_code/hadoopTMP/inputOrderProductCache/product.txt"));
//7.map端join的逻辑不需要reduce,设置reduce task=0
job.setNumReduceTasks(0);
//8.提交
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
3. Darse cuenta de salida
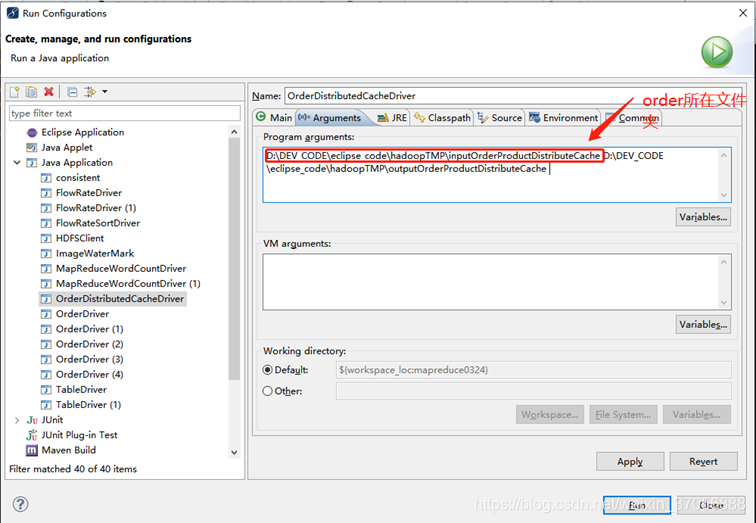


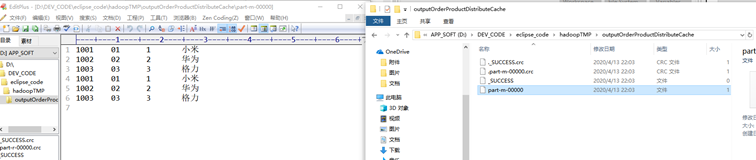
Declaración importante
Hay un problema de que la ruta no se puede encontrar aquí. La ruta del archivo del mapeador en el código fuente originalmente especificó la ruta del controlador, pero si el nombre del archivo se especifica aquí, no se puede encontrar el caché distribuido. Necesitamos cambiar la ruta del archivo a la ruta completa , No agregue archivo: /
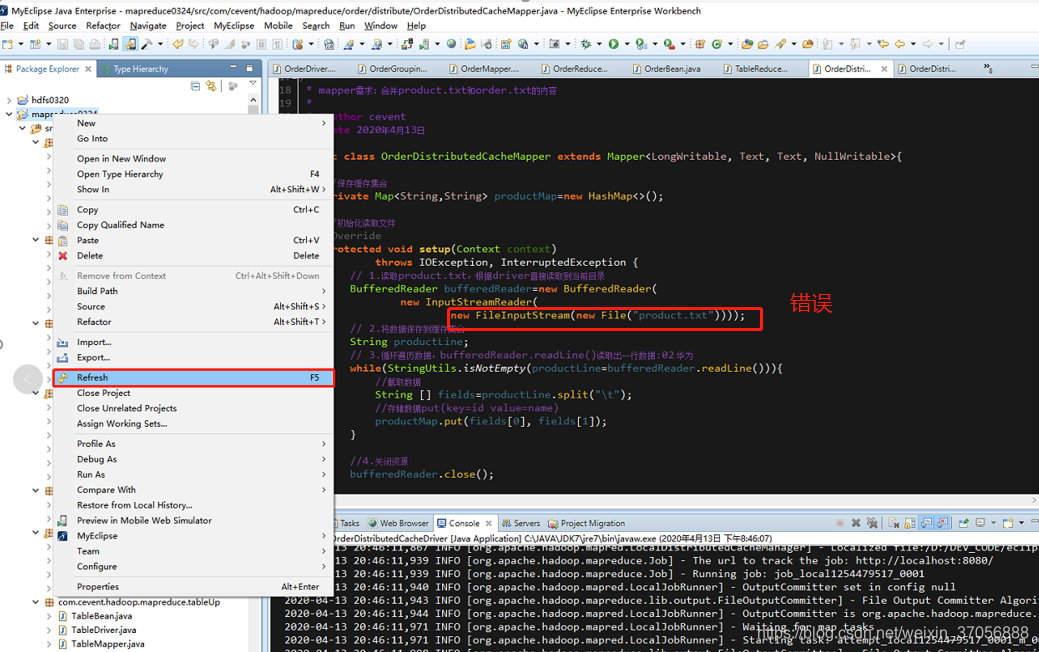
Escribir ruta exacta
BufferedReader bufferedReader=new BufferedReader(
new InputStreamReader(
//这里声明:new File路径不可以为直接文件名,否则会找不到路径,必须写全路径
new FileInputStream(new File("D:/DEV_CODE/eclipse_code/hadoopTMP/inputOrderProductCache/product.txt"))));
